机器学习笔记之受限玻尔兹曼机——推断任务[边缘概率]
- 引言
- 回顾:场景构建
- 推断任务——边缘概率求解
- 边缘概率与Softplus函数
引言
上一节介绍了受限玻尔兹曼机中随机变量节点的后验概率,本节将介绍随机变量结点的边缘概率。
回顾:场景构建
已知受限玻尔兹曼机示例表示如下:
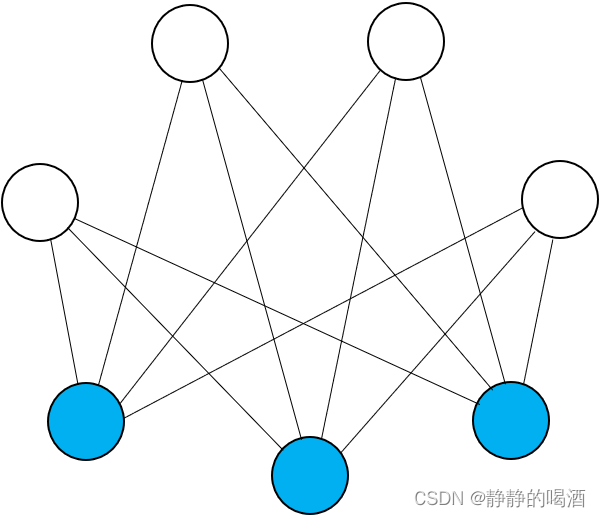
将随机变量集合
X
∈
R
p
\mathcal X \in \mathbb R^p
X∈Rp分成观测变量
v
v
v和隐变量
h
h
h两个部分:
X
=
(
x
1
,
x
2
,
⋯
,
x
p
)
T
=
(
h
v
)
p
×
1
{
h
=
(
h
1
,
h
2
,
⋯
,
h
m
)
m
×
1
T
v
=
(
v
1
,
v
2
,
⋯
,
v
n
)
n
×
1
T
m
+
n
=
p
\mathcal X = (x_1,x_2,\cdots,x_p)^T = \begin{pmatrix} h \\ v \end{pmatrix}_{p \times 1} \quad \begin{cases} h = (h_1,h_2,\cdots,h_m)_{m \times 1}^T \\ v = (v_1,v_2,\cdots,v_n)_{n \times 1}^T \end{cases} \quad m + n = p
X=(x1,x2,⋯,xp)T=(hv)p×1{h=(h1,h2,⋯,hm)m×1Tv=(v1,v2,⋯,vn)n×1Tm+n=p
并且观测变量
v
v
v、隐变量
h
h
h中的每一个随机变量均服从伯努利分布:
h
j
(
j
=
1
,
2
,
⋯
,
m
)
∈
{
0
,
1
}
v
i
(
i
=
1
,
2
,
⋯
,
n
)
∈
{
0
,
1
}
\begin{aligned} h_j(j=1,2,\cdots,m) \in \{0,1\} \\ v_i (i=1,2,\cdots,n) \in \{0,1\} \end{aligned}
hj(j=1,2,⋯,m)∈{0,1}vi(i=1,2,⋯,n)∈{0,1}
基于该模型,随机变量集合
X
\mathcal X
X的联合概率分布表示如下:
P
(
X
)
=
P
(
v
,
h
)
=
1
Z
exp
{
−
E
(
h
,
v
)
}
=
1
Z
exp
(
v
T
W
h
+
b
T
v
+
c
T
h
)
=
1
Z
exp
[
∑
j
=
1
m
∑
i
=
1
n
v
i
⋅
w
i
j
⋅
h
j
+
∑
i
=
1
n
b
i
v
i
+
∑
j
=
1
m
c
j
h
j
]
\begin{aligned} \mathcal P(\mathcal X) = \mathcal P(v,h) & = \frac{1}{\mathcal Z} \exp \{- \mathbb E(h,v)\} \\ & = \frac{1}{\mathcal Z} \exp \left(v^T\mathcal W h + b^Tv + c^Th\right) \\ & = \frac{1}{\mathcal Z} \exp \left[\sum_{j=1}^m\sum_{i=1}^n v_i \cdot w_{ij} \cdot h_j + \sum_{i=1}^n b_i v_i + \sum_{j=1}^m c_j h_j\right] \end{aligned}
P(X)=P(v,h)=Z1exp{−E(h,v)}=Z1exp(vTWh+bTv+cTh)=Z1exp[j=1∑mi=1∑nvi⋅wij⋅hj+i=1∑nbivi+j=1∑mcjhj]
推断任务——边缘概率求解
- 在受限玻尔兹曼机中,仅对观测变量
v
v
v的边缘概率分布进行求解。边缘概率
P
(
v
)
\mathcal P(v)
P(v)本质上就是对联合概率分布关于隐变量
h
h
h的积分操作:
P ( v ) = ∑ h P ( v , h ) \mathcal P(v) = \sum_{h}\mathcal P(v,h) P(v)=h∑P(v,h) - 由于模型已知,即模型参数
W
,
b
,
c
\mathcal W,b,c
W,b,c是已知的。将上式沿
P
(
v
,
h
)
\mathcal P(v,h)
P(v,h)展开:
再写一遍~
化简目标是:将P ( v , h ) \mathcal P(v,h) P(v,h)中关于隐变量h h h中的项积分掉,使其变为‘仅包含观测变量’v v v的式子。
P ( v ) = ∑ h [ 1 Z exp ( ∑ j = 1 m ∑ i = 1 n v i ⋅ w i j ⋅ h j + ∑ i = 1 n b i v i + ∑ j = 1 m c j h j ) ] = ∑ h 1 , ⋯ ∑ h m [ 1 Z exp ( ∑ j = 1 m ∑ i = 1 n v i ⋅ w i j ⋅ h j + ∑ i = 1 n b i v i + ∑ j = 1 m c j h j ) ] \begin{aligned} \mathcal P(v) & = \sum_{h} \left[\frac{1}{\mathcal Z} \exp \left(\sum_{j=1}^m\sum_{i=1}^n v_i \cdot w_{ij} \cdot h_j + \sum_{i=1}^n b_i v_i + \sum_{j=1}^m c_j h_j\right)\right] \\ & = \sum_{h_1},\cdots \sum_{h_m}\left[\frac{1}{\mathcal Z} \exp \left(\sum_{j=1}^m\sum_{i=1}^n v_i \cdot w_{ij} \cdot h_j + \sum_{i=1}^n b_i v_i + \sum_{j=1}^m c_j h_j\right)\right] \\ \end{aligned} P(v)=h∑[Z1exp(j=1∑mi=1∑nvi⋅wij⋅hj+i=1∑nbivi+j=1∑mcjhj)]=h1∑,⋯hm∑[Z1exp(j=1∑mi=1∑nvi⋅wij⋅hj+i=1∑nbivi+j=1∑mcjhj)] - 观察上述中括号内的项,其中
1
Z
,
∑
i
=
1
n
b
i
v
i
\frac{1}{\mathcal Z},\sum_{i=1}^n b_iv_i
Z1,∑i=1nbivi与随机变量
h
j
(
j
=
1
,
2
,
⋯
,
m
)
h_j(j=1,2,\cdots,m)
hj(j=1,2,⋯,m)无关;因而将它们提到公式前端:
为了方便观看,将v i ( i = 1 , 2 , ⋯ , n ) v_i(i=1,2,\cdots,n) vi(i=1,2,⋯,n)的部分进行合并
P ( v ) = 1 Z exp ( b T v ) ⋅ ∑ h 1 , ⋯ , ∑ h m exp { ∑ j = 1 m [ ( h j W j ) T v + c j h j ] } = 1 Z exp ( b T v ) ⋅ ∑ h 1 , ⋯ , ∑ h m exp { [ ( h 1 W 1 ) T v + c 1 h 1 ] + ⋯ + ( h m W m + c m h m ) T v } \begin{aligned} \mathcal P(v) & = \frac{1}{\mathcal Z} \exp (b^Tv) \cdot \sum_{h_1},\cdots,\sum_{h_m} \exp\left\{\sum_{j=1}^m \left[(h_j \mathcal W_j)^T v + c_jh_j\right]\right\} \\ & = \frac{1}{\mathcal Z} \exp (b^Tv) \cdot \sum_{h_1},\cdots,\sum_{h_m} \exp\left\{[(h_1\mathcal W_1)^Tv + c_1h_1] + \cdots + (h_m\mathcal W_m + c_mh_m)^Tv\right\} \end{aligned} P(v)=Z1exp(bTv)⋅h1∑,⋯,hm∑exp{j=1∑m[(hjWj)Tv+cjhj]}=Z1exp(bTv)⋅h1∑,⋯,hm∑exp{[(h1W1)Tv+c1h1]+⋯+(hmWm+cmhm)Tv}
以大括号第一项为例: ( h 1 W 1 ) T v + c 1 h 1 (h_1\mathcal W_1)^Tv + c_1h_1 (h1W1)Tv+c1h1中只和隐变量 h 1 h_1 h1相关,与其他隐变量无关。因此,上式可改写为:
P ( v ) = 1 Z exp ( b T v ) ⋅ { ∑ h 1 exp [ ( h 1 W 1 ) T v + c 1 h 1 ] } ⋯ { ∑ h m exp [ ( h m W m ) T v + c m h m ] } \mathcal P(v) = \frac{1}{\mathcal Z} \exp (b^Tv) \cdot \left \{\sum_{h_1} \exp [(h_1\mathcal W_1)^Tv + c_1h_1]\right\} \cdots \left \{\sum_{h_m} \exp [(h_m\mathcal W_m)^Tv + c_mh_m]\right\} P(v)=Z1exp(bTv)⋅{h1∑exp[(h1W1)Tv+c1h1]}⋯{hm∑exp[(hmWm)Tv+cmhm]}
由于 h j ( j = 1 , 2 , ⋯ , m ) ∈ { 0 , 1 } h_j(j=1,2,\cdots,m) \in \{0,1\} hj(j=1,2,⋯,m)∈{0,1},因此上式每个大括号中的项可继续展开,表示为如下形式。这里以第一项为例:
∑ h 1 exp [ ( h 1 W 1 ) T v + c 1 h 1 ] = ∑ h 1 ∈ { 0 , 1 } exp [ ( h 1 W 1 ) T v + c 1 h 1 ] = exp ( 0 ) + exp ( W 1 T v + c 1 ) = 1 + exp ( W 1 T v + c 1 ) \begin{aligned} \sum_{h_1} \exp [(h_1\mathcal W_1)^Tv + c_1h_1] & = \sum_{h_1 \in \{0,1\}}\exp [(h_1\mathcal W_1)^Tv + c_1h_1] \\ & = \exp(0) + \exp(\mathcal W_1^Tv + c_1) \\ & = 1 + \exp(\mathcal W_1^Tv + c_1) \end{aligned} h1∑exp[(h1W1)Tv+c1h1]=h1∈{0,1}∑exp[(h1W1)Tv+c1h1]=exp(0)+exp(W1Tv+c1)=1+exp(W1Tv+c1)
对上式继续化简:
对1 + exp ( W j T v + c j ) 1 + \exp(\mathcal W_j^Tv + c_j) 1+exp(WjTv+cj)进行变形,将l o g log log函数引入,从而使exp , log \exp,\log exp,log相互抵消。
1 + exp ( W j T v + c j ) = exp { log [ 1 + exp ( W j T v + c j ) ] } j = 1 , 2 , ⋯ , m 1 + \exp(\mathcal W_j^Tv + c_j) = \exp \left \{\log [1 + \exp(\mathcal W_j^Tv + c_j)]\right\} \quad j=1,2,\cdots,m 1+exp(WjTv+cj)=exp{log[1+exp(WjTv+cj)]}j=1,2,⋯,m - 因而原式
P
(
v
)
\mathcal P(v)
P(v)有:
P ( v ) = 1 Z exp ( b T v ) ⋅ ∏ j = 1 m exp { log [ 1 + exp ( W j T v + c j ) ] } \mathcal P(v) = \frac{1}{\mathcal Z} \exp (b^Tv) \cdot \prod_{j=1}^m \exp\left \{\log [1 + \exp(\mathcal W_j^Tv + c_j)]\right\} P(v)=Z1exp(bTv)⋅j=1∏mexp{log[1+exp(WjTv+cj)]}
将e x p exp exp提出来,最终有:
P ( v ) = 1 Z exp { b T v + ∑ j = 1 m log [ 1 + exp ( W j T v + c j ) ] } \mathcal P(v) = \frac{1}{\mathcal Z} \exp \left\{b^Tv + \sum_{j=1}^m \log[1 + \exp(\mathcal W_j^T v + c_j)]\right\} P(v)=Z1exp{bTv+j=1∑mlog[1+exp(WjTv+cj)]}
观测变量 v v v的边缘概率分布即为所求。
边缘概率与Softplus函数
观察上式中的
log
[
1
+
exp
(
W
j
T
v
+
c
j
)
]
\log[1 + \exp(\mathcal W_j^T v + c_j)]
log[1+exp(WjTv+cj)]部分,它实际上就是softplus的表现形式:
Softplus
(
x
)
=
log
[
1
+
exp
(
x
)
]
\text{Softplus}(x) = \log [1 + \exp(x)]
Softplus(x)=log[1+exp(x)]
Softplus
\text{Softplus}
Softplus函数图像表示如下:
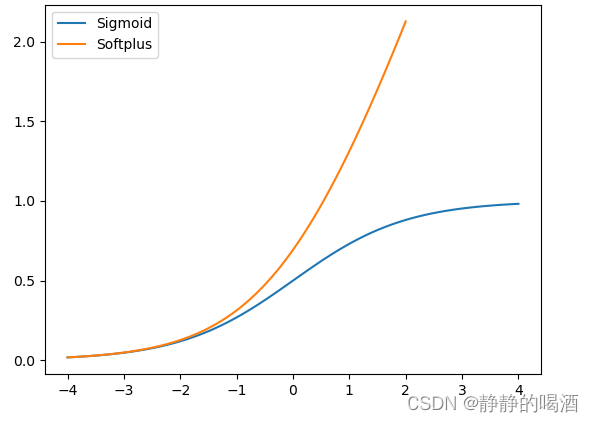
Softplus也是一种激活函数,它可看做是ReLU函数的平滑效果,其值域为
(
0
,
∞
)
(0,\infty)
(0,∞)(不含0)。并且不会像ReLU函数产生神经元挂掉情况。
并且更值得一提的属性是,Softplus函数的导数是Sigmoid函数:
∂
Softplus
(
x
)
∂
x
=
exp
(
x
)
exp
(
x
)
+
1
=
1
1
+
1
exp
(
x
)
=
1
1
+
exp
(
−
x
)
\begin{aligned}\frac{\partial \text{ Softplus}(x)}{\partial x} & = \frac{\exp(x)}{\exp(x) + 1} \\ & = \frac{1}{1 + \frac{1}{\exp (x)}} \\ & = \frac{1}{1 + \exp(-x)} \end{aligned}
∂x∂ Softplus(x)=exp(x)+1exp(x)=1+exp(x)11=1+exp(−x)1
因而上述公式可最终化简为:
W
j
\mathcal W_j
Wj表示
W
\mathcal W
W矩阵第
j
j
j行的行向量。
P
(
v
)
=
1
Z
exp
{
b
T
v
+
∑
j
=
1
m
Softplus
(
W
j
T
v
+
c
j
)
}
\mathcal P(v) = \frac{1}{\mathcal Z} \exp \{b^Tv + \sum_{j=1}^m \text{Softplus}(\mathcal W_j^T v + c_j)\}
P(v)=Z1exp{bTv+j=1∑mSoftplus(WjTv+cj)}
至此,受限玻尔兹曼机介绍结束(Learning问题的坑后续补)。下一节将介绍配分函数(Partition Function)。
相关参考:
机器学习-受限玻尔兹曼机(6)-模型推断(Inference)-边缘概率
速用笔记 | Sigmoid/Tanh/ReLu/Softplus 激活函数的图形、表达式、导数、适用条件










![[附源码]计算机毕业设计基于Springboot物品捎带系统](https://img-blog.csdnimg.cn/a192c9500a184a6ba2d028d985ce44f5.png)