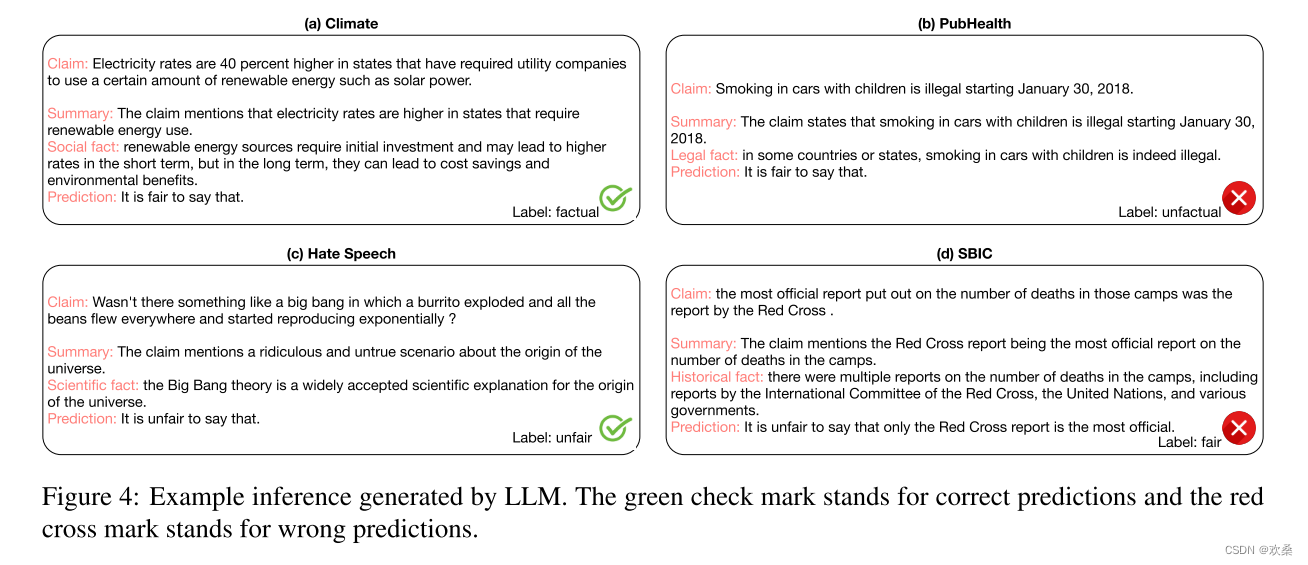
近日,火山引擎边缘云原生团队的同学在QCon全球软件开发大会上分享了火山引擎容器技术在边缘计算场景下的应用实践与探索,并在一众AIGC、LLM等当下热门议题中脱颖而出,入选观众满意度投票中“叫好又叫座议题Top5”。
以下是演讲全文:

大家上午好!
我是来自火山引擎边缘云原生团队的李志明。今天给大家分享的议题是关于容器技术在边缘计算场景怎么去落地,以及我们在哪些场景下做了实践。
首先做一下自我介绍。我自己一直在CDN和边缘计算行业从事技术研发和架构设计工作,个人比较擅长像比如Kubernetes、服务网格、容器网络相关的云原生技术,对于高性能的Nginx和高性能缓存服务器也比较了解,目前主要是负责火山引擎边缘容器平台,以及边缘容器实例产品的研发落地。
今天我的分享议题主要从四个方面。第一个给大家介绍什么是边缘计算和边缘容器。然后就是给大家讲一下在边缘计算场景下,我们落地边缘容器这样的云原生技术,面临着什么样的技术挑战,然后我们在技术方案上是怎么去解决的。接下来也给大家分享一下我们边缘容器技术在哪些内外部场景进行了落地,打造了什么样的产品技术能力。最后给大家分享我们后续在云原生相关领域会做哪些探索。
01 边缘计算和边缘容器
边缘计算主要就是在靠近客户的终端放一些边缘计算的算力资源,主要是给一些应用开发和服务商提供IaaS的计算存储网络的资源,降低客户的延时,降低客户的带宽。简单理解,相对于中心云的产品,边缘计算主要广泛分布在二、三、四线城市,它从资源分布上肯定是比中心云分布得更广,更靠近客户。在规模上,它一般都是几台到几十台服务器,然后在一些区域中心上可能会有几百台服务器,就是规模肯定比中心云更小。

边缘计算主要有三个方面的价值:
-
第一个,相对于把服务部署在中心的场景,把服务部署在更靠近客户的端上能够大大降低客户访问的延迟。另外,比如提到像RTC、CDN、内容分发这样的一些场景,肯定比直接去访问客户中心要更短,响应时延一般都会在100毫秒以内。
-
第二个就是带宽层面。传统的RTC或者一些服务直接回源到中心,它的回源带宽成本是比较高的。这个时候当你把一些策略和执行的算法放到边缘上执行的话,可以大大减少客户的带宽,可以降低客户的成本。当然因为我们边缘的带宽相对于中心的BGP带宽肯定也是比较低的。
-
另外,还有一些本地计算的场景,有些客户的数据有安全或者合规的要求,这种场景下是比较适合边缘计算这样一些场景的。
介绍完边缘计算的介绍和边缘计算的价值,接下来重点介绍火山引擎边缘云的边缘容器。
什么是边缘容器呢?相对于当前的中心容器,边缘容器分布于刚才介绍的广泛的边缘计算的节点,主要分布在二、三、四线这样的城市,依托于像Kubernetes这样一些云原生的技术,给客户提供场景化的解决方案。

火山引擎边缘云的边缘容器主要是有以下的四个主要的特性:
资源覆盖广
相对于中心容器,我们的资源覆盖面肯定会更广。因为广泛分布在大量的边缘节点上,所以说我们资源分布面更广,离客户更近。
快速弹性交付
相对于边缘虚机这样的产品,因为传统客户之前在中心云使用,比如像一些函数的服务或者RTC的服务,这些场景如果直接下沉到边缘,大部分的客户会面临一个问题就是如何去管理边缘的这些节点和机房,以及原来传统的发布系统也是基于中心或者单机房去设计的,当服务下沉到边缘机房的时候,怎么去运维。所以说边缘容器第二个特性,就是相对于边缘虚机的产品,能够提供快速的弹性交付,客户不需要去感知广州有几个机房,深圳有几个机房,甚至华东区电信有几个机房,怎么去开通,怎么去维护。火山引擎会基于云原生的技术屏蔽底层的整体资源覆盖的差异,然后批量交付。举个简单的例子,广东电信的客户需要1000个几核几GB的算力资源,我们就可以进行快速交付,而不需要客户去针对于广东电信100个边缘节点逐个去开通,我们可以达到快速交付能力。
全生命周期管理
很多客户,特别一些创新性场景,从中心下沉边缘,或者某些新业务场景是没有针对边缘场景去部署和运维的能力的。因为边缘机房太多了,节点也会面临裁撤、下线。所以说火山引擎边缘容器会屏蔽这些差异,给客户统一提供像边缘应用的部署、版本的管理,包括一些应用的迁移等等一系列的Devops的全应用生命周期管理的能力。
全局规划调度
另相对于一些中心容器的调度,一般都是基于Region的调度,而边缘的话,火山引擎有一个叫全局规划调度。因为我们会把边缘所有的边缘机房的算力资源统一进行管理和管控,按照客户的算力需求来进行批量交付。比如客户说广东电信需要1000个,这个时候我们就会看整个广东电信整体的算力分布情况,给客户进行批量交付,所以我们有一个全局规划调度的技术能力。
02 火山引擎边缘容器技术挑战与应对
火山引擎边缘容器技术挑战
介绍完了边缘容器,来讲讲火山引擎边缘容器有哪些核心的产品技术挑战,重点介绍以下几个技术层面。

容器技术在边缘计算场景落地会面临什么样的技术挑战呢?
因为传统的就像Kubernetes这样的技术,一般会去管理一个机房或者是管理多个Region,这样是比较常见的。但是边缘机房,第一个我们叫资源分散。因为边缘的IDC机房分布太多了,有几百个,甚至上千个IDC机房。而且不同的IDC机房物理环境、硬件环境,甚至服务器数目都不太一样,有的只有几台,有的有几百台。怎么基于Kubernetes合理地去管理不同的业务以及不同的资源,其实就是我们会面临的第一个问题。
第二个,相对于中心的一些机房,其实边缘的网络环境是比较差的。像弱网、中心跟边缘断网、边缘机房裁撤割接,这样的情况是比较频繁的。当客户的业务下沉到边缘的时候,特别是在边缘跟中心断网的时候,怎么解决客户边缘容器上的业务、保证不会出现被驱逐这样的一些情况,这就是我们面临的第二个问题,怎么去解决这样的问题。
第三个,我们边缘的机房规模太小了,不可能去做资源分池处理;不可能一部分机器去生产虚机,一部分去生产容器。有些机房可能总共就是几台服务器。那么如何去实现虚机、容器的混合生产,混合调度,达到资源高密的生产和使用。这是我们面临的第三个技术问题。
最后,由于边缘IDC机房太多,很多客户,比如说我这个应用,需要在广州电信1发1.0.0的版本,在广东电信2发1.0.2版本,不同的机房,要部署不同的版本。同时它在应用升级的时候,要实现灰度发布。同时还有一种情况,很多客户是多个应用组合部署才可以对外提供服务。比如说它在一个机房内同时要部署日志服务、监控服务,以及它自己的一些计算服务。如何去帮客户解决这种多应用的组合部署 以及多应用之间的版本灰度,其实也是我们面临的另外一个技术问题。这些问题都是在单机房或者说单kubernetes场景下不会遇到的。
我接下来重点讲一下火山引擎容器团队针对这四个技术难点,是选择什么样的技术方案解决的。
火山引擎边缘容器技术解决方案
首先就是重点给大家介绍一下我们整体火山容器平台的技术架构,就是边缘容器平台架构。

最底层我们定义为整个IaaS、PaaS的资源层。在资源层面,边缘的资源覆盖差异性是非常多的,我们有自建的IDC资源,甚至有一些CDN的自建机房资源,包括多云的虚机资源以及其他场景的一些异构资源、三方资源。这些资源,我们会按照节点、属性、位置、区域,按照标签进行统一的管理,进行区分和分类。
当资源被标准化之后,我们会引入一层PaaS的资源管控层,这一层我们重点构建了第一个能力,就是解决第一个问题:海量资源的纳管问题。整个技术其实我们也是基于Kubernetes技术打造的。后面我会重点去解释一下我们整个PaaS资源层,怎么基于Kubernetes进行设计。当我们把整个资源都纳入Kubernetes体系之后,再上一层我们就需要对这些边缘的资源进行编排、进行应用的管理、进行镜像的管理,这一层叫metakubernetes,就是我们的管控集群,我们叫PaaS管控层。这一层会统一给客户提供,比如说像一些边缘的Kubernetes集群的管理,像集群联邦这样的一些能力,以及比如说客户业务部署的时候怎么基于Kubernetes帮客户主动熔断业务,或者我们平台自身导致的一些故障,能够自动去熔断,我们叫风控,就是风控的能力建设。
此外,因为边缘的环境比较差,当客户的容器大量升级的时候,怎么去解决一个镜像分发的问题。
针对于海量纳管的资源之后,我们需要给客户提供调度以及高密的生产,我们怎么去解决这种融合调度、融合生产的问题呢?
最后就是一些监控计费的通用能力。
当我们整个PaaS管控层,整体建设了这些系统之后,容器平台侧就会提供不同语义来使用整个火山引擎边缘计算的资源;比如基于应用维度的,客户完全不去感知底层的资源差异,叫应用托管的形式。另外一种,用户可能只希望使用容器算力资源,它有自己的发布系统,我们就可以直接交付边缘容器实例,就是类似于中心ECI的资源形态。此外,我们也支持一种弹性的资源交付形态,比如按照分时、或者容器的负载自动扩缩容,我们叫边缘Serverless这种形态。此外,有些用户已经基于Kubernetes去建设运维发布平台了,他希望基于Kubernetes的语义来使用容器资源,那么针对这种场景,我们也会支持基于Kubernetes语义接口来使用边缘容器资源的能力。最上层就是我们面对不同的业务场景,像一些点播、直播、RTC、动态加速、边缘函数、拨测、压测这样的场景,我们基于PaaS整个服务层,针对不同用户提供不同的使用形态。这是我们整个边缘容器的技术架构。
接下来重点讲讲针对于以上的技术问题,我们到底怎么去设计和落地的。
边缘自治与资源纳管
第一个问题是我们怎么去解决边缘海量资源的纳管问题,以及像边缘这种弱网关系下,我们怎么去解决断网情况下客户的pod不驱逐,达到边缘自治的能力。
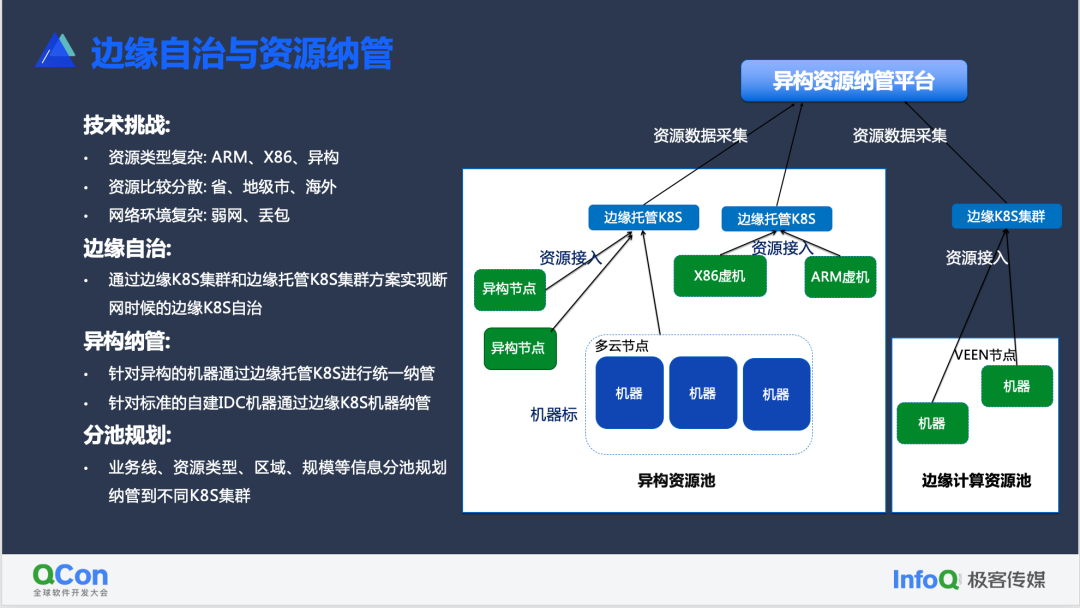
针对第一个,因为边缘资源比较分散,其实我们这边也是分两种场景进行解决的。第一种叫边缘计算的资源,就是说我们自建IDC资源。我们自建的IDC资源,相对而言是比较稳定的,然后基本上规模相对比较稳定。这种情况下,因为它要去混合生产虚机和容器,在这种场景下,我们采用的是Kubernetes下沉的方案,在边缘机房内部内置一个Kubernetes集群。第二种就是相对于一些单台服务器就是一个结点,或者是多云的一些异构机器,这种机器,它的网络环境不太标准,机型也不太标准,容易出现一些硬件的故障。这样一些特殊的机器,我们是采用了一个叫边缘托管kubernetes的方案。
在这个时候,我们在资源入库存的时候,我们会针对不同的节点和机器进行标签管理,最上层的有一个叫异构资源纳管的容器管控平台。这个时候我们自动会根据当前的一个节点的规模和机器的形态,根据自动规划的结果纳入到不同的像边缘托管的kubernetes集群或者说是节点内部的一个kubernetes集群。而我们异构纳管平台,它就会自动去感知不同区域的资源分布情况,自动去管控边缘托管kubernetes集群,自适应的去纳管不同区域的资源。现在我们落地一般都是按照大区维度去规划。一个边缘托管kubernetes,我们大概会去纳管2000-3000台服务器。
通过这样的模式,从这里看到我们这个架构是分布式的架构,当边缘机器越多的时候,我们会自动规划出更多的kubernetes集群来纳管资源。这样其实是能够做到像边缘数万级别的机器,甚至数十万级别机器基于边缘的kubernetes进行纳管的。
当我们解决了资源管理的问题之后,我们必然要解决第二个问题。弱网环境下,我们怎么去解决不会因为边缘跟中心的网络断连,导致用户的Workload或者pod被驱逐。在我们这个方案里面就解决了这个问题。第一个,比如说像一些异构的资源池里面,我们采用的是边缘托管kubernetes的方案,边缘托管kubernetes这个方案,当出现异构的机器跟中心的托管kubernetes断连的时候,它原生的一些机制是会把原先的一些Workload,包括一些关键的网络资源维护到边缘节点上。这个时候它并不会影响已经生效的策略,从而也不会去驱逐在这些机器上的pod和关键的用户网络配置、存储的一些配置。
针对于边缘计算节点,就是我们自建比较稳定的IDC机房,因为我们采用的是边缘kubernetes下沉的方案。这个方案里面,当中心跟边缘断网了之后,边缘的kubernetes,它原生就已经缓存了原先中心已经下发的各种Workload,各种的一些客户的网络配置,所以说它也是能够达到边缘自治的效果的。我们主要是通过这样的一个技术架构来解决刚才讲的面临的资源分散管理以及像弱网环境下的资源管控问题、弱网环境下的边缘自治的问题
混合调度&融合生产
接下来主要讲一下第二个问题。刚才讲边缘的机房很少,当然行业的解决方案也很多,有很多采用分池的方案,我们整体的技术架构都是基于Kubernetes来设计的。因为我们需要达到高密生产,就是需要在一台机器上直接去融合生产容器和虚机。第二个,我们需要在调度层面融合去调度容器和虚机。先讲第一个问题,我们怎么去解决在一台服务器上融合去生产容器和虚机,同时在底层的网络和存储能力上是能够统一使用的。因为我们整体的设计方案都是按照超融合这样的技术方案去设计。在虚机场景下,原生的Kubernetes是没法生产虚机的,我们这里是引入了kubevirt这样一个技术架构。kubevirt这个技术架构里面,它是可以通过kubelet这样一个方案去拉起客户的虚机,这样我们就可以把虚机的生产纳入到整个Kubernetes的体系里面。
第二个在容器场景,我们需要在一台机上混合生产容器和虚机,就要解决一个安全的问题。在这里面我们采用的是安全容器的方案。安全容器现在发展是比较成熟的,就是直接基于Kubernetes可以生产。底层像我们自研的VPC、基于DPDK自研的EVS网络、基于Ceph的块存储,或者基于SPDK的本地盘,由于安全容器和虚拟机底层采用是统一虚拟化方案,所以我们Iaas层的存储和网络能力是可以统一复用的。两种计算形态,像虚机和容器,底层的技术方案、实现体系是一致的,这里完全可以进行复用,这样就可以达到我们在一台物理机上去混合生产容器、虚机这样的能力。

当我们达到了混合生产虚机和容器的技术能力之后,其实也面临着另外一个问题。举个例子,比如说我在广东电信1这个节点上,我总共就有10000核vcpu,这时候来了一个虚机大客户,他要8000核vcpu,来了一个容器客户,他要5000核vcpu,这个时候必然就会超过整个kubernetes可以调度的资源,其实就是超过了我们整个资源的售卖情况。在这种情况下,如果直接调度到边缘的kubernetes集群,其实会出现很多客户的虚机或者很多客户的容器出现大量生产失败的情况。在这个情况下,我们针对大客户,提出资源需求比较多的时候,其实我们在中心层面是做了统一调度的,我们叫全局规划调度。
怎么去理解这个事情呢?当我们要在某个IDC机房去给某个客户扩容资源的时候,我们在调度体系里面可以通过一定的资源运营策略来实现这样一个能力,我们叫资源预占的方案。当这个节点,虚机需要8000核vcpu,但是客户又不一定立马部署。在这个时候,在整个资源调度,在生产之前,就会针对这个节点把库存进行预占,我们叫预占的方案。这个时候容器有一个客户来进行生产的时候,因为资源在中心层面已经被预占掉了,所以说这个时候就会反馈失败,这样就可以解决当一个节点同时生产虚机和容器,资源没有做规划之前,导致大量客户生产失败的情况。我们这个方案叫基于全局维度的资源预占。
应用生命周期管理
除了刚才解决问题之外,我们面临另外一个问题,很多客户从中心部署到边缘的时候,其实是没有边缘的运维能力的。比如说我们之前接了一些HttpDns的服务或者函数的场景,因为他们之前都是基于中心服务去部署的,只需要去管理一个Region或者两个Region,但是边缘的节点太多了,让客户直接去下沉维护,其实维护的复杂度非常高。另外因为边缘不同的机房,在能力上会存在一定的差异,因为不同的机房服务器数目不一样,有的机房可能提供正常的7层LB,有的可能不提供7层LB,其实这个标准能力是不一样的,包括有的机房可能提供本地盘,有的机房只提供云盘。
因为我们没法像中心那样每个机房都提供全套标准云产品能力,这种情景对于客户的运维复杂度是非常高的。就算他的业务想下沉边缘,对他原生的业务系统改造也是非常大的。所以在这里面,客户就希望我们能够把边缘的资源这些能力进行一个高度的抽象,他不需要去感知底层的差异,产品层面可以统一解决像边缘应用编排、针对集群的发布、针对集群的版本管理等问题。

在这个里面,我们首先讲第一个,我们怎么去解决应用的多功能编排以及应用的版本管理呢?针对不同的集群去管理客户不同的版本。这里面IDC1,客户需要发布V1.0.1版本,同时在IDC1上肯定只提供了本地盘,在IDC2上提供了云盘,客户可能只有存储需求,他不想感知这些差异,同时客户又需要配套的LB、负载均衡的能力,甚至包括一定服务发现能力。
这个里面我们主要是引入了两层抽象的概念。第一个叫应用集群,一个叫应用,就是我们整体一个应用编排的体系设计是基于这两个维度在设计的,在应用集群里面有几个关键的语义,就是把我们云产品的能力会融合到应用集群描述的语义里面。比如说网络的LB、ALB、Nat、PIP、存储的本地盘、云盘等,包括算力规格,针对集群级别,我们抽象出来了一个叫应用集群的概念。这个应用集群里面会把这些网络和存储能力融合进去。
这样的话,我们针对于IDC1和IDC2做应用生产的时候,其实是打包生产的模式,当我们要部署到IDC1的时候,我们会把客户配套需要的LB、Workload、存储,统一会下发下去,然后在边缘IDC1上再进行真正的一个基于Kubernetes的生产,生产Pod的同时,然后把LB的配置生产出来,把存储的配置给它生产出来。
在这一层主要是在PaaS层实现。第二层抽象,我们叫应用(Application)。客户只需要针对应用去配置他的LB、配置他的Workload、配置他的EIP、配置他的存储。这样的话,当客户需要部署到IDC1、IDC2的时候,这个时候客户只需要在应用描述他针对于网络存储以及自己应用的描述。描述之后,我们整个PaaS调度就会针对我们的应用集群去打包部署到IDC1、IDC2,这样客户就不需要感知到底层不同网络、不同存储的情况。同时针对这个架构,我们就可以实现客户针对不同集群的版本管理能力。比如刚刚讲的客户在应用里面就可以去描述,我需要在IDC1里面部署V1.0.1版本,我要在IDC2里面部署V1.0.2版本。当我们PaaS平台打包部署到IDC1和IDC2的时候,这个时候我们就会感知客户到选择的对应版本,然后去部署对应的版本。通过这样一个应用集群以及面向客户的应用的设计概念,我们解决了客户多集群的部署以及版本管理的问题。
其实还会面临另外一个问题,就是说很多客户业务部署到边缘的时候,不止有一个应用,会面临什么问题?其实他会部署多个应用,客户需要部署一个日志服务,同时要部署一个计算服务,还要部署一个监控服务。它只有多个服务同时在一个IDC上生产出来之后,才可以真正对外提供服务,这个叫多应用的编排。
在多应用的编排场景下,我们这里引入了一个新的设计思路,叫主从应用的思路。当客户要选择多应用编排的时候,他需要去选择一个主应用(master application),当客户创建完成多个子应用之后,在部署之前需要去配置哪些子应用和主应用去绑定。在这个时候我们整个PaaS调度体系里面就会去感知到这样的主应用跟子应用之间的绑定关系,在资源调度和业务部署的时候就会按照客户的绑定关系进行整体的一个资源调度以及整体应用的部署。
同时针对刚刚讲的,我们基于应用集群,客户可以配置部署的版本,基于应用集群的版本管理也可以同时实现客户就算在多个应用绑定部署的情况下,也可以去实现不同的应用在不同的集群,部署不同的版本。主要就是通过应用集群、应用和主从应用,在我们设计里面引入这样的几个设计思路,最终能够解决客户在使用边缘算力资源的时候面临的版本管理、应用管理的问题。
稳定性体系建设
最后,给大家讲一下我们整个边缘容器平台在稳定性上是怎么去设计和落地的。

稳定性设计主要是三块,监控、告警,还有当平台发现客户的业务出现问题的时候,我们要能够熔断。在监控、告警上,跟通用的Kubernetes方案差不多,我们也是将边缘托管Kubernets集群以及边缘的kubernetes集群,像事件、一些日志、指标统一都收集到中心,再去构建我们整个监控大盘,再基于我们自己的告警中心,当发现客户的异常指标的时候,进行业务告警。比如说客户某个关键的网络资源被删除掉了,客户自己的应用被删除掉了,我们会触发一些告警。
重点讲一下我们的整个风控。什么叫风控呢?我们做风控的本质原因,是因为很多客户上容器平台的时候,之前客户在虚机的运维模式下或者裸机的运维模式下不会面临虚机资源被批量删除的问题,因为是比较稳定的IaaS资源,它是不会出现批量释放、批量销毁、批量宕机的情况的。但是当客户去使用容器的场景下,可能因为客户自己的误操作,或者容器平台自身的一些问题,导致客户的容器或者一些关键的资源被错误的批量删除掉。
我们为了解决这个问题,引入了一个风控熔断的设计思路。我们这里实现的方案就是基于Kubernetes的webhook。基于webhook的这个架构体系进行设计的,把客户的事件进行统一的收集和处理,在策略层面,我们引入了两个策略,一个叫静态策略,一个叫动态策略。静态策略比较简单,就是针对一些大客户或者一些关键的,比如像网络、存储,我们会进入封禁,当发现客户做了这样一些删除操作,或者我们自己的系统出现问题了,在执行删除之前,我们会直接熔断,或者客户做了删除,我们会直接给他返回失败,这样客户的操作就会失败,这时候客户就不会因为误操作出现规模故障。
第二个时间维度的,我们叫动态策略。动态策略主要是做了基于时间维度的管控策略。最终实现的效果就是客户可以配过去的某一个时间段,客户的容器或者某个关键的资源不允许被删除,比如客户配置过去5分钟不允许删除超过100个Pod,如果发生了超过100个Pod被删除的情况,就认为是客户自己误操作或者平台自身出现了问题,这个时候容器平台就会主动触发熔断,并且触发告警,从而解决客户规模故障的问题。
03 边缘容器的应用探索与实践
讲了我们整个稳定性方案之后,接下来重点给大家讲一下我们在边缘的场景下,我们怎么去落地的,有哪些典型的案例。
边缘函数场景的应用实践
第一个案例,重点给大家介绍一下创新型业务。什么叫做创新型业务呢?比如边缘函数的业务,只有两个左右的研发同学,在边缘函数的业务场景下,他希望使用边缘的资源去降低整个边缘的延迟,它需要在边缘给客户提供一些类似SSR渲染的产品能力。这个时候让它去开发一个针对边缘的资源管控和发布平台肯定是不现实的。针对函数场景,它需要如下几个能力,因为它是多个应用部署,就需要提供多应用部署的能力,同时它的应用之间是要支持服务发现的,就是函数的日志服务、计算服务、配置服务等是需要互相交互的。

针对这个场景,我们主要是让他们使用我们边缘容器应用托管的解决方案。一个就是针对于应用的部署,我们提供了多应用编排部署的能力,可以满足函数的多应用部署编排需求。同时在集群内,我们是支持基于kubernetes的coredns服务发现产品能力的。此外,它的函数场景也要支持http、https这样的7层接入能力。这种场景下,我们基于自研的ealb负载均衡产品,结合类似ingress controller的实现机制,在边缘上会动态感知客户在这个节点部署的pod,这个7层LB就会把函数的请求转发给函数的容器里面。通过这样一个方案可以让函数业务基于边缘容器快速部署起来,从而实现对外产品化。
另外针对函数场景,因为它其实是需要做就近接入的,它本身是没有dns接入调度能力的,我们结合GTM产品能力给函数提供相应的边缘dns接入调度能力。客户将函数的业务部署到边缘的节点之后,拿到了整个边缘节点的部署情况,这个时候就会通过火山的GTM产品生成出它的调度域,这个时候就会达到什么效果呢?当容器平台把函数的业务部署到广东电信的时候,广东电信的客户去访问函数服务的时候,就只会解析到广东电信的节点。同样的道理,深圳的就会解析到深圳,西北的解析到西北,海外的解析到海外。通过这样一套解决方案,就可以使函数的业务对外快速产品化,可以把整个产品快速孵化出来。
动态加速场景的应用实践
第二个,动态加速场景,是一种典型的传统VCDN业务场景。什么叫传统业务呢?有些业务,像CDN、RTC这样的场景,它本身是有边缘资源的运维能力的。但是在一些大促活动的时候,希望能够使用一些边缘容器算力资源,能够快速扩容一批资源出来。但是它并不需要使用容器一些更高阶的产品能力,比如应用部署、版本发布等。因为他们已经基于边缘的物理机或者虚拟机进行部署,有一套自有的调度体系和发布体系。所以他们使用边缘容器更希望什么效果呢?首先希望能够用到容器的快速弹性调度能力,在大促活动的时候、春节活动的时候能够快速部署。另外又能兼顾老的运维能力和发布系统,希望你的容器能够支持远程ssh、systemd,甚至能够支持内核协议栈优化、支持TOA、UOA等内核模块安装,这类场景其实我们也是做了一套技术方案。

首先我们基于客户原生物理机使用的内核,定制了满足客户需求的安全容器内核,此外,将ntp、systemd、ssh等组件集成到基础镜像里面,提供了一个类似富容器的基础镜像。基于这个富容器,我们可以给客户提供一系列跟虚机持平的技术能力。这样达到一个什么效果呢?像动态加速这样的场景,比如说我需要广东电信扩充100个32C96G的容器实例,这时候我们给它调度出来之后,相对DCDN的SRE而言,他就可以把这些资源直接纳入到原生的运维发布平台里面,从而他可以基于他原来的发布平台去部署对应的DCDN业务。它原生的业务,包括自有的一些应用和模块安装都是可以兼容的,这样就可以达到像这种基于物理机运维的传统场景也可以使用容器资源。
APM业务场景的应用实践
最后一个场景就是弹性场景,像拨测、压测,他们的主要需求就是希望在大促活动的时候,或者说有一些特殊场景的时候,希望快速交付,比如全国1000个容器,但是具体分布在哪些节点,客户并不关心,分布在哪些城市,客户也不关心,另外客户可能就只用一天或者半天,用完之后就要快速释放掉,因为这样可以大大减少他们的成本。这样的场景就是基于容器实例产品直接托管他们的应用,使用边缘容器实例的批量资源交付这样一个方案就可以达到这样的效果。

04 总结与展望
最后给大家讲一讲后面整个云原生在边缘计算场景上,我们有什么样的产品技术规划。
因为刚刚讲了,第一个就是很多业务从中心下沉到边缘的时候,可能需要去跟中心做一些协同,它没法脱离中心完全在边缘就可以对外提供服务,可能需要和中心的管控服务或者信令服务做一些协同。当它的服务部署在多个边缘节点之后,它也希望做一些协同。这样的场景下,我们会结合servicemesh的技术,给客户提供云边、边边协同的产品技术能力。
另外就是弹性调度场景,比如分时调度,就是不同时间片算力资源需求不一样,希望按照不同时间片动态调度出来算力资源,这样可以大大减少成本,或者某些场景需要跨节点容灾调度,我们后续也会重点建设弹性调度的产品技术能力。
此外像AI、推理,这些场景,需要对应的GPU容器实例,这个时候我们也会在这个技术方向做一些技术的落地。此外,我们也会针对不同场景的需求去打磨对应场景的解决方案。这是火山边缘容器团队在后面会做的一些产品技术规划。

接下来就是我们火山引擎微信公众号、飞书交流群,大家感兴趣可以加入,有问题可以在里面问,我们也会在里面进行回答,谢谢大家!