目录
前言
课题背景与意义
课题实现技术思路
目标检测
算法检测
算法实现
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯安全帽佩戴识别系统
课题背景与意义
佩截安全帽是电网工作人员进行作业时非常重要的防护手段之一。在日常线路巡检、设备维护以及电网基建等情况下,由于长期工作以及作业人员的蔬忽,时常出现安全帽佩戴不规范或不佩戴的现象间接引超重大安全事故,所以有必要进行作业人员安全幅佩戴情况检测。
安全幅佩戴情况监测大多数采用人工检测方式,即监测人员通过视凝监控设备实时监测作业现场人员安全增佩载情况。但由于临测人员的长时间工作,可导效检测效率与检测精度的降低。结合计算机视觉中目称检测技术,利用智能算法模型进行安全幅配检测,能够克服人工检测的弊端。
课题实现技术思路
目标检测
运动目标检测:运动目标检测就是在一系列的运动视频图像中剔除背景,得到所需要的目标。运动目标检测技术在现今以及未来社会各个领域都有着很好的应用前景。常用的运动目标检测方法包含以下几种:背景差分法、帧间差分法和光流法等;这里我们利用背景差分法。
背景差分法的原理很简单,利用视频终像构建一个背景模型,接着把视频帧图像和构建好的模型进行差分运算,通过运算的结果将图像的前后景部分区分开来。
对于背景的建模用公式表示为:
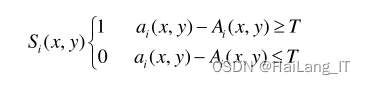
图像目标检测方法:就是在给定的一张终像上,找到多个目标的位置和分类。在计算机眼中的图像仅仅是一堆像素数字的堆叠,让它检测和识别图像里的物体是比较困难的事情。我们利用传统的目标检测方法或基于深度学习的目标检测方法对图像进行识别。这里以传统的目标检测方法为例。
传统的目标检测步骤:
(1)选取候选区域:在进行检测之前,首先要对图像中目标的大概位置进行定位。
(2)特征提取:在选取到合适的候选区域之后,就需要从这些区域中提取出一些比较特殊的视觉特征使用。
(3)分类器分类:将提取到的视觉特征,放入训练好的分类器中进行分类,就可以知道该候选区域是否有待检测的目标。
算法检测
为了实现人体目标检测,训练人体关键点检验,我们利用人体关键点检验算法,来对视频图像进行检测,得到人体各个关键点的位置。为了训练安全帽和人体框模型,我们采用yolo算法。
人体关键点检测算法:
是一种被广泛应用于人体二维姿态估计、人体运动姿态估计等领域的算法,算法的主要思想就是检测人体关键点的位置,或者称之为人体骨骼关节部位位置。
算法过程:
输入图片先使用 VGG-19 前十层分析,得到一个特征图F,将该特征图F输入到前馈网络的第一阶段,上面分支产生一系列检测置信图S=p(F),下面分支产生一系列亲和场L=o(F),p和φ是第一阶段使用的 CNN 网络。接着,把第1阶段得到的置信度图S和亲合场L以及开始得到的特征图F一起输入第2个阶段进行预测,之后每阶段都如此进行得到更好结果。
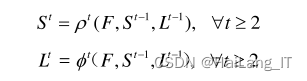
效果图:

YOLO 算法:
就是将目标检测的单独组件集成到了一个单一的神经网络中,把目标检测问题看成一个回归问题,通过整张图像的特征直接预测每个边界框位置和所有目标的分类。因此,在保持比较好的检测效果的同时达到实时的速度。
预测边界框准确程度的公式:
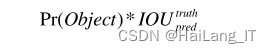
算法实现
通过人体关键点检测、人体框检测和安全帽检测。将处理好的视频帧图像送入训练好的人体关键点检测中,检测得到人体各个关键点的位置;将处理好的视频帧图像送入训练好的人体框检测模型和安全帽检测模型YOLO3中,对视频帧图像进行检测得到安全帽和人体框的位置,判断是否佩戴安全帽。
YOLO3模型:
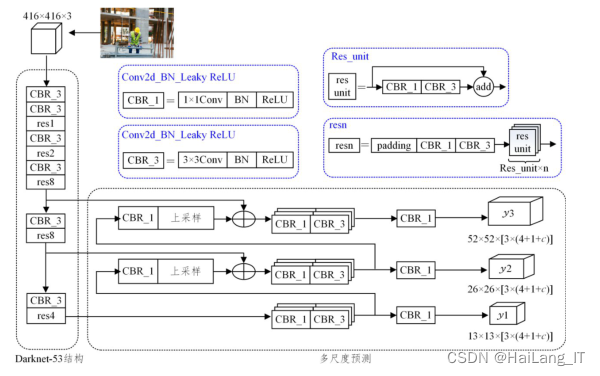
YOLOv3采用Daknet-53新的r网络做特征提取。Darknet-53网络结构由53个卷积层和5个max pooling层组成。同时,在每个卷积层后增加了Batch Normalization(BN)和Dropout操作,以防止过拟合。YOLOv3采用多尺度特征融合方法对多尺度特征图上的位置和类别进行预测,提高了目标检测的精度,在YOLOv3中,利用K-means聚类得到先验框的尺寸,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。最后,利用YOLOv3进行安全帽佩戴检测实验。
YOLOv3网络结构图:
🚀海浪学长的作品示例:




![[附源码]Python计算机毕业设计Django体育器材及场地管理系统](https://img-blog.csdnimg.cn/a2262a36449b4d21bab4d153eb15a4f1.png)