Pytorch中的数据操作和预处理
整体概述
在Pytorch中的torch.util.data模块包含着一些常用的数据预处理的操作,主要用于数据的读取、切分、准备等
常用的数据操作类如下表所示
| 类 | 功能 |
|---|---|
| torch.utils.data.TensorDataset() | 将数据处理为张量 |
| torch.utils.data. ConcatDataset() | 连接多个数据集 |
| torch.utils.data.Subset() | 根据索引获得数据集的子集 |
| torch.utils.data. DataLoader | 数据加载器 |
| torch.utils.data. random_split | 将数据集拆分为指定长度的非重叠数据集 |
使用这些类能够对高维数组、图像等各种类型的数据进行预处理,以便深度学习模型使用。
高维数组
很多情况下需要从文本文件(例如csv文件)中读取高维数组。
这一类数据的特征是,每个样本都有很多个预测变量(特征)和一个被预测变量(目标标签)特征通常是数值变量或者离散变量,连续变量对应回归、离散变量对应分类。
使用sklearn中提供的数据集load_boston和load_iris,来进行回归和分类数据的准备
回归数据准备
过程:加载相应模块,然后读取数据。
注意:使用sklearn中的数据集需要,使用1.2版本一下的数据集,否则会出错误
pip uninstall scikit-learn
pip install scikit-learn==1.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装之前的版本
import torch
import torch.utils.data as Data
from sklearn.datasets import load_boston,load_iris
# 读取波士顿数据集
boston_X,boston_Y = load_boston(return_X_y=True)
print(boston_X.dtype)
print(boston_Y.dtype)
boston_Y
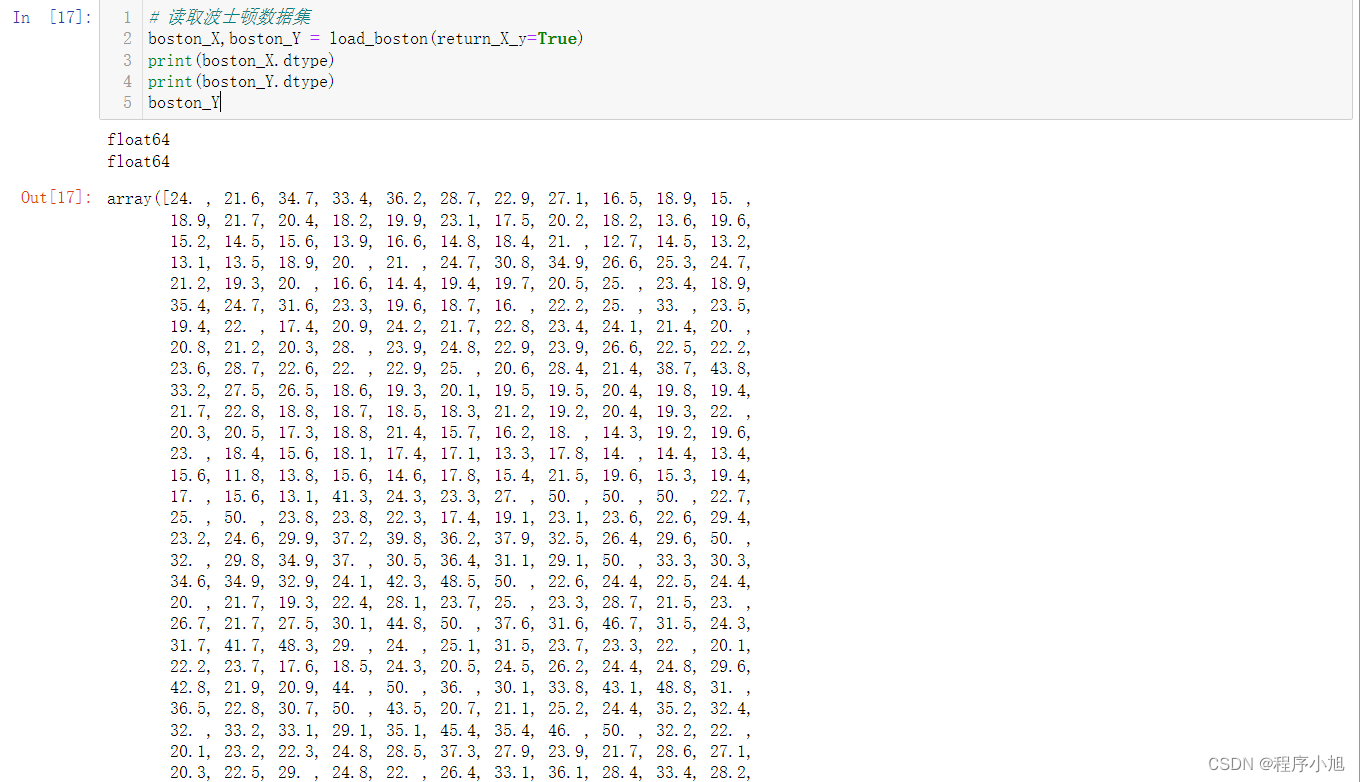
在进行数据处理的时候需要把64位的Numpy数据转化位32位的浮点型张量
# 将训练集x y转化为张量
train_xt = torch.from_numpy(boston_X.astype(np.float32))
train_yt = torch.from_numpy(boston_Y.astype(np.float32))
train_xt.dtype
train_yt.dtype

在训练全连接神经网络时,通常一次使用一个batch的数据进行权重的更新,torch.util.data.DataLoader()函数可以将输入数据集(包含数据特征张量和被预测的特征张量)获得一个加载器,每次迭代使用一个batch的数据
使用方法如下
train_data = Data.TensorDataset(train_xt,train_yt)
# 定义一个数据加载集,将训练数据集进行批处理
train_loader = Data.DataLoader(
##使用的数据集
dataset = train_data,
##批处理的大小
batch_size=64,
shuffle=True,
##使用两个进程
num_workers =1,
)
# 检测训练数据集的一个batch的样本的维度是否正确
for step, (b_x,b_y) in enumerate(train_loader):
if step > 0:
break
# 判断循环完成之后的类型
b_x.shape
print(b_x.dtype)
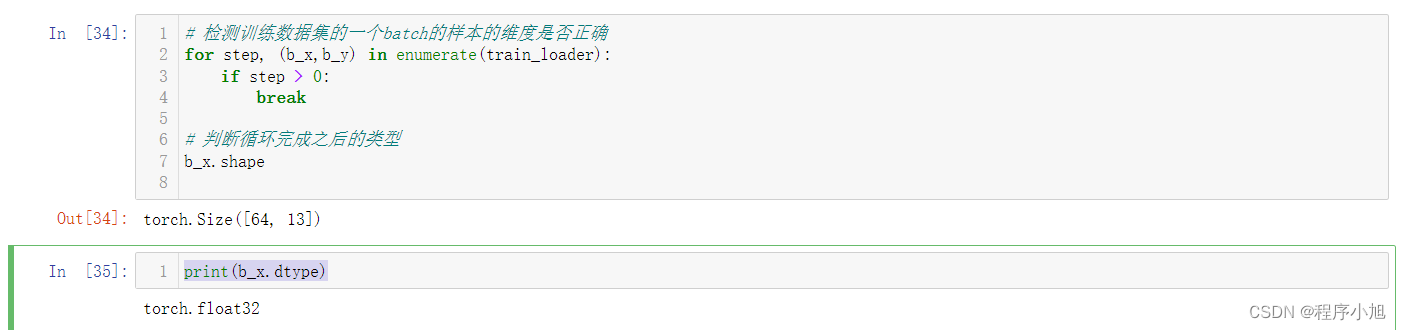
根据分类的类型,可以验证得知波士顿房价回归预测的数据集
分类数据集
分类数据集的处理思想与回归的思想基本相同,处理逻辑类似,不在进行代码的演示。
如有需要可以联系我