心脏病是人类健康的头号杀手, 全球大约1/3的人口死亡是由心脏病引起的。而我国,每年大概有几十万人口死于心脏病。如果我们可以通过提取人体相关的指标(既往病史、家族病史、血压情况、血糖情况等等),通过数据挖掘方式来分析不同特征对于心脏病的影响,或者建立电子病历,收集数据集并建预测模型,将对预防心脏病起到至关重要的作用。
本项目基于数据分析、数据挖掘,根据疾病的特征预测是否患有心脏病。
1. 项目介绍
这是一个基于机器学习的二分类任务,根据给定“患者”的某些属性信息,预测是否患有心脏病。本项目使用的数据来源于UCI机器学习库。
UCI机器学习库中,一共包含4个关于心脏病诊断的数据集,分别是:
1、cleveland.data
2、hungarian.data
3、long-beach-va.data
4、switzerland.data
每个数据集都包含76个属性,但是所有已发布的实验都只使用了其中14个属性。其中,cleveland.data是机器学习研究人员最常使用的数据集。
2. 数据获取
2.1 获取方式1
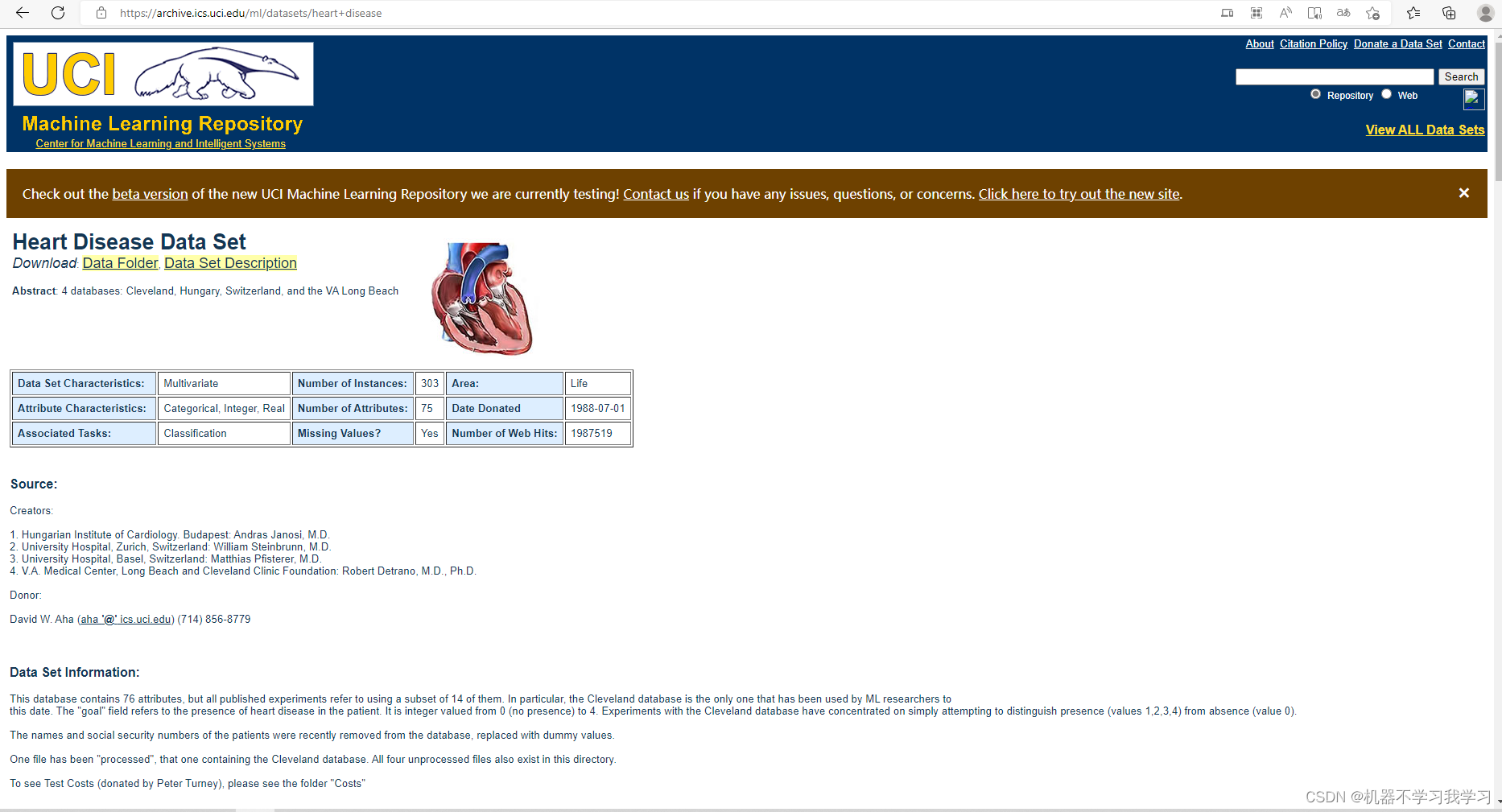
UCI网站获取:
https://archive.ics.uci.edu/ml/datasets/heart+disease
2.2 获取方式2
kaggle网站获取ÿ

![[附源码]Python计算机毕业设计Django社区住户信息管理系统](https://img-blog.csdnimg.cn/097f6469c1e5432b855ab5c8153d95aa.png)



![[附源码]JAVA毕业设计流行病调查平台(系统+LW)](https://img-blog.csdnimg.cn/dff8c562a06c4b20b3ba206960130c4a.png)