背景
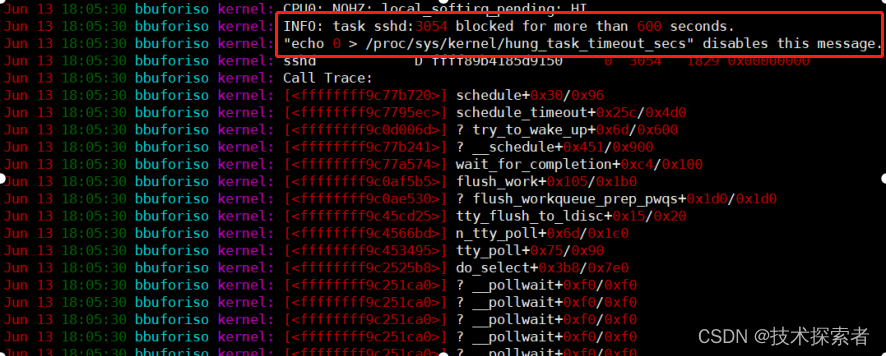
在Centos 7的系统日志 /var/log/message中出现大量的 “blocked for more than 600 seconds”和“echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.” 的错误。
如下图所示:
问题原因
默认情况下, Linux最多会使用40%的可用内存作为文件系统缓存。当超过这个阈值后,文件系统会把将缓存中的内存全部写入磁盘, 导致后续的IO请求均同步。将缓存写入磁盘的时候,有一个默认600秒的超时时间。 出现上面的问题是因为IO子系统的处理不够快速,不能在600秒将缓存中的数据全部写入到磁盘的。IO系统响应缓慢,导致越来越多的请求堆积,最终系统内存全部被占用,导致系统失去响应。
这通常发生在内存很大的系统上。系统内存大,则缓冲区大,同步数据所需要的时间就越长,超时的概率就越大。
解决方法
针对该问题,解决方法大致3种
方法一:缩小文件系统缓存大小
此种方案是降低缓存占内存的比例,比如由40%降到10%,这样的话需要同步到磁盘上的数据量会变小,IO写时间缩短,会相对比较平稳。
文件系统缓存的大小是由内核参数vm.dirty_ratio 和 vm.dirty_backgroud_ratio控制决定的。
- vm.dirty_background_ratio 指定当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存。
- vm.dirty_ratio 指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存),在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
通常情况下,vm.dirty_ratio的值要大于vm.dirty_background_ratio的值。
根据应用程序的情况,对vm.dirty_ratio,vm.dirty_background_ratio两个参数进行调优设置。 例如,推荐如下设置:
# sysctl -w vm.dirty_ratio=10
# sysctl -w vm.dirty_background_ratio=5
# sysctl -p
如果系统永久生效,在/etc/sysctl.conf文件中加入如下两行:
#vim /etc/sysctl.conf
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
重启系统生效。
缩减文件系统缓存之后,上述问题成功解决。
方法二:取消120秒时间限制
此方案是不让系统有那个120秒的时间限制。文件系统把数据从缓存转到外存慢点就慢点,应用程序对此延时不敏感。就是慢点就慢点,我等着。实际上操作系统是将这个变量设为长整形的最大值。
PS:内核hung task检测机制由来
我们知道进程等待IO时,经常处于D状态,即TASK_UNINTERRUPTIBLE状态,处于这种状态的进程不处理信号,所以kill不掉,如果进程长期处于D状态,那么肯定不正常,原因可能有二:
- IO路径上的硬件出问题了,比如硬盘坏了(只有少数情况会导致长期D,通常会返回错误);
- 内核自己出问题了。
这种问题不好定位,而且一旦出现就通常不可恢复,kill不掉,通常只能重启恢复了。
内核针对此种情况开发了一种hung task的检测机制,基本原理为:定时检测系统中处于D状态的进程,如果其处于D状态的时间超过了指定时间(默认120s,可以配置),则打印相关堆栈信息,也可以通过proc参数配置使其直接panic。
如何修改或者取消120秒的时间限值呢。120秒的时间限值由内存参数kernel.hung_task_timeout_secs决定的。直接修改此内核参数的值就可。如果kernel.hung_task_timeout_secs的值设置为0,那就是把此种设置为长整型的最大值。
下面说一下修改调度器的流程。
(1)查看当前hung_task_timeout_secs值。
在命令行中输入如下指令查询当前的值:
sysctl -a | grep hung_task_timeout_secs
(2)修改hung_task_timeout_secs值。
把hung_task_timeout_secs的值修改为0,在命令行中输入如下指令
./sbin/sysctl -w kernel.hung_task_timeout_secs=0
使参数生效:
sysctl -p
取消120秒时间限值之后,上述问题成功解决。
方法三:修改系统IO调度策略
Linux的IO共有三种调度器:CFQ、noop、deadline。每个调度器各有优点。
- CFQ (Completely Fair Scheduler(完全公平调度器))(cfq):它是许多Linux 发行版的默认调度器;它将由进程提交的同步请求放到多个进程队列中,然后为每个队列分配时间片以访问磁盘。
- Noop调度器(noop):基于先入先出(FIFO)队列概念的Linux内核里最简单的I/O调度器。此调度程序最适合于SSD。
- 截止时间调度器(deadline):尝试保证请求的开始服务时间。
Linux发行版的默认采用的是cfq调度器。此方案就是把cfq调度器修改为最简单的noop调度器。
下面说一下修改调度器的流程。
(1)查看当前采用的调度器
在命令行中输入如下指令查询当前调度器:
cat /sys/block/sda/queue/scheduler

(2)修改调度器
在命令行中输入如下指令:
echo noop >/sys/block/sda/queue/scheduler
调度器的修改是立即生效的,不必重启内核。
修改完成后,让系统继续运行一段时间。上述问题依然存在。所以此方案对本文的案例不起作用。对于其他案例是否起作用需要自己按照上述方式测试才能得知。
总结
经过上述测试,对与本案例缩减文件系统缓冲大小和取消120秒时间限值均可以解决问题。但是取消120秒的时间限值会允许系统不可切换任务的出现。综合考虑决定采用方案1,即缩减文件系统的缓冲区大小。
参考
1、Linux Kernel Crash--hung_task_timeout_secs
2、How to fix hung_task_timeout_secs and blocked for more than 120 seconds problem
3、关于修改 sysctl.conf,如何使该文件在系统重启之后生效
4、一次内核hung task分析
5、文件系统缓存dirty_ratio与dirty_background_ratio两个参数区别