一、PinYin4j库简介
1、PinYin4j简介
Pinyin4j 是一个流行的 Java 库,支持汉字和大多数流行的拼音系统之间的转换(汉语拼音,罗马拼音等)。可自定义拼音输出格式,功能强大。
官网地址:http://pinyin4j.sourceforge.net/
在线文档:http://pinyin4j.sourceforge.net/pinyin4j-doc/
2、Pinyin4j支持方式:
- 支持简体中文和繁体中文字符。
- 支持转换到汉语拼音,通用拼音,威妥玛拼音(威玛拼法),注音符号第二式,耶鲁拼法和国语罗马字母。
- 支持多音字,即可以获取一个中文字符的多种发音。
- 支持多种字符串输出格式,比如支持Unicode格式的字符ü和声调符号(阴平ˉ”,阳平"ˊ",上声"ˇ",去声"ˋ")的输出。
3、Pinyin4j支持多种格式:
Pinyin4j 提供了几个实用程序函数,用于将中文字符(简体和繁体)转换为各种中文罗马化表示。
- HanyuPinyinOutputFormat:这个类定义了如何输出汉语拼音。
- HanyuPinyinCaseType:为汉语拼音字符串的输出案例提供了几种选项。
- HanyuPinyinToneType:该类提供了几种输出中文音调的选项。
- HanyuPinyinVCharType:这个类为’ü’的输出提供了几个选项。
4、单元测试可以操作一下这几个方法:
引入依赖:
<!-- pinyin4j-->
<dependency>
<groupId>com.belerweb</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.1</version>
</dependency>
/**
* 测试 pinyin4j库原生方法
* @param chinese
*/
private static void testPinyin4j(String chinese) {
char[] arr = "汉语".toCharArray();
HanyuPinyinOutputFormat pinyinOutputFormat = new HanyuPinyinOutputFormat();
pinyinOutputFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
pinyinOutputFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
try {
System.out.println("toHanYuPinyinString -> " + PinyinHelper.toHanYuPinyinString(chinese, pinyinOutputFormat, "", true));
// 取第一个
System.out.println("toHanyuPinyinStringArray -> " + PinyinHelper.toHanyuPinyinStringArray(arr[0], pinyinOutputFormat)[0].charAt(0));
System.out.println("toHanyuPinyinStringArray -> " + PinyinHelper.toHanyuPinyinStringArray(arr[0])[0].charAt(0));
System.out.println("toTongyongPinyinStringArray -> " + PinyinHelper.toTongyongPinyinStringArray(arr[0])[0].charAt(0));
System.out.println("toYalePinyinStringArray -> " + PinyinHelper.toYalePinyinStringArray(arr[0])[0].charAt(0));
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
}
二、Pinyin4jUtil工具类
在项目中经常会遇到用户输入汉字后转换为拼音的需求场景,这时候Pinyin4j就派上用场了。
上一篇Java对中文进行排序使用到了它:https://blog.csdn.net/qq_42402854/article/details/127633147
下面创建一个Pinyin4jUtil工具类,来封装几个常用的方法。
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
/**
* 拼音工具类
*/
public class Pinyin4jUtil {
/**
* 获取中文串转汉语全拼。(支持多音字,英文字符和特殊字符都丢弃。)
*
* @param str 字符串,为null,返回“”
* @return 汉语全拼
*/
public static String getFullSpell(String str) {
String fullPinyin = "";
if (str == null) {
return fullPinyin;
}
HanyuPinyinOutputFormat pinyinOutputFormat = new HanyuPinyinOutputFormat();
/**
* 定义汉语拼音字符串的输出大小写:
* LOWERCASE(默认) - 表示汉语拼音作为大写字母输出
* UPPERCASE - 表示汉语拼音以小写字母输出
*/
pinyinOutputFormat.setCaseType(HanyuPinyinCaseType.UPPERCASE);
/**
*定义汉语拼音声调的输出格式:汉语有四个声调和一个“无音”音。它们被称为Píng(平坦),Shǎng(上升),Qù(高下降),Rù(下降)和Qing(无音调)。
* WITH_TONE_NUMBER(默认) - 表示汉语拼音以声调数字输出。比如:你说呢 - ni3 shuo1ni2
* WITHOUT_TONE - 该选项表示不输出音号或音标记的汉语拼音 比如:你说呢 - ni shuoni
* WITH_TONE_MARK - 表示输出带有音调标记的汉语拼音 比如:你说呢 - nĭshuōní
*/
pinyinOutputFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
try {
/**
* 获取一个字符串,其中所有的中文字符都被相应的主(第一)汉语拼音表示所取代。
* 参数:
* str - 中文串
* outputFormat - 描述返回的汉语拼音字符串的期望格式
* separate - 每个字的拼音使用什么分割符串显示。注意:分隔符不会出现在非中文字符之后。一般不使用任何分隔符("")时,大家都是紧挨着,看不出来的。
* retain - 是否保留不能转换为拼音的字符。true保留
*/
fullPinyin = PinyinHelper.toHanYuPinyinString(str, pinyinOutputFormat, " ", false);
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
return fullPinyin;
}
/**
* 获取中文串转汉语全拼。(支持多音字,英文字符和特殊字符都保留。)
*
* @param str 字符串,为null,返回“”
* @return 汉语全拼
*/
public static String getFullSpellAndStr(String str) {
String fullPinyin = "";
if (str == null) {
return fullPinyin;
}
HanyuPinyinOutputFormat pinyinOutputFormat = new HanyuPinyinOutputFormat();
pinyinOutputFormat.setCaseType(HanyuPinyinCaseType.UPPERCASE);
pinyinOutputFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
try {
// 保留不能转换为拼音的字符
fullPinyin = PinyinHelper.toHanYuPinyinString(str, pinyinOutputFormat, " ", true);
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
return fullPinyin;
}
/**
* 获取中文串转汉语全拼首字母。(支持多音字。英文字符和特殊字符都丢弃。)
*
* @param str 字符串,为null,返回“”
* @return 汉语全拼首字母
*/
public static String getFirstSpell(String str) {
StringBuilder firstPinyin = new StringBuilder();
if (str == null) {
return firstPinyin.toString();
}
HanyuPinyinOutputFormat pinyinOutputFormat = new HanyuPinyinOutputFormat();
pinyinOutputFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
pinyinOutputFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
// 获取中文
String chinese = getChinese(str);
char[] arr = chinese.toCharArray();
for (int i = 0; i < arr.length; i++) {
try {
// 获取单个汉字的全拼,取首字母
String[] temp = PinyinHelper.toHanyuPinyinStringArray(arr[i], pinyinOutputFormat);
if (temp != null) {
firstPinyin.append(temp[0].charAt(0));
}
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
}
return firstPinyin.toString();
}
/**
* 获取中文。(除中文之外,其他字符丢弃。)
* @param str
*/
public static String getChinese(String str) {
if (str == null) {
return "";
}
String regex = "[^\u4e00-\u9fa5]"; // 匹配非中文字符
return str.replaceAll(regex, ""); // 替换非中文字符为空字符串
}
public static void main(String[] args) {
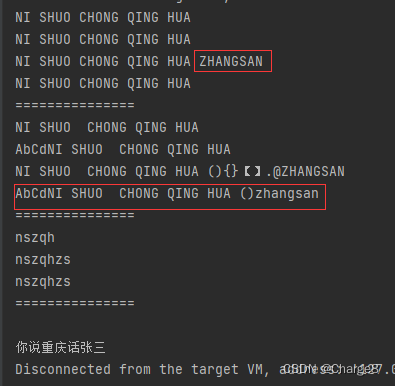
System.out.println(getFullSpell("你说 重庆话"));
System.out.println(getFullSpell("AbCd你说 重庆话"));
System.out.println(getFullSpell("你说 重庆话(){}【】.@张三")); // NI SHUO CHONG QING HUA ZHANGSAN 注意:张三没有按分隔符分隔。因为它在非中文之后
System.out.println(getFullSpell("AbCd你说 重庆话()zhangsan"));
System.out.println("===============");
System.out.println(getFullSpellAndStr("你说 重庆话"));
System.out.println(getFullSpellAndStr("AbCd你说 重庆话"));
System.out.println(getFullSpellAndStr("你说 重庆话(){}【】.@张三")); // NI SHUO CHONG QING HUA (){}【】.@ZHANGSAN
System.out.println(getFullSpellAndStr("AbCd你说 重庆话()zhangsan"));
System.out.println("===============");
System.out.println(getFirstSpell("你说 重庆话"));
System.out.println(getFirstSpell("你说 重庆话张三"));
System.out.println(getFirstSpell("你说 重庆话(){}【】.@张三"));
System.out.println("===============");
System.out.println(getChinese(""));
System.out.println(getChinese("AbCd你说 重庆话(){}【】.@张三zhangsan"));
}
}
– 求知若饥,虚心若愚。