目录
一、Spark简介
1.1、Spark是什么
1.2、Spark的特点
1.3、Spark生态系统
1.4、Spark Core的组件
1.5、Spark的安装流程
1.5.1、基础环境,安装Linux系统、Java环境和Hadoop环境
1.5.2、下载Spark文件并解压缩
1.5.3、编辑profile
1.5.4、Spark-shell运行
二、Spark集群搭建
2.1、Spark部署模式
2.2、为什么选择Spark On YARN
2.3、Spark On YARN模式
2.4、启动Spark
三、Scala基础语法与方法函数
3.1、Scala变量定义及循环等基础语法
3.1.1、变量定义
3.1.2、If循环
3.1.3、For循环
3.1.4、Do while循环
3.2、集合的可变与不可变
3.2.1、不可变集合的基本语法
3.2.2、可变集合的基本语法
3.3、数组的可变和不可变
3.3.1、不可变数组基本语法
3.3.2、可变数组的基本语法
3.4、列表的可变和不可变
3.4.1、不可变List基本语法
3.4.2、可变List基本语法
3.5、元组
3.6、映射(Map)的可变和不可变
3.6.1、不可变Map基本语法
3.6.2、可变Map基本语法
四、面向对象
4.1、什么是面向对象
4.2、什么是类
4.3、什么是对象
4.4、类和对象的基本结构
4.5、构造器
4.6、样例类和样例对象
五、Spark RDD编程
5.1、RDD转换操作
5.2、RDD行动操作
5.3、RDD分区
5.4、RDD缓存(持久化)
5.5、RDD键值对的操作和读写方法
5.6、实验
六、Spark SQL
6.1、什么是DataFrame
6.2、DataFrame、DataSet和RDD之间的转换
6.2.1、从RDD到DataFrame
6.2.2、从DataFrame到RDD
一、Spark简介
1.1、Spark是什么
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎
1.2、Spark的特点
1、运行速度快:支持在内存中对数据进行迭代计算
2、易用性好:支持Scala、Java、Python等语言的编写,语法简洁
3、通用性强:Spark生态圈包含丰富组件
4、随处运行:Spark具有很强的适应性,可以访问不同的数据源
1.3、Spark生态系统
Spark生态圈以Spark Core为核心,从HDFS、Amazon S3和HBase等读取数据,以MESOS、YARN和自身携带的Standalone为资源管理器调度Job完成应用程序的计算。应用程序来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming实时处理应用、SparkSQL查询、MLlib机器学习、GraphX图处理等等。

1.4、Spark Core的组件
Spark Core是Spark框架最核心的部分,实现了Spark的基本功能,包括任务调度、内存管理、错误恢复与存储系统交互模块。
1)提供了有向无环图(DAG)的分布式并行计算框架,并提供了Cache机制来支持多次迭代计算或者数据共享,大大减少了迭代计算之间读取数据的开销。
2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可根据“血统”进行重建,保证高容错性。
3)移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
1.5、Spark的安装流程
1.5.1、基础环境,安装Linux系统、Java环境和Hadoop环境
1.5.2、下载Spark文件并解压缩
tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz
1.5.3、编辑profile
vim /etc/profile追加spark配置内容,注意不是覆盖
export SPARK_HOME=/home/spark/spark-3.0.3-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin最后要刷新配置
source /etc/profile1.5.4、Spark-shell运行
启动Spark Shell成功后在输出信息的末尾可以看到“Scala>”的命令提示符号
使用命令“ :quit” 退出Spark Shell,也可以使用“ Ctrl + D”组合键,退出Spark Shell
二、Spark集群搭建
2.1、Spark部署模式
1)单机模式:Local模式:Spark单机运行
2)伪分布式模式:Standalone模式:使用Spark自带的简单集群管理器
3)分布式模式:Spark On YARN模式:使用YARN作为集群管理器
Spark On Mesos模式:使用Mesos作为集群管理器
2.2、为什么选择Spark On YARN
Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。
2.3、Spark On YARN模式
Spark On YARN模式有client和cluster两种模式,主要区别在于:Driver 程序的运行节点不同
client:Driver程序运行在客户端,适用于交互、调试、希望立即看到运行的输出结果。
cluster:Driver程序运行在由RM(ResourceManager)启动的AM(AplicationMaster)上,适用于生产环境。
2.4、启动Spark
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/home/spark/spark-3.0.3-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.3.jar三、Scala基础语法与方法函数
3.1、Scala变量定义及循环等基础语法
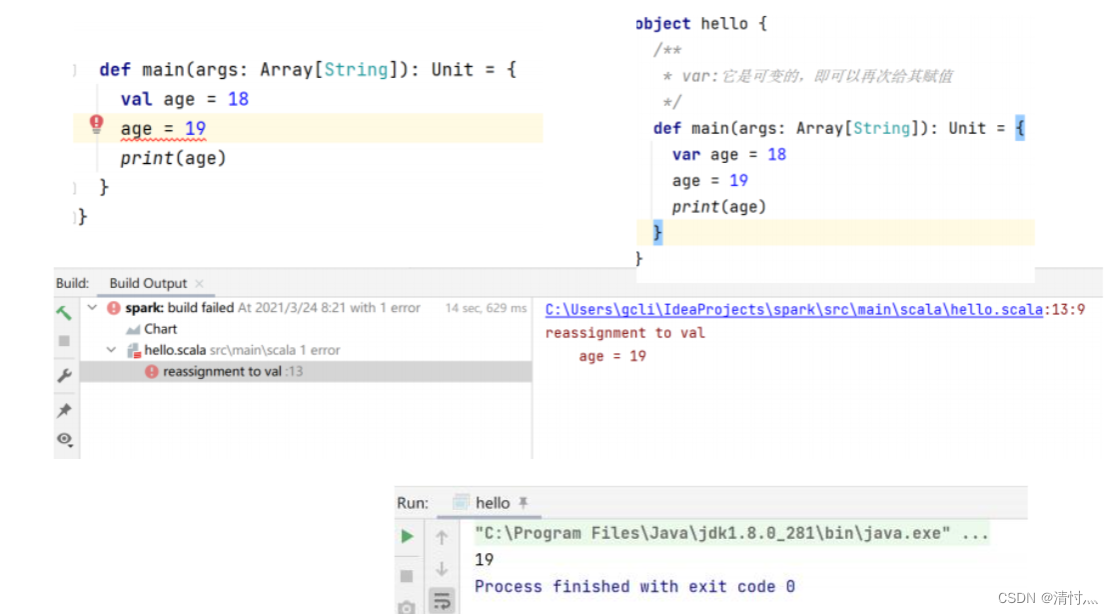
3.1.1、变量定义
3.1.2、If循环
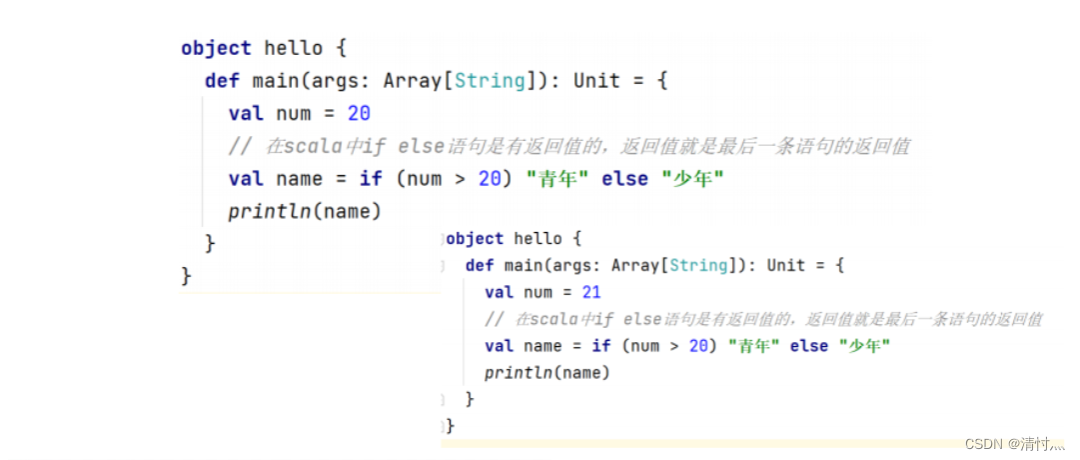
3.1.3、For循环

3.1.4、Do while循环

3.2、集合的可变与不可变
可变集合:可以在适当的地方被更新或扩展。这意味着可以修改,移除一个集合的元素,简单来说,就是这个集合本身可以动态变化
不可变集合:相比之下,永远不会改变。不过仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。简单来说,就是这个集合本身不能动态变化。
3.2.1、不可变集合的基本语法
var/val 变量名 = Set[类型]()
var/val 变量名 = Set(元素1, 元素2, 元素3,..)3.2.2、可变集合的基本语法
可变集指的是元素,长度都可变,它的创建方式和不可变集的创建方法一致,不过需要先导入可变集合类
3.3、数组的可变和不可变
3.3.1、不可变数组基本语法
var/val 变量名 = new Array[元素类型](数组长度)
var/val 变量名 = Array(元素1,元素2,...)
3.3.2、可变数组的基本语法
var/val 变量名 = new ArrayBuffer[元素类型](数组长度)
var/val 变量名 = ArrayBuffer(元素1,元素2,...)3.4、列表的可变和不可变
列表的元素、长度是不可变的
3.4.1、不可变List基本语法
val/var 变量名 = List(元素1,元素2,元素3,...)3.4.2、可变List基本语法
val/var 变量名 = ListBuffer[数据类型]()
val/var 变量名 = ListBuffer(元素1,元素2,元素3,..)3.5、元组
val/var 元组名 = (元素 1, 元素 2, 元素 3....)
val/var 元组名 = 元素 1 -> 元素 23.6、映射(Map)的可变和不可变
3.6.1、不可变Map基本语法
val/var map = Map(键->值, 键->值, 键->值...)
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)3.6.2、可变Map基本语法
定义语法与不可变 Map 一致, 不过需要先手动导包: import scala.collection.mutable.Map
四、面向对象
4.1、什么是面向对象
面向对象是一种编程思想,它是基于面向过程的,是以对象即类的实例为基础完成编程
4.2、什么是类
类是属性和行为的集合体,是一个抽象的概念
4.3、什么是对象
对象是类的具体实例
4.4、类和对象的基本结构
创建类语法:class 类名 {属性和行为} 注意:如果类是空的、没有任何成员可省略{}
创建对象语法:val 对象名 = new 类()
4.5、构造器
当创建对象的时候,会自动调用类的构造器。之前使用的都是默认构造器。除了定义主构造器外,还可以根据需要来定义辅助构造器。把除了主构造器之外的构造器称为辅助构造器
分类:1、主构造器。2、辅助构造器
4.6、样例类和样例对象
样例类:在Scala中,样例类是一种特殊类,一般是用于保存数据的,在并发编程以及Spark、Flink这些框架中都会经常使用它。
样例对象:在Scala中,用case修饰的单例对象就叫样例对象,而且它没有主构造器
五、Spark RDD编程
5.1、RDD转换操作
filter(func):筛选出满足函数func的元素,并返回一个新的数据集
map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
flatMap(func):与map()相似,但每个输入元素都可以映射到0或多个输出结果
groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K,Iterable)形式的数据集
reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中每个值是每个key传递到函数func中进行聚合后的结果
5.2、RDD行动操作
count():返回数据集中的元素个数
collect():以数组的形式返回数据集中的所有元素
first():返回数据集中的第一个元素
take(n):以数组的形式返回数据集中的前n个元素
reduce(func):通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
foreach(func):将数据集中的每个元素传递到函数func中运行

5.3、RDD分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同节点上
5.4、RDD缓存(持久化)
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价很大,迭代计算经常需要多次重复使用同一组数据。
缓存的意义:第二次动作操作时,只需要去使用第一次动作操作时缓存起来的值,避免重复计算
5.5、RDD键值对的操作和读写方法
1)键值对RDD的创建
val pairRDD = lines.flatMap(line => line.split("")).map(word => (word, 1))pairRDD.foreach(println)2)从文件中读取数据创建RDD
val textFile = sc.textFile(".....")
5.6、实验
1、有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数)
2、根据key值的最后一位数字,写到不同的文件
package com.qst.rdd import org.apache.spark.{Partitioner, SparkConf, SparkContext} //自定义分区类,需要继承org.apache.spark.Partitioner类 class MyPartitioner(numParts: Int) extends Partitioner { //覆盖分区数 override def numPartitions: Int = numParts //覆盖分区号获取函数 override def getPartition(key: Any): Int = { key.toString.toInt % 10 } } object MyPartitioner { def main(args: Array[String]) { val conf = new SparkConf().setAppName("persistDemo") val sc = new SparkContext(conf) // 模拟5个分区的数据 val data = sc.parallelize(1 to 10, 5) // 将每个元素转化为 (元素, 1) 的形式 data.map((_, 1)) // MyPartitioner的构造函数需要传入分区数,这里传入的是10,将原本的5个分区转变为10个分区 .partitionBy(new MyPartitioner(10)) // 对集合中的每个元组取第一个元素进行映射操作,返回一个包含映射结果的新集合。 // 也就是只保留元素,去除分区前加的1 .map(_._1) // 使用saveAsTextFile方法将结果保存到HDFS中。 // Spark 会自动将数据写到多个文件中,每个文件对应一个分区。 .saveAsTextFile("hdfs://192.168.74.80:9000/output6") sc.stop() } }
六、Spark SQL
6.1、什么是DataFrame
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema
6.2、DataFrame、DataSet和RDD之间的转换
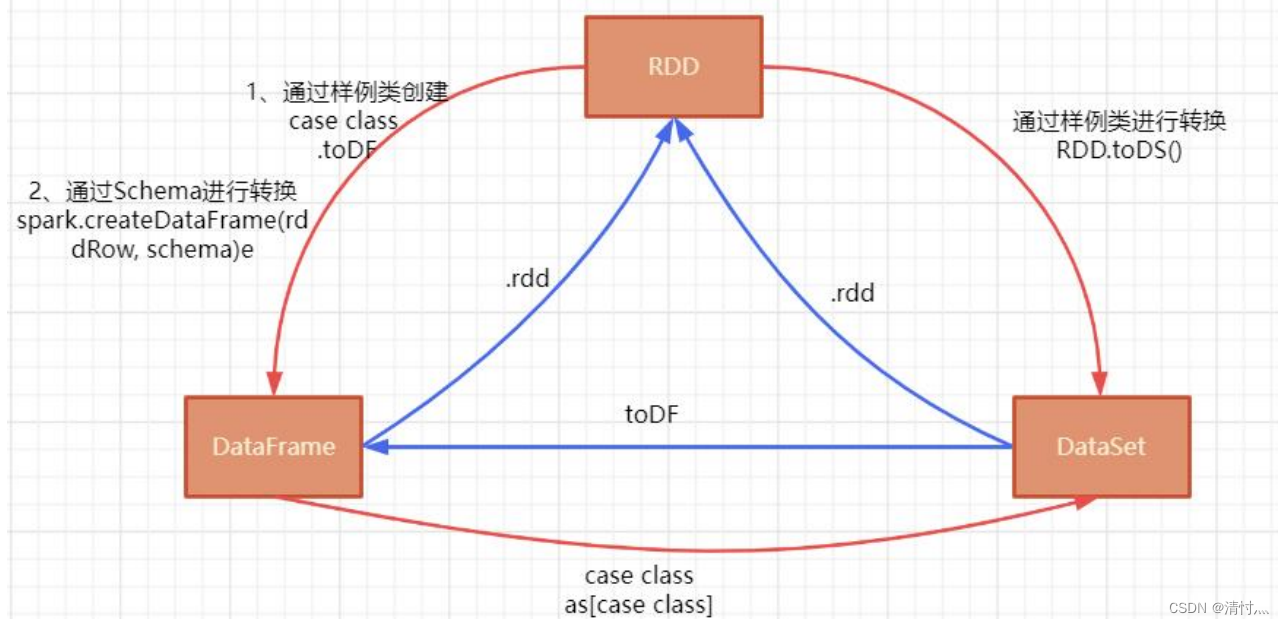
6.2.1、从RDD到DataFrame
object SparkSQLDemo03 {
// 样例类
case class Person(id: Int, name: String, age: Int)
def main(args: Array[String]): Unit = {
// 准备工作:创建 SparkSession
val spark = SparkSession.builder().appName(this.getClass.getName).master("local[*]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
// 1. 通过样例类进行转换
val linesRDD = sc.textFile("file/person.txt")
// 1.1. RDD[String] 变为 RDD[Person]
课程内容页
val personRDD: RDD[Person] = linesRDD.map(x => {
val arr = x.split(",")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
import spark.implicits._ // 隐式转换
// 1.2. RDD+样例类 => DataFrame
val personDF: DataFrame = personRDD.toDF()
val personDS: Dataset[Person] = personRDD.toDS()
personDF.show()
personDS.show()
// 关闭
spark.stop()
}
}6.2.2、从DataFrame到RDD
val rdd = pDF.rdd
println(rdd)
println(rdd.collect())
// 关闭
spark.stop()
}
}