顾名思义,时间序列数据是一种随时间变化的数据类型。例如,24小时内的温度,一个月内各种产品的价格,一年中特定公司的股票价格。
去年,我们为一位客户进行了短暂的咨询工作,他正在构建一个主要基于时间序列预测的分析应用程序。诸如长期短期记忆网络(LSTM)之类的高级深度学习模型能够捕获时间序列数据中的模式,因此可用于对数据的未来趋势进行预测。在本文中,您将看到如何使用LSTM算法使用时间序列数据进行将来的预测。
相关视频:LSTM神经网络架构和工作原理及其在Python中的预测应用
LSTM神经网络架构和原理及其在Python中的预测应用
数据集和问题定义
让我们先导入所需的库,然后再导入数据集:
import matplotlib.pyplot as plt
让我们将数据集加载到我们的程序中 data.head()
输出:
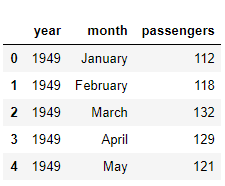
该数据集有三列:year,month,和passengers。passengers列包含指定月份旅行旅客的总数。让我们输出数据集的维度:
data.shape
输出:
(144, 3)
您可以看到数据集中有144行和3列,这意味着数据集包含12年的乘客旅行记录。
任务是根据前132个月来预测最近12个月内旅行的乘客人数。请记住,我们有144个月的记录,这意味着前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最近12个月的值进行评估。
让我们绘制每月乘客的出行频率。 接下来的脚本绘制了每月乘客人数的频率:
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(data['passengers'])输出:
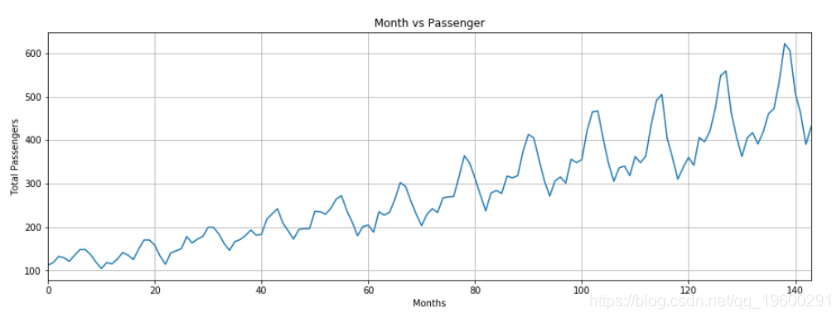
输出显示,多年来,乘飞机旅行的平均乘客人数有所增加。一年内旅行的乘客数量波动,这是有道理的,因为在暑假或寒假期间,旅行的乘客数量与一年中的其他部分相比有所增加。
数据预处理
数据集中的列类型为object,如以下代码所示:
data.columns
输出:
Index(['year', 'month', 'passengers'], dtype='object')
第一步是将passengers列的类型更改为float。
all_data = data['passengers'].values.astype(float)
现在,如果 输出all_datanumpy数组,则应该看到以下浮点类型值:
print(all_data)
前132条记录将用于训练模型,后12条记录将用作测试集。以下脚本将数据分为训练集和测试集。
test_data_size = 12
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
现在让我们输出测试和训练集的长度:
输出:
132
12
如果现在输出测试数据,您将看到它包含all_datanumpy数组中的最后12条记录:输出:
[417. 391.... 390. 432.]
我们的数据集目前尚未归一化。最初几年的乘客总数远少于后来几年的乘客总数。标准化数据以进行时间序列预测非常重要。以在一定范围内的最小值和最大值之间对数据进行归一化。我们将使用模块中的MinMaxScaler类sklearn.preprocessing来扩展数据。
以下代码 将最大值和最小值分别为-1和1进行归一化。
MinMaxScaler(feature_range=(-1, 1))
输出:
[[-0.96483516]
......
[0.33186813]
[0.13406593]
[0.32307692]]
您可以看到数据集值现在在-1和1之间。
在此重要的是要提到数据归一化仅应用于训练数据,而不应用于测试数据。如果对测试数据进行归一化处理,则某些信息可能会从训练集中 到测试集中。
最后的预处理步骤是将我们的训练数据转换为序列和相应的标签。
您可以使用任何序列长度,这取决于领域知识。但是,在我们的数据集中,使用12的序列长度很方便,因为我们有月度数据,一年中有12个月。如果我们有每日数据,则更好的序列长度应该是365,即一年中的天数。因此,我们将训练的输入序列长度设置为12。
接下来,我们将定义一个名为的函数create_inout_sequences。该函数将接受原始输入数据,并将返回一个元组列表。在每个元组中,第一个元素将包含与12个月内旅行的乘客数量相对应的12个项目的列表,第二个元组元素将包含一个项目,即在12 + 1个月内的乘客数量。
如果输出train_inout_seq列表的长度,您将看到它包含120个项目。这是因为尽管训练集包含132个元素,但是序列长度为12,这意味着第一个序列由前12个项目组成,第13个项目是第一个序列的标签。同样,第二个序列从第二个项目开始,到第13个项目结束,而第14个项目是第二个序列的标签,依此类推。
现在让我们输出train_inout_seq列表的前5个项目:
输出:
[(tensor([-0.9648, -0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066,
-0.8593, -0.9341, -1.0000, -0.9385]), tensor([-0.9516])),
(tensor([-0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593,
-0.9341, -1.0000, -0.9385, -0.9516]),
tensor([-0.9033])),
(tensor([-0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341,
-1.0000, -0.9385, -0.9516, -0.9033]), tensor([-0.8374])),
(tensor([-0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000,
-0.9385, -0.9516, -0.9033, -0.8374]), tensor([-0.8637])),
(tensor([-0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385,
-0.9516, -0.9033, -0.8374, -0.8637]), tensor([-0.9077]))]
您会看到每个项目都是一个元组,其中第一个元素由序列的12个项目组成,第二个元组元素包含相应的标签。
创建LSTM模型
我们已经对数据进行了预处理,现在是时候训练我们的模型了。我们将定义一个类LSTM,该类继承自nn.ModulePyTorch库的类。
让我总结一下以上代码。LSTM该类的构造函数接受三个参数:
input_size:对应于输入中的要素数量。尽管我们的序列长度为12,但每个月我们只有1个值,即乘客总数,因此输入大小为1。hidden_layer_size:指定隐藏层的数量以及每层中神经元的数量。我们将有一层100个神经元。output_size:输出中的项目数,由于我们要预测未来1个月的乘客人数,因此输出大小为1。
接下来,在构造函数中,我们创建变量hidden_layer_size,lstm,linear,和hidden_cell。LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。该hidden_cell变量包含先前的隐藏状态和单元状态。lstm和linear层变量用于创建LSTM和线性层。
在forward方法内部,将input_seq作为参数传递,该参数首先传递给lstm图层。lstm层的输出是当前时间步的隐藏状态和单元状态,以及输出。lstm图层的输出将传递到该linear图层。预计的乘客人数存储在predictions列表的最后一项中,并返回到调用函数。下一步是创建LSTM()类的对象,定义损失函数和优化器。由于我们在解决分类问题,
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size让我们输出模型:
输出:
LSTM(
(lstm): LSTM(1, 100)
(linear): Linear(in_features=100, out_features=1, bias=True)
)训练模型
我们将训练模型150个步长。
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq:
optimizer.zero_grad()输出:
epoch: 1 loss: 0.00517058
epoch: 26 loss: 0.00390285
epoch: 51 loss: 0.00473305
epoch: 76 loss: 0.00187001
epoch: 101 loss: 0.00000075
epoch: 126 loss: 0.00608046
epoch: 149 loss: 0.0004329932
由于默认情况下权重是在PyTorch神经网络中随机初始化的,因此您可能会获得不同的值。
做出预测
现在我们的模型已经训练完毕,我们可以开始进行预测了。
您可以将上述值与train_data_normalized数据列表的最后12个值进行比较。
该test_inputs项目将包含12个项目。在for循环内,这12个项目将用于对测试集中的第一个项目进行预测,即编号133。然后将预测值附加到test_inputs列表中。在第二次迭代中,最后12个项目将再次用作输入,并将进行新的预测,然后将其test_inputs再次添加到列表中。for由于测试集中有12个元素,因此该循环将执行12次。在循环末尾,test_inputs列表将包含24个项目。最后12个项目将是测试集的预测值。以下脚本用于进行预测:
model.eval()
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])如果输出test_inputs列表的长度,您将看到它包含24个项目。可以按以下方式输出最后12个预测项目:
需要再次提及的是,根据用于训练LSTM的权重,您可能会获得不同的值。
由于我们对训练数据集进行了归一化,因此预测值也进行了归一化。我们需要将归一化的预测值转换为实际的预测值。
print(actual_predictions)
现在让我们针对实际值绘制预测值。看下面的代码:
print(x)
在上面的脚本中,我们创建一个列表,其中包含最近12个月的数值。第一个月的索引值为0,因此最后一个月的索引值为143。
在下面的脚本中,我们将绘制144个月的乘客总数以及最近12个月的预计乘客数量。
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x,actual_predictions)
plt.show()
输出:
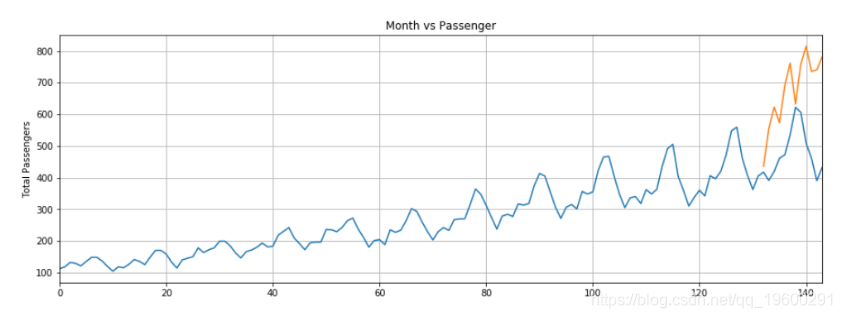
我们的LSTM所做的预测用橙色线表示。您可以看到我们的算法不太准确,但是它仍然能够捕获最近12个月内旅行的乘客总数的上升趋势以及波动。您可以尝试在LSTM层中使用更多的时期和更多的神经元,以查看是否可以获得更好的性能。
为了更好地查看输出,我们可以绘制最近12个月的实际和预测乘客数量,如下所示:
plt.plot(flight_data['passengers'][-train_window:])
plt.plot(x,actual_predictions)
plt.show()
输出:
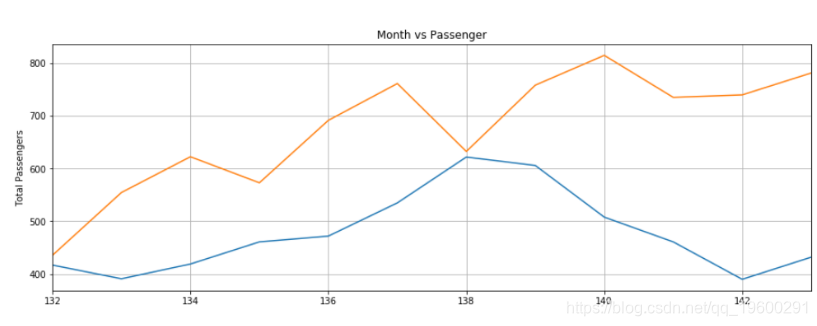
预测不是很准确,但是该算法能够捕获趋势,即未来几个月的乘客数量应高于前几个月,且偶尔会有波动。
结论
LSTM是解决序列问题最广泛使用的算法之一。在本文中,我们看到了如何通过LSTM使用时间序列数据进行未来的预测。






![[附源码]Python计算机毕业设计Django松林小区疫情防控信息管理系统](https://img-blog.csdnimg.cn/9752c7186f504ccda539b9fdd8bb603d.png)