目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
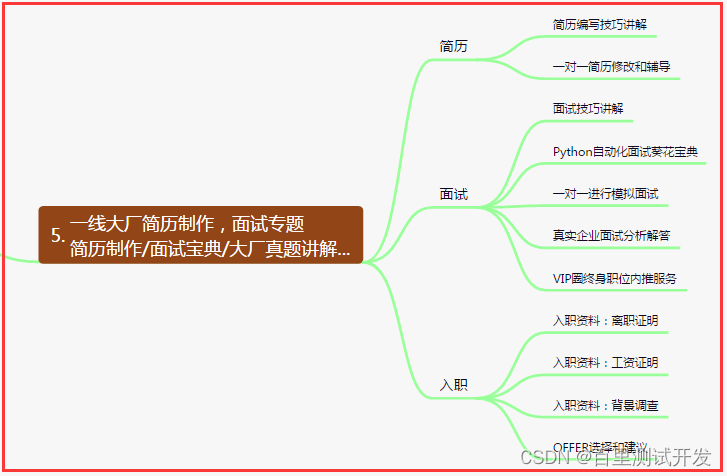
- 五、一线大厂简历
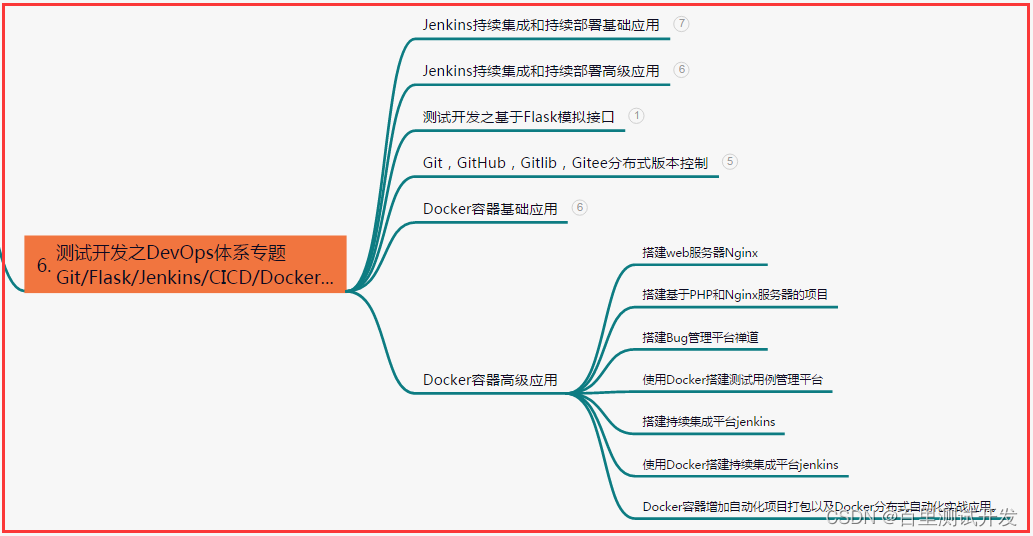
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
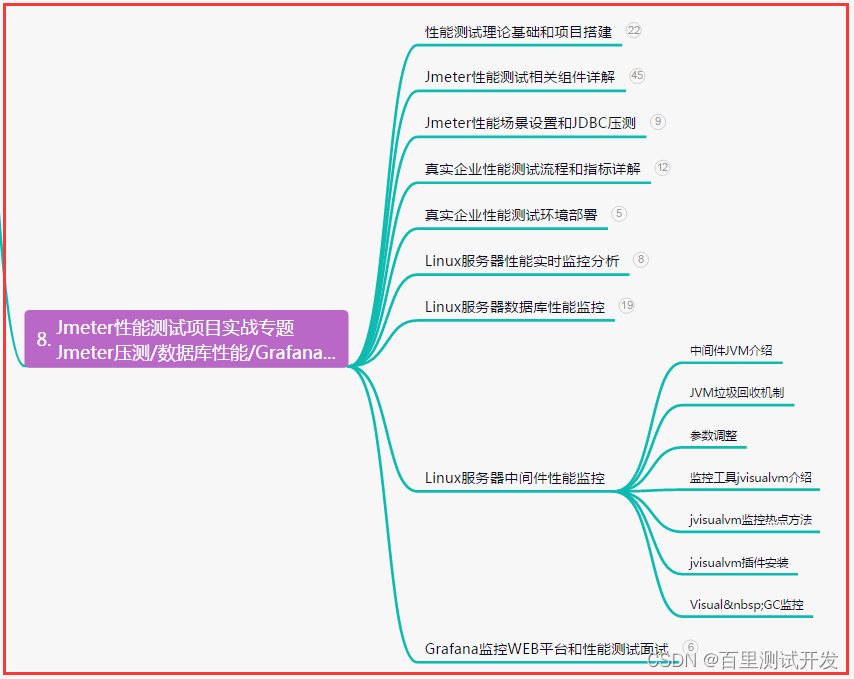
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
我们谈到测试设计,往往是指功能测试设计,往往忽视性能测试的场景设计,例如,如何进行性能测试时,如何把性能负载加上去,就需要根据业务进行负载发起策略的设计,包括逐步加载、一次性加载和峰谷加载等。
不管是否重视,性能场景应该说是在性能测试中非常关键的一个环节。经常在一些场合被问到性能场景的设计问题,但是大部分都是和容量相关的。
但为什么稳定性问的人少呢?
稳定性是不是说在容量场景做好了之后就水到渠成了呢?
首先稳定性场景的设计应该说比容量场景设计要简单一点。
如果容量测试结果非常好的话,稳定性场景只要维持较长时间的动作就可以了。但是不要小看这个时间变长的动作,它会让你要准备和思考的内容多出不少。
1、数据的增加
数据的增加有两个方面
参数化数据:
基础数据;
这里以参数化数据为例:
拿一个100TPS和稳定性场景来说,假设业务数据不能复用,如果只测试30分钟。需要的数据是1003060=180000,也就是18万的参数化数据。但如果要跑12个小时呢?
就是100126060=4320000,也就是432万条数据。
甚至有人还说:我要跑724。嗯,很好,那就需要60480000,即6千多万条数据,慢慢准备吧
如果这些数据是做insert的动作呢?
可想而知,对表结构的要求就会多出很多,索引创建的合理性就非常重要了。
举个例子:
同样的一个SQL,在查找基数为5537362的表,都是查一条数据出来。如果是从9万多条的索引命中的数据中找的话,需要0.219s,而在索引命中100多条数据中找的话,只需要0.016s。
这是14倍的差距
insert的动作是会被折成insert select的。所以在稳定性中,如果select的基数越来越大,对索引的考验那是可想而知的。对update、delete也是一样。
2、监控的考验
如果是自己写监控脚本,稳定性场景中数据量的处理那是非常耗时的。所以在稳定性场景中,基本上不会像容量场景中那样设计监控粒度。
粒度的扩大导致的另一个问题是毛刺看不到。
一般容量场景中使用1-3s的监控采样粒度,1s对系统监控还是会消耗些资源,3s不会有太大的影响。但是对稳定性来说,3s却有点短了。可以设置5-10s的监控粒度。5-10的跨度是不是有些大呢?这个取决于系统的稳定程度,对不稳定的tps曲线,可以设置为5s,对稳定的tps曲线,10s其实是够了的。
监控工具也要选择好,尽量不要用手工生成数据和曲线的工具,费时费力又容易出错。用自动生成图表的工具比较理智,并且要用可以持续保存数据的,像zabbix类型的工具。
先要设置好监控的计数器。从OS层开始,到应用层、jvm层,再到数据库层。os层一定要监控cpu、memory、io、network这几个基本资源,如果是C/C++的应用,还要有process层的监控。
在场景结束时,如果发现还有需要的数据没取到,那就悲催了,还要再来一遍,所以场景设计和监控设置时都要认真对待。
3、对压力工具的选择
一般情况下,选择压力工具要注意压力工具本身的稳定性。像loadrunner/jmeter之类的工具已经被普遍接受了,没有什么问题。
但是jmeter,本地的jvm也是需要关注的。
尽量不要用压力工具取监控的数据,这种做法会让结果整理比较费力。
4、稳定性场景的时长确定
这应该是稳定性场景中最关键的一个点了。但我看到有不少设计稳定性的时候没有计算过,只是凭感觉。
那怎么设计这个时长?
我们可以做一个计算,这个计算有一个前提条件。就是系统在运维的过程中需要稳定运行多长时间。假设在运维中是要三个月做一次正常的维护动作,在这个动作中包括了对一些资源的归档、系统的重启等。那下一步要计算的就是系统三个月内的业务总量。
我们来做一个假设场景:
一个系统一天业务量是100万笔。稳定运行要求3个月。那总的业务量就是100万330=9000万。假设系统最大TPS是2000。这时候要设计的稳定性场景时长就是:(9000万/2000tps)*3600=12.5h
根据这个系统的业务需求,稳定运行时间是三个月。
线上均值tps是329。
那业务量在三个月就是:329330243600=2558304000笔业务。
稳定性场景用80%*最大TPS的压力做的话(这里的稳定性场景的TPS可以灵活设置,不一定都是80%*最大TPS),就是4000tps左右。
来计算一下:2558304000/4000/3600/24=7.4天
时长就确定下来了。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
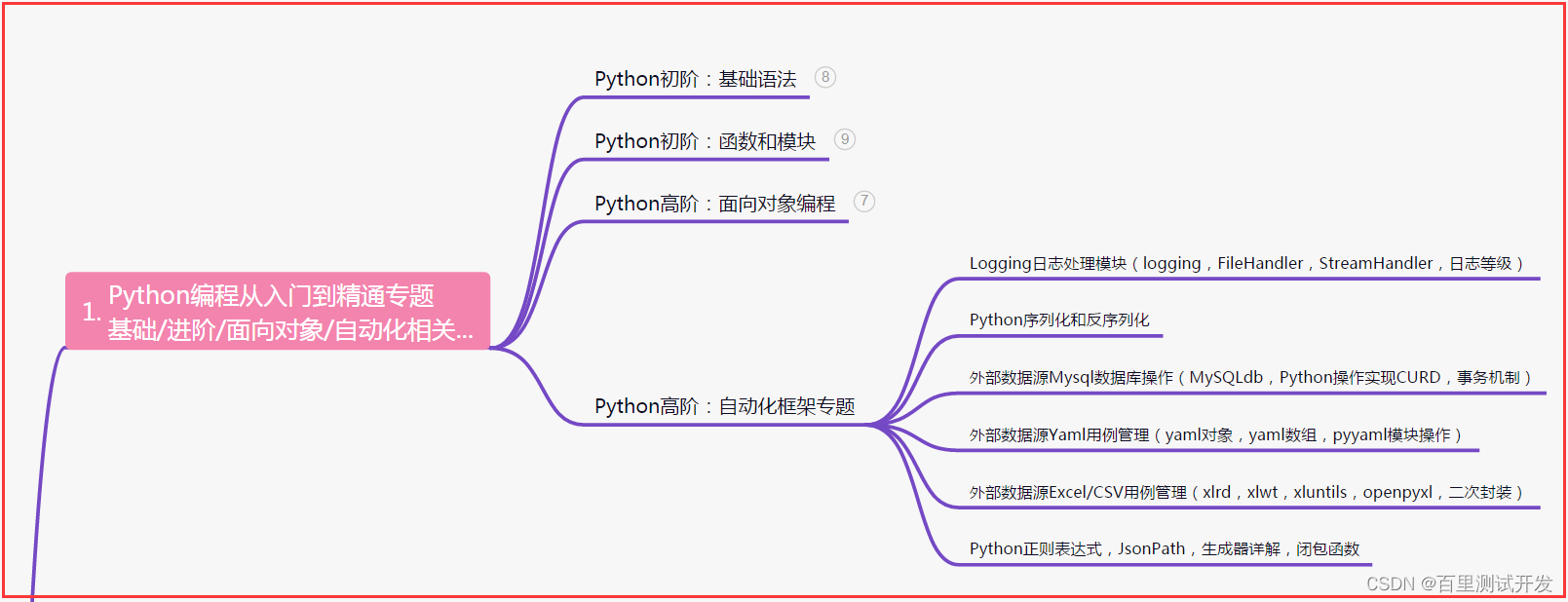
一、Python编程入门到精通
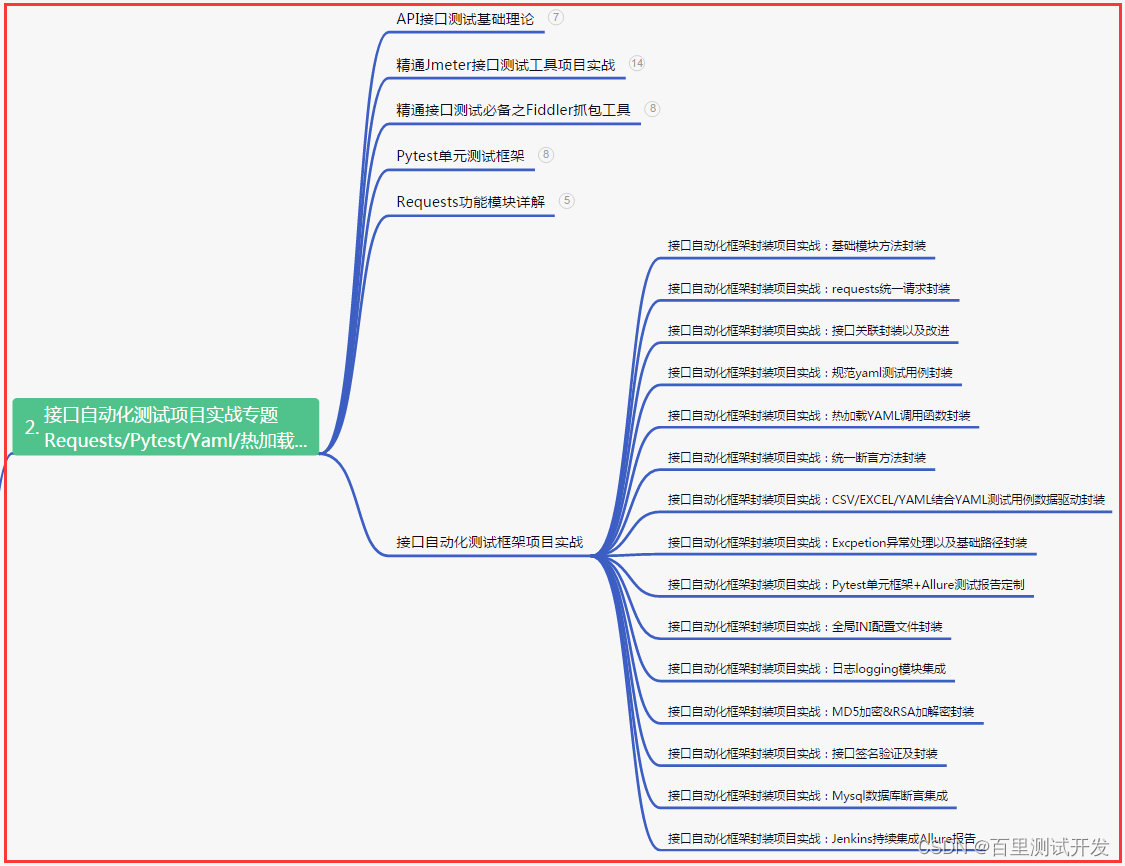
二、接口自动化项目实战
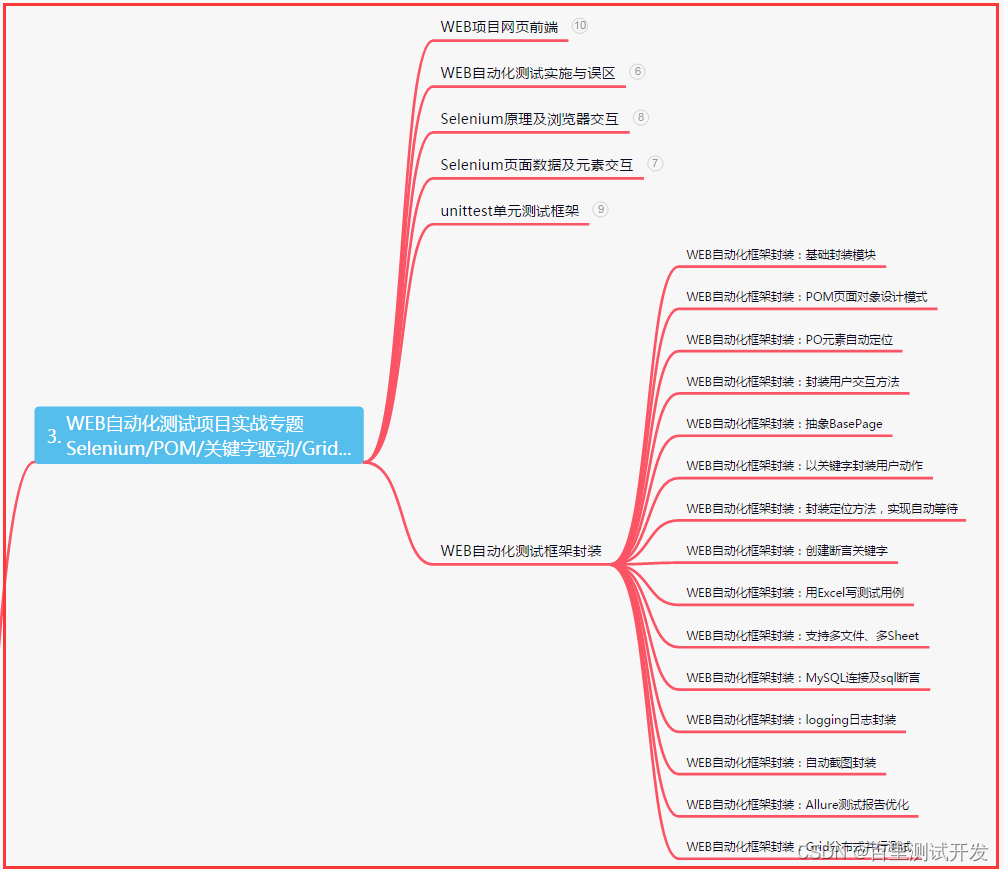
三、Web自动化项目实战
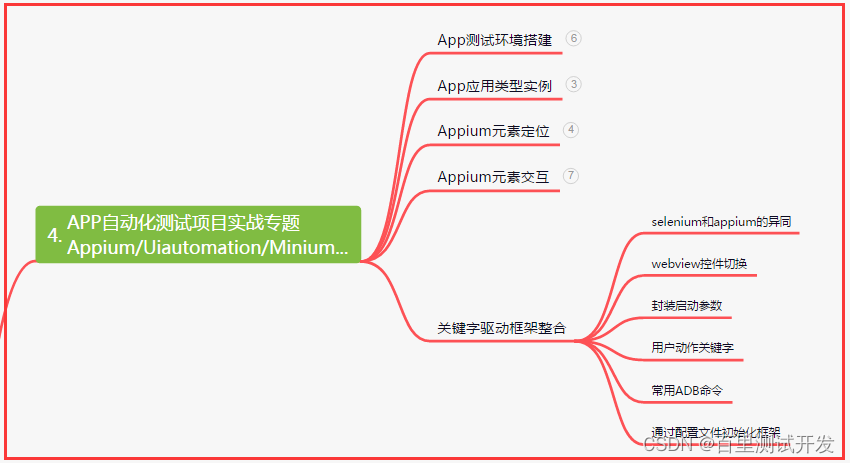
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试
九、总结(尾部小惊喜)
只有不断地努力和坚持,才能走向成功的道路。在面对挫折和失败时,要保持积极和乐观的心态,并从中吸取经验教训。相信自己,勇于追梦,不断成长,你一定能够实现心中所愿,创造属于自己的辉煌!
只有不断地向前奔跑,才能超越自我;只有不断地拼搏努力,才能迎来成功的曙光。无论前方道路如何泥泞坎坷,只要不放弃梦想,就一定会迎来辉煌。加油!
生命只有一次,没有人会替你承担后悔和痛苦。不要在意别人的眼光,为自己的梦想而努力奋斗,只有付出和坚持,才能让你的人生更加精彩和有意义。