一、爬取数据
小问题汇总
1.python之matplotlib使用系统字体
用于解决python绘图中,中文字体显示问题
2.cookie与视频页面id(b站、微博等)查看
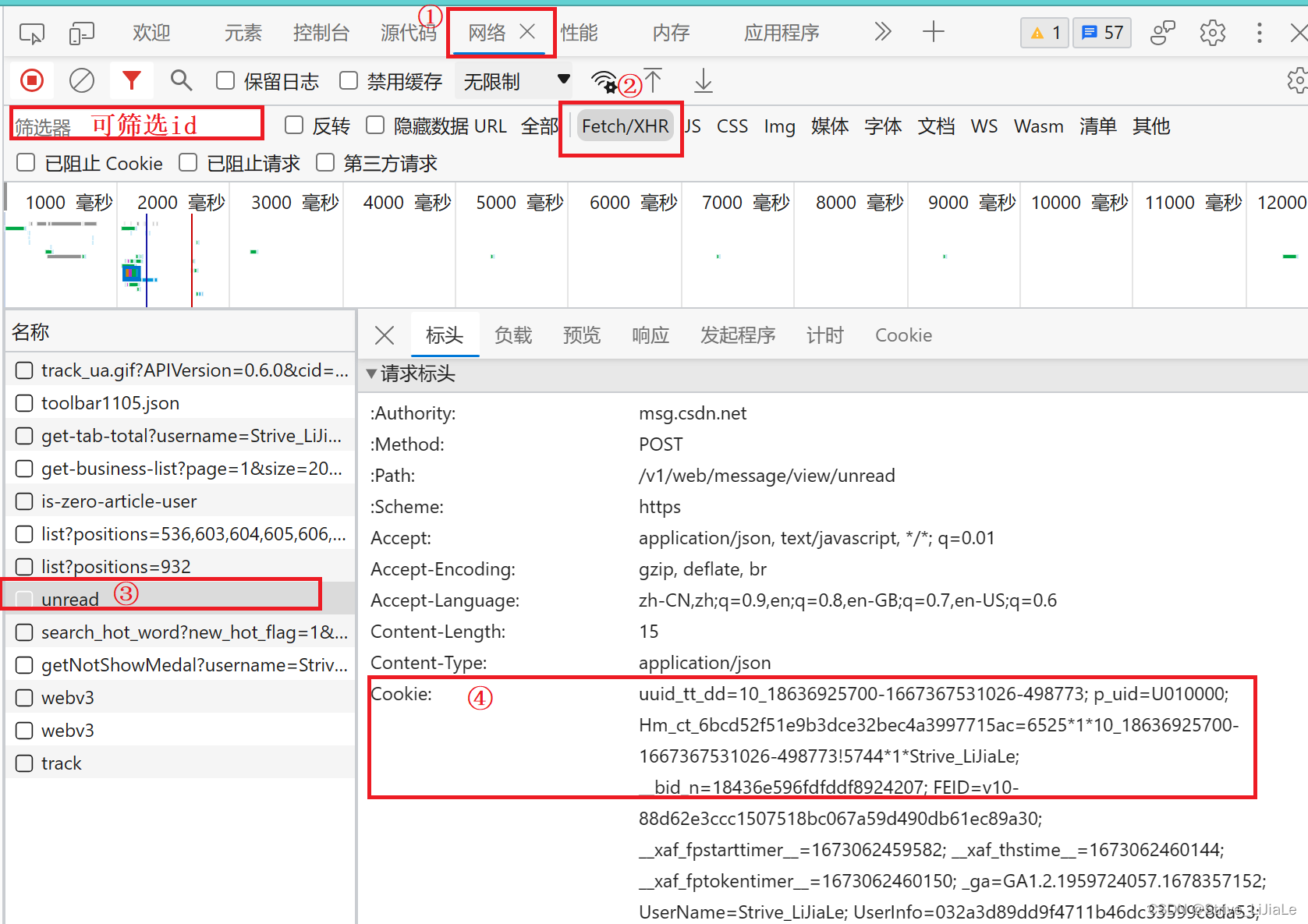
F12打开网页开发者模式,然后F5刷新,进入控制台中的网络,查看Fetch/XHR
3.爬取wb评论时,最好使用网页手机端
网页手机端:https://m.weibo.cn/?sudaref=cn.bing.com
4.从存储文件读数据,可能会提示编码错误
对文件的打开方式,添加代码encoding='utf-8'
b站爬虫
1.前提准备工具
- 安装 Python 3。
- 安装所需的库。在命令行中输入以下命令:pip install selenium beautifulsoup4 webdriver-manager
- 安装 chrome浏览器以及启动软件chromedriver.exe(版本号要接近),使用selenium + chrome浏览器爬取数据
- .csv文件用excel或者notepad打开都会乱码,可用记事本打开,或者用excel导入.csv文件,具体过程自行百度
2.使用说明
1.功能说明
- 能批量爬取B站多个视频的评论,使用Selenium而非B站api,能爬取到更全面的数据。
- 能够断点续爬,可以随时关闭程序,等到有网络时再继续运行。
- 遇到错误自动重试,非常省心,可以让它自己爬一整晚。
2.关于断点续爬与progress
-
断点续爬功能依托progress.txt记录实现:程序运行时,如果代码同级文件夹内存在progress.txt文件,它会读取其中进度;如果没有,则自动创建。
-
如果想要从头开始爬取,只需删除 progress.txt 文件即可。
-
如果想要修改爬虫任务,跳过某些视频/一级评论/二级评论页,建议直接修改progress.txt文件。
(例如,有一个视频爬取失败,想要跳过它,直接在progress中,把video_count加1即可) -
progress含义:
第{video_count}个视频已完成爬取。
第{video_count + 1}个视频中,第{first_comment_index}个一级评论的,二级评论第{sub_page}页已完成爬取。
"write_parent"为1指当前一级评论已写入,为0指当前一级评论尚未写入。
示例如右:{"video_count": 1, "first_comment_index": 15, "sub_page": 114, "write_parent": 1}
注意:“video_count”“first_comment_index”"sub_page"三个值全部是从0开始的,"write_parent"取值为0或1。3.使用步骤
-
将要爬取评论的视频 URL 列表放入名为 video_list.txt 的文件中,每行一个 URL。
-
参数设定
- 若要修改最大滚动次数(默认45次,预计最多爬取到920条一级评论),请在代码中修改参数MAX_SCROLL_COUNT的值。注意,滚动次数过多,加载的数据过大,网页可能会因内存占用过大而崩溃。
- 若要设定最大二级评论页码数(默认为150页),请在代码中修改参数max_sub_pages的值(若想无限制,请设为max_sub_pages = None)。建议设定一个上限以减少内存占用,避免页面崩溃。
-
运行代码:python Bilicomment.py(或pycharm等软件打开运行)。代码使用selenium爬取数据。
-
根据看到"请登录,登录成功跳转后,按回车键继续…"提示后,请登录 Bilibili。登录成功并跳转后,回到代码,按回车键继续。
-
等待爬取完成。每个视频的评论数据将保存到以视频 ID 命名的 CSV 文件中, CSV 文件位于代码文件同级目录下。
-
输出的 CSV 文件将包括以下列:‘一级评论计数’, ‘隶属关系’(一级评论/二级评论), ‘被评论者昵称’(如果是一级评论,则为“up主”), ‘被评论者ID’(如果是一级评论,则为“up主”), ‘昵称’, ‘用户ID’, ‘评论内容’, ‘发布时间’, ‘点赞数’。
-
输出的 CSV 文件是utf-8编码,若乱码,请检查编码格式(可以先用记事本打开查看)。
-
如果有视频因为错误被跳过,将会被记录在代码同级文件夹下的video_errorlist.txt中。
-
4.注意实现
- 用Excel打开 CSV 文件查看时,可能会发现有些单元格报错显示"$NAME?“,这是由于这个单元格的内容是以”-“符号开头的,例如昵称”-Ghauster"。
- 如果代码报错Permission denied,请查看是否有别的进程占用了正在写入中的 CSV 文件或 progress.txt 文件(比如,文件被我自己打开了),检查是否有写入权限。还不行,可以尝试以管理员身份运行代码(遇到PermissionError,都可以尝试以管理员身份运行来解决)。
- 爬取超大评论量的热门视频时,网页可能会因为内存不足而崩溃。如果发生这种情况,程序会在一定时间后自动重启浏览器断点续爬。但是如果网页都还没有滚动到底全部加载完、都还没有开始爬,就内存不足了,那无论自动重试多少次都会重复出现网页崩溃的问题,此时建议限制最大滚动次数。
- 在使用selenium + chrome浏览器爬取数据时,如果该视频评论量过大,selenium模拟浏览器会产生大量的临时文件。目前,程序将缓存存储在代码文件所在目录中,重试续爬前我们可以自行删除。
- 如果程序长时间没有动静(控制台长时间没有打印当前进度),就重启程序吧,它会断点续爬的。这可能是因为访问b站过于频繁,阿b不想理你了(或者要输验证码了)。如果这个问题频繁发生,可以尝试延长延时时间,或改为随机延时。
添加随机延时:
先import random
在想要延时的地方写time.sleep(random.uniform(1, 5)) # 随机生成1到5秒之间的延时,具体秒数可根据需要修改
完整代码
github:https://github.com/Ghauster/BilibiliCommentScraper
记得给作者点星星
微博爬取
1.前提准备工具
- 安装SQLiteSpy,用于查看.db文件(爬取数据存储方式)
- cookie是以
SUB=_2A2开头的 - User-Agent也可以找到,
Mozilla/5.0 (Macintosh。。。
2.使用步骤
- 点进微博正文

地址栏中的数字:491…278就是ID号
仅修改代码中的weibo_id即可,可自行写循环,读取多个视频id
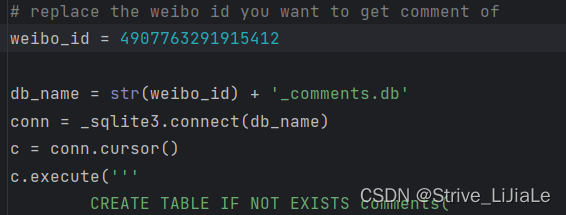
- 可自行修改每次的获取量
max_retries,不易太大,容易被🈲
完整代码
import requests
import _sqlite3
import time
def req(comment_id, max_id, max_id_type):
if max_id == '':
url = f'https://m.weibo.cn/comments/hotflow?id={comment_id}&mid={comment_id}&max_id_type={max_id_type}'
else:
url = f'https://m.weibo.cn/comments/hotflow?id={comment_id}&mid={comment_id}&max_id={max_id}&max_id_type={max_id_type}'
# add your cookie here
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'cookie': 'SUB=_2A25JgtBTDeRhGeFK6lAZ8i3JwzuIHXVqjPAbrDV6PUNbktAGLU_BkW1NQ4YXL0ReJHn1GmrpS18v3XL0JC5yCKFN; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFU_bVsl9QC9P9MnfDn.wXg5JpX5KMhUgL.FoMXeKzReoef1hM2dJLoIEnLxK-L12BL1KMLxK-LBo2LBo2LxKBLB.zLBK-LxK-L12BL1KMEeh50; SSOLoginState=1686544387; ALF=1689136387; BAIDU_SSP_lcr=https://login.sina.com.cn/; mweibo_short_token=460be2ed11; M_WEIBOCN_PARAMS=oid%3D4910481981055278%26luicode%3D20000061%26lfid%3D4910481981055278%26uicode%3D20000061%26fid%3D4910481981055278'
}
content = requests.get(url, headers=headers)
return content
# replace the weibo id you want to get comment of
weibo_id = 4907763291915412
db_name = str(weibo_id) + '_comments.db'
conn = _sqlite3.connect(db_name)
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS comments(
id TEXT PRIMARY KEY,
created_time TEXT,
screen_name TEXT,
user_id TEXT,
content TEXT
)
''')
retry_count = 0
max_retries = 10
max_id_type = 0
data = req(weibo_id, max_id='', max_id_type=0).json()
comments = data['data']['data']
max_id = data['data']['max_id']
max_page = data['data']['max']
total_num = data['data']['total_number']
count = 1
print(f'total {max_page} pages,{total_num} comments')
print(f'the first page has {len(comments)} comments')
time.sleep(5)
while retry_count < max_retries:
try:
content = req(weibo_id, max_id, max_id_type).json()
if content['ok'] == 0:
break
max_id = content['data']['max_id']
max_id_type = content['data']['max_id_type']
content = content['data']['data']
count += 1
print(f'page {count} has {len(content)} comments')
for comment in content:
c.execute('''
INSERT OR REPLACE INTO comments VALUES (?,?,?,?,?)
''', (
comment['id'],
comment['created_at'],
comment['user']['screen_name'],
comment['user']['id'],
comment['text']
))
conn.commit()
if max_id == 0:
break
retry_count = 0
time.sleep(5)
except Exception as e:
retry_count += 1
print(f'an error occurred:{e},retrying...')
time.sleep(5)
continue
conn.close()
数据分析
1.数据爬取后读取接口
注意:所有函数接口都是接收列表或者txt文件
- 从.db文件读取某一列放列表中(以评论内容为例)
import sqlite3
comments = []
conn = sqlite3.connect(r'D:\PyCharm\pythonProject2\B\4875620099559502_comments.db')
c = conn.cursor()
ret = c.execute("select * from comments") # 获取该表所有元素
for row in ret:
comments.append(row[4])# 获取该表第五列数据
conn.close()
- 从.xlsx(excel)读取,写入另一个txt文件中(也可以放入列表或者其他)
file_path = r'C:\Users\lijiale\Desktop\b站评论数据分析\data2.xlsx'
txt_path = r'C:\Users\lijiale\Desktop\b站评论数据分析\l.txt
df = pd.read_excel(file_path) # 默认读取工作簿中第一个工作表,默认第一行为表头
data = df['评论内容'].values.tolist()
f = open(txt_path, "w",encoding='utf-8')
for line in data:
f.write(str(line))
f.close()
2.词云图
以comments列表为接收参数
def form_wordcloud(comments):
mk = imread('词云背景图.png') #词云图形状,放当前目录下
"""解析评论内容并形成词云"""
word = ''.join(comments)
# 使用jieba分词并提取出现频率前200的名词、动词、形容词等有代表性的词汇
topWord_lis = jieba.analyse.extract_tags(word, topK=200, allowPOS='n''v''a''vn''an')
topWord = ' '.join(topWord_lis)
# 词云参数配置
w = wordcloud.WordCloud(
background_color='white',
font_path=r"C:\Windows\Fonts\simhei.ttf", # 字体
width=2000,
height=1500,
max_words=1000,
max_font_size=80,
min_font_size=10,
mode='RGBA',
mask=mk, # 背景图
)
w.generate(topWord)
w.to_file('评论词云.png')
print('词云形成!')
3.情感分析
def get_emotion(comment):
"""对一条评论进行情感分析,返回该评论的情感属性(emotion_label可能为0,1,2,分别对应消极的、中肯的、积极的)"""
# 百度API认证
APP_ID = '********'
API_KEY = '********'
SECRET_KEY = '********'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
comment = ''.join(re.findall('[\u4e00-\u9fa5]', comment)) # 去除评论文本中的特殊字符
# 调用情感倾向分析
dic = client.sentimentClassify(comment)
# 可能存在没有文本的空评论,异常处理保证程序执行的连续性
try:
emotion_label = dic['items'][0]['sentiment']
except KeyError:
return 1 # 若无内容,则为中性评论
return emotion_label
4.绘图
def emotion_analysis(comments):
"""对所有评论进行情感分析并绘制饼图"""
pos_comment = 0 # 积极
rel_comment = 0 # 中肯
neg_comment = 0 # 消极
for comment in comments:
if get_emotion(comment) == 0:
neg_comment += 1
elif get_emotion(comment) == 1:
rel_comment += 1
else:
pos_comment += 1
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文支持
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
plt.style.use('fivethirtyeight') # 图表样式
attitude = ['消极的', '积极的', '中肯的'] # 标签
popularity = [neg_comment, pos_comment, rel_comment] # 数据
# 绘制饼图
plt.pie(popularity, labels=attitude, autopct='%1.1f%%',
counterclock=False, startangle=90, explode=[0, 0.1, 0])
plt.title('评论情感分析')
plt.tight_layout()
plt.savefig('情感分析结果.png')
plt.show()
print('情感分析完毕!')
央视新闻标题
# _*_ coding: utf-8 _*_
import requests
import re
from datetime import datetime
def cctv(company, page):
num = (page)
# 第一步:模拟浏览器,在央视网中输入相应的企业,并得到网页源代码
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'}
url = 'https://search.cctv.com/search.php?qtext=' + company + '&sort=date&type=web&vtime=&page=' + str(num)
print('正在获取----------------》》》',url)
res = requests.get(url, headers=headers, timeout=10).text
# print(res)
# 第二步:正则表达式提取文本信息
p_href = '<span lanmu1=".*?"'
p_title = 'target="_blank">.*?</a>'
p_source = '<div class="src-tim">.*?<span class="src">(.*?)</span>'
p_date = '<div class="src-tim">.*?<span class="tim">(.*?)</span>'
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
for i in range(20):
title.remove('target="_blank"></a>')
source = re.findall(p_source, res, re.S)
date = re.findall(p_date, res, re.S)
# 第三步:信息清洗
for i in range(len(title)):
title[i] = title[i].strip().replace('target="_blank">', '')
title[i] = title[i].strip().replace('</a>', '')
href[i] = href[i].strip().replace('<span lanmu1="', '')
href[i] = href[i].strip().replace('"', '')
source[i] = source[i].strip()
date[i] = date[i].strip()
# 第四步:自动生成报告
# time = datetime.now().strftime('%Y-%M-%d')
# file_path = time
file1 = open('结果数据' + '.txt', 'a', encoding='utf-8')
file1.write(company + '数据爬取开始了!' + '\n' + '\n')
# 第五步:输出爬取信息到数据报告中
for i in range(len(title)):
file1.write(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')' + '\n')
file1.write(href[i] + '\n')
file1.write('-' * 60 + '\n' + '\n')
file1.close()
# 第六步:依次爬取不同的企业
companys = ['皮影戏']
for company in companys:
for i in range(10):
try:
cctv(company, i + 1)
print(company + '第' + str(i + 1) + '页信息爬取成功!')
except:
print(company + '第' + str(i + 1) + '页信息爬取失败!')
网易新闻标题
# PyCode-Github/爬虫-所有
# _*_ coding: utf-8 _*_
# @Time : 2022/4/27 21:19
# @FileName : 网易新闻.py
import random
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
headers = {
"Cookie": 'WM_TID=vmnobKPZql5FQQAVBVIqvvBV1sX%2F4YTJ; WM_NI=cIS3xusLaiBpcwc1aU3Xy%2FsmuTRyBvwuDzOyWuyiI%2F8JTbyERrL8KzkBmmJXGu98YyEgTM77a89tnKc4OxLEzkHfAm4SOu8K0DyCznFvGgXszoVhvB6ijwhTFYu5Vjt7eUM%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee86d180a596aeb8e480b1968fb6d84e868e9e86c15e97e7b798fc738de9fdd1d32af0fea7c3b92aa1979dd4fb7fb194af8ac17ca1a9add2e45ff188b7d0f267b78c9e9ac17eb5ab8c9bce7395abb78acc25fc969c83fc4f92ae84d9ca72a99ea38ec95485abf7d9dc7387b99caeb63da3e8f795ed41a1ec8199cf4fbab58887c467f88d8196bb41f49cb7a4f96686aa8988db79bab19a89f54af6b7a698eb608687bbd6d562b8e9abb6d037e2a3; _ntes_nnid=dd35c7c0872421fca032e3d8604a9733,1650637481352; _ntes_nuid=dd35c7c0872421fca032e3d8604a9733; _antanalysis_s_id=1651065371996',
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.30'
}
# 获取文章文字
def getItemInfo(url): # 获取文字
try:
res = requests.get(url, headers=headers).content.decode('utf-8')
soup = BeautifulSoup(res, "lxml")
title = soup.select('.post_title')[0].string # (标题)
contentList = soup.select('.post_body > p')
content = '' # (内容)
for i in contentList:
content += str(i.string)
content = str(content).replace('None', '')
content = content[0:200] #截取前200个
time = soup.select('.post_info')[0].contents[0].string
time = str(time).split(' ')[0] # 截取时间
time = time.replace(' ', '') # 替换空格(时间)
author = soup.select('.post_info')[0].contents[1].string # (作者)
print('获取成功~~', url)
return [title, author, time, content, url]
except:
title = soup.select('.title_wrap > h1')[0].string # (视频标题)
print('视频链接~~', url)
return [title, ' ', ' ', ' ', url]
# 获取所有URL
# url = 'https://www.163.com/search?keyword=%E8%AF%88%E9%AA%97' #获取诈骗关键字
url = 'https://www.163.com/search?keyword=%%E4%BC%A0%E7%BB%9F%E7%9A%AE%E5%BD%B1%E6%88%8F' # 获取反诈关键字
response = requests.get(url, headers=headers).content.decode('utf-8')
print(len(response))
soup = BeautifulSoup(response, "lxml")
listBox = soup.select('.keyword_list > .keyword_new > h3 > a')
for i in listBox:
try:
itemInfo = getItemInfo(i['href'])
# time.sleep(random.randint(1, 5)) # 延时随机1-5
except:
print('获取所有URl报错了~~~~~')
df = pd.read_csv('新闻数据.csv', encoding='utf-8')
df.loc[len(df)] = itemInfo # 其中loc[]中需要加入的是插入地方dataframe的索引,默认是整数型
df.columns = ['标题', '作者', '时间', '内容', '文章链接']
df.to_csv('新闻数据.csv', index=False, encoding='utf_8_sig')
print('总共获取数据:', len(listBox))




![DAY 77 [ Ceph ] 基本概念、原理及架构](https://img-blog.csdnimg.cn/6016b8e5f6174afaaf5cb13e39a8edcd.png)