说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家!
文件的随机读写
1) fseek
- 表头文件:
#include <stdio.h> - 定义函数:
int fseek(FILE *stream, long offset, int whence); - 功能:移动文件流(文件光标)的读写位置。
- 参数:
stream:已经打开的文件指针
offset:根据whence来移动的位移数(偏移量),可以是正数,也可以负数,如果正数,则相对于whence往右移动,如果是负数,则相对于whence往左移动。如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过了文件末尾,再次写入时将增大文件尺寸。
whence:其取值如下:
SEEK_SET:从文件开头移动offset个字节
SEEK_CUR:从当前位置移动offset个字节
SEEK_END:从文件末尾移动offset个字节 - 返回值:
成功:0
失败:-1
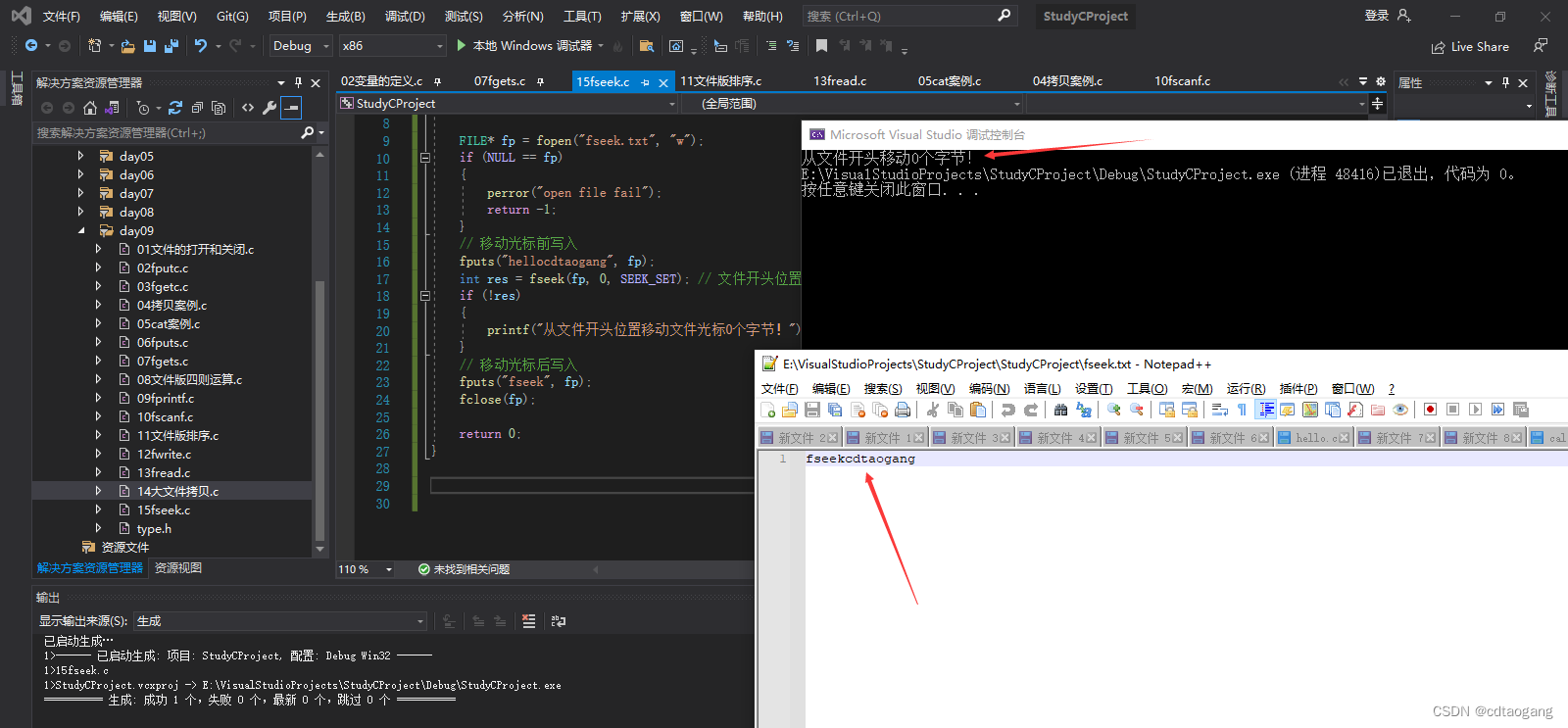
示例1: SEEK_SET:从文件开头移动offset个字节(会覆盖原有位置上的字符)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE* fp = fopen("fseek.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 移动光标前写入
fputs("hellocdtaogang", fp);
int res = fseek(fp, 0, SEEK_SET); // 文件开头位置
if (!res)
{
printf("从文件开头位置移动文件光标0个字节!");
}
// 移动光标后写入
fputs("fseek", fp);
fclose(fp);
return 0;
}
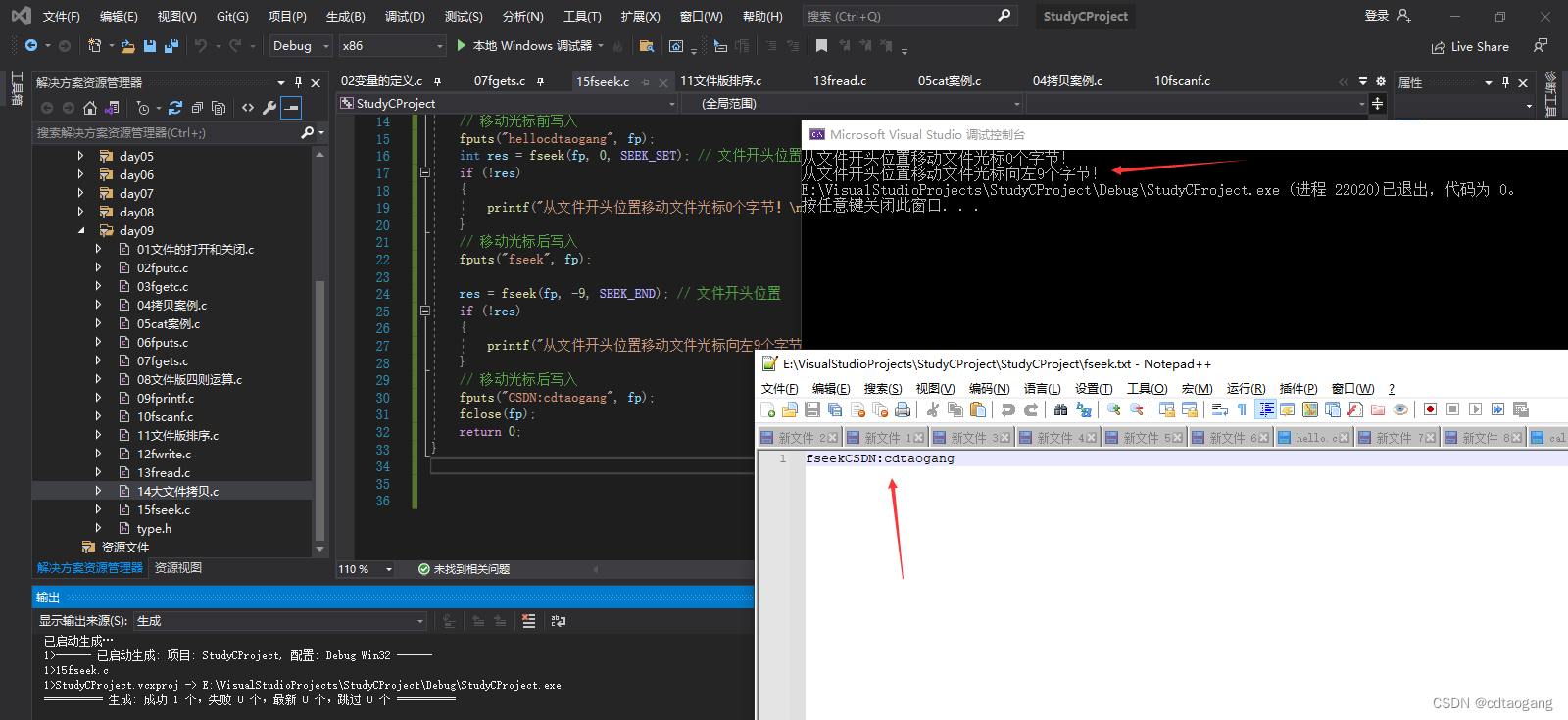
示例2: SEEK_END:从文件末尾移动offset个字节(会覆盖原有位置上的字符)
int main()
{
FILE* fp = fopen("fseek.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 移动光标前写入
fputs("hellocdtaogang", fp);
int res = fseek(fp, 0, SEEK_SET); // 文件开头位置
if (!res)
{
printf("从文件开头位置移动文件光标0个字节!\n");
}
// 移动光标后写入
fputs("fseek", fp);
res = fseek(fp, -9, SEEK_END); // 文件开头位置
if (!res)
{
printf("从文件开头位置移动文件光标向左9个字节!");
}
// 移动光标后写入
fputs("CSDN:cdtaogang", fp);
fclose(fp);
return 0;
}
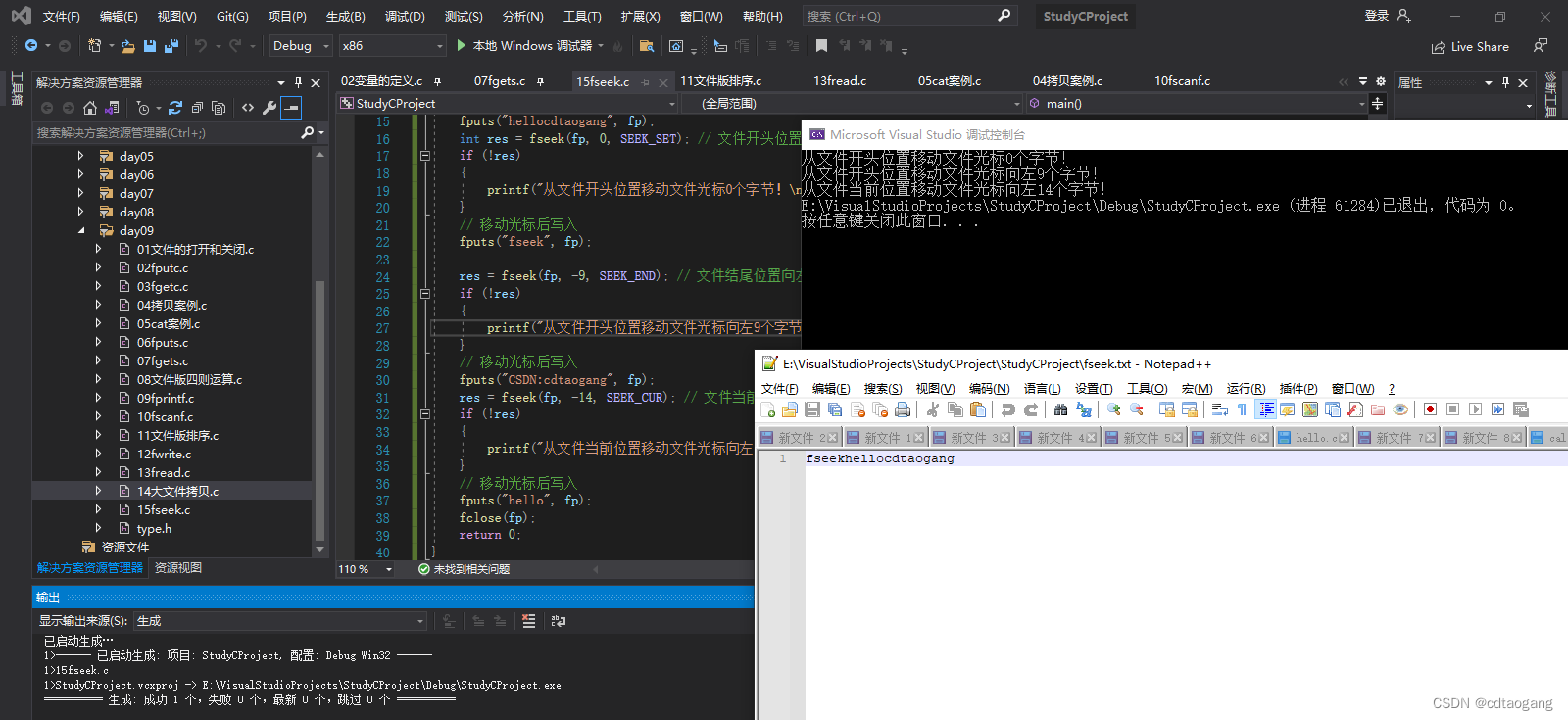
示例3: SEEK_END:从当前位置移动offset个字节(会覆盖原有位置上的字符)
int main()
{
FILE* fp = fopen("fseek.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 移动光标前写入
fputs("hellocdtaogang", fp);
int res = fseek(fp, 0, SEEK_SET); // 文件开头位置
if (!res)
{
printf("从文件开头位置移动文件光标0个字节!\n");
}
// 移动光标后写入
fputs("fseek", fp);
res = fseek(fp, -9, SEEK_END); // 文件结尾位置向左移动9个字节
if (!res)
{
printf("从文件开头位置移动文件光标向左9个字节!\n");
}
// 移动光标后写入
fputs("CSDN:cdtaogang", fp);
res = fseek(fp, -14, SEEK_CUR); // 文件当前位置向左移动14个字节
if (!res)
{
printf("从文件当前位置移动文件光标向左14个字节!");
}
// 移动光标后写入
fputs("hello", fp);
fclose(fp);
return 0;
}
2) rewind
- 表头文件:
#include <stdio.h> - 定义函数:
void rewind(FILE *stream); - 功能:把文件流(文件光标)的读写位置移动到文件开头;就相当于
fseek(fp, 0, SEEK_SET);一样效果 - 参数:
stream:已经打开的文件指针 - 返回值:
无返回值
示例: 把文件光标的读写位置移动到文件开头
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE* fp = fopen("rewind.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 移动光标前写入
fputs("nnnnncdtaogang", fp);
rewind(fp); // 把文件光标的读写位置移动到文件开头
// 移动光标后写入
fputs("hello", fp);
return 0;
}
3) ftell
- 表头文件:
#include <stdio.h> - 定义函数:
long ftell(FILE *stream); - 功能:获取文件流(文件光标)的读写位置。
- 参数:
stream:已经打开的文件指针 - 返回值:
成功:当前文件流(文件光标)的读写位置
失败:-1
示例: 获取文件流(文件光标)的读写位置,同时也可以根据返回值测试出该文件有多少个字符(字节)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE* fp = fopen("rewind.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 移动光标前写入
fputs("nnnnncdtaogang", fp);
rewind(fp); // 把文件光标的读写位置移动到文件开头
// 移动光标后写入
fputs("hello", fp);
// 获取文件流(文件光标)的读写位置
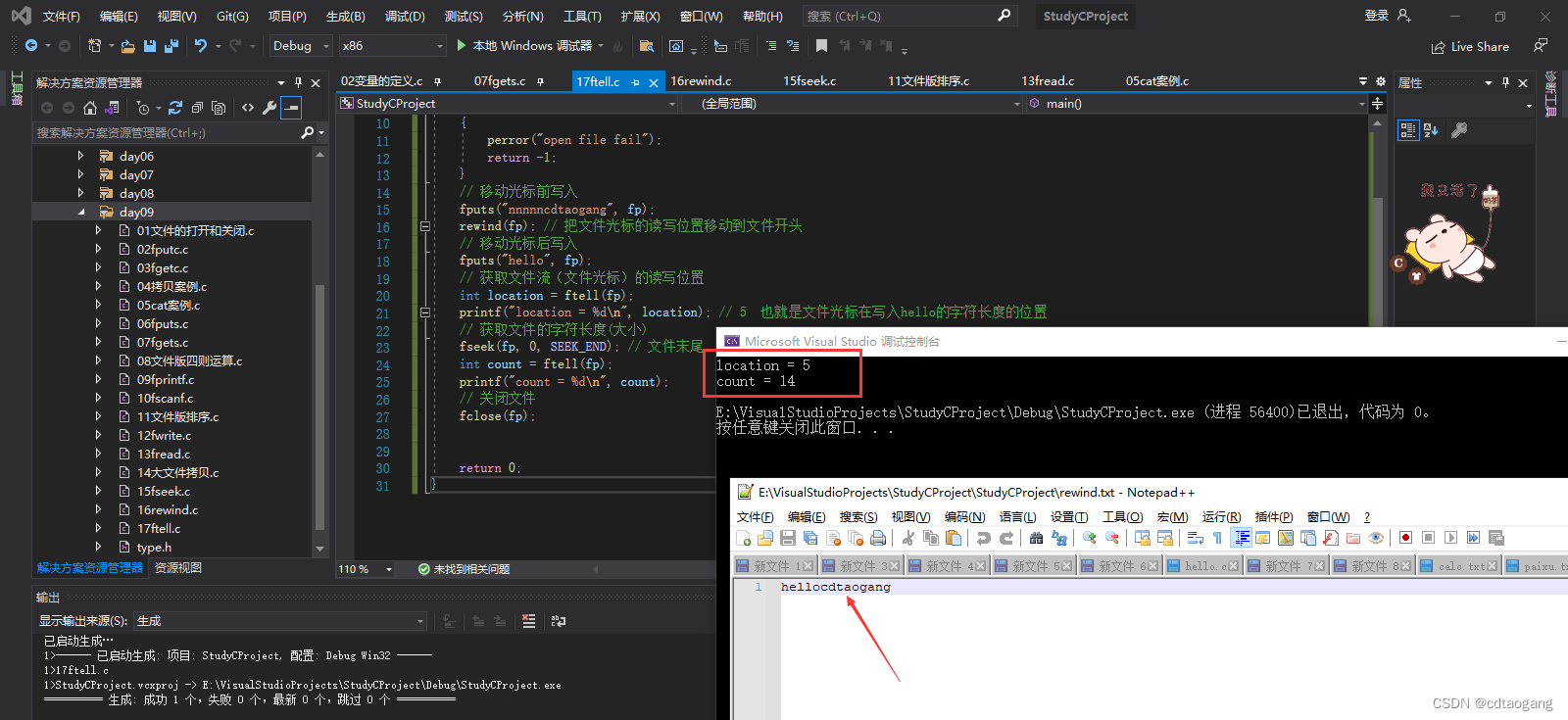
int location = ftell(fp);
printf("location = %d\n", location); // 5 也就是文件光标在写入hello的字符长度的位置
// 获取文件的字符长度(大小)
fseek(fp, 0, SEEK_END); // 文件末尾
int count = ftell(fp);
printf("count = %d\n", count);
// 关闭文件
fclose(fp);
return 0;
}
获取文件状态
stat
- 表头文件1:
#include <sys/types.h> - 表头文件2:
#include <sys/stat.h> - 定义函数:
int stat(const char *path, struct stat *buf); - 功能:获取文件状态信息
- 参数:
path:文件名
buf:保存文件信息的结构体 - 返回值:
成功:0
失败:-1
struct stat内各参数的说明:
struct stat {
dev_t st_dev; //文件的设备编号
ino_t st_ino; //节点
mode_t st_mode; //文件的类型和存取的权限
nlink_t st_nlink; //连到该文件的硬连接数目,刚建立的文件值为1
uid_t st_uid; //用户ID
gid_t st_gid; //组ID
dev_t st_rdev; //(设备类型)若此文件为设备文件,则为其设备编号
off_t st_size; //文件字节数(文件大小)
unsigned long st_blksize; //块大小(文件系统的I/O 缓冲区大小)
unsigned long st_blocks; //块数
time_t st_atime; //最后一次访问时间
time_t st_mtime; //最后一次修改时间
time_t st_ctime; //最后一次改变时间(指属性)
};
示例1: 使用stat函数判断文件是否存在
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
struct stat buf;
int res = 0;
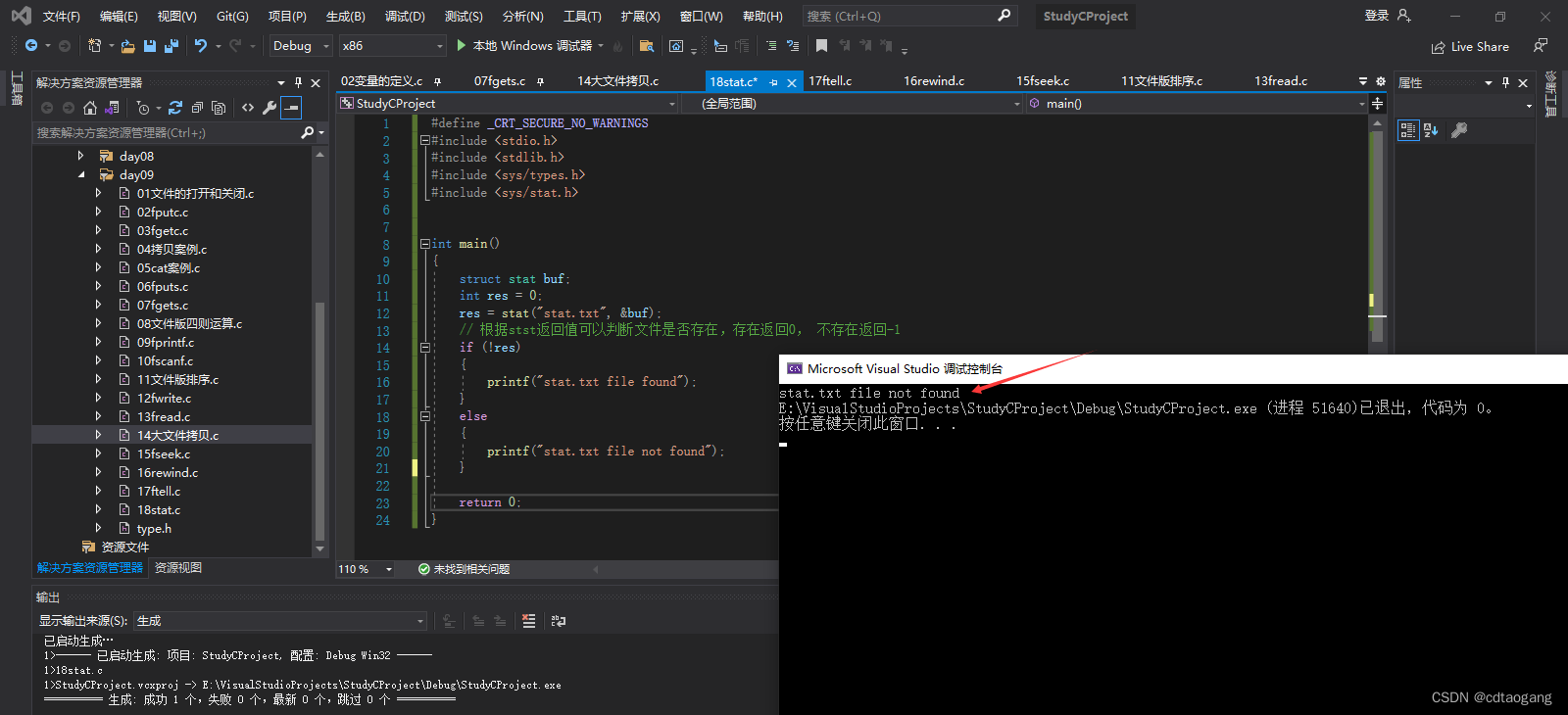
res = stat("stat.txt", &buf);
// 根据stst返回值可以判断文件是否存在,存在返回0, 不存在返回-1
if (!res)
{
printf("stat.txt file found");
}
else
{
printf("stat.txt file not found");
}
return 0;
}
示例2: 使用stat函数判断文件是否存在,存在则返回文件大小
int main()
{
struct stat buf;
int res = 0;
res = stat("stat.txt", &buf);
// 根据stst返回值可以判断文件是否存在,存在返回0, 不存在返回-1
if (!res)
{
printf("stat.txt file found");
}
else
{
printf("stat.txt file not found\n");
}
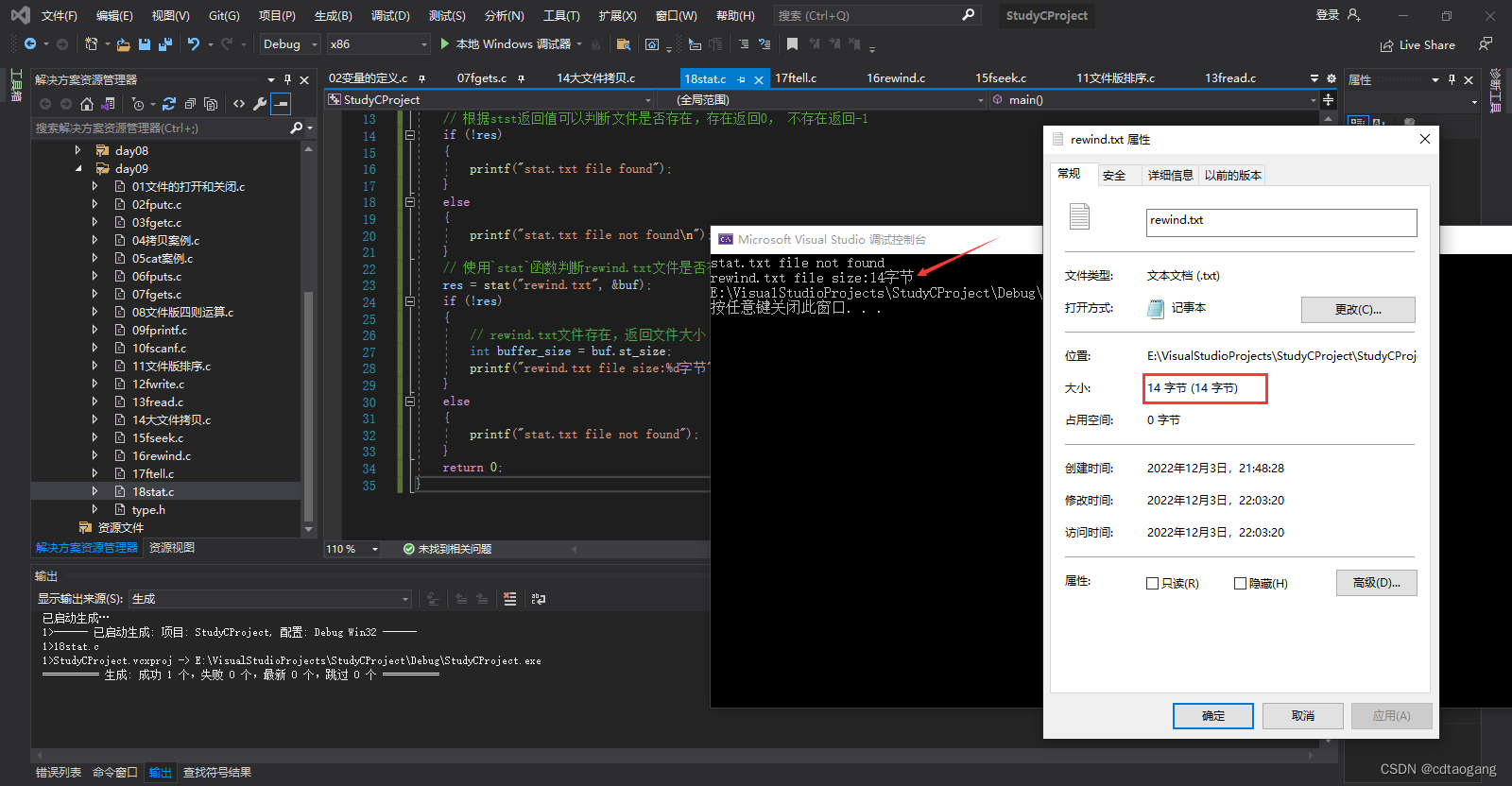
// 使用`stat`函数判断rewind.txt文件是否存在,存在则返回文件大小
res = stat("rewind.txt", &buf);
if (!res)
{
// rewind.txt文件存在,返回文件大小
int buffer_size = buf.st_size;
printf("rewind.txt file size:%d字节", buffer_size);
}
else
{
printf("stat.txt file not found");
}
return 0;
}
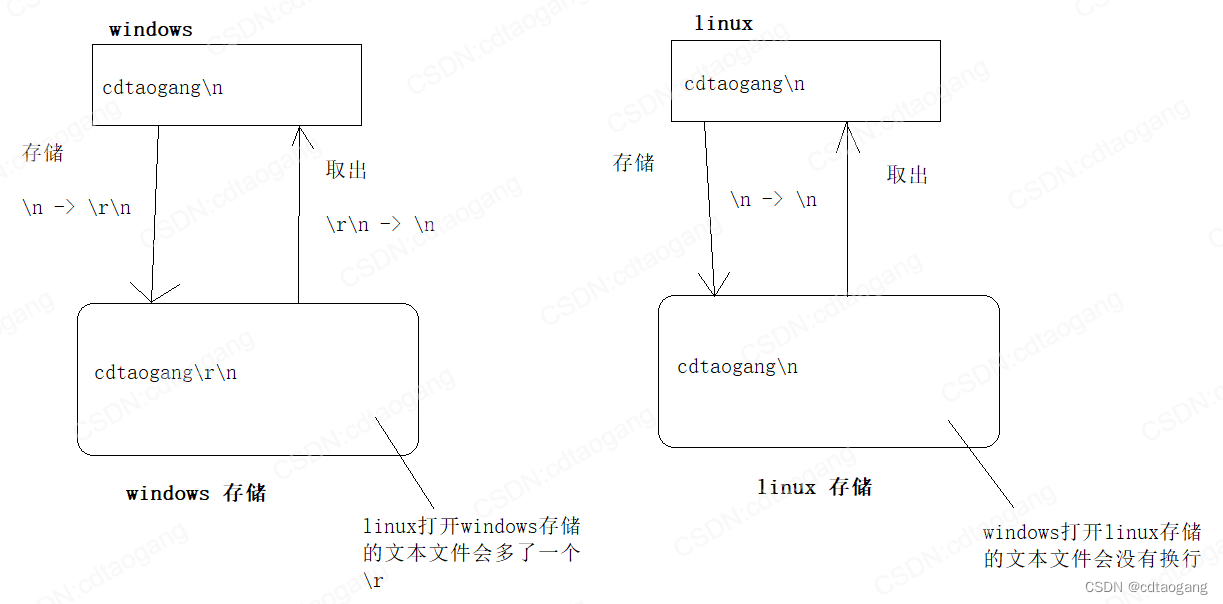
Windows和Linux文本文件区别
b是二进制模式的意思,b只是在Windows有效,在Linux用r和rb的结果是一样的Unix和Linux下所有的文本文件行都是\n结尾,而Windows所有的文本文件行都是\r\n结尾- 在
Windows平台下,以 “ 文本 ” 方式打开文件,不加b: - 当读取文件的时候,系统会将所有的 “
\r\n” 转换成 “\n” - 当写入文件的时候,系统会将 “
\n” 转换成 “\r\n” 写入 - 以 “ 二进制 ” 方式打开文件,则读\写都不会进行这样的转换
- 在
Unix/Linux平台下,“ 文本 ” 与 “ 二进制 ” 模式没有区别,“\r\n” 作为两个字符原样输入输出
判断文本文件是Linux格式还是Windows格式:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main(int argc, char** args)
{
if (argc < 2)
return 0;
FILE* p = fopen(args[1], "rb");
if (!p)
return 0;
char a[1024] = { 0 };
fgets(a, sizeof(a), p);
int len = 0;
while (a[len])
{
if (a[len] == '\n')
{
if (a[len - 1] == '\r')
{
printf("windows file\n");
}
else
{
printf("linux file\n");
}
}
len++;
}
fclose(p);
return 0;
设置运行命令参数:右击项目-属性-调试
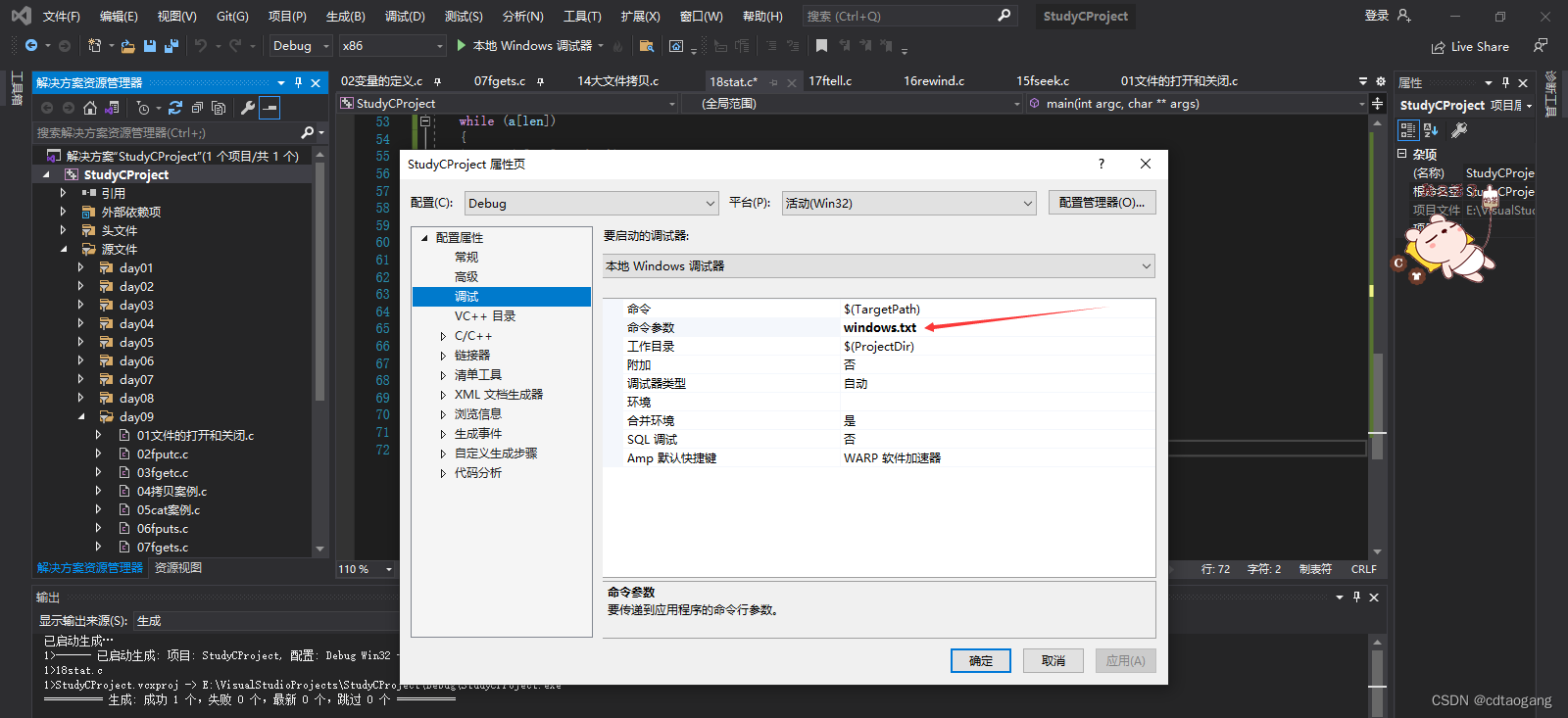
运行代码查看结果

删除文件、重命名文件名
1) 删除文件
- 表头文件:
#include <stdio.h> - 定义函数:
int remove(const char *pathname); - 功能:删除文件
- 参数:
pathname:文件名 - 返回值:
成功:0
失败:-1
示例: 使用remove函数删除文件,并根据返回值判断是否删除成功
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
char* fileName = "remove.txt";
FILE* fp = fopen(fileName, "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
// 关闭文件
fclose(fp);
// 删除文件
int res = 0;
res = remove(fileName);
if (!res)
{
printf("%s 文件删除成功!", fileName);
}
return 0;
}
2) 重命名文件名
- 表头文件:
#include <stdio.h> - 定义函数:
int rename(const char *oldpath, const char *newpath); - 功能:把
oldpath的文件名改为newpath - 参数:
oldpath:旧文件名
newpath:新文件名 - 返回值:
成功:0
失败:-1
示例: 使用rename函数对文件进行重命名,并根据返回值判断是否重命名成功
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
int res = 0;
res = rename("hellocdtaogang.txt", "cdtaogang.txt");
if (!res)
{
printf("重命名成功!");
}
return 0;
}
文件缓冲区
1) 概述
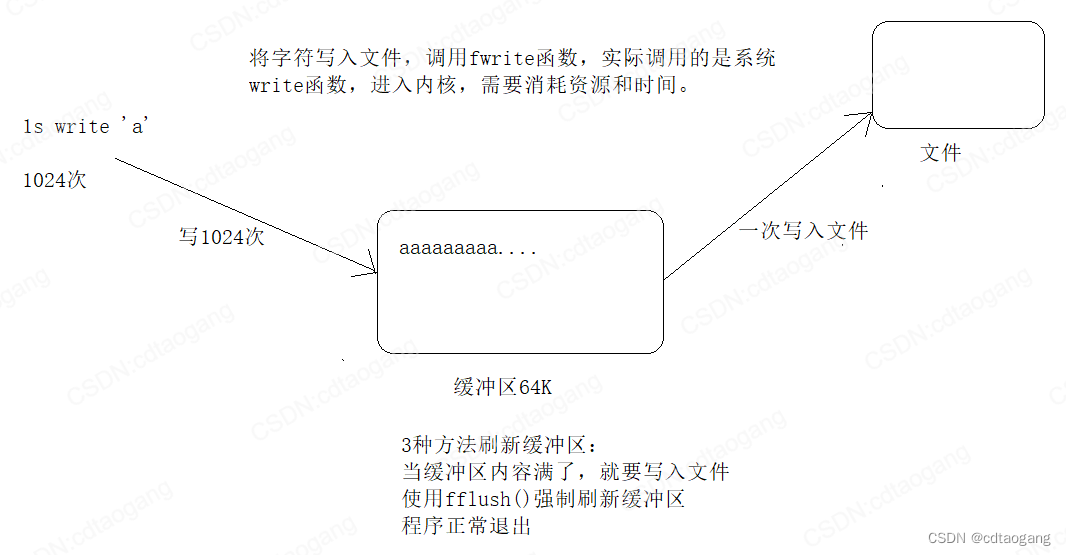
缓冲区:就是内存中的一块临时的空间。
ANSI C标准采用 “ 缓冲文件系统 ” 处理数据文件。
所谓缓冲文件系统是指系统自动地在内存区为程序中每一个正在使用的文件开辟一个文件缓冲区从内存向磁盘输出数据必须先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘去。
如果从磁盘向计算机读入数据,则一次从磁盘文件将一批数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(给程序变量) 。
2) 磁盘文件的存取

- 磁盘文件,一般保存在硬盘、U盘等掉电不丢失的磁盘设备中,在需要时调入内存
- 在内存中对文件进行编辑处理后,保存到磁盘中
- 程序与磁盘之间交互,不是立即完成,系统或程序可根据需要设置缓冲区,以提高存取效率
3) 更新缓冲区
- 表头文件:
#include <stdio.h> - 定义函数:
int fflush(FILE *stream);
功能:更新缓冲区,让缓冲区的数据立马写到文件中。
参数:
stream:文件指针
返回值:
成功:0
失败:-1
示例1: 使用fputs函数对文件进行数据写入,通过死循环让程序假死状态下来查看文件是否被写入数据,如果没有被写入数据,说明数据被存到了缓冲区。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE* fp = fopen("demo.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
fputs("hellocdtaogang", fp); // 不会马上写入文件,先存至缓冲区
while (1);
return 0;
}
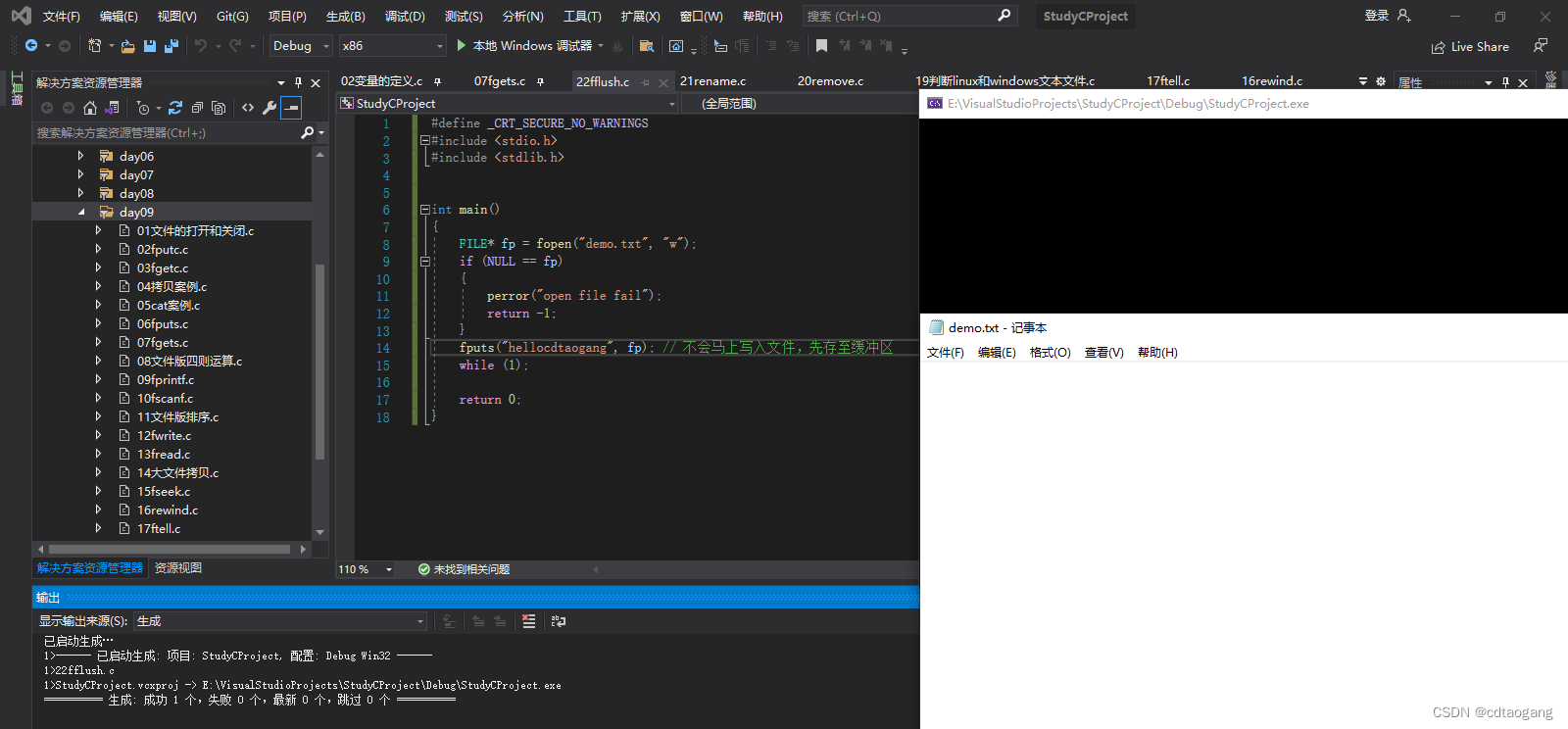
此时如果ctrl+c关闭程序,那么缓冲区将被释放
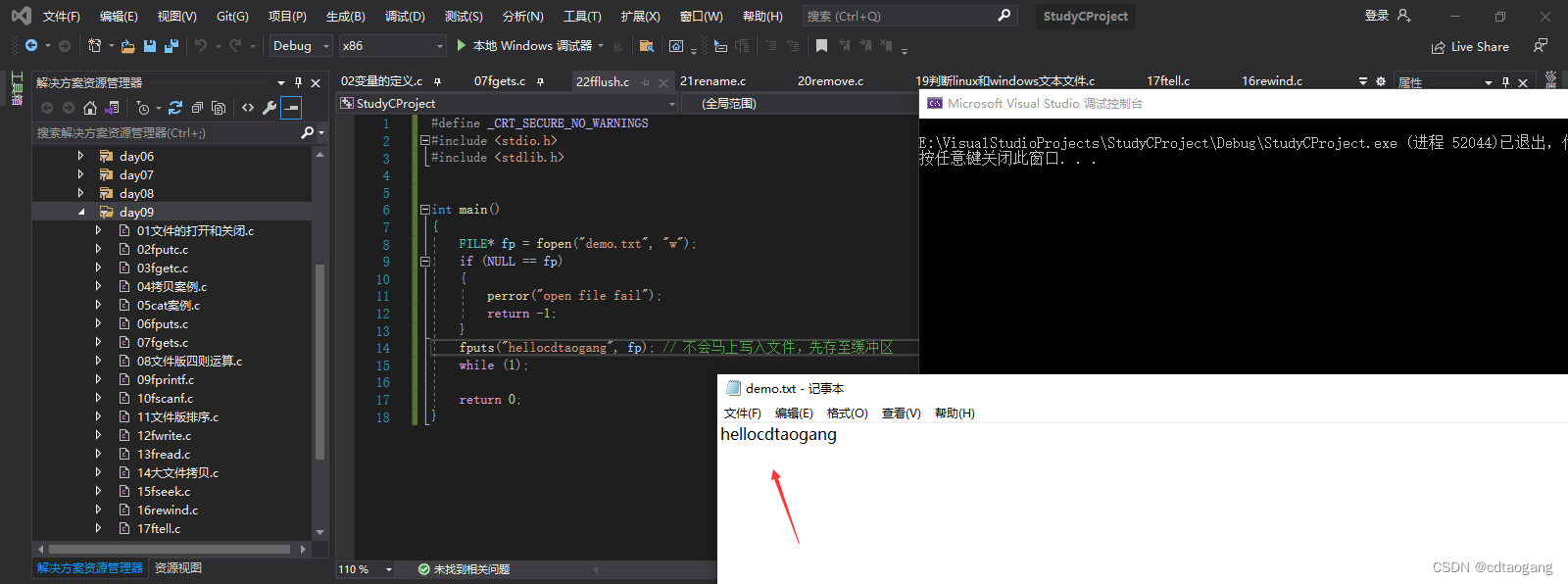
示例2: 调用fflush函数来强制刷新缓冲区到文件中
int main()
{
FILE* fp = fopen("demo.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
fputs("CSDN:cdtaogang", fp); // 不会马上写入文件,先存至缓冲区
// 调用fflush函数来强制刷新缓冲区内容到fp里面
fflush(fp);
while (1);
return 0;
}
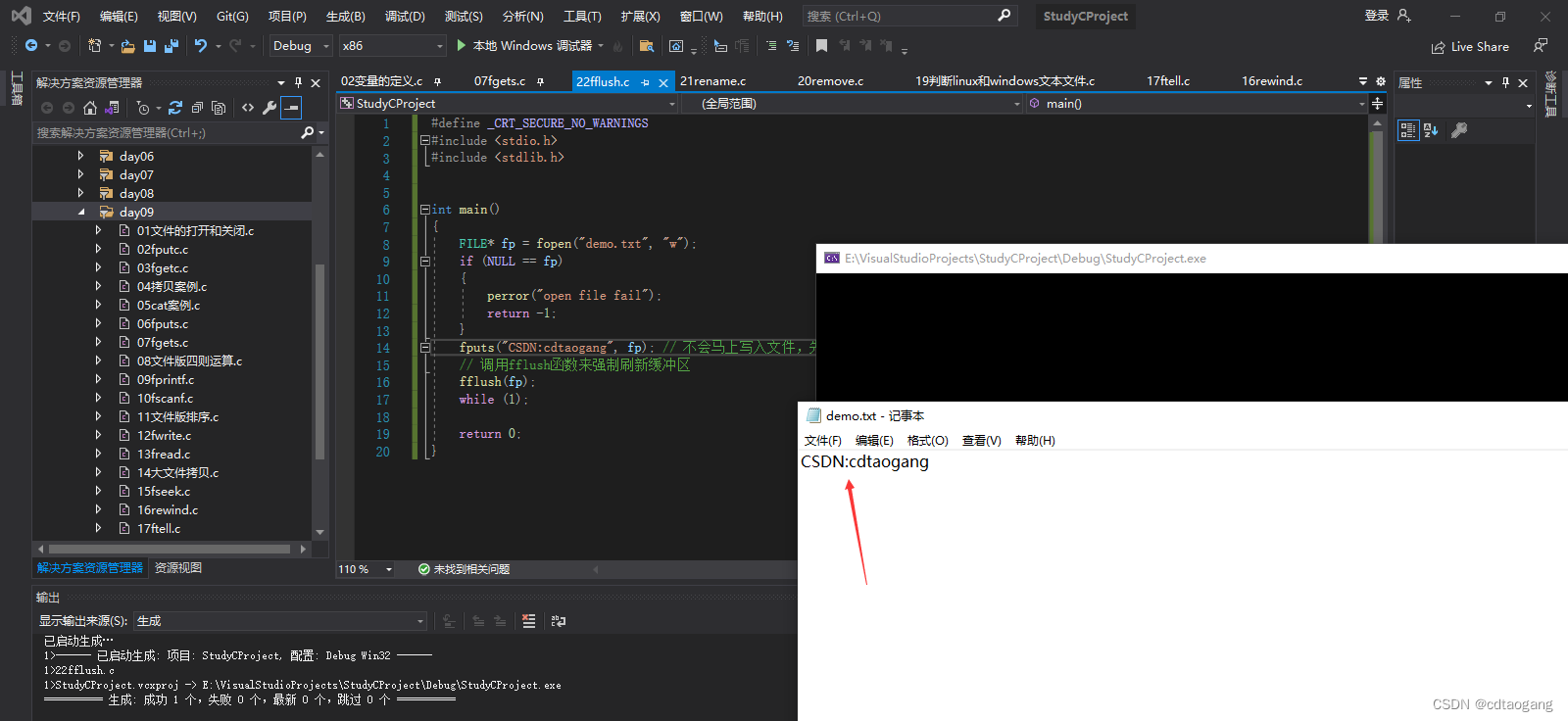
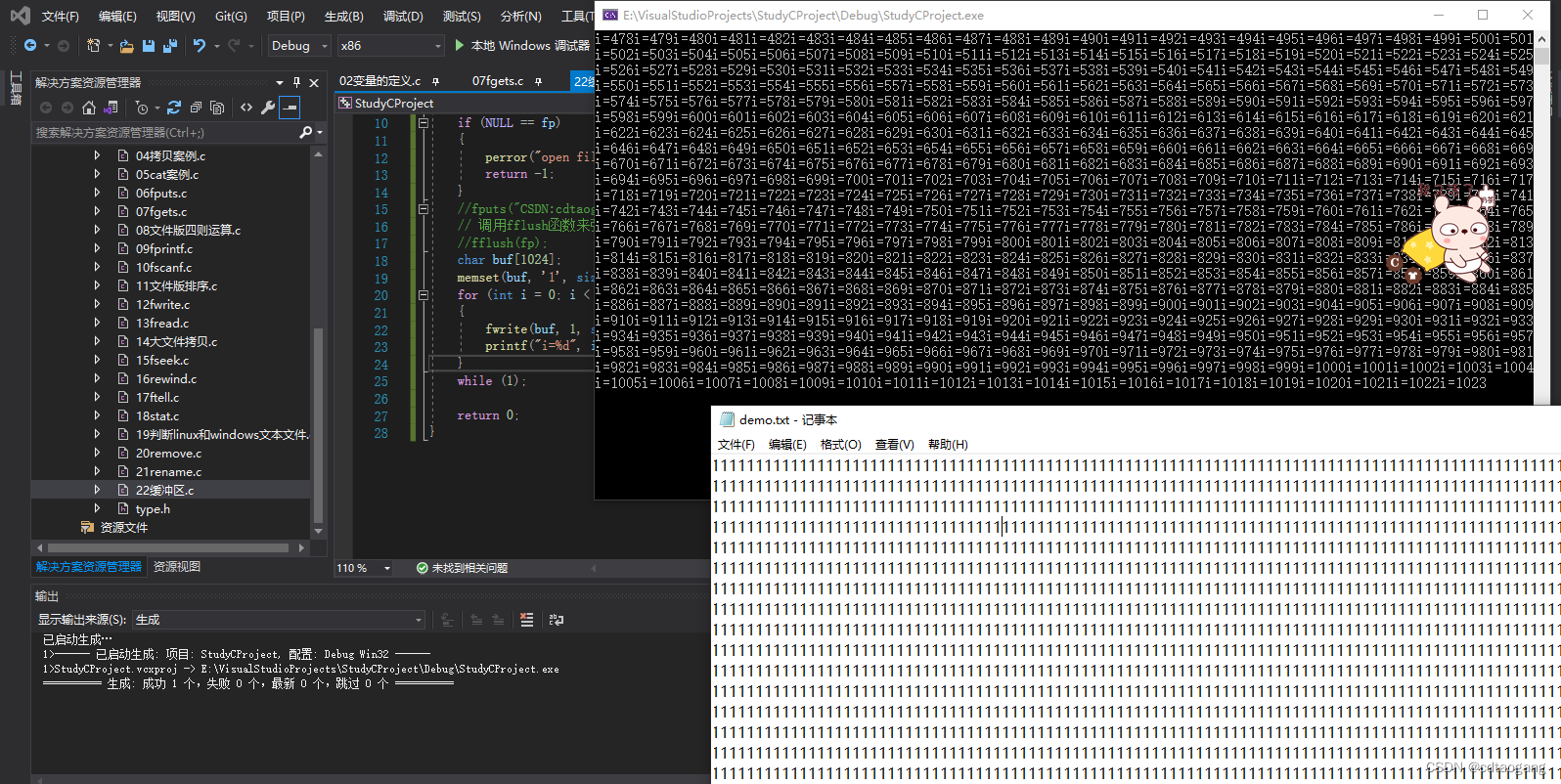
示例3: 当缓冲区内容满了,也会写入文件
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
FILE* fp = fopen("demo.txt", "w");
if (NULL == fp)
{
perror("open file fail");
return -1;
}
//fputs("CSDN:cdtaogang", fp); // 不会马上写入文件,先存至缓冲区
// 调用fflush函数来强制刷新缓冲区
//fflush(fp);
char buf[1024];
memset(buf, '1', sizeof(buf));
for (int i = 0; i < 1024; i++)
{
fwrite(buf, 1, sizeof(buf), fp);
printf("i=%d", i);
}
while (1);
return 0;
}
4) 文件缓冲区问题
- 在
windows下标准输出stdout文件是没有缓冲区的,但是在linux有,比如printf中没有\n是不会显示在终端上的 - 标准输入
stdin不能调用fflush强制刷新
快译通案例
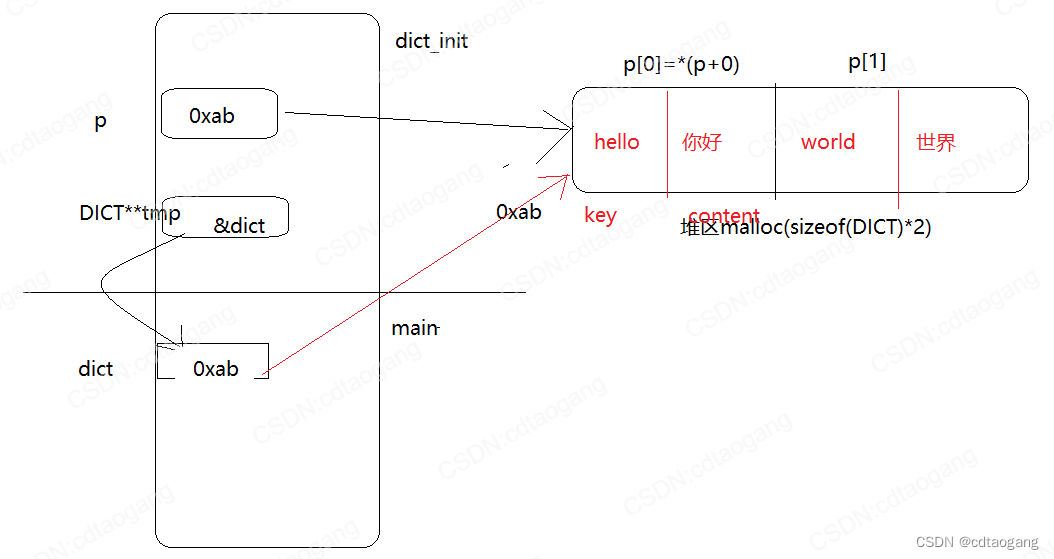
1) 基础版1.0
- hello:你好
- world :世界
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct _dict
{
char key[256];
char content[256];
}DICT;
void dict_init(DICT** tmp)
{
DICT* p;
// 结构体指针申请两个DICT结果体大小的空间
p = malloc(sizeof(DICT) * 2);
// 给p指向的结构体进行初始化
strcpy(p[0].key, "hello");
strcpy(p[0].content, "你好");
strcpy(p[1].key, "world");
strcpy(p[1].content, "世界");
// 修改实参dict的值
*tmp = p;
return;
}
int search_dict_key(char* cmd, DICT* dict, int n, char* content)
{
for (int i = 0; i < n; i++)
{
// 比较终端输入的字符串与结构体中的key是否相同, 相同则将key对应的content字符串内容拷贝到形参content所指的地址
if (strcmp(cmd, dict[i].key) == 0)
{
strcpy(content, dict[i].content);
return 1;
}
}
// 没有找到返回
return 0;
}
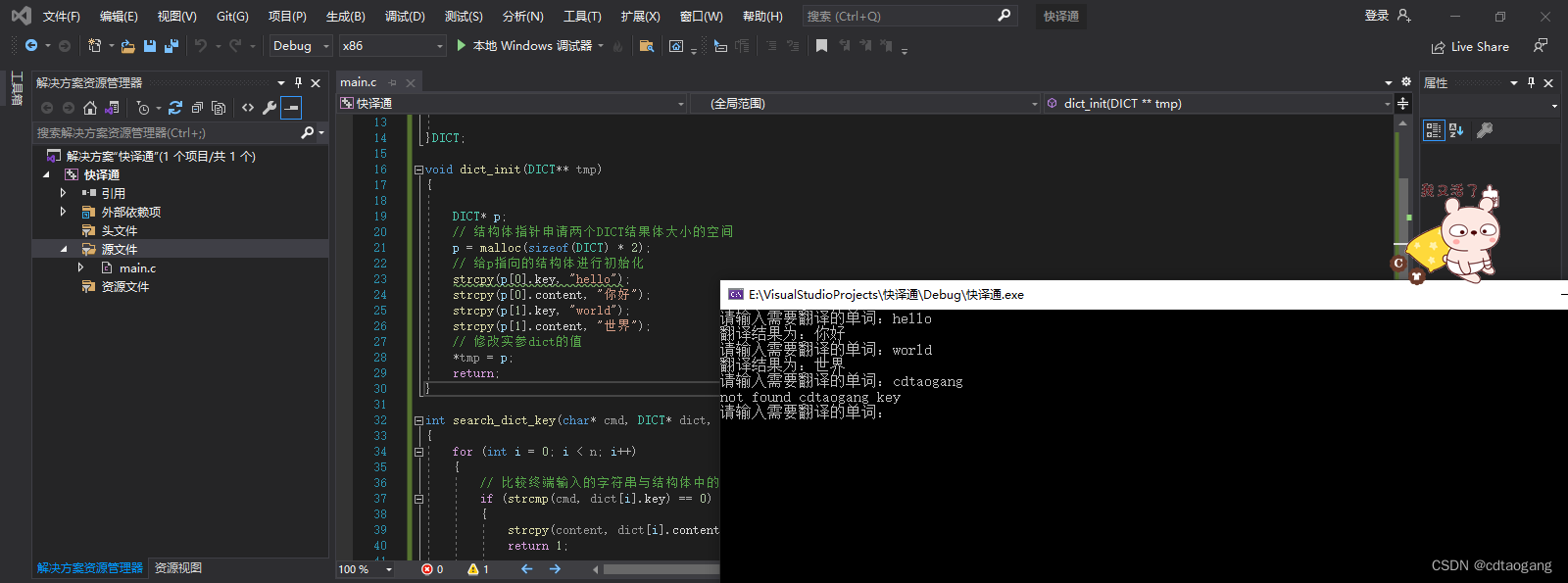
int main()
{
DICT* dict = NULL;
// 结果体初始化数据
dict_init(&dict);
char cmd[256];
char content[256];
int res = 0;
while (1)
{
// 获取用户输入
printf("请输入需要翻译的单词:");
fgets(cmd, sizeof(cmd), stdin);
// 去掉输入的最后一个字符\n
cmd[strlen(cmd) - 1] = 0;
// 搜索判断
res = search_dict_key(cmd, dict, 2, content);
if (res == 0)
{
printf("not found %s key\n", cmd);
}
else
{
printf("翻译结果为:%s\n", content);
}
}
return 0;
}
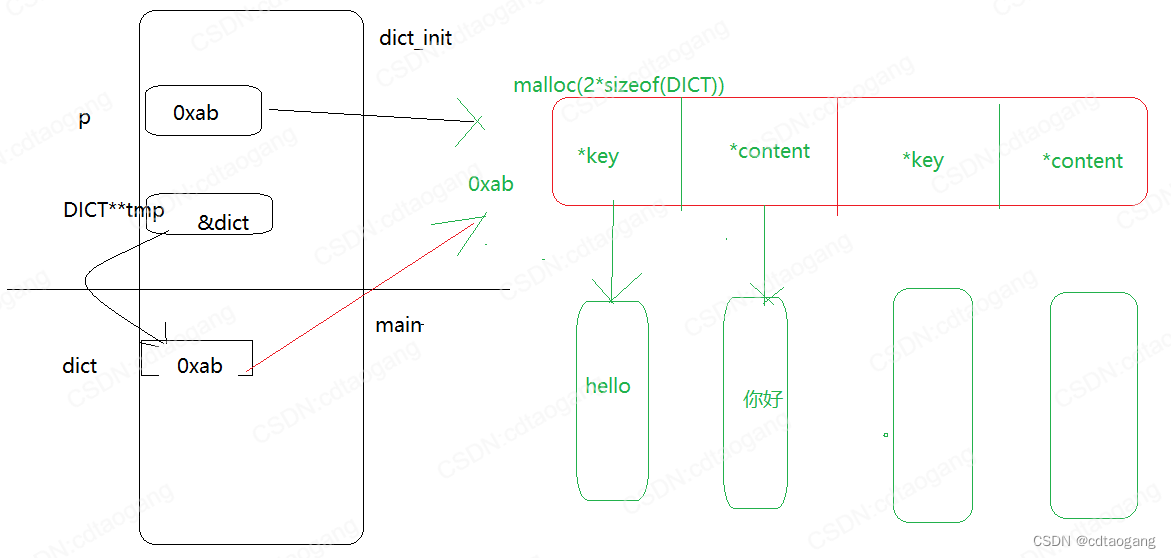
2) 基础版2.0
typedef struct _dict
{
/*char key[256];
char content[256];*/
char* key;
char* content;
}DICT;
void dict_init(DICT** tmp)
{
DICT* p;
// 结构体指针申请两个DICT结果体大小的空间
p = malloc(sizeof(DICT) * 2);
// 给p指向的结构体进行初始化
p[0].key = malloc(sizeof("hello") + 1); // 为了包含\n字符所以要+1
p[0].content = malloc(sizeof("你好"));
strcpy(p[0].key, "hello"); // 将"hello"存p[0].key指向的空间
strcpy(p[0].content, "你好");
p[1].key = malloc(sizeof("world") + 1);
p[1].content = malloc(sizeof("世界"));
strcpy(p[1].key, "world");
strcpy(p[1].content, "世界");
// 修改实参dict的值
*tmp = p;
return;
}
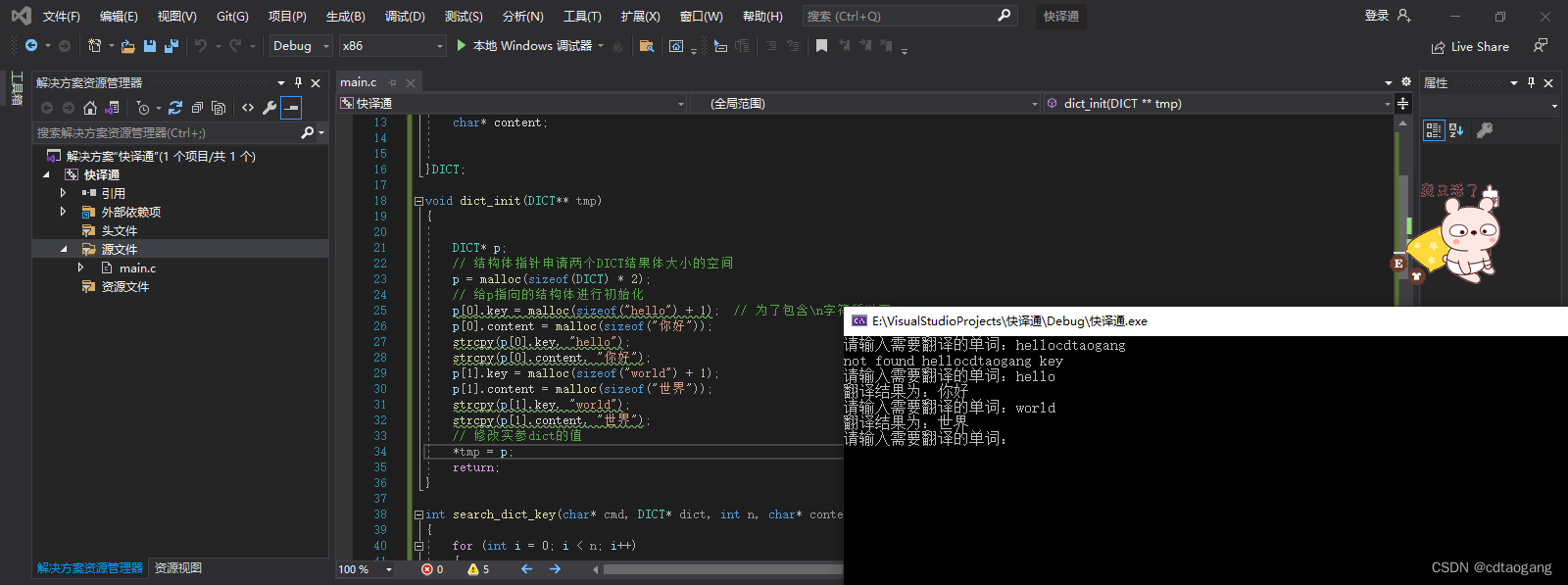
3) 加强版
从英汉词典文本中读取
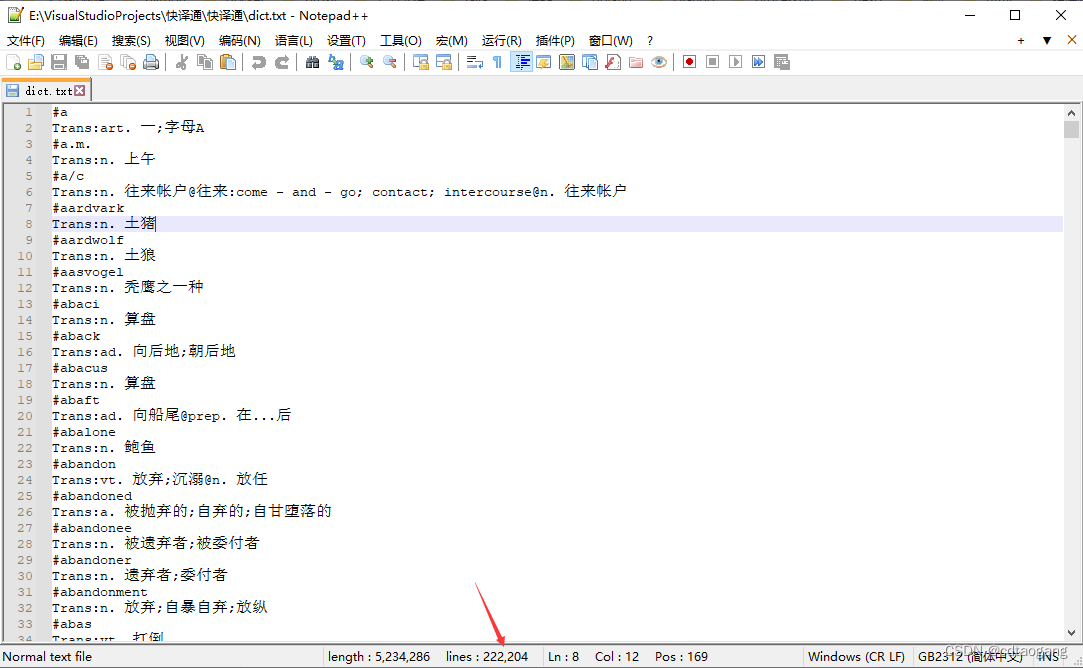
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define LINE_NUM 111102 // 一共222204行,包括原文和译文,每次读两行,所以只要111102行
#define FILENAME "dict.txt"
typedef struct _dict
{
char* key;
char* content;
}DICT;
FILE* open_file()
{
FILE* fp = fopen(FILENAME, "r");
if (NULL == fp)
{
perror("open file error");
return NULL;
}
return fp;
}
void filter_buf(char* buf)
{
// buf最后一个字符下标
int n = strlen(buf) - 1;
// 从buf最后一个字符开始往前判断是否存在空格、\n、\r、\t,如果存在则下标-1,如#abc\r\t 跳出循环时,下标为c字符的下标
while (buf[n] == " " || buf[n] == '\n' || buf[n] == "\r" || buf[n] == "\t")
{
n--;
}
// n+1表示有效字符后面的无效字符置为0即可,如#abc\r\t\n -> abc0
buf[n + 1] = 0;
}
void dict_init(DICT** tmp)
{
DICT* p;
// 结构体指针申请LINE_NUM个DICT结果体大小的空间
p = malloc(sizeof(DICT) * LINE_NUM);
int i = 0;
char* q = NULL;
char buf[256];
FILE* fp = open_file(); // 打开dict.txt文件
while (1)
{
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即原文
if (NULL == q)
{
break;
}
filter_buf(buf); // 过滤掉单词后面的隐藏的字符如\r \t \n等
p[i].key = malloc(strlen(buf) + 1); // 给存储单词p[i].key开辟空间
strcpy(p[i].key, buf + 1); // buf+1 取#后面的原文
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即译文
p[i].content = malloc(strlen(buf) + 1);
strcpy(p[i].content, buf + 6); // buf+6取Trans:后面的译文
i++;
}
// 修改实参dict的值
*tmp = p;
return;
}
int search_dict_key(char* cmd, DICT* dict, int n, char* content)
{
for (int i = 0; i < n; i++)
{
// 比较终端输入的字符串与结构体中的key是否相同, 相同则将key对应的content字符串内容拷贝到形参content所指的地址
if (strcmp(cmd, dict[i].key) == 0)
{
strcpy(content, dict[i].content);
return 1;
}
}
// 没有找到返回
return 0;
}
int main()
{
DICT* dict = NULL;
// 结果体初始化数据
dict_init(&dict);
char cmd[256];
char content[256];
int res = 0;
while (1)
{
// 获取用户输入
printf("请输入需要翻译的单词:");
fgets(cmd, sizeof(cmd), stdin);
// 去掉输入的最后一个字符\n
cmd[strlen(cmd) - 1] = 0;
// 搜索判断
res = search_dict_key(cmd, dict, LINE_NUM, content);
if (res == 0)
{
printf("not found %s key\n", cmd);
}
else
{
printf("翻译结果为:%s\n", content);
}
}
return 0;
}
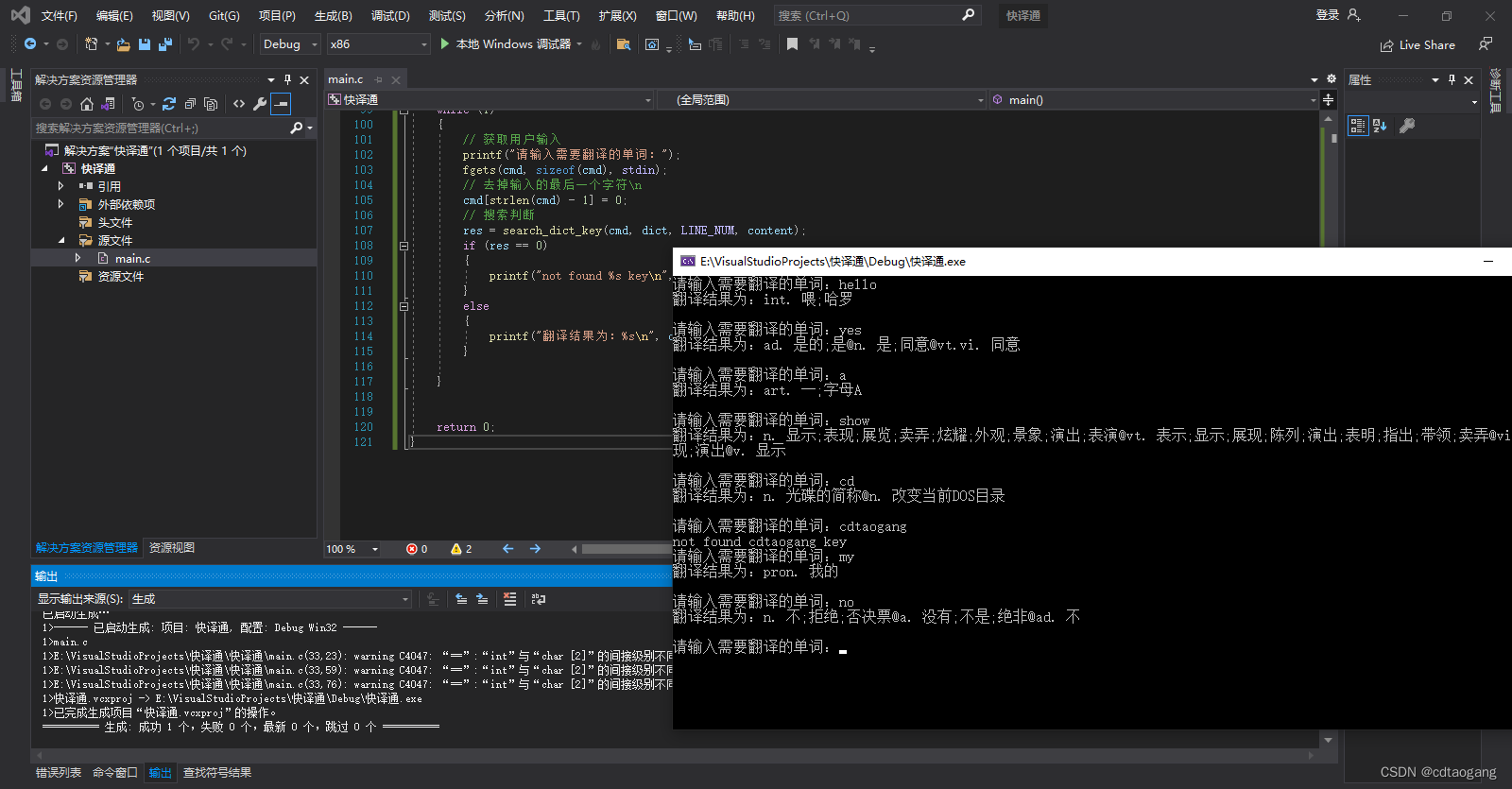
自动获取文本文件的行号
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define LINE_NUM 111102 // 一共222204行,包括原文和译文,每次读两行,所以只要111102行
#define FILENAME "dict.txt"
typedef struct _dict
{
char* key;
char* content;
}DICT;
FILE* open_file()
{
FILE* fp = fopen(FILENAME, "r");
if (NULL == fp)
{
perror("open file error");
return NULL;
}
return fp;
}
void filter_buf(char* buf)
{
// buf最后一个字符下标
int n = strlen(buf) - 1;
// 从buf最后一个字符开始往前判断是否存在空格、\n、\r、\t,如果存在则下标-1,如#abc\r\t 跳出循环时,下标为c字符的下标
while (buf[n] == " " || buf[n] == '\n' || buf[n] == "\r" || buf[n] == "\t")
{
n--;
}
// n+1表示有效字符后面的无效字符置为0即可,如#abc\r\t\n -> abc0
buf[n + 1] = 0;
}
void dict_init(DICT** tmp, int n)
{
DICT* p;
// 结构体指针申请LINE_NUM个DICT结果体大小的空间
p = malloc(sizeof(DICT) * n);
int i = 0;
char* q = NULL;
char buf[256];
FILE* fp = open_file(); // 打开dict.txt文件
while (1)
{
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即原文
if (NULL == q)
{
break;
}
filter_buf(buf); // 过滤掉单词后面的隐藏的字符如\r \t \n等
p[i].key = malloc(strlen(buf) + 1); // 给存储单词p[i].key开辟空间
strcpy(p[i].key, buf + 1); // buf+1 取#后面的原文
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即译文
p[i].content = malloc(strlen(buf) + 1);
strcpy(p[i].content, buf + 6); // buf+6取Trans:后面的译文
i++;
}
fclose(fp);
// 修改实参dict的值
*tmp = p;
return;
}
int search_dict_key(char* cmd, DICT* dict, int n, char* content)
{
for (int i = 0; i < n; i++)
{
// 比较终端输入的字符串与结构体中的key是否相同, 相同则将key对应的content字符串内容拷贝到形参content所指的地址
if (strcmp(cmd, dict[i].key) == 0)
{
strcpy(content, dict[i].content);
return 1;
}
}
// 没有找到返回
return 0;
}
int get_file_lineNum()
{
char* q = NULL;
char buf[256];
FILE* fp = open_file();
int i = 0;
while (1)
{
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即原文
if (NULL == q)
{
break;
}
q = fgets(buf, sizeof(buf), fp); // 读取一行数据 即译文
i++;
}
fclose(fp);
return i;
}
int main()
{
DICT* dict = NULL;
int n = 0;
n = get_file_lineNum();
printf("n=%d\n", n);
// 结果体初始化数据
dict_init(&dict, n);
char cmd[256];
char content[256];
int res = 0;
while (1)
{
// 获取用户输入
printf("请输入需要翻译的单词:");
fgets(cmd, sizeof(cmd), stdin);
// 去掉输入的最后一个字符\n
cmd[strlen(cmd) - 1] = 0;
// 搜索判断
res = search_dict_key(cmd, dict, n, content);
if (res == 0)
{
printf("not found %s key\n", cmd);
}
else
{
printf("翻译结果为:%s\n", content);
}
}
return 0;
}
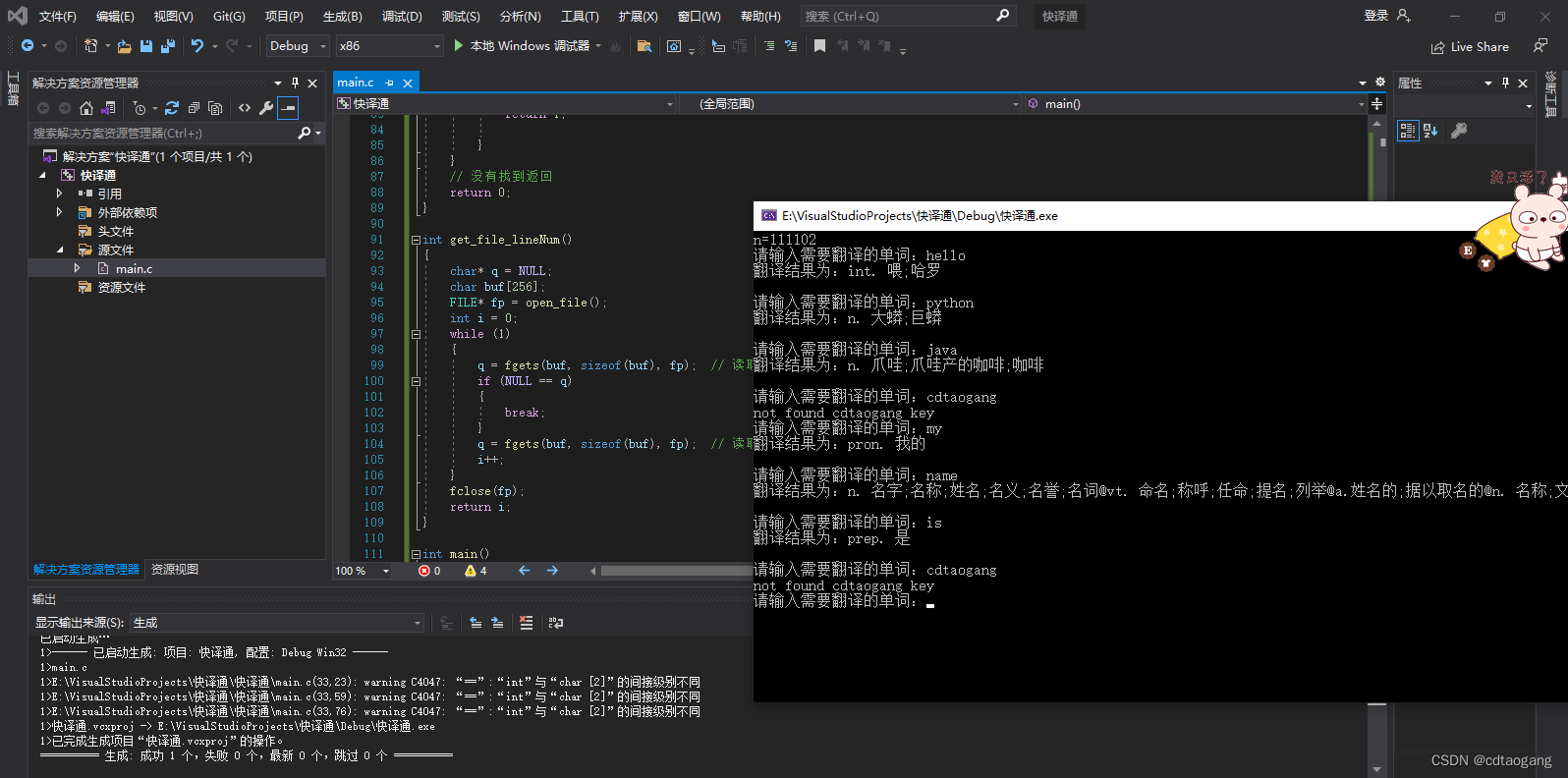
添加查询耗时
int main()
{
DICT* dict = NULL;
int n = 0;
n = get_file_lineNum();
printf("n=%d\n", n);
// 结果体初始化数据
dict_init(&dict, n);
char cmd[256];
char content[256];
int res = 0;
LARGE_INTEGER start;
LARGE_INTEGER end;
LARGE_INTEGER frequency;
QueryPerformanceFrequency(&frequency);
double time;
while (1)
{
// 获取用户输入
printf("请输入需要翻译的单词:");
fgets(cmd, sizeof(cmd), stdin);
// 去掉输入的最后一个字符\n
cmd[strlen(cmd) - 1] = 0;
QueryPerformanceCounter(&start); //开始计时
// 搜索判断
res = search_dict_key(cmd, dict, n, content);
if (res == 0)
{
printf("not found %s key\n", cmd);
}
else
{
printf("翻译结果为:%s\n", content);
}
QueryPerformanceCounter(&end); //结束计时
time = (double)(end.QuadPart - start.QuadPart) / (double)frequency.QuadPart;
printf("耗时:%f秒\n ", time);
}
return 0;
}
![[附源码]JAVA毕业设计律师事务管理系统(系统+LW)](https://img-blog.csdnimg.cn/9b2d52259f5341c8816a25474344e46a.png)







![[附源码]Python计算机毕业设计Django农村人居环境治理监管系统](https://img-blog.csdnimg.cn/e326e60577f246e5bee10b16a1a0eb8d.png)