Vision Transformer综述
- 1. Transformer简介
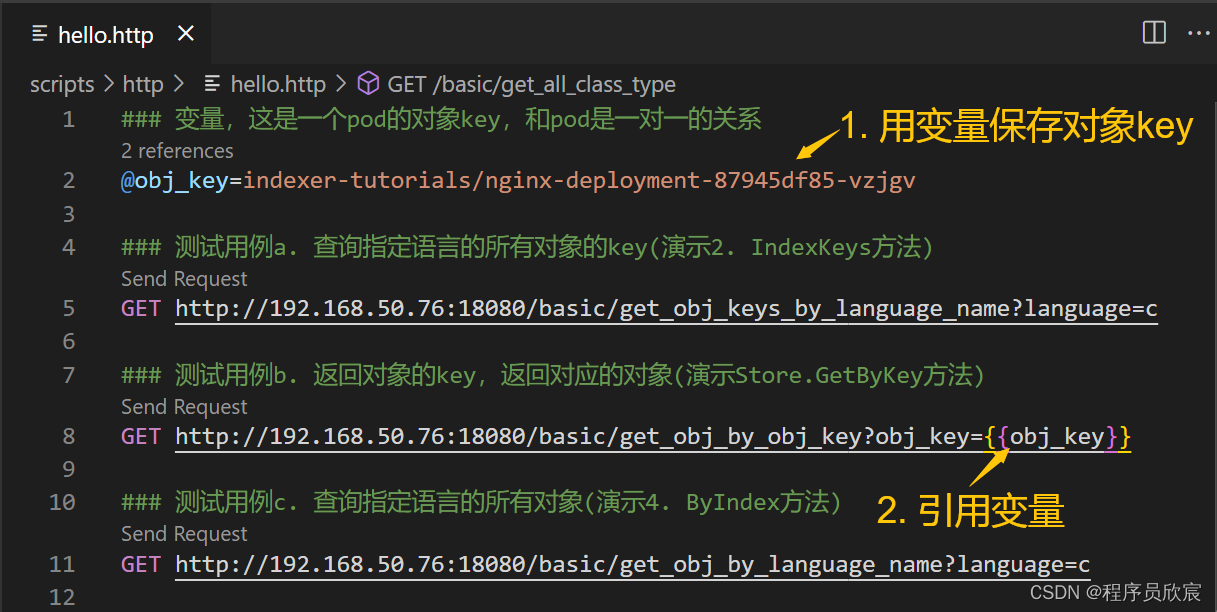
- 2. Transformer组成
- 2.1 Self-Attention
- Multi-Head Attention(多头注意力)
- 2.2 Transformer的其他关键概念
- 2.2.1 Feed-Forward Network 前馈网络
- 2.2.2 Residual Connection 残差连接
- 2.2.3 解码器中的最后一层
- 3. VISION TRANSFORMER
- 3.1 Representation Learning的主干
- 3.1.1 Pure Transformer
- 3.1.2 Transformer With Convolution
- 3.1.3 自我监督的表征学习
- 3.1.4 讨论
- 3.2 高/中级视觉任务
- 3.2.1 通用对象检测
- 基于Transformer的集预测检测(DETR)
- 基于Transformer的检测骨干( R-CNN)
- 基于Transformer的预训练(YOLO)
- 3.2.2 分割Segmentation
- 用于全景分割的Transformer(DETR)
- 用于实例分割的Transformer(VisTR)
- 用于语义分割的Transformer(SETR)
- 用于医学图像分割的Transformer(Cell-DETR)
- 3.2.3 姿态估计 Pose Estimation
- 3.2.4 其他任务
- 行人检测 Pedestrian Detection
- 车道检测 Lane Detection
- 场景图 Scene Graph
- 跟踪 Tracking
- 重鉴 Re-Identification
- 点云 Point Cloud Learning
- 3.3 低水平视觉任务 Low-Level Vision
- 3.3.1 图像生成 Image Generation
- 3.3.2 图像处理 Image Processing
- 3.4 视频处理
- 3.5 多模态任务
- 3.6 Efficient Transformer
- 4. 结论与讨论
1. Transformer简介
Transformer首先应用于自然语言处理领域,是一种以自我注意机制为主的深度神经网络。由于其强大的表示能力,研究人员正在寻找将变压器应用于计算机视觉任务的方法。在各种视觉基准测试中,基于变压器的模型表现类似或优于其他类型的网络,如卷积和循环神经网络。由于其高性能和较少的视觉特异性感应偏倚需求,变压器正受到计算机视觉界越来越多的关注。在本文中,我们对这些视觉转换器模型进行了综述,并根据不同的任务对其进行了分类,分析了它们的优缺点。我们探讨的主要类别包括骨干网络、高/中级视觉、低级视觉和视频处理。我们还包括高效的变压器方法,用于将变压器推入基于实际设备的应用程序。此外,我们还简要介绍了计算机视觉中的自注意机制,因为它是变压器的基本组件。在本文的最后,我们讨论了视觉变压器所面临的挑战,并提出了进一步的研究方向。
在这里,我们回顾了与基于变压器的视觉模型相关的工作,以跟踪这一领域的进展。图1展示了视觉变压器的发展时间表——毫无疑问,未来会有更多的里程碑。
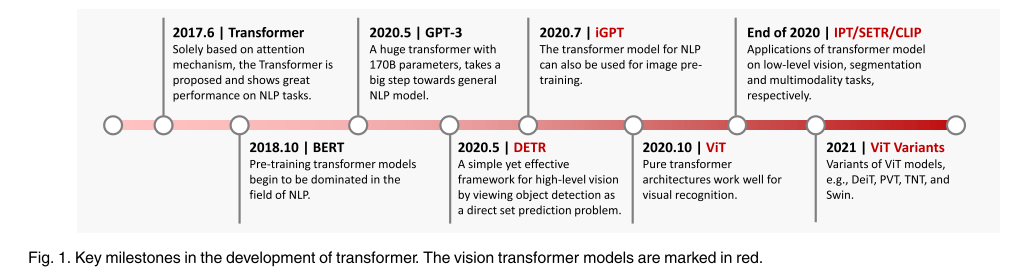
图1,Transformer发展的关键里程碑。视觉Transformer型号用红色标注。
2. Transformer组成
Transformer首次被用于机器翻译任务的自然语言处理(NLP)领域。如图2,原始变压器的结构。它由一个编码器和一个解码器组成,其中包含几个具有相同架构的转换器块。
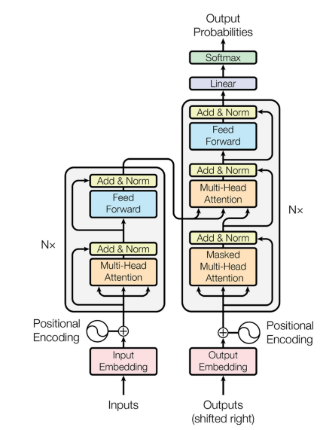
编码器生成输入的编码,而解码器获取所有编码并使用它们合并的上下文信息来生成输出序列。每个变压器块由多头注意层、前馈神经网络、快捷连接和层归一化组成。下面,我们详细描述变压器的每个组成部分。
2.1 Self-Attention
在自注意层,首先将输入向量转换为三个不同的向量:
-
查询向量(query vector)q
-
键(key vector)向量k
-
值向量(value vector)v
三种向量的维数d(q、k、v)=d(model)=512,由不同输入导出的向量被打包成三个不同的矩阵,即Q、K和V。然后,计算出不同输入向量之间的注意函数,如下图3所示:
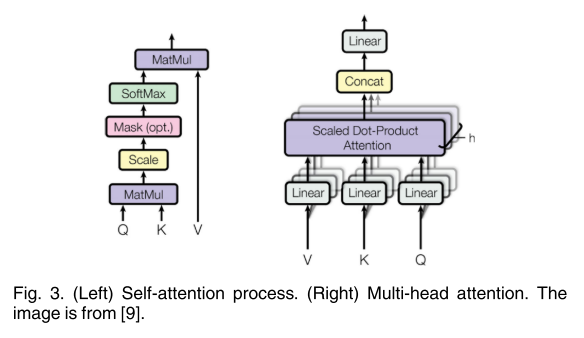
Step 1:计算不同输入向量之间的得分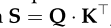
Step 2:对梯度的稳定性分数进行归一化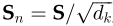
Step 3:使用softmax函数将得分转化为概率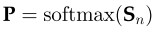
Step 4:求加权值矩阵Z=V*P
该过程可以统一为一个单一函数(dk=模型维度=512)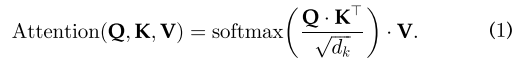
公式(1)背后的逻辑很简单。
Step 1 计算每对不同向量之间的分数,这些分数决定了我们在编码当前位置的单词时给予其他单词的关注程度
Step 2 将分数归一化,以增强梯度稳定性,用于改进训练;
Step 3 将分数转化为概率。
最后,将每个值向量乘以概率的和。具有较大概率的向量将获得额外的注意。
解码器模块中的编码器-解码器注意层类似于编码器模块中的自注意层,但有以下例外:密钥矩阵K和值矩阵V由编码器模块导出,查询矩阵Q由上一层导出。
注意,前面的过程对每个单词的位置是不变的,这意味着自我注意层缺乏捕捉单词在句子中的位置信息的能力。然而,语言中句子的顺序性要求我们在编码中整合位置信息。为了解决这个问题并获得单词的最终输入向量,在原始的输入嵌入中添加了一个维度为dmodel的位置编码。具体地说,这个位置是用下面的公式编码的

Pos表示单词在句子中的位置,i 表示位置编码的当前维度。通过这种方式,位置编码的每个元素都对应于一个正弦波,它允许变压器模型学习通过相对位置参与,并在推理过程中外推到更长的序列长度。
除了vanilla transformer中的固定位置编码外,各种模型中还使用了习得的位置编码和相对位置编码。
Multi-Head Attention(多头注意力)
多头注意是一种可以用来提高vanilla自我注意层性能的机制。
注意,对于一个给定的参考词,我们通常想要在整个句子中关注其他几个词。一个单一的自我注意层限制了我们专注于一个或多个特定位置的能力,而不会同时影响对其他同等重要位置的注意。这是通过给注意层不同的表示子空间来实现的。
具体来说,对于不同的头部使用不同的查询矩阵、键值矩阵,这些矩阵通过随机初始化,训练后可以将输入向量投射到不同的表示子空间中。
为了更详细地说明这一点,给定一个输入向量和注意头数量h,dmodel=模型维度
-
首先将输入向量转换为三组不同的向量:查询组(query group)、键组(key group)和值组(value group)
-
在每一个组中。有h个维度为dq=dk’=dv’=dmodel/h=64的向量
-
然后,从不同输入导出的向量被打包成三组不同的矩阵:
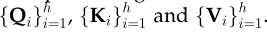
-
多头注意过程如下图所示:

其中,Q’(K’,V’同理)是{Qi}的串联,Wo是投影权值。
2.2 Transformer的其他关键概念
2.2.1 Feed-Forward Network 前馈网络
在每个编码器和解码器的自注意层之后采用前馈网络(FFN)。它由两个线性变换层和其中的一个非线性激活函数组成,可以表示为以下函数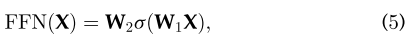 其中w1、w2为两个线性变换层的两个参数矩阵,s为非线性激活函数,如GELU。隐藏层的维度为dh=2048。
其中w1、w2为两个线性变换层的两个参数矩阵,s为非线性激活函数,如GELU。隐藏层的维度为dh=2048。
2.2.2 Residual Connection 残差连接
如图2中所示,在编码器和解码器的每个子层中增加一个剩余的连接(黑色箭头)。
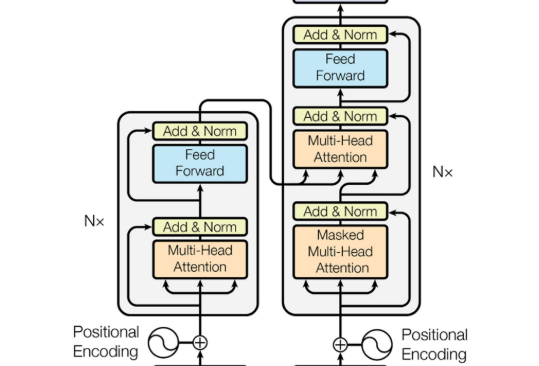
这加强了信息流,以实现更高的性能。在剩余连接之后,采用层归一化。这些操作的输出可以描述为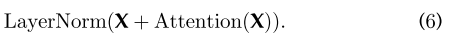
X作为自我注意层的输入,查询、键值矩阵Q、K和V都来自同一个输入矩阵X。
2.2.3 解码器中的最后一层
解码器中的最后一层用于将向量堆栈转换回一个单词。这是通过一个线性层和一个softmax层实现的。
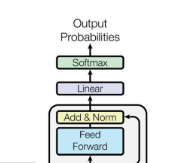
线性层将该向量投影为具有dword维数的logits向量,其中dword是词汇表中的单词数。然后使用softmax层将logit向量转换为概率。
当用于CV(计算机视觉)任务时,大多数变压器采用原变压器的编码器模块。这种变压器可以看作是一种新型的特征提取器。与只关注局部特征的CNN(卷积神经网络)相比,变压器可以捕获长距离的特征,这意味着它可以很容易地获得全局信息。
与必须顺序计算隐藏状态的RNN(循环神经网络)相比,变压器的效率更高,因为自注意层和全连接层的输出可以并行计算,且易于加速。由此,我们可以得出结论,进一步研究变压器在计算机视觉和自然语言处理中的应用将会产生有益的结果。
3. VISION TRANSFORMER
在本节中,我们回顾了基于变压器的模型在计算机视觉中的应用,包括图像分类、高/中级视觉、低级视觉和视频处理。简要总结了自注意机制和模型压缩方法在高效变压器中的应用。
3.1 Representation Learning的主干
与文本相比,图像涉及更多的维度、噪声和冗余形态,因此被认为生成建模更加困难。除了cnn,可以采用ResNet作为模型的基线,并使用视觉变压器代替卷积的最后阶段。
卷积层提取的低层特征输入vision transformer,之后使用一个标记器(tokenizer)将像素分组为少量的视觉标记(visual tokens),每个标记表示图像中的一个语义概念。
这些视觉标记直接用于图像分类,而转换器用于建模标记之间的关系。
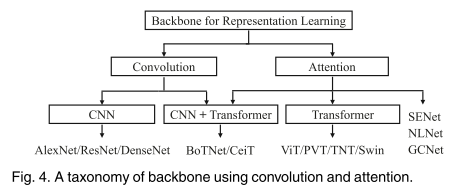
如图4所示,将作品分为单纯使用变压器和将CNN与变压器相结合。
我们将这些模型的结果总结在表2和图6中,以展示backbones的发展情况。

除了监督学习外,自监督学习也在视觉转换器中进行了探索。
3.1.1 Pure Transformer

基础ViT. Vision Transformer (ViT)是一个纯变压器,直接应用于图像补丁序列进行图像分类任务。它尽可能地遵循变压器的原始设计。ViT的框架如图5所示:将2d图像重塑成一块块补丁,并通过线性映射将其位置编码和补丁块嵌合在一起。
令(p,p)为补丁的分辨率,(h,w)为图像分辨率,变压器的有效序列长度为n=hw/p^2。由于变压器在其所有层中使用恒定的宽度,一个可训练的线性投影将每个矢量化路径映射到模型维数d,其输出被称为补丁嵌入(patch embeddings)。
值得注意的是,ViT只使用标准变压器的编码器(除了用于层规范化的位置),其输出在一个MLP头之前。在大多数情况下,ViT是在大型数据集上进行预训练的,然后针对较小数据的下游任务进行微调。
**ViT的变体.**在虚拟视觉技术范式的基础上,人们提出了一系列虚拟视觉技术的变体,以提高视觉任务的性能。主要途径包括增强局部性、提高自我意识和建筑设计。
还有一些其他方向可以进一步改进视觉变压器,如位置编码、归一化策略、快捷连接、去注意力等。
3.1.2 Transformer With Convolution
每个变压器块中的前馈网络(FFN)与卷积层相结合,以促进相邻tokens之间的相关性。此外,一些研究人员已经证明,基于变压器的模型可能更难获得良好的数据拟合能力,换句话说,他们对优化器的选择、超参数和训练的时间表非常敏感。
Visformer揭示了使用两种不同训练设置的变压器和cnn之间的差距。第一个是cnn的标准设定,训练时间更短,数据增加只包含随机裁剪和水平翻转。另一种即训练日程更长,数据增强更强。改变了ViT早期的视觉处理,将其嵌入干替换为标准的卷积干,并发现这种改变使ViT收敛更快,并允许使用AdamW或SGD而不显著降低精度。除了这两项工作外,还选择在变压器顶部添加卷积干。
3.1.3 自我监督的表征学习
基于生成的方法:本文简要介绍iGPT的作用机制。这种方法包括一个训练前阶段,接着是一个微调阶段。在训练前阶段,研究了自回归目标和BERT目标。为了实现像素预测,采用了序列转换器的结构,而不是语言符号(如NLP中使用的)。当与早期停止结合使用时,预训练可以被认为是一个有利的初始化或正则化。在微调阶段,他们向模型中添加了一个小的分类头。这有助于优化分类目标和调整所有权重。
通过k-means聚类将图像像素转化为序列数据。给定由高维数据X=(x1,…,xn)组成的未标记数据集X,他们通过最小化数据的负对数可能性来训练模型: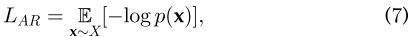
p(x)是图像数据的概率密度,可以建模为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IH41Nqiq-1686551810644)(C:/Users/dell/AppData/Roaming/Typora/typora-user-images/image-20230612142825068.png)]
恒等排列Πi=i 适用于[1,n],这也被称为光栅顺序。
iGPT和ViT是将变压器应用于视觉任务的两项开创性工作。iGPT模型与vi -like模型的区别主要体现在3个方面:
-
iGPT的输入是一组像素聚类的调色板序列,而ViT则将图像均匀地分割成若干个局部的小块;
-
iGPT体系结构为编码器-解码器框架,而ViT只有变压器编码器;
-
iGPT利用自回归的自监督损耗进行训练,而ViT则通过监督图像分类任务进行训练。
基于对比学习的方法。对比学习是当前计算机视觉中最流行的一种自我监督学习方式。将对比学习应用于视觉变压器的无监督预训练
3.1.4 讨论
视觉转换器的多头自注意、多层感知器、快捷连接、层归一化、位置编码和网络拓扑等组成部分在视觉识别中发挥着关键作用。如上所述,为了提高视觉变压器的有效性和效率,人们提出了许多工作。从图6的结果可以看出,将CNN和transformer结合使用可以获得更好的性能,这说明它们通过局部连接和全局连接实现了互补。对骨干网的进一步研究将有助于整个视觉社区的改进。对于视觉变压器的自监督表征学习,我们还需要努力追求大规模的预训练在NLP领域的成功。
3.2 高/中级视觉任务
最近,人们对将变压器用于高/中级计算机视觉任务越来越感兴趣,如目标检测,车道检测,分割和姿态估计。我们将在本节中回顾这些方法。
3.2.1 通用对象检测
传统的目标检测方法主要基于CNN,而基于变压器的目标检测方法因其优越的性能而受到广泛关注。
一些目标检测方法尝试利用变压器的自注意机制,然后对现代探测器的具体模块进行增强,如特征融合模块和预测头。
基于变压器的目标检测方法大致分为两类:
-
基于变压器的集合预测方法
-
基于变压器的骨干方法,如图7所示
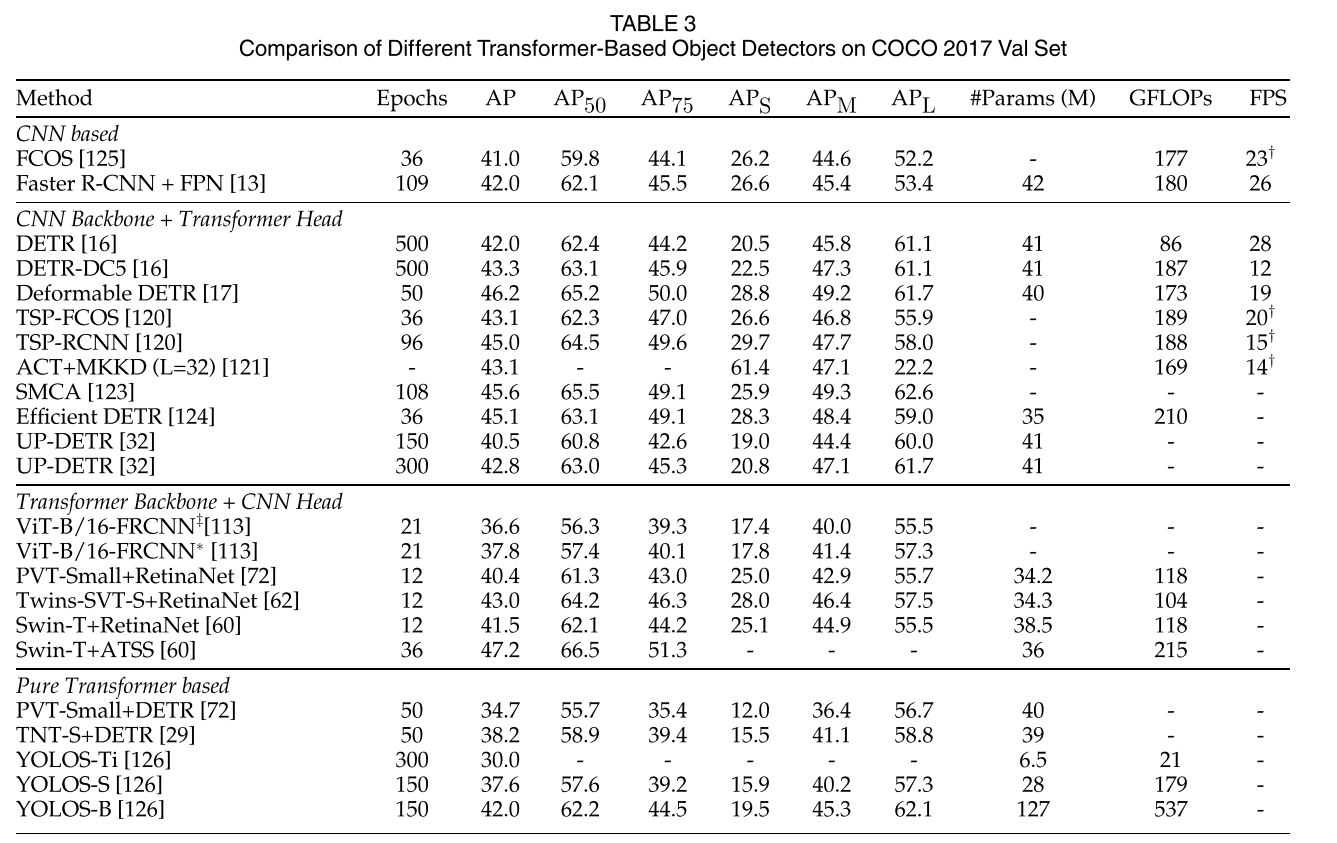
表3显示了前面提到的在COCO 2012 val集上不同基于变压器的目标检测器的检测结果。
基于Transformer的集预测检测(DETR)
DETR,是一种简单的全端到端对象检测器,它将对象检测任务视为一个直观的集合预测问题,消除了传统手工制作的组件,如锚点生成和非最大抑制(non-maximum suppression, NMS)后处理。(前馈网络(FFN))
-
为了对图像特征进行位置信息的补充,在将图像特征输入编码器-解码器变压器之前,对其进行固定位置编码。
-
解码器使用来自编码器的嵌入以及N个学习过的位置编码(对象查询),并产生N个输出嵌入。(这里的N是一个预定义的参数,通常大于图像中对象的数量)
-
使用简单的前馈网络(ffn)来计算最终的预测,其中包括边界框坐标和类别标签来表示对象的特定类别(或表示不存在对象)。
-
与按顺序计算预测的原始转换器不同,DETR并行地对N个对象进行解码。DETR采用二部匹配算法来分配预测对象和地面真实对象。如式(11)所示,利用匈牙利Hungarian损失来计算所有匹配对象对的损失函数。
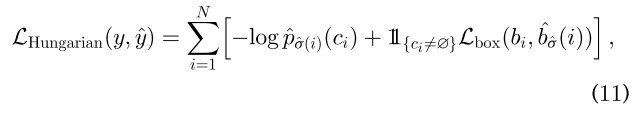
DETR在物体检测上表现出了令人印象深刻的性能,提供了与流行的和公认的Faster R-CNN基线在COCO基准上相当的精度和速度,DETR是一种基于转换器的目标检测框架的新设计,它使社区能够开发完全端到端检测器。然而,vanilla DETR提出了几个挑战,具体来说,较长的训练计划和对于小目标检测较差的性能。
Deformable DETR的训练成本比DETR低10倍,推理速度比DETR快1.6倍。通过采用迭代边界盒优化方法和两阶段方案,Deformable DETR可以进一步提高检测性能。
Efficient DETR通过附加的区域提议网络将密集的先验信息整合到检测管道中。更好的初始化使它们能够只使用一个解码器层,而不是六层,以实现更紧凑的网络的竞争性能。
基于Transformer的检测骨干( R-CNN)
与DETR不同,DETR通过transformer将对象检测重新设计为集预测任务,Beal等人出利用transformer作为常见检测框架的主干,如Faster R-CNN。输入图像被分割成几个小块,送入视觉变压器,其输出的嵌入特征根据空间信息进行重组,然后通过检测头得到最终结果。一个大规模的预训练变压器主干可以为提议的ViT-FRCNN带来好处。
也有相当多的方法来探索多功能视觉变压器主干设计,并将这些主干转移到传统的检测框架,如RetinaNet和Cascade R-CNN。例如,Swin Transformer通过ResNet-50骨干网获得4 box AP增益,使用类似的FLOPs用于各种检测框架。
基于Transformer的预训练(YOLO)
受NLP中预训练变压器方案的启发,人们提出了几种方法来探索基于变压器的目标检测的不同预训练方案。Dai等人提出了无监督的目标检测预训练(UP-DETR)。
具体来说,提出了一种新的无监督托词任务——随机查询补丁检测来预训练DETR模型。通过这种无监督的预训练方案,UP-DETR显著提高了在相对较小的数据集(PASCAL VOC)上的检测精度。在训练数据充足的COCO基准上,UP-DETR仍然优于DETR,证明了无监督预训练方案的有效性。
YOLOS首先在ViT中删除分类标记,并添加可学习检测标记。此外,利用二部匹配损耗对目标进行集预测。通过在ImageNet数据集上使用这种简单的预训练方案,所提出的YOLOS在COCO基准测试上显示出了具有竞争力的目标检测性能。
3.2.2 分割Segmentation
分割是计算机视觉领域的一个重要研究课题,广泛包括全景分割、实例分割和语义分割等。视觉变压器在分割领域也显示出了惊人的潜力。
用于全景分割的Transformer(DETR)
DETR可以自然地扩展到全景分割任务中,并通过在解码器上附加一个掩模头来获得具有竞争力的结果。
用于实例分割的Transformer(VisTR)
VisTR是一种基于变压器的视频实例分割模型
用于语义分割的Transformer(SETR)
SETR是基于变压器的语义分割网络
用于医学图像分割的Transformer(Cell-DETR)
这是一个用于医学图像分割的类unet纯Transformer,通过将标记化的图像块输入基于Transformer的du - shapedencoderdecoder架构,并带有跳跃连接,用于局部全局语义特征学习。
3.2.3 姿态估计 Pose Estimation
人的姿势和手的姿势估计是一个基本的课题,已经吸引了重大兴趣的研究社区。关节姿态估计类似于结构化预测任务,旨在从输入的RGB/D图像中预测关节坐标或网格顶点。有以下2类需要注意,
- 用于手部姿态估计的变压器
- 用于人体姿态估计的变压器
3.2.4 其他任务
还有很多不同的高/中级视觉任务已经探索了视觉转换器的使用,以获得更好的性能。我们将简要回顾以下几个任务。
行人检测 Pedestrian Detection
车道检测 Lane Detection
场景图 Scene Graph
跟踪 Tracking
重鉴 Re-Identification
点云 Point Cloud Learning
以下几节内容不做更多解释,希望大家自己去了解
3.3 低水平视觉任务 Low-Level Vision
在图像超分辨率和图像生成等低层次视觉领域应用变压器的研究很少。这些任务通常以图像作为输出(例如,高分辨率或去噪图像),这比分类、分割和检测等高级视觉任务更具挑战性,这些任务的输出是标签或框。
3.3.1 图像生成 Image Generation
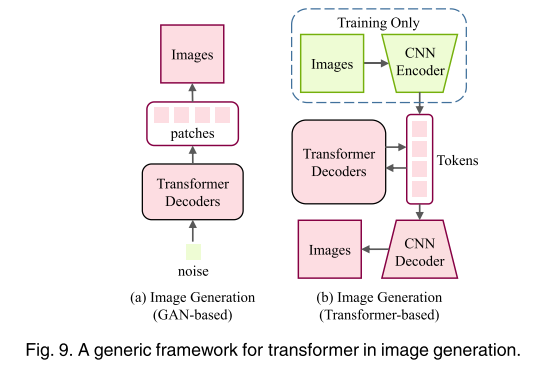
图9,一个通用的框架,变压器在图像生成。
3.3.2 图像处理 Image Processing
3.4 视频处理
3.5 多模态任务
由于变压器在基于文本的自然语言处理任务中的成功,许多研究热衷于开发其在处理多模态任务时的潜力。其中一个例子是VideoBERT,它使用一个基于cnn的模块对视频进行预处理,以获得表示令牌。
3.6 Efficient Transformer
虽然变压器模型在各种任务中都取得了成功,但它们对内存和计算资源的高要求阻碍了它们在资源有限的设备(如移动电话)上的实现。在本节中,我们回顾了为高效实现而对变压器模型进行压缩和加速的研究。其中包括网络剪枝、低秩分解、知识精馏、网络量化和结构紧凑设计。
表4列出了一些具有代表性的压缩变压器模型。
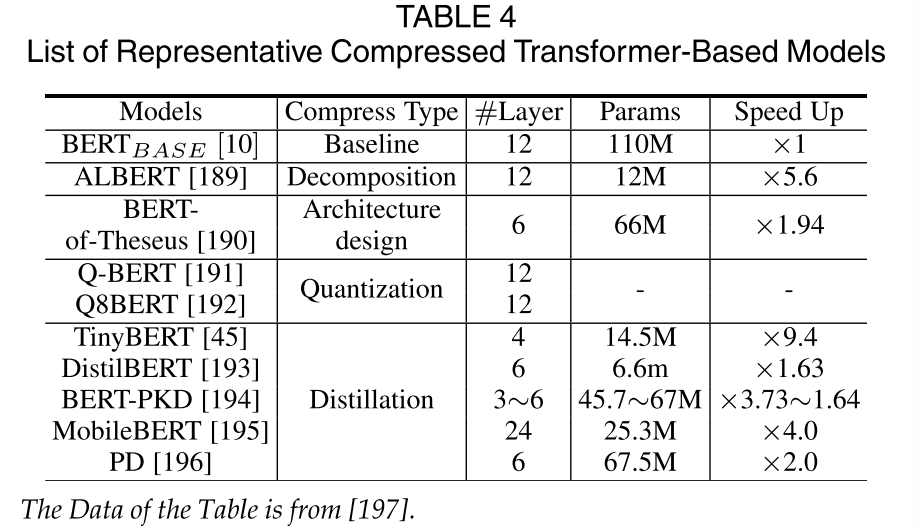
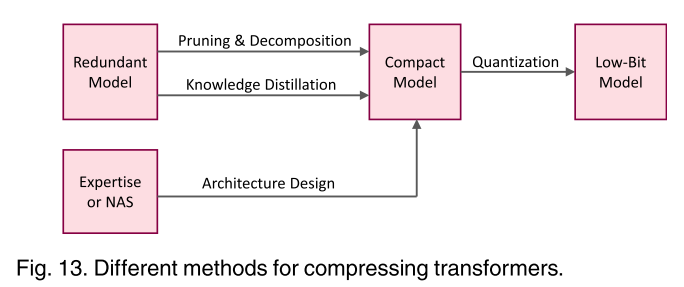
图13。压缩变压器的不同方法。
上述方法在试图识别变压器模型中的冗余时采用了不同的方法(见图13)。剪枝和分解方法通常需要预定义的冗余模型。具体来说,剪枝专注于减少变压器模型中组件(如层、头)的数量,而分解则用多个小矩阵表示一个原始矩阵。紧凑的模型也可以直接手工设计(需要足够的专业知识)或自动设计(例如,通过NAS)。得到的紧凑模型可以通过量化方法用低比特进一步表示,以便在资源有限的设备上高效部署。
4. 结论与讨论
与cnn相比,Transformer的性能和巨大的潜力使其成为计算机视觉领域的热门话题。为了发现和利用变压器的能量,正如本调查所总结的,近年来提出了许多方法。这些方法在主干网、高/中级视觉、低水平视觉和视频处理等视觉任务中表现优异。然而,计算机视觉变压器的潜力尚未得到充分开发,这意味着仍有几个挑战需要解决。在本节中,我们将讨论这些挑战,并提供对未来前景的见解。
为了推动视觉变压器的发展,我们提出了几个潜在的研究方向。
一个方向是计算机视觉中变压器的有效性和效率。目标是开发高效、高效的视觉变压器;具体来说,是高性能、资源成本低的变压器。性能决定了模型是否可以应用于真实世界的应用程序,而资源成本影响设备的部署。有效性通常与效率相关,因此如何在两者之间取得更好的平衡是未来研究的一个有意义的课题。
神经网络有各种类型,如CNN、RNN和transformer。在CV领域,cnn曾经是主流选择,但现在变压器越来越流行。cnn可以捕获归纳偏差,如平移等方差和局域性,而ViT使用大规模训练来超越归纳偏差。从目前可用的证据[15]来看,cnn在小数据集上表现良好,而变压器在大数据集上表现更好。未来的问题是使用CNN还是变压器。