在优化 ArchGuard 的 AI 辅助架构治理工具 Co-mate 的架构时,发现有一些模式与之前设计 AutoDev、ClickPrompt 等颇为相似。便思考着适合于 ArchGuard Co-mate 的架构设计原则是什么,写下了初步的三条原则。
而正好要在公司内分享 LLM + 架构,便又整理了适合于更通用的四个架构设计原则。以此作为一个参考的架构原则基础,方便于我后续设计其它的 LLM 为核心的软件架构。

TL;DR 版本:
用户意图导向设计。设计全新的人机交互体验,构建领域特定的 AI 角色,以更好地理解用户的意图。简单来说,寻找更适合于理解人类意图的的交互方式。
上下文感知。构建适合于获取业务上下文的应用架构,以生成更精准的 prompt,并探索高响应速度的工程化方式。即围绕高质量上下文的 Prompt 工程。
原子能力映射。分析 LLM 所擅长的原子能力,将其与应用所欠缺的能力进行结合,进行能力映射。让每个 AI 做自己擅长的事,诸如于利用好 AI 的推理能力。
语言 API。探索和寻找合适的新一代 API ,以便于 LLM 对服务能力的理解、调度与编排。诸如自然语言作为人机 API,DSL 作为 AI 与机器间的 API 等。
作为一个参考性的架构原则,它在不同的场景之下是需要经过一定裁剪的。以上仅是一些初始想法,还需要进一步的研究和实践来完善。
引子:ArchGuard Co-mate 的三个设计架构原则
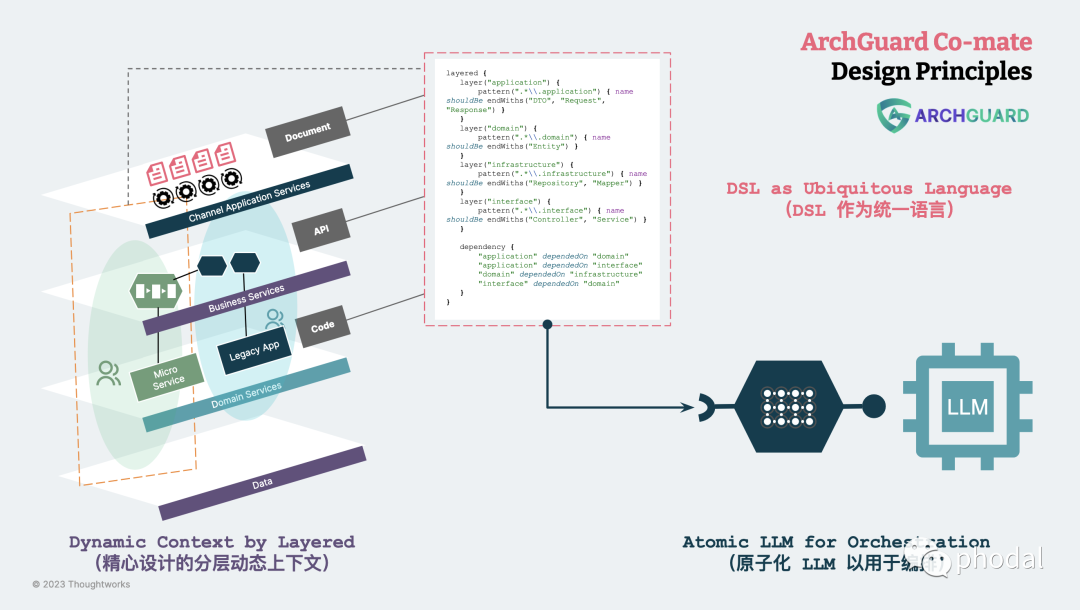
Co-mate 是基于 ArchGuard 的分析能力所构建的,并且是以 DSL、规范文档为核心来构建的。所以,我们设计了三条初步的设计原则:
DSL 作为统一语言。通过使用领域特定语言(DSL)来增强人机交互,实现高效的人机、机机、机人交流。
原子化 LLM 以用于编排。利用语言模型(LLM)的原子能力,在 DSL 中构建复杂的行为。即我们在上一篇文章《规范即治理函数》提到基于 LLM 原子能力的动态函数生成。
精心设计的分层动态上下文。通过将上下文分为不同的层次,使用 LLM 有效地处理复杂性。
总体关系如下图所示:
在 Co-mate 中,我们采用了 Kotlin Type-safe Builder 封装了基础的函数功能,以让 LLM 能根据文档、规范来编排治理函数。
原规范如下所示:
- 代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
- 代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式,正确的英文拼写和语法可以让阅读者易于理解,避免歧义。
- 类名使用 UpperCamelCase 风格,必须遵从驼峰形式。正例: HelloWorld。示例 DSL 如下所示:
naming {
class_level {
style("CamelCase")
pattern(".*") { name shouldNotBe contains("$") }
}
function_level {
style("CamelCase")
pattern(".*") { name shouldNotBe contains("$") }
}
}中间的文档转换 DSL 的过程就交给 LLM 来动态处理和生成(进行中)。有了这个基础,我们会发现它与我们先前开源的基于 LLM 的应用,在架构上并没有太多的区别。只是利用的能力有所差异,而又由于交互还没到我们的核心。所以,我添加了一条:用户意图导向设计。
LLM 优先的软件架构设计原则
LLM 对于开发人员、架构师来说,即充满了机遇,又充满了挑战。诸如于:LLM 如何辅助架构设计、如何构建基于 LLM 的架构、如何让 LLM 引导架构设计以及如何构建 LLM 为核心的软件架构。

不同的模式之下,对于现有的流程和软件都会带来不少的冲击。基于 Thoughtworks 内部的一系列探索、基于 LLM 的软件架构和总结,我重新思考了四个原则:
用户意图导向设计。
上下文感知。
原子能力映射。
语言 API。
详细展开如下。
1. 用户意图导向设计
如我们所熟悉的一样,现有的应用都以 Chat 方式作为 LLM 的入口之一,而 Chat 的本意是去理解用户的意图,诸如于:“帮我写一篇文章介绍设计原则”。这里的意图就很直接,而为了让用户更好地去表达自己的意图,就需要有意地去引导用户的输入。
在这里,就会呈现不同的引导方式或者封装方式,诸如于封装菜单为指令、封装指令为 prompt、基于用户输入解析成 UI 等等。
为了更好地理解用户意图,我们需要考虑:设计全新的人机交互体验。
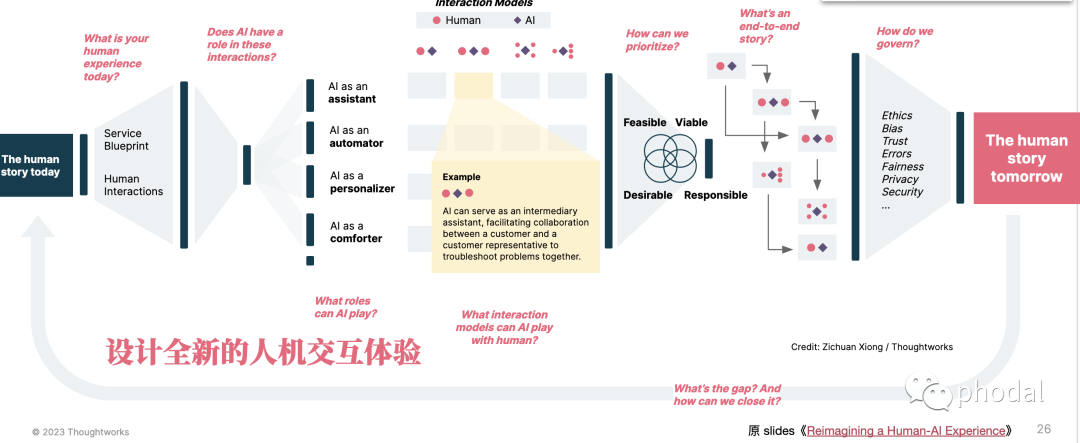
总结:通过设计全新的人机交互体验,构建领域特定的 AI 角色,以更好地理解用户的意图。例如,在聊天应用程序中,AI 可以使用自然语言处理来理解用户的意图,从而更好地回答用户的问题。除此之外,还可以探索其他交互方式,如语音识别、手势识别等,以提高用户体验。
2. 上下文感知
在先前的文章里,我们一直在强调上下文工程的重要性。我们原先对其的定义是:上下文工程是一种让 LLM 更好地解决特定问题的方法。它的核心思想是,通过给 LLM 提供一些有关问题的背景信息,比如指令、示例等,来激发它生成我们需要的答案或内容。
而在包含了业务场景的情况下,我们要考虑的是围绕于上下文工程的软件架构。诸如于在 ArchGuard Co-mate 里,我们的思路是:通过分层方法来构建动态的上下文。其原因也主要是:我们对于某个用户意图的理解会存在不同的架构层次里,如业务架构、技术架构、代码等。
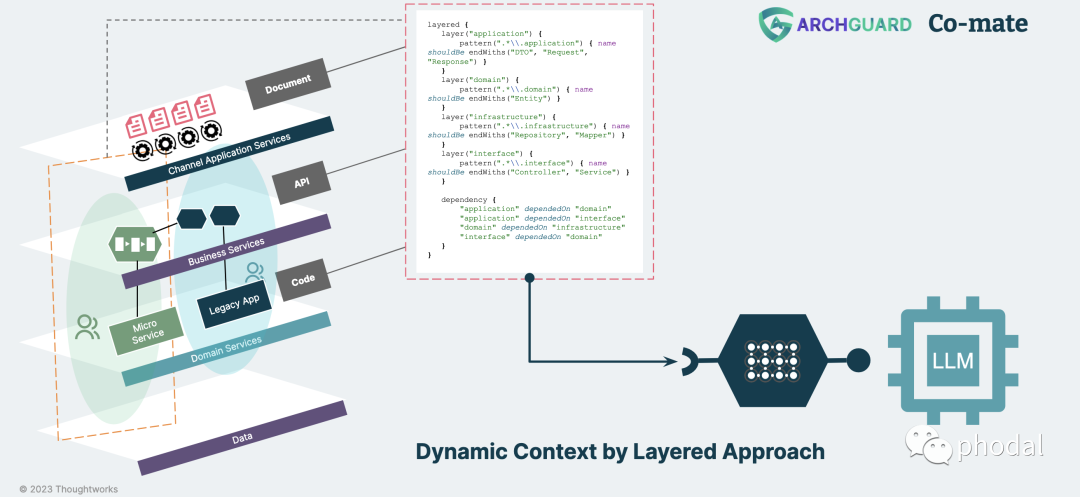
总结:通过构建适合于获取业务上下文的应用架构,以生成更精准的 prompt,并探索高响应速度的工程化方式。即围绕高质量上下文的 Prompt 工程。例如,在一个电商应用程序中,AI 可以了解用户的购物历史记录、浏览历史记录等上下文信息,以提供更好的购物建议。
3. 原子能力映射
起初,大部分结合 OpenAI 的应用,都是让 LLM 直接生成 JSON、Yaml 的形式。但是呢,在我们尝试了 3000 条左右的 PlantUML 生成之后,发现有 20% 的概率生成的 UML 是错误的,不可编译的。正是这种场景,让我们思考了 LLM 是否适合去做这样的事情。
而在架构治理治理之下,我们将其定义为:借助 LLM 原子能力显性化架构知识,映射和构建治理函数,动态度量不同场景。
在日常的业务场景里,对于 LLM 的能力分析也是非常重要的一环,诸如于我们不应该让 LLM 进行数学计算,而是通过诸如 Functions Calling 的方式,将意图与系统的功能相结合。
所以,我们分解了 LLM 的能力,按照不同的方式与系统结合在一起。
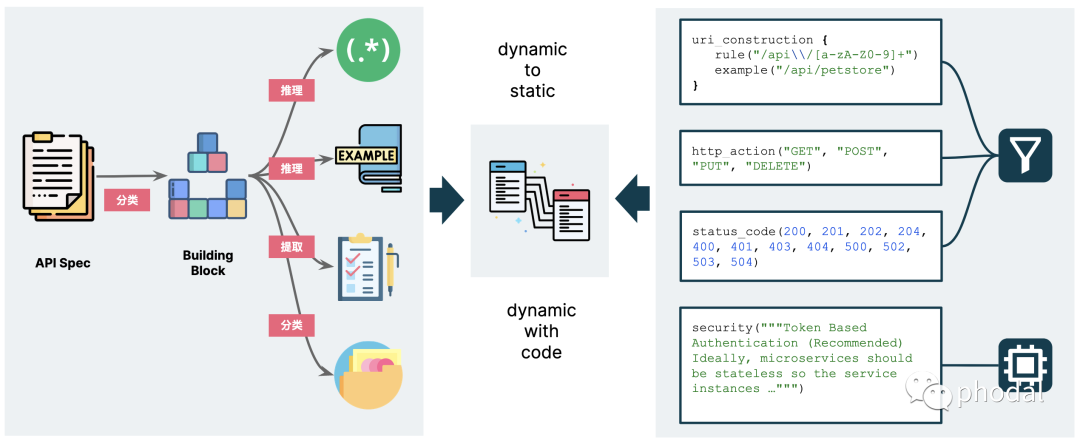
总结:我们需要分析 LLM 所擅长的原子能力,将其与应用所欠缺的能力进行结合,进行能力映射。让每个 AI 做自己擅长的事,诸如于利用好 AI 的推理能力。例如,在一个智能家居应用程序中,AI 可以根据用户的行为自动调整室内温度、光线等,以提供更好的家居体验。
4. 语言 API
在我与诸多架构师讨论之后,我们几乎达到了一个一致意见:我们需要一种新的 API,一种适合于 LLM 的 API。
它或许是一类基于语言的 API。对于人与机器、机器与机器来说,是我们熟悉的诸如于 JSON、YAML 或者其它自定义的 DSL;对于人与机器来说,这个语言 API 是自然语言,又或者是图形等方式。
当我们可视化了自己的软件架构之后,你会发现这一点特别的明显。
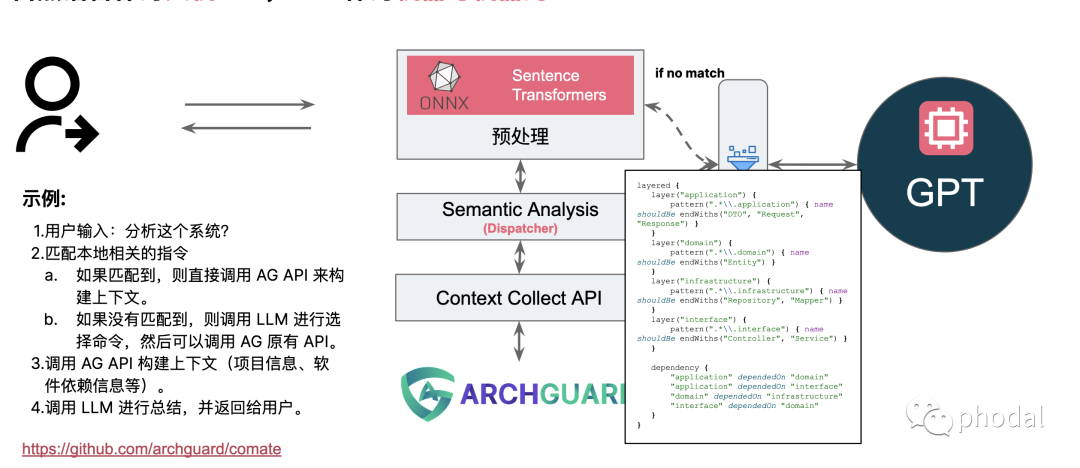
总结:我们需要探索和寻找合适的新一代 API ,以便于 LLM 对服务能力的理解、调度与编排。诸如自然语言作为人机 API,DSL 作为 AI 与机器间的 API 等。例如,在一个在线客服应用程序中,AI 可以使用自然语言处理来理解客户的问题,并根据问题的类型和紧急程度自动分配给不同的客服代表。
总结
来自不成熟的 Notion AI 的总结:
本文介绍了基于 LLM 的软件架构设计原则,包括用户意图导向设计、上下文感知、原子能力映射和语言 API。通过设计全新的人机交互体验、构建适合于获取业务上下文的应用架构、分析 LLM 所擅长的原子能力和探索和寻找合适的新一代 API,可以更好地利用 LLM 辅助架构设计、构建基于 LLM 的架构、让 LLM 引导架构设计以及构建 LLM 为核心的软件架构。