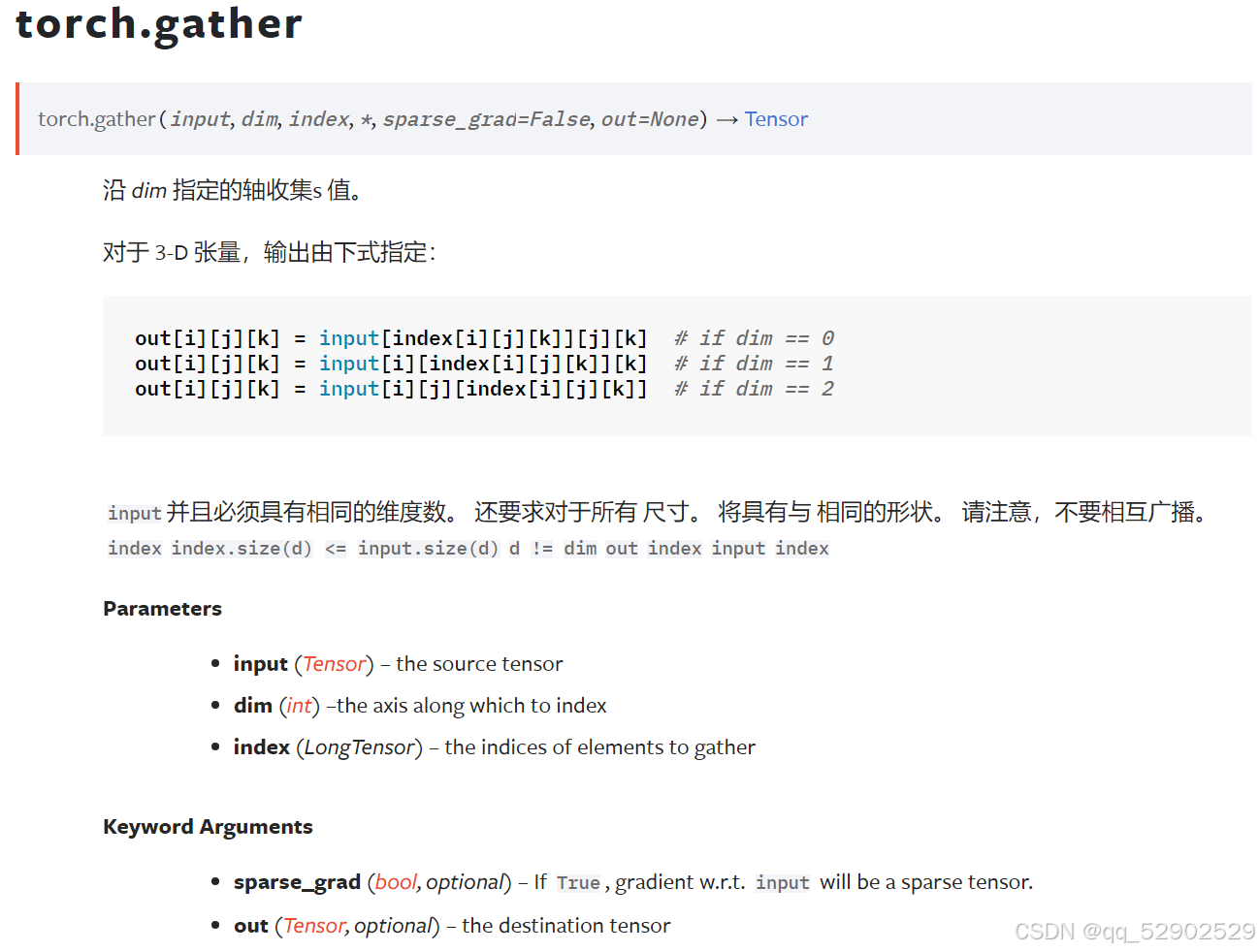
数据清洗与集成:保障数据质量的关键环节
在当今数字化时代,数据扮演着至关重要的角色,然而原始数据往往存在诸多问题,需要经过一系列处理才能更好地服务于分析和决策。数据清洗与数据集成就是其中两个关键环节,下面我们将对其进行详细介绍。
一、数据清洗概述
(一)数据清洗的定义与重要性
数据清洗,顾名思义,是对数据进行清理的过程,旨在确保数据的质量和一致性。这一过程至关重要,因为它直接关系到我们能否从数据中提取出有价值的信息。如果数据未经清洗,其中存在的问题,如缺失值、异常值或重复记录等,将会导致数据分析结果出现偏差,影响我们对数据真实情况的理解以及后续决策的准确性。
(二)数据清洗的步骤
数据清洗通常包括以下几个关键步骤:
- 识别数据中的问题:需要敏锐地察觉数据中存在的诸如缺失值、异常值或重复记录等情况。例如在客户数据库中,可能会发现一些客户的邮箱地址格式不正确,或电话号码缺失等问题。
- 处理这些问题:针对识别出的问题,可采取多种方法进行处理。比如填充缺失值、修正错误或删除重复记录等。
- 验证清洗的效果:确保经过处理后的数据具备准确性和完整性,为后续数据分析打下坚实基础。
二、数据清洗常见方法
(一)处理缺失值
- 缺失值的含义与产生原因:缺失值指数据集中某个或某些属性的值是不完整的,这种情况在数据收集过程中较为常见,可能是由于录入错误、数据丢失或其他原因造成的。例如在客户数据库中,可能存在某个客户的收入属性值缺失的情况,若不妥善处理,会影响基于收入进行的相关数据分析。
- 缺失值的处理方法:
- 忽略元组的方法:当缺失的是类标号时可考虑此方法,即删除那些带有缺失值的记录。不过该方法简单直接的同时,可能会导致数据量减少,影响模型的泛化能力,适用于缺失值对整体数据集影响不大或缺失值比例很低的情况。
- 人工填写缺失值:通常适用于缺失值较少且容易获取补充信息的情况,但成本较高,且可能引入主观性。
- 使用一个全局常量填充:比如用“n”或数字“0”填充,操作简便,但可能会影响数据的分布和模型的性能。
- 根据数据的分布特点来填充缺失值:若数据是对称分布的,可使用属性的均值来填充;若是倾斜分布的,则使用中位数。此方法能更好地保持数据的原始分布特性。
- 使用同类样本的属性均值或中位数填充缺失值:当缺失值的属性与其他属性有较强的相关性时,该方法可以更准确地估计缺失值,帮助保持数据的内在一致性。
- 使用最可能的值填充:通常涉及到机器学习技术,如回归分析、基于推理的工具或决策树归纳等,可利用数据中的其他特征来预测缺失的值,从而提高填充的准确性。
处理数据缺失值时,要根据数据的特性和分析的需求,灵活选择最合适的方法,因为没有一种方法适用于所有情况。
(二)光滑噪声数据
- 噪声数据的概念:噪声数据就是数据中的随机误差和方差,在数据分析过程中,它可能会干扰我们对数据真实情况的把握以及分析结果的准确性。我们可通过数据核图、散点图或其他数据可视化技术来识别可能的噪声。
- 处理噪声数据的技术:
- 分箱方法:这是一种通过考察数据的精明值,将有序数据的值分布到一些桶和箱中,以减少异常值影响的数据预处理技术。常用的分箱方法有等平分箱法(将数据集按元组个数分箱,每箱具有相同的元组数)、等宽法和用户自定义区间法。此外,还有采用箱平均值光滑(将箱中的均值替代每一个真实的数据值)以及用箱边界值光滑(将给定箱中的最大和最小值视为箱边界,将箱中的每个值替换为最近的边界值)等具体实现方式。
- 回归技术:是一种利用数学中的拟合函数来模拟变量之间关系的数学工具,特别适用于平滑数据、减少随机波动同时保留数据基本趋势的情况。其中线性回归是最基础直观的一种,通常用方程(y = ax + b)来表示变量间关系,通过最小二乘法来估计参数,找到最佳拟合直线以去除数据中的随机噪声,并揭示数据中的趋势和模式。
- 孤立点分析技术:孤立点是指那些不符合数据集整体模式的异常值,聚类是一种将数据集中的对象分组,使同一组内对象相似度高、不同组之间对象相似度低的技术,通过聚类可找出并清除落在簇之外的孤立点。在实际应用中,需根据数据特点和分析需求来决定如何处理这些孤立点,比如删除、修正或保留等。
(三)纠正数据偏差
- 数据偏差产生的原因:在数据的收集和处理过程中,数据偏差是常见问题,其产生原因多种多样,包括设计不完善的表单输入、人为或有意的错误输入、数据表示或编码的不一致性,以及硬件设备故障或系统错误等。此外,数据集成过程中由于不同数据库使用不同的术语也可能产生偏差。
- 偏差检测与纠正的方法:检测偏差是数据清洗的第一步,通常可根据已知的数据性质(如数据类型和定义域等),利用一些统计方法和业务规则来发现数据中的噪声、孤立点以及任何不寻常的值。一旦发现数据偏差,可采取数据转换、数据标准化、填补缺失值或删除异常记录等措施来纠正偏差,这是确保数据质量的重要环节,有助于提高数据的准确性和分析的有效性。
三、数据集成
(一)数据集成的概念与作用
数据集成就是把来自不同地方的数据,比如几个数据库、数据立方体或者普通的数据文件,都整合到一个统一的地方(如数据仓库里)。这样做可以减少数据重复和不统一的问题,让数据挖掘变得更准确、更高效。
(二)数据集成需重点考虑的方面
- 模式集成和对象匹配:整合数据时,若不同数据库里存在相同信息,需确认其格式是否一致,保证系统里的规则和目标系统相符,避免在整合数据结构时出错。同时,要准确识别来自不同数据源却代表同一个真实世界事物的信息,这可能面临同义不同名或同名不同义等难题。
- 语义问题:由于各种数据来源的表达方式、测量方法或者编码都不一样,可能会出现数据值冲突的情况,例如不同系统中对重量采用不同单位表示、不同地方旅馆房价因多种因素存在差异、不同大学成绩计分方式不同等,这些都给数据集成带来挑战。此外,不同系统中原子属性的抽象层可能不同,也需要谨慎处理,确保数据准确整合。
总之,数据清洗与数据集成是保障数据质量的重要工作,在大数据应用日益广泛的今天,掌握好这些关键环节的相关知识和技术,对于准确挖掘数据价值、助力科学决策有着不可忽视的作用。












现代C++的第三方库的导入方式: 例如Visual Studio 2022导入GSL 4.1.0](https://i-blog.csdnimg.cn/direct/c61ffae4304b4396bddaf6c49dfb4367.png)