文章目录
- 一、SAM 导读
- 二、SAM 的应用场景
- 2.1 SAM-RBox-生成旋转矩形框
- 2.2 Prompt-Segment-Anything-生成矩形框和掩
- 2.3 Grounded-Segment-Anything-开放数据集检测与分割
- 2.4 segment-anything-video-视频分割
- 2.5 Open-vocabulary-Segment-Anything-开放词典分割
- 2.6 SegDrawer-基于SAM的标注工具
- 2.7 Caption Anything-基于SAM的caption生成工具
- 三、HQ-SAM简介
- 四、HQ-SAM整体流程
- 五、HQ-SAM vs SAM
- 5.1 HQ-SAM与SAM主观效果比较
- 5.2 HQ-SAM与SAM客观指标比较
- 六、HQ-SAM效果展示
一、SAM 导读
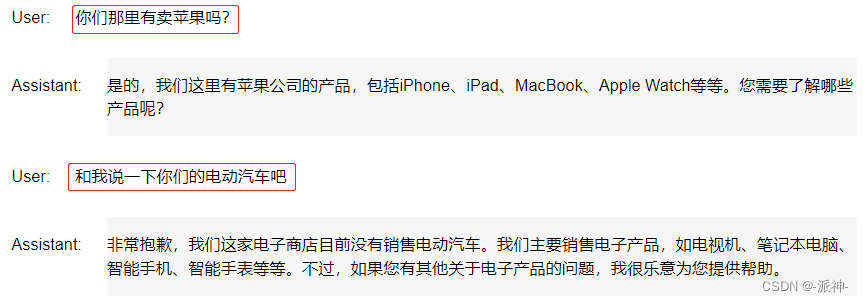
相信很多朋友都对Facebook开源的Segement Anything(SAM)算法有很深的印象,当前SAM已经被开发出众多的热门应用,至今为止,可能已经有很多朋友用它来提升自己的工作与生产效率。
虽然SAM算法效果很好,但是当碰到复杂的图像分割任务时,SAM输出的效果并不能满足我们的需求。
为了进一步提升SAM算法的Mask质量,有学者提出了一个增强版本的HQ-SAM算法,它的出现极大的扩展了SAM算法的应用场景、极大的提升了SAM算法的预测效果。
SAM,即Segment Anything,它借助了NLP任务中的Prompt思路,通过给图像分割任务提供一下Prompt提示来完成任意目标的快速分割。提示可以是前景/背景点集、粗略的框或遮罩、任意形式的文本或者任何指示图像中需要进行分割的信息。该任务的输入是原始的图像和一些提示语,输出是图片中不同目标的掩码信息。
二、SAM 的应用场景
2.1 SAM-RBox-生成旋转矩形框

2.2 Prompt-Segment-Anything-生成矩形框和掩

2.3 Grounded-Segment-Anything-开放数据集检测与分割

2.4 segment-anything-video-视频分割

2.5 Open-vocabulary-Segment-Anything-开放词典分割
2.6 SegDrawer-基于SAM的标注工具

2.7 Caption Anything-基于SAM的caption生成工具

三、HQ-SAM简介
HQ-SAM是在现有的Segment Anything Model (SAM)基础上进行改进的一个能够分割任何物体的算法。HQ-SAM具有更好的分割能力,特别是在处理具有复杂结构的对象时,能够更准确地分割。同时,HQ-SAM保留了SAM的可提示性、高效性和零-shot泛化能力。
为了训练HQ-SAM,研究人员设计了一个可学习的高质量输出标记,并将其注入到SAM的掩模解码器中,负责预测高质量掩模。为了提高掩模细节,研究人员将掩模解码器特征与早期和最终的ViT特征融合。

为了训练引入的可学习参数,研究人员创建了一个由多个不同来源组成的44K细粒度掩模数据集。HQ-SAM只在这个44k数据集上进行训练,使用8个GPU训练了4个小时。研究人员展示了HQ-SAM在9个不同的分割数据集中的有效性,更多的细节请看下文。
论文链接:
https://arxiv.org/pdf/2306.01567.pdf
github 链接:
https://github.com/SysCV/SAM-HQ

四、HQ-SAM整体流程
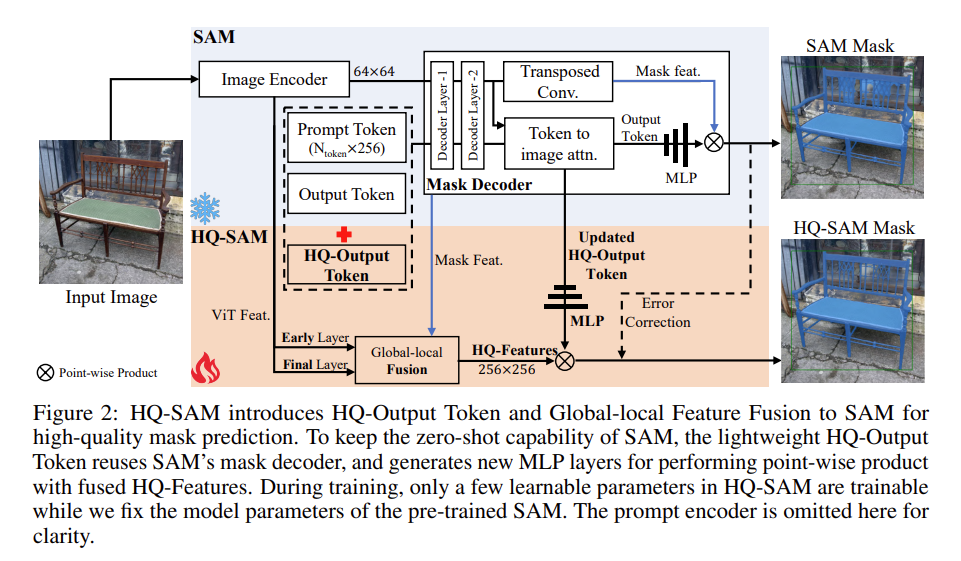
为了保留 SAM算法的零样本迁移能力,同时防止模型过拟合或灾难性遗忘,HQ-SAM 尽可能采用最小的改动,而不是直接微调 SAM 或添加新的复杂的解码器网络。因而,HQ-SAM 尽可能重用 SAM 的预训练模型权重,只添加了两个新的关键组件,即高质量输出令牌和全局-局部特征融合。如上图所示,HQ-SAM算法的具体步骤如下所述:
步骤1:首先,将输入图片传入SAM中的图像编码器中获取一个6464大小的特征映射。获取输入Prompt信息的Token表示Ntoken256,输出Token(类似于 DETR 中的对象查询)。
步骤2:然后,为了改进SAM算法的掩码质量,HQ-SAM 重用并修复了 SAM 的掩码解码器。HQ-SAM 添加了一个新的可学习的 HQ-Output Token(大小为 1×256),将其与 SAM 的输出令牌(大小为 4×256)和提示令牌(大小为 Nprompt×256)连接起来,作为输入传递给 SAM 的掩码解码器。类似于原始的输出令牌,在每个注意力层中,HQ-Output Token 首先与其他令牌进行自注意力计算,然后进行令牌到图像和图像到令牌的注意力计算,以更新其特征;最后,HQ-SAM 添加了一个新的三层 MLP,用于从更新的 HQ-Output Token 生成动态卷积核,然后将其与融合的 HQ-feature 进行空间逐点乘积,以生成高质量的掩码。
步骤3:接着,HQ-SAM 使用了 SAM 的 ViT 编码器中的三个特征来提高分割质量,这些特征分别是:1)SAM 的 ViT 编码器中的早期层局部特征,其空间形状为 64×64,可以捕捉更一般的图像边缘/边界细节。具体来说,HQ-SAM 提取了 ViT 编码器的第一个全局注意力块之后的特征,对于基于 ViT-Large 的 SAM,这是总共 24 个块中的第 6 个块输出。2)SAM 的 ViT 编码器中的最终层全局特征,其形状为 64×64,包含更多的全局图像上下文信息;3)SAM 的掩码解码器中的掩码特征,其大小为 256×256,也被输出令牌共享,包含强烈的掩码形状信息。
步骤4:输出最终的HQ-SAM分割结果,为了便于比较,作者同时显示了SAM的输出结果。
五、HQ-SAM vs SAM
5.1 HQ-SAM与SAM主观效果比较






上图展示了HQ-SAM算法与SAM算法在几张测试图片上面的输出结果。通过观察与分析,我们可以得出以下的初步结论:
1)HQ-SAM与SAM都可以对任意目标进行快速的分割;
2)相比于SAM算法,HQ-SAM算法能够精确的分割出一些细节信息,尤其是对其比较复杂的目标,例如:长凳、网球拍等。
3)HQ-SAM算法可以在一定程度上降低你的数据标注量,不仅可以降低你的成本,而且可以节约你的时间。
5.2 HQ-SAM与SAM客观指标比较
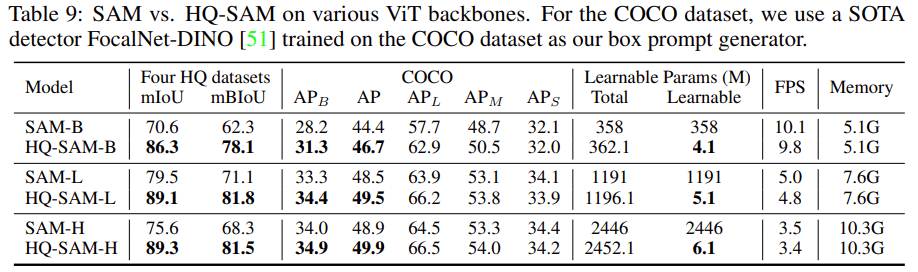
上表展示了HQ-SAM和SAM算法的不同版本在HQ数据集和COCO数据集上面的效果。通过观察与分析,我们可以得出以下的初步结论:
- 针对HQ数据集而言,不管是mIoU指标还是mBIoU指标,HQ-SAM算法的输出效果都明显优于SAM算法的效果;
- 针对COCO数据集而言,从各种AP指标来看,HQ-SAM算法的输出效果都在一定程度上优于SAM算法的效果;
- 虽然HQ-SAM算法的参数量更大一些,但是可学习的参数量却比较少!
- 从运行速度上而言,SAM算法的运行速度要稍微由于HQ-SAM算法。
- 两者所占用的内存大小是一样的!
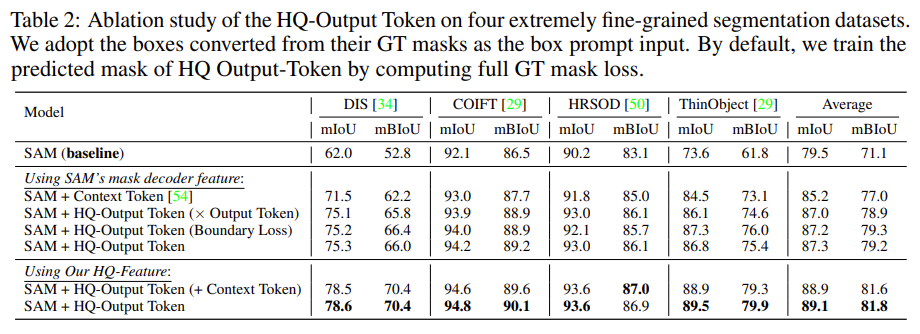
上表展示了不同的SAM基线算法在DIS、COIFT、HRSOD、ThinObject 4个数据集上面的评估指标。通过观察与分析,我们可以得出以下的初步结论:
- 在原始的SAM算法的基础上增加了Context Token之后,可以较大提升算法的mIoU和mBIoU指标;
- 在原始的SAM算法的基础上增加了Output Token之后,可以在一定程度提升算法的mIoU和mBIoU指标;
- 在原始的SAM算法的基础上增加了HQ特征之后,整个算法的mIoU和mBIoU指标都得到了较大的提升。
六、HQ-SAM效果展示