本文由清华大学与虎牙信息科技有限公司、元象唯思控股(深圳)有限公司和香港中文大学合作。 人类语音的风格表达是多尺度的,不仅包括全局尺度的情感表达,还包括局部尺度的韵律表达。 而现有关于表现力语音合成的工作只考虑了单一尺度的说话风格。 针对该问题,本文提出一种基于不同层级上下文语义信息来建模 段落级别、句子级别和字级别 等不同尺度说话风格的方法,以进一步提升合成语音的表现力。 在中文有声小说数据集上,与只考虑单一尺度说话风格的基线模型相比,本文所提方法的用户偏好率最多可 提升38% 、主观意见得分最多可 提升0.377 。
扫码阅读论文
https://arxiv.org/abs/2204.02743
合成样例试听
https://thuhcsi.github.io/interspeech2022-msc-tts/
01 背景动机
随着深度学习的发展,基于神经网络的语音合成模型已经可以合成具有中性说话风格的高质量语音。 然而,合成语音的表现力和真人录音相比仍然有明显差距。 这阻碍了语音合成技术在许多领域的应用,如有声读物、播客和语音助手。
基于文本预测说话风格,是实现表现力语音合成的主要方法之一。 有的工作根据当前句子的文本或者上下文预测句子级别的风格表征,实现了全局尺度的说话风格建模; 另一些研究进一步将风格建模粒度细化,对词级别或者音素级别韵律信息进行预测。
但是,上述工作只考虑了单一尺度的说话风格,这对完全建模人类语音的表现力是不够的。 一些研究已经揭示,人类语音的风格表达是多尺度的,其中全局尺度的风格通常被视为情感,而局部尺度的风格则更接近于韵律变化,这些不同尺度的风格共同产生了语音中丰富的表现力。
02 贡献
本文提出了一种多尺度说话风格建模方法,其核心是基于不同层级上下文语义信息来建模段落级别、句子级别和字级别等不同尺度的说话风格,以进一步提升合成语音的表现力。 该方法在FastSpeech 2的基础上增加了一个多尺度风格提取器和一个多尺度风格预测器。 多尺度风格提取器被用于从全局、句子和每个字对应的语音片段中提取三个不同层级的说话风格表征。 在提取器的基础上,多尺度风格预测器从上下文中提取不同层级的语义信息,然后以残差连接的方式依次预测这各个层级的说话风格表征。 特别地,为了减少不同层级说话风格表征之间的冗余,本文提出用语音表征的残差来表示不同层级的风格变化。 实验表明,本文提出的方法可以显著提升合成语音的自然度和表现力。
03 解决方案
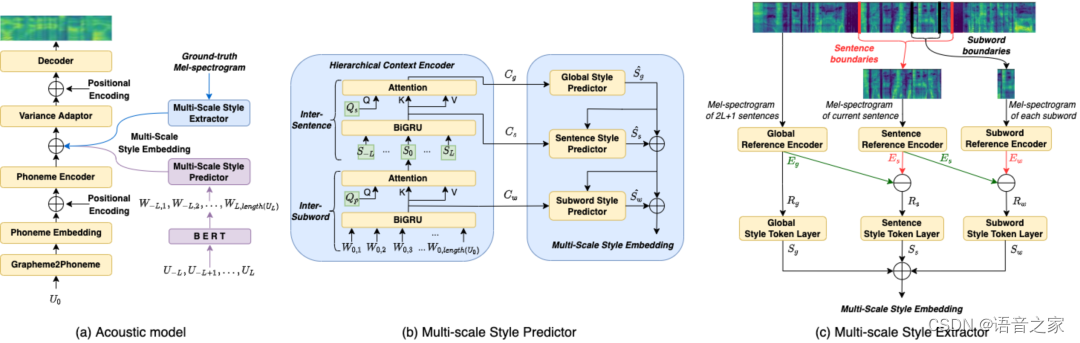
本文提出的模型结构如上图所示,它主要包括: (1) 多尺度风格提取器 (Multi-scale Style Extractor); (2) 多尺度风格预测器 (Multi-scale Style Predictor); (3) 基于FastSpeech 2的声学模型 。 提取器将用于提取三个不同层级的说话风格表征,而预测器用于从上下文中预测这些风格表征。 声学模型在提取器或者预测器的帮助下合成当前句子的语音。
多尺度风格提取器
多尺度风格提取器由三个与不同层级的参考编码器和风格标记层组成。 本文考虑了与上下文文本范围对应的整段音频,并按照句子边界、字边界切分得到当前句子和句子内每个字对应的音频片段,不同层级的音频片段将通过对应层级的参考编码器获得相应的语音表征。 接下来,不同层级语音表征之间的残差将被视作风格变化,送入对应的风格标记层。 最后,不同层级风格标记层的输出,就是我们得到的当前句子不同层级的风格表征。
为了避免训练时多尺度风格的学习相互干扰,段落级别、句子级别和字级别的参考编码器和风格标记层将依次训练,当训练其中一个层级的模块时,其余层级的模块被冻结。 当多尺度风格提取器训练完毕后,我们将冻结多尺度风格提取器,以提取器提取的风格表征作为预测器的训练目标,使得预测器能更好的建立不同层级语音风格和文本语义之间的联系。
多尺度风格预测器
本文考虑了固定数量的上文句子、当前句和下文句子组成的上下文文本。 上下文文本先通过预训练的BERT模型获得字级别的语义表征序列,再作为多尺度风格预测器的输入。
多尺度风格预测器首先利用包含两层注意力网络的层级上下文编码器,对上下文的字间关系和句间关系进行建模,得到段落级别、句子级别和字级别的上下文语义表征。 接下来,模型将根据不同层级上下文语义表征预测对应层级的风格表征,以还原人类语音中多尺度的说话风格。 此外,考虑到更接近全局尺度的高层级语音风格会对低层级的语音风格产生影响,在预测过程我们基于残差连接从高层级到低层级依次对语音风格进行建模。 具体来说,高层级的风格首先被预测,然后被用作低层级风格预测器的条件输入,这种结构与风格提取器的残差策略是对称的。
04实验验证实验数据
本文 在一个内部的普通话有声读物数据集上进行训练和测试,该数据集包含了14500句约30小时的有声读物录音,这些录音是一位专业的男性说话人以丰富的表现力阅读小说时录制的 。
基线模型
我们实现了三种基于FastSpeech 2的模型作为基线模型,其细节如下:
FastSpeech 2: 开源实现的FastSpeech 2模型。
WSV*: 词级风格变(Word-level Style Variatios)模型。 为了进行公平的对比,我们用FastSpeech 2代替原始版本的Tacotron 2作为声学模型。 此外,还通过一个额外的双向GRU来考虑上下文信息。
HCE: 层级上下文编码器(Hierarchical Context Encoder)模型,它从上下文中预测句子级别的说话风格。
对比实验
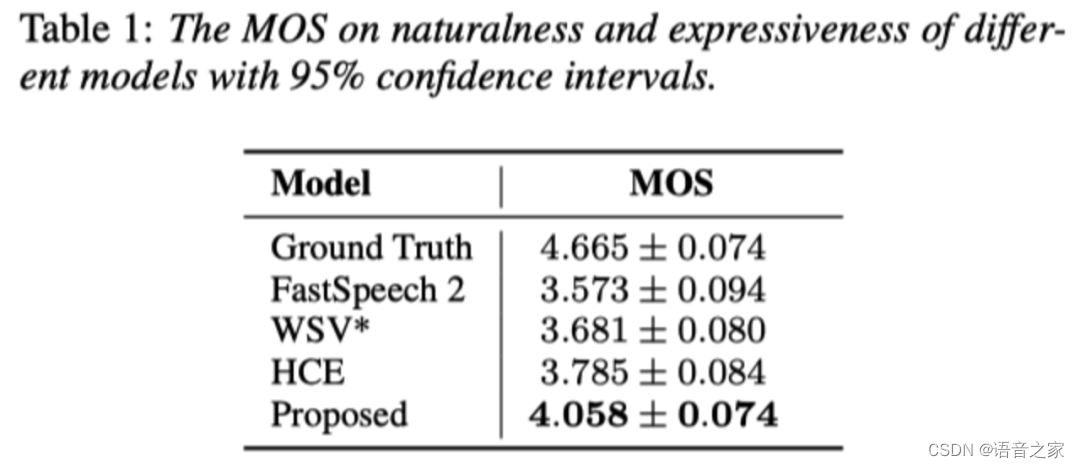
为了说明本文所提方法的有效性,我们分别通过主观测评和客观测评对合成语音的自然度和表现力进行了比较,如下表和下图所示。 从实验结果可以看到,本文所提方法在多项测评中均优于基线模型。 与FastSpeech 2相比,另外三个模型(WSV*、HCE和我们提出的模型)都表现的更好,这表明考虑上下文信息建模说话风格确实有助于表现力语音合成。 相比只考虑局部说话风格建模的WSV*和只考虑全局说话风格建模的HCE,我们提出的模型取得了更好的性能,证明了对语音中不同尺度的说话风格进行建模的重要性。
消融实验
为了证明本文用到的几种技术的有效性,包括利用段落级别风格、多尺度框架和残差表示的风格表征,我们进行了三项消融实验。 首先忽视段落级别说话风格的建模,导致的CMOS为-0.428,进一步去掉多尺度框架(即只建模字级别的说话风格)的CMOS结果是-0.64。 这表明,建模句子级别和段落级别的说话风格对提升合成语音表现力有帮助。 此外,我们还发现,去除残差表示的风格表征的CMOS结果是-0.516,这表明它可以通过降低不同层级说话风格之间的冗余信息来有效地表示语音的风格变化。
样例分析
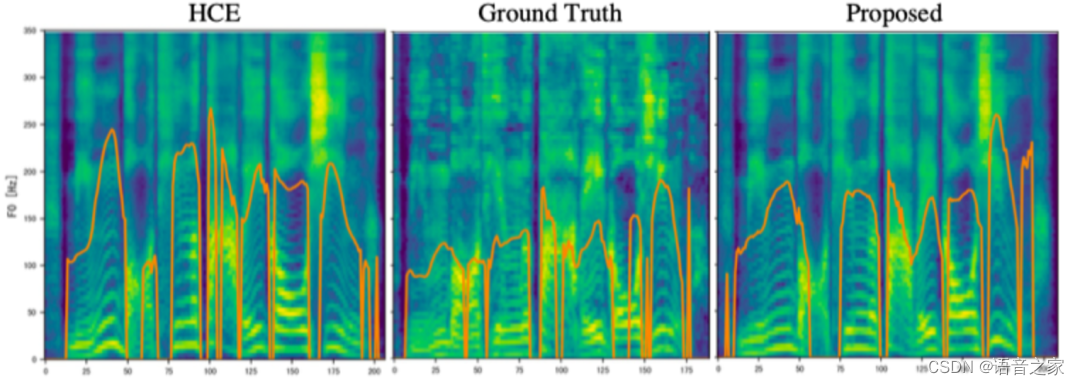
为了探索多尺度说话风格对合成语音表现力和自然度的影响,我们进行了样例分析。 我们用HCE和提出的模型合成了测试集中同一个语料,并且提供了该语料的真实语音作为参考。 实验结果如下图所示。 从结果可以看到,由HCE合成的语音包含更大的音高波动。 但由于缺乏局部尺度说话风格的建模,它缺乏控制合成语音局部风格特征的能力,导致与真实语音相比,音调的变化趋势有较大差异。 与HCE相比,我们提出的模型所合成的语音在细粒度的风格特征上更接近于真实语音,如语调的趋势和重音模式。
样例分析的结果表明,在多尺度说话风格的帮助下,我们的模型成功地学习了人类说话的风格变化,使合成语音拥有更接近于真实语音的韵律变化。
05结语
本文提出了一种多尺度说话风格的建模方法,从不同层级上下文语义信息中建模段落级别、句子级别和字级别等不同尺度说话风格,以提高语音合成的表现力。 此外,我们提出了一种基于残差表示的多尺度说话风格提取方法,有效降低了不同尺度风格表征之间的冗余信息。 实验结果表明,本文提出的方法通过从上下文中更准确的预测全局尺度和局部尺度的说话风格,显著提升了合成语音的表现力,使得合成语音拥有更接近于真实语音的韵律变化。


![[附源码]计算机毕业设计基于Springboot物品捎带系统](https://img-blog.csdnimg.cn/a192c9500a184a6ba2d028d985ce44f5.png)