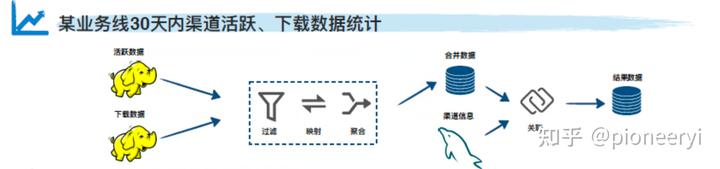
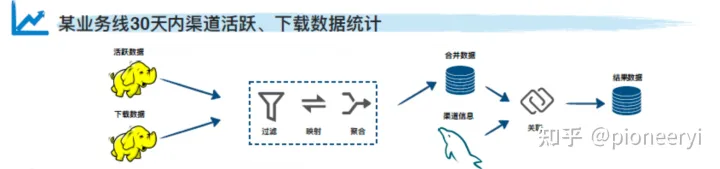
MixQuery系列(一):多数据源混合查询引擎调研
news2026/2/12 8:19:38


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/635966.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
如何兼顾性能+实时性处理缓冲数据?
我们经常会遇到这样的数据处理应用场景:我们利用一个组件实时收集外部交付给它的数据,并由它转发给一个外部处理程序进行处理。考虑到性能,它会将数据存储在本地缓冲区,等累积到指定的数量后打包发送;考虑到实时性&…

Golang每日一练(leetDay0094) H 指数 I\II H Index
目录
274. H 指数 H Index 🌟🌟
275. H 指数 II H Index ii 🌟🌟
🌟 每日一练刷题专栏 🌟
Rust每日一练 专栏
Golang每日一练 专栏
Python每日一练 专栏
C/C每日一练 专栏
Java每日一练 专栏 27…
sqlserver数据库学习感悟(1)----关于group by
以下含编写过程,如果嫌啰嗦,最后有总结哒!
例题:有heat表和eatables两张表,分别为:
eatables heat:protein(蛋白质),fat(脂肪)&…

软考A计划-系统架构师-学习笔记-第五弹
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列
👉关于作者 专注于Android/Unity和各种游戏开发技巧ÿ…
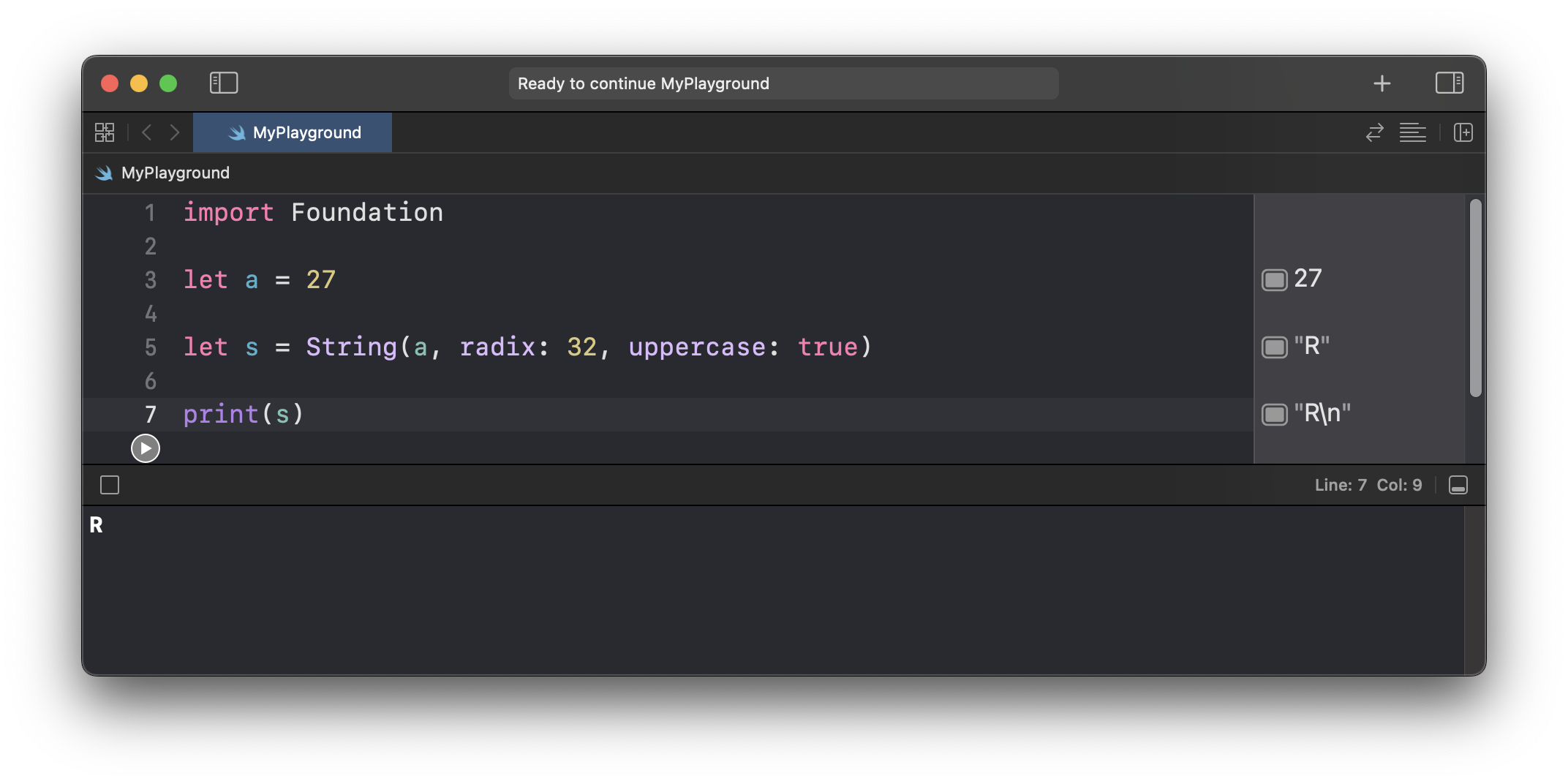
Swift——如何将某一进制的数字按另一种进制输出(比如十进制输出打印成十六进制,八进制打印输出成二进制)
最近由于需要阅读比较老的文档,老文档里内存地址是用八进制而不是十六进制,所以需要写一个小工具,用来转换进制进制。虽然自带的计算器可以,但是数量一多比较麻烦。 一开始我想费劲吧啦写十二个转换函数,虽然有些函数可…

chatgpt赋能python:Python字符串:如何定义一个空字符串
Python字符串:如何定义一个空字符串
在Python中,字符串是一种常见的数据类型,通常用于存储文本信息。定义一个空字符串在Python中非常简单,本文将介绍如何定义一个空字符串以及在Python中使用字符串的一些常见操作。
定义一个空…
基于Java+SpringBoot+Vue前后端分离摄影分享网站平台系统
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…

python课程设计:实现一个飞行训练成绩管理微信息系统,对飞行员的某门飞行课目成绩进行质量评定
一、编程题目 在日常飞行训练中,飞行训练成绩是 飞行员进行综合等级评定的重要依据。
假设飞行训练团在某次飞行训练结束后,要对飞行员的某门飞行课目成绩进行质量评定。
请编程实现一个飞行训练成绩管理系统。要求完成以下功能:
1录入成绩
2计算平均分
3计算最高分
4查…

零入门kubernetes网络实战-35->vxlan简介以及原理介绍(vxlan报文结构介绍)
《零入门kubernetes网络实战》视频专栏地址
https://www.ixigua.com/7193641905282875942
本篇文章视频地址(稍后上传) 本篇文章开始介绍vxlan虚拟设备。
主要介绍vxlan的协议报文结构, 1、总结
主要涉及到以下方面:
overlay跟vxlan的关系如何理解v…
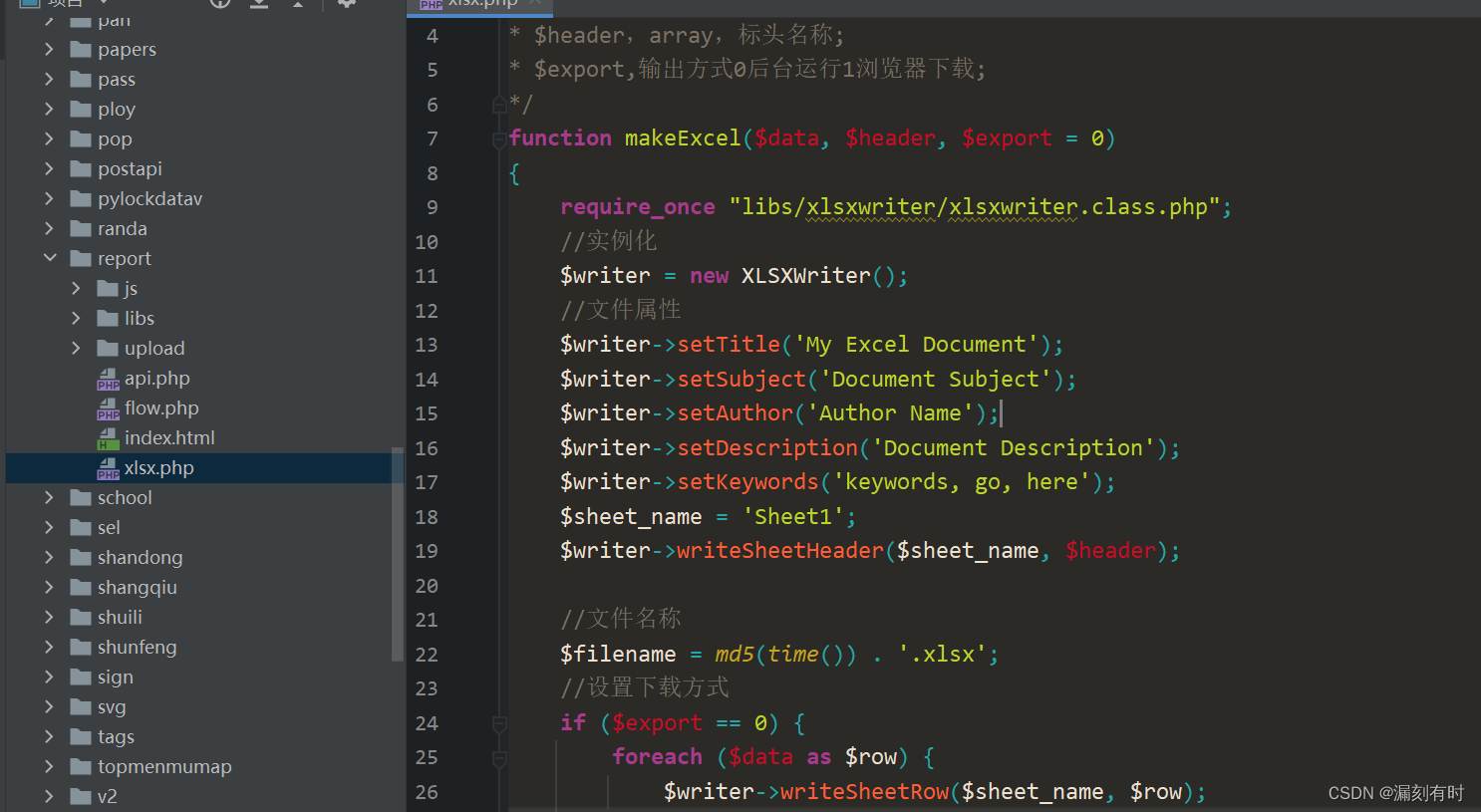
Excel电子表格的PHP类库:PHP_XLSXWriter(大数据量报表、后台运行、浏览器下载)
Excel电子表格的PHP类库:PHP_XLSXWriter 一、PHP_XLSXWriter与PHPExcel的区别二、PHP_XLSXWriter的使用1.使用步骤2.后台下载3.浏览器下载4.封装函数 PHP_XLSXWriter 是一个用于生成 Microsoft Excel 2007 xlsx 文件的 PHP 库。XLSX 是一种用基于 XML 的开放式文件标…
chatgpt赋能python:Python多行缩进——提高代码可读性和效率的关键
Python多行缩进——提高代码可读性和效率的关键
众所周知,Python是一种缩进敏感的编程语言,它鼓励程序员使用缩进来表示代码块,而非传统的大括号或关键字。在Python中,缩进通过使用空格或制表符来实现,而且空格和制表…
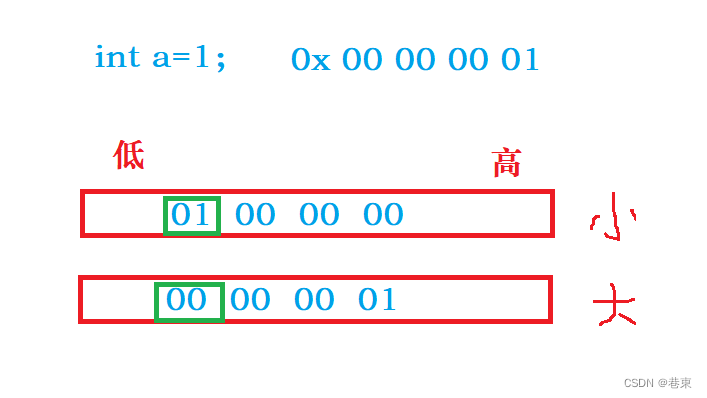
深度剖析整形数据在内存中的存储
📕博主介绍:目前大一正在学习c语言,数据结构,计算机网络。 c语言学习,是为了更好的学习其他的编程语言,C语言是母体语言,是人机交互接近底层的桥梁。 本章来学习数据的存储。 让我们开启c语言学…
Linux命令(31)之watch
Linux命令之watch
1.watch介绍
linux命令watch是周期性的用来执行某命令,并把某命令执行结果输出到屏幕上。使用watch命令,可以周期性的监测并输出某命令的执行结果到屏幕上,省得手动一遍一遍运行某命令,提高工作效率。
2.watc…
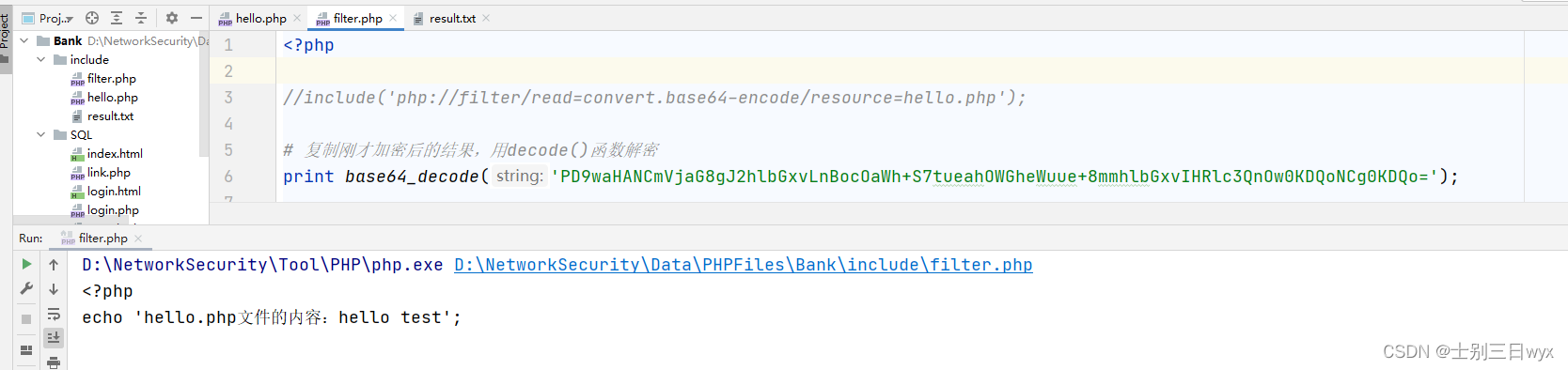
PHP伪协议filter详解,php://filter协议过滤器
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:对网络安全感兴趣的小伙伴可以关注专栏《网络安全入门到精通》 php://filter 一、访问数据流二、过滤数据流三、多…
![[第一章 web入门]SQL注入-2](https://img-blog.csdnimg.cn/img_convert/667a4d09cd5649568bec4b0b25a52ebb.png)
[第一章 web入门]SQL注入-2
拿到题目后看提示,要自主访问两个页面 访问login.php后,是一个登录界面,直接测试注入类型 第一件事还是输入常用账户名admin,密码随便输入 回显账号或者密码错误 这种登录界面一般都是字符型注入,所以测试一下闭合符&a…

【力扣刷题 | 第七天】
前言: 今天我们将会进入栈与队列的刷题篇章,二者都是经典的数据结构,熟练的掌握栈与队列实现可以巧妙的解决有些问题。 232. 用栈实现队列 - 力扣(LeetCode)
请你仅使用两个栈实现先入先出队列。队列应当支持一般队…

野火Renesas R4M2 UDS诊断bootloader 升级MCU
基于can总线的UDS软件升级
最近学习UDS诊断协议(ISO14229),是一项国际标准,为汽车电子系统中的诊断通信定义了统一的协议和服务。它规定了与诊断相关的服务需求,并没有设计通信机制。ISO14229仅对应用层和会话层做出了…
从零开始Vue项目中使用MapboxGL开发三维地图教程(一)MapboxGL介绍以及前期vue项目的搭建
MapboxGL介绍以及前期vue项目的搭建 1、Mapbox-gl简介2、搭建vue项目2.1、创建vue项目2.2、注册mapbox官网2.3、mapbox-gl入门案例 3、Mapbox-gl地图主要配置参数说明 1、Mapbox-gl简介 Mapbox-gl是一个开源、基于webgl技术的前端地图类库。 地图数据渲染和可视化这块我们经常用…
chatgpt赋能python:如何培训Python?-从入门到专业化
如何培训Python?- 从入门到专业化
Python是一种高级编程语言,已被广泛应用于各种领域以及各种应用程序的开发中。如果你也想成为一名Python开发人员,有以下几种培训方法帮助你一步步实现你的目标。
1.自学Python
学习Python的最简单方法是…