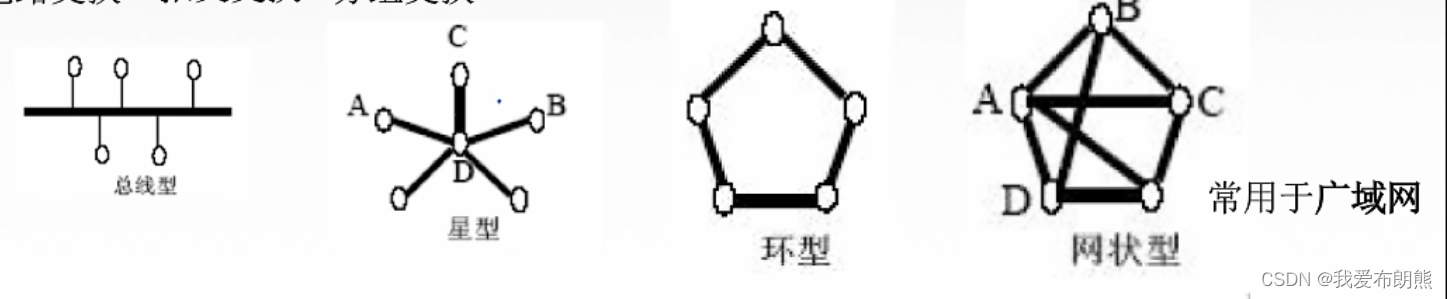
-
抓取函数调用流程关系
-
抓取函数耗时
-
抓取代码片耗时
-
抓取函数里每个子函数时间戳
-
抓取事件信息
trace是内核自带的工具,相比于perf工具,trace只管抓trace数据并没有分析,perf在trace数据分析方面做出了很多成果。 但是我们现在就想看一下底层多调用关系,所以使用trace抓一下数据是非常有必要的,还可以分析一下驱动性能。
因为trace工具是内核自带的,所以我们配置一下内核就可以使用了:

trace 通过 debugfs 向用户态提供了访问接口,所以还需要将 debugfs 编译进内核。激活对 debugfs 的支持,在 make menuconfig 时到 Kernel hacking 菜单下选中对 debugfs 文件系统的支持:

系统启动后,进入文件系统,执行:
mount -t debugfs none /sys/kernel/debug/
cd /sys/kernel/debug/tracing/
挂载debugfs后即可使用trace。
tracing 目录下文件和目录比较多,有些是各种跟踪器共享使用的,有些是特定于某个跟踪器使用的。在操作这些数据文件时,使用 echo 命令来修改其值,也可以在程序中通过文件读写相关的函数来操作这些文件的值。
-
README文件提供了一个简短的使用说明,展示了 ftrace 的操作命令序列。可以通过 cat 命令查看该文件以了解概要的操作流程。
-
current_tracer用于设置或显示当前使用的跟踪器;使用 echo 将跟踪器名字写入该文件可以切换到不同的跟踪器。系统启动后,其缺省值为 nop ,即不做任何跟踪操作。在执行完一段跟踪任务后,可以通过向该文件写入 nop 来重置跟踪器。
-
available_tracers记录了当前编译进内核的跟踪器的列表,可以通过 cat 查看其内容;写 current_tracer 文件时用到的跟踪器名字必须在该文件列出的跟踪器名字列表中。
-
trace文件提供了查看获取到的跟踪信息的接口。可以通过 cat 等命令查看该文件以查看跟踪到的内核活动记录,也可以将其内容保存为记录文件以备后续查看。
-
set_graph_function设置要清晰显示调用关系的函数,显示的信息结构类似于 C 语言代码,这样在分析内核运作流程时会更加直观一些。在使用 function_graph 跟踪器时使用;缺省为对所有函数都生成调用关系序列,可以通过写该文件来指定需要特别关注的函数。
-
buffer_size_kb用于设置单个 CPU 所使用的跟踪缓存的大小。跟踪器会将跟踪到的信息写入缓存,每个 CPU 的跟踪缓存是一样大的。跟踪缓存实现为环形缓冲区的形式,如果跟踪到的信息太多,则旧的信息会被新的跟踪信息覆盖掉。注意,要更改该文件的值需要先将 current_tracer 设置为 nop 才可以。
-
tracing_on用于控制跟踪的暂停。有时候在观察到某些事件时想暂时关闭跟踪,可以将 0 写入该文件以停止跟踪,这样跟踪缓冲区中比较新的部分是与所关注的事件相关的;写入 1 可以继续跟踪。
-
available_filter_functions记录了当前可以跟踪的内核函数。对于不在该文件中列出的函数,无法跟踪其活动。
-
set_ftrace_filter和 set_ftrace_notrace在编译内核时配置了动态 ftrace (选中CONFIG_DYNAMIC_FTRACE 选项)后使用。前者用于显示指定要跟踪的函数,后者则作用相反,用于指定不跟踪的函数。如果一个函数名同时出现在这两个文件中,则这个函数的执行状况不会被跟踪。这些文件还支持简单形式的含有通配符的表达式,这样可以用一个表达式一次指定多个目标函数;注意,要写入这两个文件的函数名必须可以在文件 available_filter_functions 中看到。缺省为可以跟踪所有内核函数,文件 set_ftrace_notrace 的值则为空。
-
available_events 当前编译进内核的可以监控的事件。
-
set_event 跟踪的事件类型,名字必须在available_events列出的跟踪器名字列表中。
trace 当前包含多个跟踪器,用于跟踪不同类型的信息,比如进程调度、中断关闭等。可以查看文件 available_tracers 获取内核当前支持的跟踪器列表。在编译内核时,也可以看到内核支持的跟踪器对应的选项。
nop跟踪器不会跟踪任何内核活动,将 nop 写入 current_tracer 文件可以删除之前所使用的跟踪器,并清空之前收集到的跟踪信息,即刷新 trace 文件。
function跟踪器可以跟踪内核函数的执行情况;可以通过文件 set_ftrace_filter 显示指定要跟踪的函数。function_graph跟踪器可以显示类似 C 源码的函数调用关系图,这样查看起来比较直观一些;可以通过文件
set_grapch_function 显示指定要生成调用流程图的函数。 sched_switch跟踪器可以对内核中的进程调度活动进行跟踪。
irqsoff跟踪器和preemptoff跟踪器分别跟踪关闭中断的代码和禁止进程抢占的代码,并记录关闭的最大时长,preemptirqsoff跟踪器则可以看做它们的组合。
那具体怎么用呢?
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
抓取函数调用流程关系
比如我们抓一次spi输出传输,驱动用的是kernel自带的spidev驱动:
echo 0 > tracing_on
echo function_graph > current_tracer
echo spidev_ioctl> set_graph_function
echo 1 > tracing_on
./spidev_test
echo 0 > tracing_on
cat trace
spidev_ioctrl 被echo到set_grapch_function 属性里面,就可以查看整个spidev_ioctrl 函数的调用流程,但是实际上我们执行的时候会发现一个事情,抓取来的数据太多了,许多无关的、我们不太关心的函数调用关系也被抓进去了,导致抓出来的数据非常乱!
所以最好是利用set_ftrace_filter进行一些过滤。
所以针对这种情况,我们应该这样设置:
echo 0 > tracing_on
echo function_graph > current_tracer
echo *spi* > set_ftrace_filter
echo *dma* >> set_ftrace_filter
echo *spin* >> set_ftrace_notrace
echo 1 > tracing_on
./spidev_test
echo 0 > tracing_on
cat trace
在spi传输里,我们主要关系spi的函数和dma的函数,所以大概抓一下这些字眼即可,还可以按需自己添加过滤语句。
ps:因为spin_lock语句也带了spi字眼,也会被误抓进来,所以最后也把他剔除掉。
最后得出的数据就正常多了:
1) + 41.292 us | spidev_open();
1) | spidev_ioctl() {
1) | spi_setup() {
1) 0.417 us | __spi_validate_bits_per_word.isra.0();
1) | sunxi_spi_setup() {
1) 0.834 us | sunxi_spi_check_cs();
1) 0.875 us | spi_set_cs();
1) 0.625 us | sunxi_spi_cs_control();
1) + 17.125 us | }
1) 0.833 us | spi_set_cs();
1) + 30.458 us | }
1) ! 699.875 us | }
1) 6.916 us | spidev_ioctl();
1) | spidev_ioctl() {
1) | spi_setup() {
1) 0.291 us | __spi_validate_bits_per_word.isra.0();
1) | sunxi_spi_setup() {
1) 0.250 us | sunxi_spi_check_cs();
1) 0.459 us | spi_set_cs();
1) 0.375 us | sunxi_spi_cs_control();
1) + 12.209 us | }
1) 0.291 us | spi_set_cs();
1) + 21.042 us | }
1) + 30.000 us | }
1) 5.750 us | spidev_ioctl();
1) | spidev_ioctl() {
1) | spi_setup() {
1) 0.250 us | __spi_validate_bits_per_word.isra.0();
1) | sunxi_spi_setup() {
1) 0.292 us | sunxi_spi_check_cs();
1) 0.375 us | spi_set_cs();
1) 0.416 us | sunxi_spi_cs_control();
1) + 11.750 us | }
1) 0.291 us | spi_set_cs();
1) + 20.750 us | }
1) + 29.666 us | }
以上仅列举部分信息,有兴趣的小伙伴可以自行尝试。
抓取函数耗时
有时候,也许我们也要通过程序的耗时来分析程序的性能,可以这么做:
同样也是以spidev驱动为例:
echo 0 > tracing_on
echo function_graph > current_tracer
echo spidev_ioctl> set_ftrace_filter
echo 1 > tracing_on
./spidev_test
echo 0 > tracing_on
cat trace
这样可以非常直观的看到spidev_ioctrl 执行的耗时。
/sys/kernel/debug/tracing # cat trace
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
2) ! 665.584 us | spidev_ioctl();
2) 8.125 us | spidev_ioctl();
2) 9.042 us | spidev_ioctl();
2) 5.750 us | spidev_ioctl();
2) 8.791 us | spidev_ioctl();
2) 5.667 us | spidev_ioctl();
2) | spidev_ioctl() {
0) # 1385.625 us | } /* spidev_ioctl */
其中, 带左侧时间显示一块:
延迟比较大的部分,会有+、#等特殊标号:

抓取代码片耗时
有时,我们需要抓取一大片多个函数耗时。可以这么做:
以i2c传输为例,抓取twi_set_start到sunxi_i2c_handler函数的时间:
echo 0 > tracing_on
echo function > current_tracer
echo twi_set_start sunxi_i2c_handler > set_ftrace_filter
echo 1 > tracing_on
i2cget -y 1 0x50 0x01
echo 0 > tracing_on
cat trace
这样我们即可抓取Linux里面执行i2cget的时候去读取0x50地址器件时i2c传输 twi_set_start 函数到 sunxi_i2c_handler 函数的耗时,即两个时间戳相减:
# tracer: function
#
# entries-in-buffer/entries-written: 4/4 #P:1
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
i2cget-810 [000] ...1 21.434049: twi_set_start <-twi_start
i2cget-810 [000] d.h1 21.434073: sunxi_i2c_handler <-__handle_irq_event_percpu
可以看得出耗时为24us。
当然,我们也可以使用do_gettimeofday函数来统计耗时,不过比较麻烦,需要在检测的地方手动添加:
#include <linux/time.h>
struct timeval old_tv;
struct timeval new_tv;
do_gettimeofday(&old_tv);
xxx_functions();
do_gettimeofday(&new_tv);
printk("time is %d us\n", (new_tv.tv_usec-old_tv.tv_usec) + (new_tv.tv_sec-old_tv.tv_sec) * 1000000);
timeval 结构体定义:
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
甚至也可以用ktime_to_us来实现:
s64 before, after;
before = ktime_to_us(ktime_get());
xxx_functions();
after = ktime_to_us(ktime_get());
printk("regu ad time: %d us\n", (u32)(after - before));
方法是多种多样的。
抓取函数里每个子函数时间戳
在第一点里面,抓取函数调用流程里面只能看到每个子函数的耗时,不能看到时间戳,那么如何能看到每个子函数的时间戳呢?和第一点的手段类似:
echo 0 > tracing_on
echo function_graph > current_tracer
echo spidev_ioctl > set_graph_function
echo funcgraph-tail > trace_options
echo 1 > tracing_on
./spidev_test
echo 0 > tracing_on
cat trace
区别操作就是添加了:echo funcgraph-tail > trace_options
主要是在函数结束显示函数名。这样方便使用grep找出函数的执行时间,默认disable:
hide: echo nofuncgraph-tail > trace_options
show: echo funcgraph-tail > trace_options
最后结果非常直观:
# tracer: function_graph
#
# entries-in-buffer/entries-written: 408/408 #P:1
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
spidev_test-1818 [000] .... 221.614092: graph_ent: func=spidev_ioctl
spidev_test-1818 [000] d... 221.614101: graph_ent: func=preempt_count_add
spidev_test-1818 [000] d..1 221.614104: graph_ret: func=preempt_count_add
spidev_test-1818 [000] d..1 221.614107: graph_ent: func=get_device
spidev_test-1818 [000] d..1 221.614108: graph_ret: func=get_device
graph_ent代表函数开始执行,graph_ret代表函数结束。
抓取事件信息
有时候我们需要根据事件来抓取信息,就可以使用set_event了。可以 cat available_events 查看获得支持的跟踪event列表,这个支持的比较多,配置相对简单,只需向set_event写相应值即可。
比如我们要查看spi的事件,可以先看下available_event 里有无spi事件:
/sys/kernel/debug/tracing # cat available_events | grep spi
spi:spi_transfer_stop
spi:spi_transfer_start
spi:spi_message_done
spi:spi_message_start
spi:spi_message_submit
spi:spi_master_busy
spi:spi_master_idle
可以看出,我们这里支持七个spi事件,其对应的头文件在:Linux-4.9/include/trace/events/spi.h文件。感兴趣的可以查看里面的内容实现。这里我们把所有的spi事件都打印出来:
echo 0 > tracing_on
echo spi > set_event
echo 1 > tracing_on
./spidev_test
echo 0 > tracing_on
cat trace
即可看到我们需要跟踪的spi事件:
/sys/kernel/debug/tracing # cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 24/24 #P:1
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
sh-811 [000] d..1 20.800876: spi_message_submit: spi0.0 de49faf4
sh-811 [000] d..1 20.801005: spi_message_submit: spi0.0 de49fab0
sh-811 [000] d..1 20.801196: spi_message_submit: spi0.0 de49fa18
sh-811 [000] d..1 20.801346: spi_message_submit: spi0.0 de49fa18
sh-811 [000] d..1 20.801437: spi_message_submit: spi0.0 de49faf4 

![[附源码]Python计算机毕业设计Django甜品购物网站](https://img-blog.csdnimg.cn/fdfc756dec994bd7b6bf7323bb8d70ca.png)






![[附源码]计算机毕业设计基于Springboot药品仓库及预警管理系统](https://img-blog.csdnimg.cn/d9c8891f9d974ba2b089ebc814e5e14e.png)