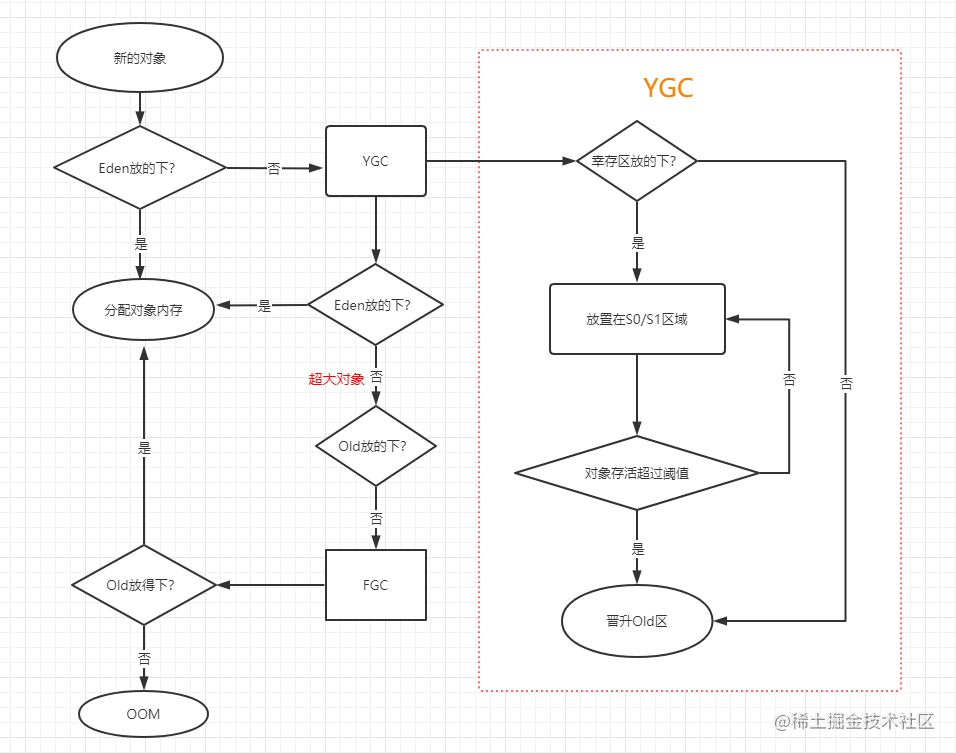
文章目录
- 一、大模型训练太难了
- 二、大模型的训练有三大难点
- 三、OpenAI 的一些启发
一、大模型训练太难了
这里大模型训练特指基座大模型的从0开始训练,不包括在2000条数据上SFT这样的小任务。
有人说大模型嘛,简单,给我卡就行,等到老板真给你买来了1000张卡你就知道有多难了,老板说,小王,卡买来了,三个月给我搞出来。
然后你发现,就算有人把正确的代码,数据,参数全告诉你,你也就够完整跑一次把它训练出来,万一中间服务器停电一次,完蛋交不了活儿了。
更别提你要自己写模型代码,调试,想办法评估模型,根据结果反馈调整实验方向,时间和资源完全不够!
确实,从头开始训练一个大型模型是一项艰巨的任务,需要大量的计算资源、时间和专业知识。以下是一些可能遇到的挑战:
- 计算资源:训练大型模型需要大量的计算资源,包括高性能的图形处理单元(GPU)或专用的张量处理单元(TPU)。在没有足够计算资源的情况下,训练过程可能会非常缓慢或无法完成。
- 数据准备:训练大型模型需要大规模的数据集,而且数据集的质量对于最终模型的性能至关重要。收集、清理和准备数据可能是一项繁琐的工作,特别是对于特定任务或领域的数据集。
- 超参数调整:大型模型通常有很多超参数需要调整,如学习率、批量大小、层数等。找到最佳的超参数组合可能需要进行大量的试验和调优。
- 模型设计和调试:设计和实现适合特定任务的模型结构需要深入的专业知识和经验。调试模型中的错误或性能问题可能是一项复杂的任务。
- 训练时间:训练大型模型可能需要数天甚至数周的时间,这取决于模型的规模、数据集的大小以及计算资源的可用性。在训练过程中发生中断或错误可能导致需要重新开始训练。
- 模型评估和迭代:评估训练出的模型性能是关键的一步,可能需要进行多轮迭代来改进模型。这需要根据评估结果进行调整实验方向和参数设置。
总之,从零开始训练一个大型模型需要面对多个挑战,包括计算资源、数据准备、超参数调整、模型设计和调试、训练时间以及模型评估和迭代。这需要丰富的经验、时间和资源投入,以及对机器学习和深度学习的深入理解。

二、大模型的训练有三大难点
- 消耗计算资源巨大。
- 对数据的数量和数据的质量要求极高。
- 很难用技术指标进行评估他的好坏。
在传统的深度学习时代,人们热衷于对网络架构进行各种修改和排列组合,试图通过手动调整来优化模型性能。然而,随着进入大型模型时代,这种方法已经不再奏效。
过去的实验通常在单个V100 GPU上运行,最多需要半天的时间完成。研究人员会在多个GPU上同时尝试多个模型配置,并通过实验结果的观察和评估来调整下一步的方向。
然而,进入大型模型时代后,他们发现这种基于直觉和手动修改的方法行不通了。
首先,进行实验需要数百个A100 80GB GPU,并且还需要准备10TB的数据。同时,数据集必须经过精心清洗,以确保数据的质量。这样的实验设置决定了实验的速度变得非常缓慢。
此外,一个关键问题是,很难确定一个合适的评估指标来衡量模型的好坏。这就像盲目地炒菜,无法确定最终的味道,试验过程中完全是一片模糊。
总而言之,以上提到的三个主要困难因素使得实验变得缓慢、不可靠、困难且结果不确定。大型模型的训练相较于传统的小型模型来说,面临更多的挑战和复杂性。
随着模型规模和复杂度的增加,试错成本也随之增加。这使得手动调整和炼丹的方式逐渐无法满足大规模模型训练的需求,进一步推动了大规模工业化训练的发展。
以META AI训练OPT-175B(对应于GPT-3的规模)为例,他们的经验教训可以提供一些洞见。
他们由一个由5名工程师组成的小组,使用1024张A100(80GB显存)的GPU对175B参数的语言模型进行训练。整个训练过程大约耗时三个月。
根据他们的训练效率预估,在没有发生错误和重启的情况下,使用300B个标记的数据集进行训练将需要大约33天的时间。
这个例子揭示了大规模模型训练的复杂性和资源需求。它需要庞大的计算资源、长时间的训练周期以及大规模高质量的数据集。这些因素使得大规模模型训练成为一个挑战,需要充足的计算资源、高效的算法和合理的时间规划来取得良好的训练效果。
在第一轮训练中,通常会进行初步的训练尝试,这可能涉及多次启动和停止训练过程。在这个阶段,根据经验和假设,会设定模型和训练超参数,并对其进行简单调整。例如,增加权重衰减(weight decay)从0.01到0.1、设置全局梯度范数剪裁为1.0、调整Adam优化器的参数等等。
这些调整是基于观察每个批次的损失结果而进行的。然而,他们发现这些调整实际上没有太大意义,因为他们发现自己的代码存在错误(非常遗憾,在前三次训练中白白浪费了时间)。因此,他们认识到在小规模数据集和模型参数上对代码进行测试是非常重要的。
通过在小规模的数据集和模型参数上进行测试,可以帮助发现和修复代码中的错误,确保代码的正确性。这个阶段的目标是确保训练过程正常运行,并获得可靠的结果,以便在后续的训练中建立在稳固的基础上进行。
在第二轮中,会进行超参数的调整。根据观察和反复实验,确认哪些参数对模型效果更有效。这个过程非常考验观察能力和经验,需要不断地调整和优化参数设置。
第三轮开始了正式的训练,超过一个月的时间已经过去。在训练过程中,仍然观察损失曲线的变化(可能会出现许多尖峰),并不断地调整参数。特别是在Run11.6之后,会反复重新计算相同一段批次数据,观察不同超参数对结果的影响。在Run11.10甚至会更换激活函数,从Gelu改为ReLU。
在第四轮(也可以称为“最后”一轮)中,使用了33天的时间,使用992张80GB显存的A100 GPU,训练了拥有175B参数和300B标记的模型。然而,在这个过程中遇到了许多问题,包括但不限于:GPU掉线、CUDA错误、任务挂起、NCCL错误、代码错误(例如检查点存储问题、损失函数问题)以及训练不稳定的情况。这表明即使拥有丰富的经验、充足的数据集和庞大的硬件资源,训练大型模型仍然充满了各种困难和挑战。
即使像OpenAI这样的组织在训练GPT-4时也面临了巨大的困扰。为了应对这个挑战,他们采用了一些元学习(meta-learning)的方法,利用小型模型的表现来预测更大规模模型的表现。
这种方法在直觉上是可行的,但它确实是一种无奈之举。由于大型模型的训练是极其耗时和资源密集型的,无法进行大规模的试错和优化。因此,利用小型模型的训练结果作为参考来预测大型模型的性能,可以为研究人员提供一些指导和启示。
虽然这种方法可能有一定的效果,但仍然存在预测的不确定性和局限性。毕竟,大型模型具有自身的复杂性和特殊性,无法完全依靠小型模型的结果进行准确预测。因此,即使这是一种权宜之计,仍然需要在实际训练中进行验证和调整,以获得最佳的结果。
三、OpenAI 的一些启发
OpenAI在GPT的发展过程中花费了大量时间和精力,经过反复的实验和探索,才逐步积累了宝贵的经验并取得了突破。这是因为训练大型模型是一个复杂而艰巨的任务,需要经过大量的试错和优化才能取得成功。
至于中文数据方面的问题,确实存在一些挑战。由于中文互联网的特殊性,中文优质语料相对较少,这使得获取高质量的中文数据变得困难。虽然有一些观点认为这是一种甩锅的说法,但实际情况可能更多是技术和资源的限制。OpenAI使用公开获取的中文数据进行训练的能力,可能也取决于他们对数据的处理和利用能力。
目前,即使国内的公司购买了大量难以公开获取的数据,仍然远远落后于OpenAI的进展。这一点确实反映了大型模型时代中,实践经验和训练方法的重要性。拥有能够总结出一套有效的训练方法论的专业人才,以及那些拥有丰富实践经验并完成了大量实验的技术专家,是大型模型时代中最宝贵的资源。相比于硬件设备和时间的成本,人才的贡献往往更具决定性的影响,并且难以替代。