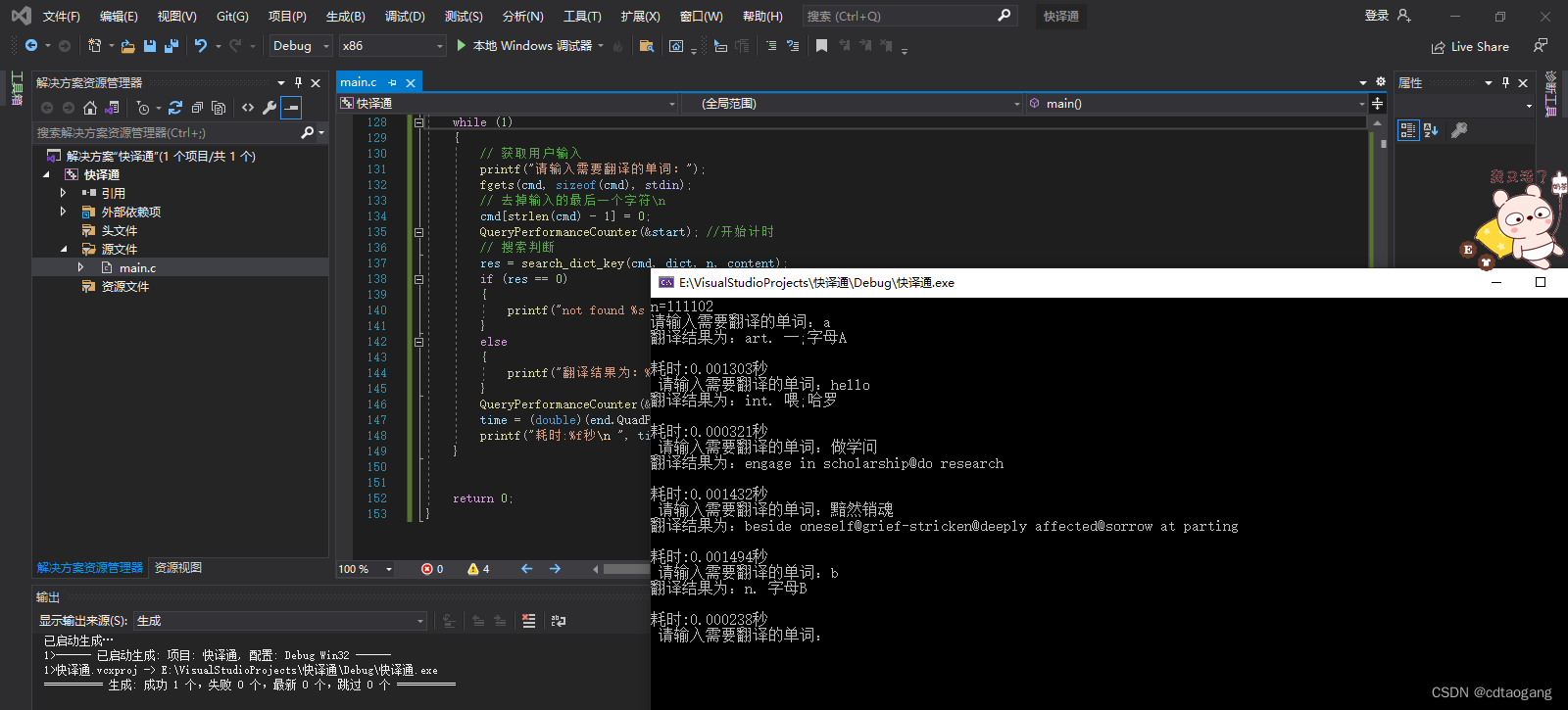
一.match
re.match 是从字符串的起始位置匹配一个模式,
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
re.match(pattern, string, flags=0)pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位或 ( | ) 来指定,例如:re.L | re.M 。
| 修饰符 | 描述 |
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 为了增加可读性,忽略空格和' # '后面的注释 |
import re
print(re.match('www', 'www.baidu.com'))
# 在起始位置匹配 返回 <re.Match object; span=(0, 3), match='www'>
print(re.match('com', 'www.baidu.com'))
# 不在起始位置匹配 返回 None
print(re.match('www', 'www.baidu.com').span())
# 匹配成功字符起始位置 返回 (0, 3)
print(re.match('www', 'www.baidu.com').group())
# 获取匹配成功字符串 返回 www二.search
re.search 是扫描整个字符串并返回第一个成功的匹配,
匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.search(pattern, string, flags=0)pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
print(re.search('www', 'www.baidu.com'))
# 在起始位置匹配 返回 <re.Match object; span=(0, 3), match='www'>
print(re.search('com', 'www.baidu.com'))
# 不在起始位置匹配 返回 <re.Match object; span=(0, 3), match='www'>
print(re.search('www', 'www.baidu.com').span())
# 匹配成功字符起始位置 返回 (0, 3)
print(re.search('com', 'www.baidu.com').group())
# 获取匹配成功字符串 返回 com注意:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
三.sub
re.sub用于替换字符串中的匹配项,结果返回替换后的字符串。
re.sub(pattern, repl, string, count=0, flags=0)pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
print(re.sub('w', 'www', 'w.baidu.com'))
# 匹配成功替换字符串(默认替换1次) 返回 www.baidu.com
print(re.sub('w', 'WWW', 'w.baidu.www', 2))
# 匹配成功替换指定次数字符串 返回 WWW.baidu.WWWww四.subn
re.subn和sub相同,都是用于替换字符串中的匹配项,只不过subn的结果返回一个元组包含替换后的字符串和替换次数。
re.subn(pattern, repl, string, count=0, flags=0)pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
print(re.subn('w', 'www', 'w.baidu.com'))
# 匹配成功替换字符串(默认替换1次) 返回 (www.baidu.com,1)
print(re.subn('w', 'WWW', 'w.baidu.www', 2))
# 匹配成功替换指定次数字符串 返回 (WWW.baidu.WWWww,2)五.compile
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,
供 match() 和 search() 这两个函数使用。
re.compile(pattern[, flags])pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等。
import re
x = re.compile('www')
print(re.match(x,'www.baidu.com'))
# <re.Match object; span=(0, 3), match='www'>
y = re.compile('com')
print(re.search(y,'www.baidu.com'))
# <re.Match object; span=(10, 13), match='com'>六.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,
则返回元组列表,如果没有找到匹配的,则返回空列表。
findall(string[, pos[, endpos]])string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
import re
x = re.compile('www')
print(re.findall(x,'www.baidu.www'))
# ['www', 'www']
x = re.compile('yyy')
print(re.findall(x,'www.baidu.www'))
# []注意:
match 和 search 是匹配一次 findall 匹配所有。
七.finditer
在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)pattern:匹配的正则表达式
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
x = re.compile('www')
y = re.finditer(x,'www.baidu.www')
for i in y:
print(i,i.group())
# <re.Match object; span=(0, 3), match='www'> www
# <re.Match object; span=(10, 13), match='www'> www
八.split
split 方法按照能够匹配的子串将字符串分割后返回列表。
re.split(pattern, string[, maxsplit=0, flags=0])pattern: 匹配的正则表达式
string: 要匹配的字符串。
maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
x = re.compile(r'\.|:')
print(re.split(x, 'www.baidu:com'))
# ['www', 'baidu', 'com']九.表达式模式
| 模式 | 描述 |
| ^ | 匹配字符串开头 。 |
| $ | 匹配字符串结尾 。 |
| . | 匹配除 '\n'之外的任何单个字符。要匹配 '\n' 请使用象 '[.\n]' 的模式 。 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 。 |
| * | 匹配前一个字符出现0次或者无限次,即可有可无 。 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 。 |
| | | 匹配左右任意一个表达式 。 |
| [ ] | 匹配[ ]中列举的字符 。 |
| ( ) | 将括号中字符作为一个分组进行匹配 。 |
| { } | 匹配前一个字符出现的次数。 |
| \A | 用于匹配字符的开头,等同于 ^ 。 |
| \b | 匹配单词结尾,包括各种空白字符或者字符串结尾 。 |
| \B | 匹配非边界字符。 |
| \d | 匹配一个数字字符。等价于 [0-9] 。 |
| \D | 匹配一个非数字字符。等价于 [^0-9] 。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] 。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v] 。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]' 。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]' 。 |
| \Z | 用于匹配字符的结尾,等同于 $ 。 |
十.表达式应用
1.字符 '^' 匹配以指定字符串开头,并返回匹配成功字符串 。
import re
x = re.compile(r'^w')
for i in ['www', 'ywy']:
print(re.search(x, i))
# <re.Match object; span=(0, 1), match='w'>
# None2.字符 '$' 匹配以指定字符串的结尾,并返回匹配成功字符串 。
import re
x = re.compile(r'w$')
for i in ['www', 'ywy']:
print(re.search(x, i))
# <re.Match object; span=(2, 3), match='w'>
# None3.字符 '.' 代表任何一个字符,但是没有特别声明时不代表字符'\n' 。
import re
x = re.compile(r'1.3')
for i in ['12333', '1\t333', '1\n333']:
print(re.search(x, i))
# <re.Match object; span=(0, 3), match='123'>
# <re.Match object; span=(0, 3), match='1\t3'>
# None4.字符 '+' 重复前面一个匹配字符一次或者多次 。
import re
x = re.compile(r'\d+')
for i in ['123', '45x']:
print(re.search(x, i))
# <re.Match object; span=(0, 3), match='123'>
# <re.Match object; span=(0, 2), match='45'>5.字符 '*' 重复前面一个匹配字符零次或者多次 。
import re
x = re.compile(r'12*')
for i in ['11222', '12255']:
print(re.search(x, i))
# <re.Match object; span=(0, 1), match='1'>
# <re.Match object; span=(0, 3), match='122'>
x = re.compile(r'12+')
for i in ['11222', '12255']:
print(re.search(x, i))
# <re.Match object; span=(1, 5), match='1222'>
# <re.Match object; span=(0, 3), match='122'>注意:
r'12+'匹配是'12',而r'12*'匹配的是'1',因为'2'可以重复零次,但'12+'却要求'2'重复一次以上。
6. 字符 '?' 重复前面一个匹配字符零次或者一次 。
import re
x = re.compile(r'12?')
for i in ['12122', '31529']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='12'>
# <re.Match object; span=(1, 2), match='1'>7.字符 '|' 代表或,即把左右分成两个部分,匹配左右任意⼀个表达式 。
import re
x = re.compile(r'12|21')
for i in ['12333', '21333']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='12'>
# <re.Match object; span=(0, 2), match='21'>8. 字符 '[ ]' 中的字符是任选择一个,如果字符ASCll码中连续的一组,那么可以使用 '-' 字符连接,例如[0-9]表示0-9的其中一个数字,[A-Z]表示A-Z的其中一个大写字符,[0-9A-z]表示0-9的其中一个数字或者A-z的其中一个大写字符。
import re
x = re.compile(r'[0-9]')
for i in ['123', '45', '78']:
print(re.search(x, i))
# 匹配数字0-9之间的任意数字。
# <re.Match object; span=(0, 1), match='1'>
# <re.Match object; span=(0, 1), match='4'>
x = re.compile(r'[A-Z]')
for i in ['Abc', 'aBc']:
print(re.search(x, i))
# 匹配A-Z之间任意大写字母。
# <re.Match object; span=(0, 1), match='A'>
# <re.Match object; span=(1, 2), match='B'>
x = re.compile(r'[A-z]')
for i in ['Abc', 'abC']:
print(re.search(x, i))
# 匹配A-z之间任意大写或小写字母。
# <re.Match object; span=(0, 1), match='A'>
# <re.Match object; span=(0, 1), match='a'>
9. 使用括号( )可以把( )看出一个整体,经常与'+'、'*'、'?'连续使用,对( )部分进行重复匹配 。
x = re.compile(r'(ab)+')
for i in ['ababc', 'cababc']:
print(re.search(x, i))
# <re.Match object; span=(0, 4), match='abab'>
# <re.Match object; span=(1, 5), match='abab'>
x = re.compile(r'(ab)*')
for i in ['ababc', 'abcabc']:
print(re.search(x, i))
# <re.Match object; span=(0, 4), match='abab'>
# <re.Match object; span=(0, 2), match='ab'>
x = re.compile(r'(ab)?')
for i in ['ababc', 'abcabc']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='ab'>
# <re.Match object; span=(0, 2), match='ab'>10.字符 '{ }' 用于匹配前一个字符出现的次数 。
import re
for i in ['abc','abb','acb']:
print(re.search(r'b{1}', i))
# <re.Match object; span=(1, 2), match='b'>
# <re.Match object; span=(1, 2), match='b'>
# <re.Match object; span=(2, 3), match='b'>
import re
for i in ['abc','abb','acb']:
print(re.search(r'b{2}', i))
# None
# <re.Match object; span=(1, 3), match='bb'>
# None11.特殊字符使用 '\' 引导,例如 '\r'、'\n'、'\t' 等分别表示回车、换行、制表符号 。
import re
x = re.compile(r'\n|\t|\r')
for i in ['12\r33','12\n33', '12\t33']:
print(re.search(x, i))
# <re.Match object; span=(2, 3), match='\r'>
# <re.Match object; span=(2, 3), match='\n'>
# <re.Match object; span=(2, 3), match='\t'>12. '^' 出现在[]第首字符位置代表取反,例如 '[ ^x0-9]' 表示即不是x,也不是0-9数字的字符串 。
import re
x = re.compile(r'[^a0-9]')
for i in ['abc', 'c16']:
print(re.search(x, i))
# <re.Match object; span=(1, 2), match='b'>
# <re.Match object; span=(0, 1), match='c'>13.字符 '\A' 用于匹配字符的开头,等同于 ^ 。
import re
x = re.compile(r'\A21')
for i in ['212122', '122555']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='21'>
# None14.字符 '\b' 表示单词结尾,单词结尾包括各种空白字符或者字符串结尾 。
import re
x = re.compile(r'b\b')
for i in ['a b c', 'ab c', 'abb']:
print(re.search(x, i))
# <re.Match object; span=(2, 3), match='b'>
# <re.Match object; span=(1, 2), match='b'>
# <re.Match object; span=(2, 3), match='b'>15.字符 ' \B '匹配非边界字符 。
import re
for i in ['abc','abb','acb']:
print(re.search(r'b\B', i))
# <re.Match object; span=(1, 2), match='b'>
# <re.Match object; span=(1, 2), match='b'>
# None16.字符 ' \d ' 匹配0~9之间的一个数值,并返回匹配成功的数字 。
import re
x = re.compile(r'\d')
for i in ['123', 'x5y']:
print(re.search(x, i))
# <re.Match object; span=(0, 1), match='1'>
# <re.Match object; span=(1, 2), match='5'>17.字符 '\D' 匹配一个非数字字符。等价于 '[^0-9]' 。
x = re.compile(r'\D+')
for i in ['a12', 'b_56']:
print(re.search(x, i))
# <re.Match object; span=(0, 1), match='a'>
# <re.Match object; span=(0, 2), match='b_'>18.字符 '\s' 匹配任何空白字符,等价'[\r\n\t\f\v]' 。
import re
x = re.compile(r'\s+')
for i in ['a\r\n\tb', 'c\f\vc']:
print(re.search(x, i))
# <re.Match object; span=(1, 4), match='\r\n\t'>
# <re.Match object; span=(1, 3), match='\x0c\x0b'>19.字符 '\S' 匹配任何非空白字符。等价于 '[^\f\n\r\t\v]' 。
import re
x = re.compile(r'\S+')
for i in ['aB\r\n\tb', 'cD\f\vc']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='aB'>
# <re.Match object; span=(0, 2), match='cD'>20.字符 '\w' 匹配包括下划线子内的单词字符,等价于'[a-zA-Z0-9_]' 。
x = re.compile(r'\w+')
for i in ['a123', 'b_456']:
print(re.search(x, i))
# <re.Match object; span=(0, 4), match='a123'>
# <re.Match object; span=(0, 5), match='b_456'>21.字符 '\W' 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]' 。
import re
x = re.compile(r'\W+')
for i in ['@#a123', '&*b_456']:
print(re.search(x, i))
# <re.Match object; span=(0, 2), match='@#'>
# <re.Match object; span=(0, 2), match='&*'>22.字符 '\Z' 用于匹配字符的结尾,等同于 $ 。
import re
x = re.compile(r'21\Z')
for i in ['121221', '122555']:
print(re.search(x, i))
# <re.Match object; span=(4, 6), match='21'>
# None

![[附源码]计算机毕业设计基于Springboot药品仓库及预警管理系统](https://img-blog.csdnimg.cn/d9c8891f9d974ba2b089ebc814e5e14e.png)




![[附源码]Python计算机毕业设计Django微录播室预约管理系统](https://img-blog.csdnimg.cn/5bb07b1fae43432ba57d2cafb26abde1.png)

![[附源码]Python计算机毕业设计Django农产品销售网站](https://img-blog.csdnimg.cn/f80925e471424e7c8e050dbb9ab44288.png)