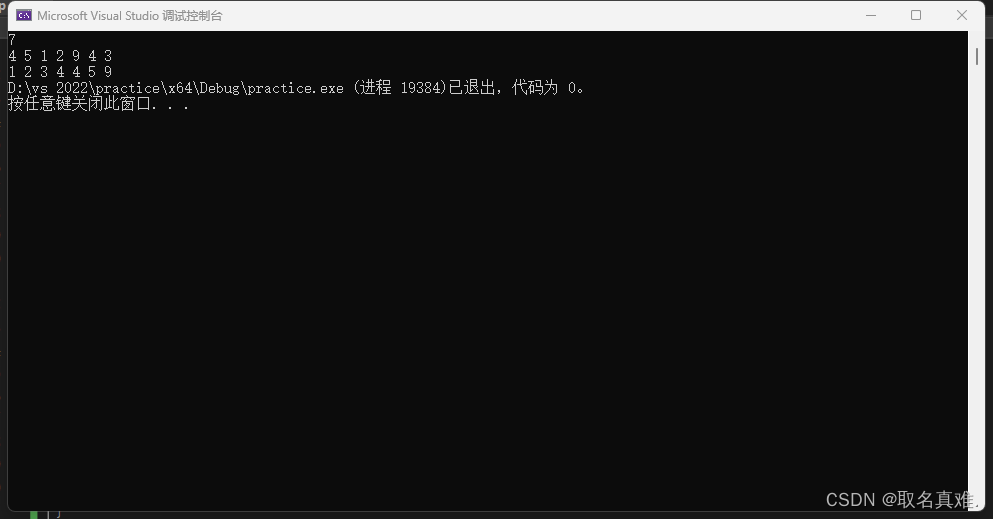
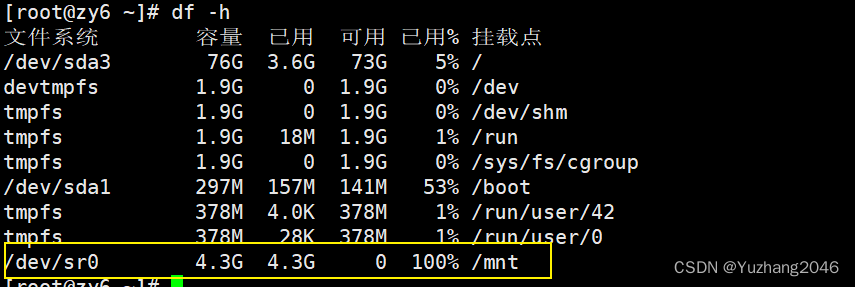
归并排序是一种经典的排序算法,也被称为“归并算法”。它的基本思想是将待排序数组分成若干个子数组,每个子数组都是有序的,然后将这些子数组合并成一个大的有序数组。
具体实现过程如下:
-
将待排序数组不断划分为左右两个子数组,直到每个子数组只有一个元素为止。
-
对每个子数组进行排序,可以使用插入排序等算法。
-
将相邻的两个子数组合并为一个有序数组,直到整个数组排序完成。
归并排序的时间复杂度为O(nlogn),空间复杂度为O(n)。虽然它的常数因子较大,但它稳定性好、适用于大规模数据排序等优点使得它在实际应用中得到广泛使用。
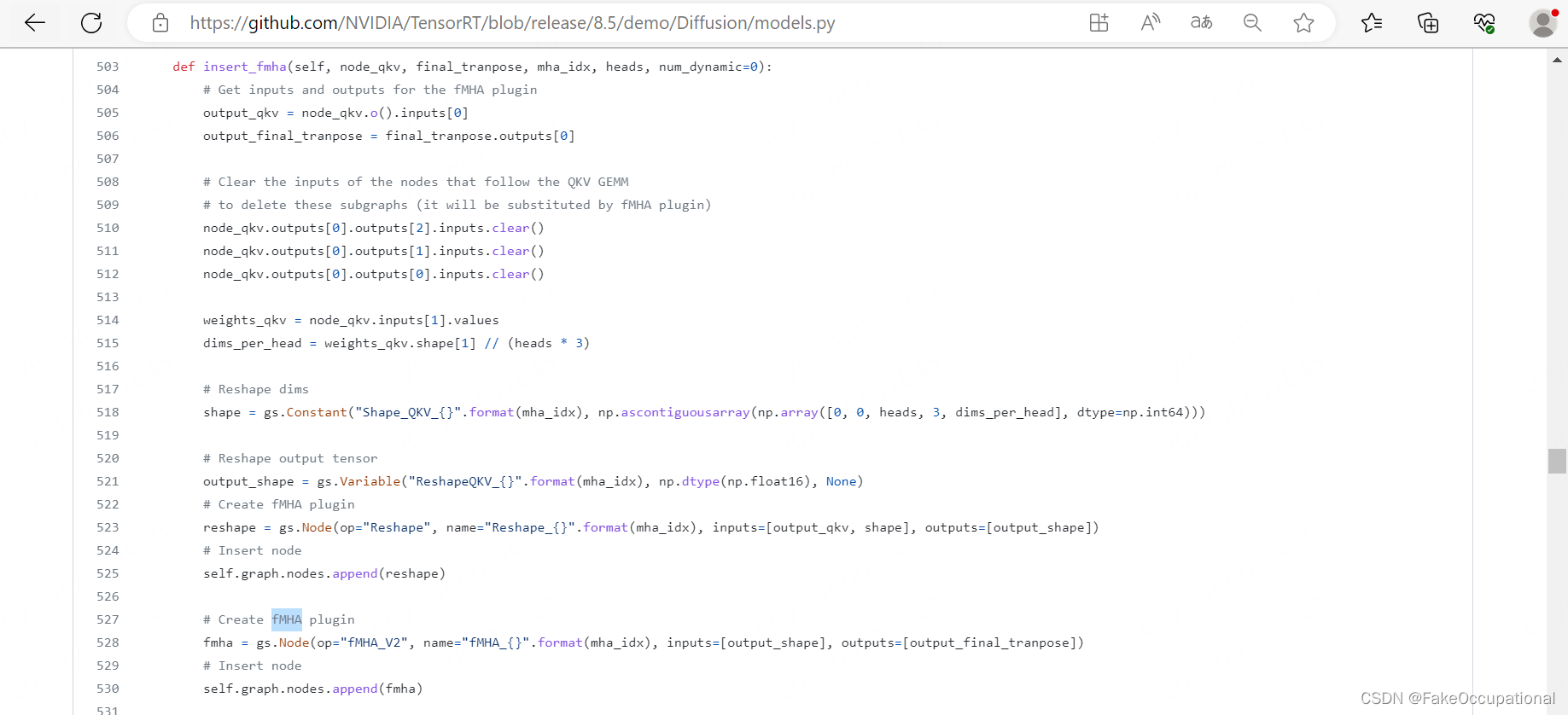
#include<iostream>//归并排序
using namespace std;
int a[1000], n;
int b[1000];
void hebin(int l, int mid, int r)
{
int p = l, q = mid + 1;
for (int i = l; i <= r; i++)
{
if ((q > r) || (p <= mid && a[p] <= a[q]))
{
b[i] = a[p++];
}
else
{
b[i] = a[q++];
}
}
for (int i = l; i <= r; i++)
a[i] = b[i];
}
void merge_sort(int l,int r)
{
if (l == r) return;
int mid = (l + r) / 2;
merge_sort(l, mid); //对左边进行归并
merge_sort(mid + 1, r);//对右边进行归并
hebin(l, mid, r); //合并
}
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
cin >> a[i];
merge_sort(0, n-1);
for (int i = 0; i < n; i++)
cout << a[i]<<" ";
}
快速排序是一种高效的排序算法,基本思想是通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
具体实现过程如下:
- 选择一个基准元素,通常选择第一个元素或者最后一个元素;
- 从序列的两端开始进行扫描,设立两个指示标志(low 和 high);
- 从后面开始扫描,如果发现有元素比基准元素小,则将其与基准元素交换;
- 从前面开始扫描,如果发现有元素比基准元素大,则将其与基准元素交换;
- 重复3和4步,直到 low 和 high 相遇;
- 将基准元素与 low 位置交换,这样就完成了一次排序;
- 递归地对基准元素左边的序列和右边的序列进行排序,直到整个序列有序为止。
快速排序的时间复杂度为 O(nlogn),是一种非常高效的排序算法。
#include<iostream>//快排
using namespace std;
int a[1000];
void quick_sort(int l, int r)
{
int i = l, j = r;
int mid = (l + r) / 2;
int x = a[mid];
while (i <= j)
{
while (a[i] < x) i++;
while (a[j] > x) j--;
if (i<=j)
{
swap(a[i], a[j]);
i++, j--;
}
}
if (l < j) quick_sort(l, j);//对左边
if (i < r) quick_sort(i, r);//对右边
}
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
cin >> a[i];
quick_sort(0, n - 1);
for (int i = 0; i < n; i++)
cout << a[i]<<" ";
}