目录
创建简单使用
直接内存vs堆内存
池化vs非池化
组成
常用写入方法
扩容
读取
retain&release
slice
其他拷贝方式 duplicate& copy&CompositeByteBuf
Unpooled
netty中用于进行信息承载和交流的类叫做ByteBuf,从名字可以看出这是Byte的缓存区,是对字节数据的封装
粗略地可以从2个维度进行区分:内存分布和内存回收
-
按照内存分布维度:堆内存字节缓冲区、直接内存字节缓冲区
-
按照内存回收维度:基于对象池,普通缓冲区
创建简单使用
public class test1 {
public static void main(String[] args) {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
log(buffer);
}
private static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(NEWLINE);
appendPrettyHexDump(buf, buffer);
System.out.println(buf.toString());
}
}上面代码创建了一个默认的 ByteBuf(池化基于直接内存的 ByteBuf),初始容量是 10
输出:
read index:0 write index:0 capacity:10直接内存vs堆内存
可以使用下面的代码来创建池化基于堆的 ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10);也可以使用下面的代码来创建池化基于直接内存的 ByteBuf(默认的)
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10);- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
池化vs非池化
池化的最大意义在于可以重用 ByteBuf,优点有
- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
-Dio.netty.allocator.type={unpooled|pooled} 
- 4.1 以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现
- 4.1 之前,池化功能还不成熟,默认是非池化实现
组成
ByteBuf 由四部分组成

最开始读写指针都在 0 位置
- capacity:它表示ByteBuf的容量大小,即ByteBuf最多能够容纳多少字节数据。
- readerIndex和writerIndex:它们表示ByteBuf中可读和可写的字节索引位置。
- maxCapacity:它表示ByteBuf的最大容量大小,即ByteBuf能够扩容的最大限制。
常用写入方法
| 方法签名 | 含义 | 备注 |
|---|---|---|
| writeBoolean(boolean value) | 写入 boolean 值 | 用一字节 01|00 代表 true|false |
| writeByte(int value) | 写入 byte 值 | |
| writeShort(int value) | 写入 short 值 | |
| writeInt(int value) | 写入 int 值 | Big Endian,即 0x250,写入后 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endian,即 0x250,写入后 50 02 00 00 |
| writeLong(long value) | 写入 long 值 | |
| writeChar(int value) | 写入 char 值 | |
| writeFloat(float value) | 写入 float 值 | |
| writeDouble(double value) | 写入 double 值 | |
| writeBytes(ByteBuf src) | 写入 netty 的 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 nio 的 ByteBuffer | |
| int writeCharSequence(CharSequence sequence, Charset charset) | 写入字符串 |
注意
- 这些方法的未指明返回值的,其返回值都是 ByteBuf,意味着可以链式调用
- 网络传输,默认习惯是 Big Endian
先写入 4 个字节:
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
buffer.writeBytes(new byte[]{1, 2, 3, 4});
log(buffer);read index:0 write index:4 capacity:10
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 |.... |
+--------+-------------------------------------------------+----------------+再写进一个int整数,也就是四个字节
buffer.writeInt(5);read index:0 write index:8 capacity:10
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 |........ |
+--------+-------------------------------------------------+----------------+还有一类方法是 set 开头的一系列方法,也可以写入数据,但不会改变写指针位置。
buffer.setByte(4,1); 
扩容
再写进一个整数时,容量就不够了(初始容量为10),这个时候就会引发扩容
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
buffer.writeBytes(new byte[]{1, 2, 3, 4});
buffer.writeInt(5);
log(buffer);
buffer.writeInt(6);
log(buffer); 具体的扩容规则:
具体的扩容规则:
- 如果写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
- 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 2^10=1024(2^9=512 已经不够了)
- 扩容不能超过 max capacity 会报错
读取
例如读了 4 次,每次一个字节
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
buffer.writeBytes(new byte[]{1, 2, 3, 4});
buffer.writeInt(5);
log(buffer);
buffer.writeInt(6);
log(buffer);
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
log(buffer);读过的内容,就属于废弃部分了,再读只能读那些尚未读取的部分

如果需要重复读取 int 整数 5,怎么办?
可以在 read 前先做个标记 mark
buffer.markReaderIndex();
System.out.println(buffer.readInt());
log(buffer); 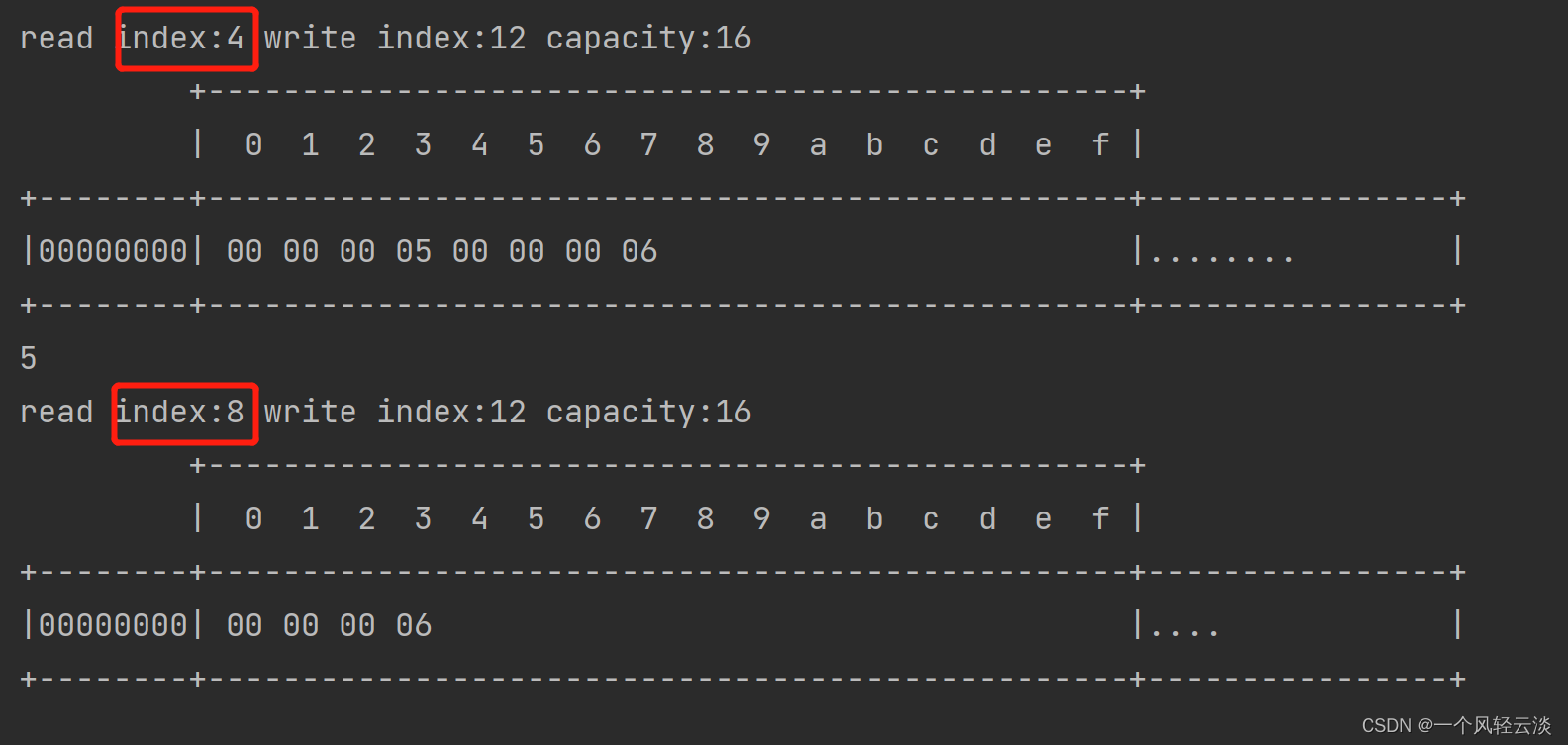
这时要重复读取的话,重置到标记位置 reset
buffer.resetReaderIndex();
log(buffer);
System.out.println(buffer.readInt());
log(buffer);
还有种办法是采用 get 开头的一系列方法,这些方法不会改变 read index
retain&release
由于堆外内存并不直接控制于JVM,因此只能等到full GC的时候才能垃圾回收
由于 Netty 中有堆外内存的 ByteBuf 实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。
- UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可
- UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存
- PooledByteBuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存
回收内存的源码实现,请关注下面方法的不同实现
protected abstract void deallocate()
Netty 这里采用了引用计数法来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
- 每个 ByteBuf 对象的初始计数为 1
- 调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
- 调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
- 当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
谁来负责 release 呢?
不是我们想象的(一般情况下)
ByteBuf buf = ...
try {
...
} finally {
buf.release();
}请思考,因为 pipeline 的存在,一般需要将 ByteBuf 传递给下一个 ChannelHandler,如果在 finally 中 release 了,就失去了传递性(当然,如果在这个 ChannelHandler 内这个 ByteBuf 已完成了它的使命,那么便无须再传递)
基本规则是,谁是最后使用者,谁负责 release,详细分析如下
- 起点,对于 NIO 实现来讲,在 io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read 方法中首次创建 ByteBuf 放入 pipeline(line 163 pipeline.fireChannelRead(byteBuf))
- 入站 ByteBuf 处理原则
- 对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
- 将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
- 如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
- 注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
- 假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
- 出站 ByteBuf 处理原则
- 出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release
- 异常处理原则
- 有时候不清楚 ByteBuf 被引用了多少次,但又必须彻底释放,可以循环调用 release 直到返回 true
TailContext 释放未处理消息逻辑
// io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage(java.lang.Object)
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug(
"Discarded inbound message {} that reached at the tail of the pipeline. " +
"Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}具体代码
// io.netty.util.ReferenceCountUtil#release(java.lang.Object)
public static boolean release(Object msg) {
if (msg instanceof ReferenceCounted) {
return ((ReferenceCounted) msg).release();
}
return false;
}slice
【零拷贝】的体现之一,对原始 ByteBuf 进行切片成多个 ByteBuf,切片后的 ByteBuf 并没有发生内存复制,还是使用原始 ByteBuf 的内存,切片后的 ByteBuf 维护独立的 read,write 指针

原始 ByteBuf 进行一些初始操作
ByteBuf origin = ByteBufAllocator.DEFAULT.buffer(10);
origin.writeBytes(new byte[]{1, 2, 3, 4});
origin.readByte();
System.out.println(ByteBufUtil.prettyHexDump(origin)); +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 02 03 04 |... |
+--------+-------------------------------------------------+----------------+这时调用 slice 进行切片,无参 slice 是从原始 ByteBuf 的 read index 到 write index 之间的内容进行切片,切片后的 max capacity 被固定为这个区间的大小,因此不能追加 write
ByteBuf slice = origin.slice();
System.out.println(ByteBufUtil.prettyHexDump(slice));
// slice.writeByte(5); 如果执行,会报 IndexOutOfBoundsException 异常 +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 02 03 04 |... |
+--------+-------------------------------------------------+----------------+如果原始 ByteBuf 再次读操作(又读了一个字节)
origin.readByte();
System.out.println(ByteBufUtil.prettyHexDump(origin));这时的 slice 不受影响,因为它有独立的读写指针
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 02 03 04 |... |
+--------+-------------------------------------------------+----------------+如果 slice 的内容发生了更改
slice.setByte(2, 5);
System.out.println(ByteBufUtil.prettyHexDump(slice)); +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 02 03 05 |... |
+--------+-------------------------------------------------+----------------+这时,原始 ByteBuf 也会受影响,因为底层都是同一块内存
System.out.println(ByteBufUtil.prettyHexDump(origin)); +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 03 05 |.. |
+--------+-------------------------------------------------+----------------+其他拷贝方式 duplicate& copy&CompositeByteBuf
duplicate
【零拷贝】的体现之一,就好比截取了原始 ByteBuf 所有内容,并且没有 max capacity 的限制,也是与原始 ByteBuf 使用同一块底层内存,只是读写指针是独立的

copy
会将底层内存数据进行深拷贝,因此无论读写,都与原始 ByteBuf 无关
CompositeByteBuf
【零拷贝】的体现之一,可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免拷贝
有两个 ByteBuf 如下
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
System.out.println(ByteBufUtil.prettyHexDump(buf1));
System.out.println(ByteBufUtil.prettyHexDump(buf2)); +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 |..... |
+--------+-------------------------------------------------+----------------+
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 06 07 08 09 0a |..... |
+--------+-------------------------------------------------+----------------+现在需要一个新的 ByteBuf,内容来自于刚才的 buf1 和 buf2,如何实现?
方法1:
ByteBuf buf3 = ByteBufAllocator.DEFAULT
.buffer(buf1.readableBytes()+buf2.readableBytes());
buf3.writeBytes(buf1);
buf3.writeBytes(buf2);
System.out.println(ByteBufUtil.prettyHexDump(buf3));结果
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 06 07 08 09 0a |.......... |
+--------+-------------------------------------------------+----------------+这种方法好不好?
回答:是不太好,因为进行了数据的内存复制操作
方法2:
CompositeByteBuf buf3 = ByteBufAllocator.DEFAULT.compositeBuffer();
// true 表示增加新的 ByteBuf 自动递增 write index, 否则 write index 会始终为 0
buf3.addComponents(true, buf1, buf2);结果是一样的
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 06 07 08 09 0a |.......... |
+--------+-------------------------------------------------+----------------+CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。
- 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制
- 缺点,复杂了很多,多次操作会带来性能的损耗
Unpooled
Unpooled 是一个工具类,类如其名,提供了非池化的 ByteBuf 创建、组合、复制等操作
这里仅介绍其跟【零拷贝】相关的 wrappedBuffer 方法,可以用来包装 ByteBuf
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
// 当包装 ByteBuf 个数超过一个时, 底层使用了 CompositeByteBuf
ByteBuf buf3 = Unpooled.wrappedBuffer(buf1, buf2);
System.out.println(ByteBufUtil.prettyHexDump(buf3)); +-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 06 07 08 09 0a |.......... |
+--------+-------------------------------------------------+----------------+也可以用来包装普通字节数组,底层也不会有拷贝操作
ByteBuf buf4 = Unpooled.wrappedBuffer(new byte[]{1, 2, 3}, new byte[]{4, 5, 6});
System.out.println(buf4.getClass());
System.out.println(ByteBufUtil.prettyHexDump(buf4));class io.netty.buffer.CompositeByteBuf
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 06 |...... |
+--------+-------------------------------------------------+----------------+