零冗余优化器
内容
- 零概述
- 培训环境
- 启用零优化
- 训练 1.5B 参数 GPT-2 模型
- 训练 10B 参数 GPT-2 模型
- 使用 ZeRO-Infinity 训练万亿级模型
- 使用 ZeRO-Infinity 卸载到 CPU 和 NVMe
- 分配 Massive Megatron-LM 模型
- 以内存为中心的平铺
- 注册外部参数
- 提取权重
如果您还没有这样做,我们建议您在逐步完成本教程之前先阅读有关入门和Megatron-LM GPT-2 的DeepSpeed 教程。
在本教程中,我们将 ZeRO 优化器应用于Megatron-LM GPT-2模型。ZeRO 是一组强大的内存优化技术,可以有效训练具有数万亿参数的大型模型,例如GPT-2和Turing-NLG 17B。与训练大型模型的替代模型并行方法相比,ZeRO 的一个关键吸引力在于不需要修改模型代码。正如本教程将演示的那样,在 DeepSpeed 模型中使用 ZeRO 既快速又简单,因为您只需更改 DeepSpeed 配置 JSON 中的一些配置。无需更改代码。
零概述固定链接
ZeRO 利用数据并行的聚合计算和内存资源来减少用于模型训练的每个设备 (GPU) 的内存和计算需求。ZeRO 通过在分布式训练硬件中的可用设备(GPU 和 CPU)之间划分各种模型训练状态(权重、梯度和优化器状态)来减少每个 GPU 的内存消耗。具体而言,ZeRO 正在作为优化的增量阶段实施,其中早期阶段的优化在后期阶段可用。要深入了解 ZeRO,请参阅我们的论文。
-
阶段 1:优化器状态(例如,对于Adam 优化器、32 位权重以及第一和第二矩估计)在进程之间进行分区,以便每个进程仅更新其分区。
-
阶段 2:用于更新模型权重的减少的 32 位梯度也被分区,这样每个进程只保留与其优化器状态部分对应的梯度。
-
第 3 阶段:16 位模型参数跨进程进行分区。ZeRO-3 将在前向和后向传递过程中自动收集和划分它们。
此外,ZeRO-3 包括无限卸载引擎以形成 ZeRO-Infinity(论文),它可以卸载到 CPU 和 NVMe 内存以节省大量内存。
培训环境固定链接
我们在本练习中使用 DeepSpeed Megatron-LM GPT-2 代码。您可以逐步完成 Megatron-LM教程以熟悉代码。我们将在具有 32GB RAM 的NVIDIA Tesla V100-SXM3 Tensor Core GPU上训练本教程中的模型。
启用零优化固定链接
要为 DeepSpeed 模型启用 ZeRO 优化,我们只需将zero_optimization键添加到 DeepSpeed JSON 配置。此处提供了zero_optimization键的配置旋钮的完整描述。
训练 1.5B 参数 GPT-2 模型固定链接
我们展示了 ZeRO 第 1 阶段的优势,展示了它可以在八个 V100 GPU 上对 15 亿参数的 GPT-2 模型进行数据并行训练。我们将训练配置为使用每个设备 1 的批处理大小,以确保内存消耗主要是由于模型参数和优化器状态。我们通过对 deepspeed 启动脚本应用以下修改来创建此训练场景:
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#89ddff">--model-parallel-size</span> 1 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--num-layers</span> 48 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--hidden-size</span> 1600 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--num-attention-heads</span> 16 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--batch-size</span> 1 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--deepspeed_config</span> ds_zero_stage_1.config <span style="color:#f78c6c">\</span>
</code></span></span>在没有 ZeRO 的情况下训练此模型失败并出现内存不足 (OOM) 错误,如下所示:

该模型不适合 GPU 内存的一个关键原因是模型的 Adam 优化器状态消耗 18GB;32GB RAM 的很大一部分。通过使用 ZeRO 第 1 阶段将优化器状态划分为八个数据并行列,每个设备的内存消耗可以减少到 2.25GB,从而使模型可训练。要启用 ZeRO 阶段 1,我们只需更新 DeepSpeed JSON 配置文件,如下所示:
<span style="background-color:#263238"><span style="color:#eeffff"><code><span style="color:#eeffff">{</span>
<span style="color:#eeffff">"zero_optimization"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"stage"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"reduce_bucket_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">5e8</span>
<span style="color:#eeffff">}</span>
<span style="color:#eeffff">}</span>
</code></span></span>如上所示,我们在zero_optimization键中设置了两个字段。具体来说,我们将stage字段设置为 1,并将梯度缩减的可选reduce_bucket_size设置为 500M。启用 ZeRO stage 1 后,该模型现在可以在 8 个 GPU 上顺利训练,而不会耗尽内存。下面我们提供一些模型训练的截图:


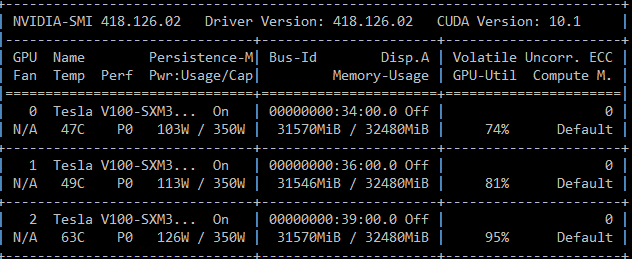
从nvidia-smi上面的屏幕截图我们可以看到,只有 GPU 6-7 用于训练模型。使用 ZeRO stage 1,我们可以通过提高数据并行度来进一步降低每台设备的内存消耗。这些内存节省可用于增加模型大小和/或批量大小。相比之下,单靠数据并行性无法实现此类优势。
训练 10B 参数 GPT-2 模型固定链接
ZeRO 第 2 阶段优化进一步增加了可以使用数据并行性进行训练的模型的大小。我们通过使用 32 个 V100 GPU 训练具有 10B 个参数的模型来展示这一点。
首先,我们需要配置一个启用了激活检查点的 10B 参数模型。这可以通过将以下 GPT-2 模型配置更改应用于 DeepSpeed 启动脚本来完成。
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#89ddff">--model-parallel-size</span> 1 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--num-layers</span> 50 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--hidden-size</span> 4096 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--num-attention-heads</span> 32 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--batch-size</span> 1 <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--deepspeed_config</span> ds_zero_stage_2.config <span style="color:#f78c6c">\</span>
<span style="color:#89ddff">--checkpoint-activations</span>
</code></span></span>接下来,我们需要更新 DeepSpeed JSON 配置,如下所示,以启用 ZeRO 阶段 2 优化:
<span style="background-color:#263238"><span style="color:#eeffff"><code><span style="color:#eeffff">{</span>
<span style="color:#eeffff">"zero_optimization"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"stage"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">2</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"contiguous_gradients"</span><span style="color:#eeffff">:</span> <span style="color:#c792ea">true</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"overlap_comm"</span><span style="color:#eeffff">:</span> <span style="color:#c792ea">true</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"reduce_scatter"</span><span style="color:#eeffff">:</span> <span style="color:#c792ea">true</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"reduce_bucket_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">5e8</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"allgather_bucket_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">5e8</span>
<span style="color:#eeffff">}</span>
<span style="color:#eeffff">}</span>
</code></span></span>在上述更改中,我们将stage字段设置为 2,并配置了 ZeRO 阶段 2 中可用的其他优化旋钮。例如,我们启用了contiguous_gradients减少反向传递期间的内存碎片。此处提供了这些优化旋钮的完整描述。通过这些更改,我们现在可以启动训练运行。
这是训练日志的屏幕截图:

这是 nvidia-smi 的屏幕截图,显示了训练期间的 GPU 活动:
使用 ZeRO-Infinity 训练万亿级模型
ZeRO-3 是 ZeRO 的第三个阶段,它对整个模型状态(即权重、梯度和优化器状态)进行分区,以根据数据并行度线性扩展内存节省。可以在 JSON 配置中启用 ZeRO-3。此处提供了这些配置的完整描述。
使用 ZeRO-Infinity 卸载到 CPU 和 NVMe
ZeRO-Infinity 使用 DeepSpeed 的无限卸载引擎将整个模型状态卸载到 CPU 或 NVMe 内存,从而允许更大的模型尺寸。可以在 DeepSpeed 配置中启用卸载:
<span style="background-color:#263238"><span style="color:#eeffff"><code><span style="color:#eeffff">{</span>
<span style="color:#eeffff">"zero_optimization"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"stage"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">3</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"contiguous_gradients"</span><span style="color:#eeffff">:</span> <span style="color:#c792ea">true</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"stage3_max_live_parameters"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e9</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"stage3_max_reuse_distance"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e9</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"stage3_prefetch_bucket_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e7</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"stage3_param_persistence_threshold"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e5</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"reduce_bucket_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e7</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"sub_group_size"</span><span style="color:#eeffff">:</span> <span style="color:#f78c6c">1e9</span><span style="color:#eeffff">,</span>
<span style="color:#eeffff">"offload_optimizer"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"device"</span><span style="color:#eeffff">:</span> <span style="color:#c3e88d">"cpu"</span>
<span style="color:#eeffff">},</span>
<span style="color:#eeffff">"offload_param"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"device"</span><span style="color:#eeffff">:</span> <span style="color:#c3e88d">"cpu"</span>
<span style="color:#eeffff">}</span>
<span style="color:#eeffff">}</span>
<span style="color:#eeffff">}</span>
</code></span></span>ZeRO-Infinity 与 ZeRO-Offload: DeepSpeed 首先包括 ZeRO-Offload 的卸载功能,ZeRO-Offload 是一种用于将优化器和梯度状态卸载到 ZeRO-2 中的 CPU 内存的系统。ZeRO-Infinity 是 ZeRO-3 可访问的下一代卸载功能。ZeRO-Infinity 能够比 ZeRO-Offload 卸载更多的数据,并且具有更有效的带宽利用率和计算与通信的重叠。
分配 Massive Megatron-LM 模型固定链接
我们对模型初始化进行了两项进一步更改,以支持超过本地系统内存但不超过总系统内存的模型。
-
以内存可扩展的方式分配模型。模型参数将被分配并立即在数据并行组中进行分区。如果
remote_device是"cpu"或"nvme",模型也将分配在 CPU/NVMe 内存中,而不是 GPU 内存中。有关详细信息,请参阅完整的ZeRO-3 Init 文档。<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#c792ea">with</span> <span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">.</span><span style="color:#eeffff">zero</span><span style="color:#eeffff">.</span><span style="color:#eeffff">Init</span><span style="color:#eeffff">(</span><span style="color:#eeffff">data_parallel_group</span><span style="color:#89ddff">=</span><span style="color:#eeffff">mpu</span><span style="color:#eeffff">.</span><span style="color:#eeffff">get_data_parallel_group</span><span style="color:#eeffff">(),</span> <span style="color:#eeffff">remote_device</span><span style="color:#89ddff">=</span><span style="color:#eeffff">get_args</span><span style="color:#eeffff">().</span><span style="color:#eeffff">remote_device</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">enabled</span><span style="color:#89ddff">=</span><span style="color:#eeffff">get_args</span><span style="color:#eeffff">().</span><span style="color:#eeffff">zero_stage</span><span style="color:#89ddff">==</span><span style="color:#f78c6c">3</span><span style="color:#eeffff">):</span> <span style="color:#eeffff">model</span> <span style="color:#89ddff">=</span> <span style="color:#eeffff">GPT2Model</span><span style="color:#eeffff">(</span><span style="color:#eeffff">num_tokentypes</span><span style="color:#89ddff">=</span><span style="color:#f78c6c">0</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">parallel_output</span><span style="color:#89ddff">=</span><span style="color:#eeffff">True</span><span style="color:#eeffff">)</span> </code></span></span> -
收集用于初始化的嵌入权重。DeepSpeed 将在其构造函数期间自动收集模块的参数,并用于前向和后向传递。但是,额外的访问必须与 DeepSpeed 协调以确保收集参数数据并随后对其进行分区。如果修改了张量,
modifier_rank则还应使用该参数来确保所有等级对数据的看法一致。有关详细信息,请参阅完整的GatheredParameters 文档。<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">position_embeddings</span> <span style="color:#89ddff">=</span> <span style="color:#eeffff">torch</span><span style="color:#eeffff">.</span><span style="color:#eeffff">nn</span><span style="color:#eeffff">.</span><span style="color:#eeffff">Embedding</span><span style="color:#eeffff">(...)</span> <span style="color:#c792ea">with</span> <span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">.</span><span style="color:#eeffff">zero</span><span style="color:#eeffff">.</span><span style="color:#eeffff">GatheredParameters</span><span style="color:#eeffff">(</span><span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">position_embeddings</span><span style="color:#eeffff">.</span><span style="color:#eeffff">weight</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">modifier_rank</span><span style="color:#89ddff">=</span><span style="color:#f78c6c">0</span><span style="color:#eeffff">):</span> <span style="color:#b2ccd6"># Initialize the position embeddings. </span> <span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">init_method</span><span style="color:#eeffff">(</span><span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">position_embeddings</span><span style="color:#eeffff">.</span><span style="color:#eeffff">weight</span><span style="color:#eeffff">)</span> <span style="color:#eeffff">...</span> <span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">tokentype_embeddings</span> <span style="color:#89ddff">=</span> <span style="color:#eeffff">torch</span><span style="color:#eeffff">.</span><span style="color:#eeffff">nn</span><span style="color:#eeffff">.</span><span style="color:#eeffff">Embedding</span><span style="color:#eeffff">(...)</span> <span style="color:#c792ea">with</span> <span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">.</span><span style="color:#eeffff">zero</span><span style="color:#eeffff">.</span><span style="color:#eeffff">GatheredParameters</span><span style="color:#eeffff">(</span><span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">tokentype_embeddings</span><span style="color:#eeffff">.</span><span style="color:#eeffff">weight</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">modifier_rank</span><span style="color:#89ddff">=</span><span style="color:#f78c6c">0</span><span style="color:#eeffff">):</span> <span style="color:#b2ccd6"># Initialize the token-type embeddings. </span> <span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">init_method</span><span style="color:#eeffff">(</span><span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">tokentype_embeddings</span><span style="color:#eeffff">.</span><span style="color:#eeffff">weight</span><span style="color:#eeffff">)</span> </code></span></span>
以内存为中心的平铺固定链接
ZeRO-Infinity 包括层的替代品Linear,可进一步减少内存。我们可选择平铺模型平行线性层,在每个 Transformer 层中找到。注意,在构建层时指定相应的基类,可以将模型并行和平铺结合起来。该deepspeed.zero.TiledLinear模块利用 ZeRO-3 的数据获取和释放模式,通过将大型运算符分解为可按顺序执行的较小块来减少工作内存需求。
我们包括对 Megatron-LM 的ParallelMLP中一个示例的更改。另外三个模型并行层以transformer.py类似方式进行。
Megatron-LM 的模型并行层有一种特殊的形式,其中bias层的加法被延迟,而不是从forward()后面的运算符中返回以与后面的运算符融合。DeepSpeed的deepspeed.zero.TiledLinearReturnBias子类TiledLinear也简单的将返回的bias参数转发,不累加。
<span style="background-color:#263238"><span style="color:#eeffff"><code><span style="color:#eeffff">@@ -1,6 +1,9 @@</span>
<span style="color:#f07178">-self.dense_h_to_4h = mpu.ColumnParallelLinear(
</span><span style="color:#c3e88d">+self.dense_h_to_4h = deepspeed.zero.TiledLinearReturnBias(
</span> args.hidden_size,
4 * args.hidden_size,
<span style="color:#c3e88d">+ in_splits=args.tile_factor,
+ out_splits=4*args.tile_factor,
+ linear_cls=mpu.ColumnParallelLinear,
</span> gather_output=False,
init_method=init_method,
skip_bias_add=True)
</code></span></span>请注意,我们使用in_splits和out_splits按比例缩放input_size和output_size。这会产生固定大小的图块[hidden/tile_factor, hidden/tile_factor]。
注册外部参数固定链接
已弃用: DeepSpeed 版本0.3.15引入了自动外部参数注册,不再需要此步骤。
提取权重固定链接
如果您需要从 Deepspeed 中取出预训练权重,您可以通过以下方式获取 fp16 权重:
- 在 ZeRO-2 下,
state_dict包含 fp16 模型权重,这些可以正常保存torch.save。 - 在 ZeRO-3 下,
state_dict仅包含占位符,因为模型权重是跨多个 GPU 分区的。如果你想获得这些权重,请启用:
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#eeffff">"zero_optimization"</span><span style="color:#eeffff">:</span> <span style="color:#eeffff">{</span>
<span style="color:#eeffff">"stage3_gather_16bit_weights_on_model_save"</span><span style="color:#eeffff">:</span> <span style="color:#c792ea">true</span>
<span style="color:#eeffff">}</span><span style="color:#f07178">,</span>
</code></span></span>然后使用以下方法保存模型:
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#c792ea">if</span> <span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">:</span>
<span style="color:#eeffff">self</span><span style="color:#eeffff">.</span><span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">.</span><span style="color:#eeffff">save_16bit_model</span><span style="color:#eeffff">(</span><span style="color:#eeffff">output_dir</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">output_file</span><span style="color:#eeffff">)</span>
</code></span></span>因为它需要在一个 GPU 上整合权重,所以它可能很慢并且需要内存,所以只在需要时使用此功能。
请注意,如果stage3_gather_16bit_weights_on_model_save是False,则不会保存任何权重(同样,因为state_dict没有它们)。您也可以使用此方法保存 ZeRO-2 权重。
如果您想获得 fp32 权重,我们提供了一个可以进行离线合并的特殊脚本。它不需要配置文件或 GPU。下面是它的用法示例:
<span style="background-color:#263238"><span style="color:#eeffff"><code><span style="color:#f07178">$ </span><span style="color:#eeffff">cd</span> /path/to/checkpoint_dir
<span style="color:#f07178">$ </span>./zero_to_fp32.py <span style="color:#eeffff">.</span> pytorch_model.bin
Processing zero checkpoint at global_step1
Detected checkpoint of <span style="color:#eeffff">type </span>zero stage 3, world_size: 2
Saving fp32 state dict to pytorch_model.bin <span style="color:#89ddff">(</span><span style="color:#f07178">total_numel</span><span style="color:#89ddff">=</span>60506624<span style="color:#89ddff">)</span>
</code></span></span>zero_to_fp32.py保存检查点时会自动创建脚本。
注意:目前此脚本使用最终检查点大小的 2 倍内存(通用 RAM)。
或者,如果您有足够的空闲 CPU 内存,而不是获取您希望将模型更新到其 fp32 权重的文件,您可以在训练结束时执行以下操作:
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#89ddff">from</span> <span style="color:#ffcb6b">deepspeed.utils.zero_to_fp32</span> <span style="color:#89ddff">import</span> <span style="color:#eeffff">load_state_dict_from_zero_checkpoint</span>
<span style="color:#eeffff">fp32_model</span> <span style="color:#89ddff">=</span> <span style="color:#eeffff">load_state_dict_from_zero_checkpoint</span><span style="color:#eeffff">(</span><span style="color:#eeffff">deepspeed</span><span style="color:#eeffff">.</span><span style="color:#eeffff">module</span><span style="color:#eeffff">,</span> <span style="color:#eeffff">checkpoint_dir</span><span style="color:#eeffff">)</span>
</code></span></span>请注意,该模型适合保存,但不再适合继续训练,需要deepspeed.initialize()重新训练。
如果你只想要state_dict,你可以这样做:
<span style="background-color:#263238"><span style="color:#eeffff"><code> <span style="color:#89ddff">from</span> <span style="color:#ffcb6b">deepspeed.utils.zero_to_fp32</span> <span style="color:#89ddff">import</span> <span style="color:#eeffff">get_fp32_state_dict_from_zero_checkpoint</span>
<span style="color:#eeffff">state_dict</span> <span style="color:#89ddff">=</span> <span style="color:#eeffff">get_fp32_state_dict_from_zero_checkpoint</span><span style="color:#eeffff">(</span><span style="color:#eeffff">checkpoint_dir</span><span style="color:#eeffff">)</span>
</code></span></span>恭喜!您已完成零教程。