文章目录
- 背景
- 一、Prefix-Tuning介绍
- 二、分类
- 三、效果
- 四、参阅
背景
近期, CSDN博客推荐流的标题党博客又多了起来, 先前的基于TextCNN版本的分类模型在语义理解上能力有限, 于是, 便使用的更大的模型来优化, 最终准确率达到了93.7%, 还不错吧.
一、Prefix-Tuning介绍
传统的fine-tuning是在大规模预训练语言模型(如Bert、GPT2等)上完成的, 针对不同的下游任务, 需要保存不同的模型参数, 代价比较高,
解决这个问题的一种自然方法是轻量微调(lightweight fine-tunning),它冻结了大部分预训练参数,并用小的可训练模块来增强模型,比如在预先训练的语言模型层之间插入额外的特定任务层。适配器微调(Adapter-tunning)在自然语言理解和生成基准测试上具有很好的性能,通过微调,仅添加约2-4%的任务特定参数,就可以获得类似的性能。
受到prompt的启发,提出一种prefix-tuning, 只需要保存prefix部分的参数即可.
相关论文: Prefix-Tuning: Optimizing Continuous Prompts for Generation
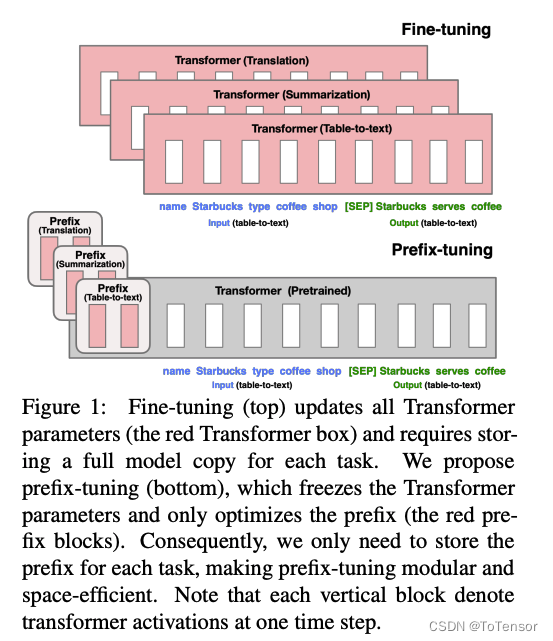
论文中, 作者使用Prefix-tuning做生成任务,它根据不同的模型结构定义了不同的Prompt拼接方式.

对于自回归模型,加入前缀后的模型输入表示:
对于编解码器结构的模型,加入前缀后的模型输入表示:
原理部分不过多赘述, 对于Prompt不太熟悉的同学, 一定要看看王嘉宁老师写的综述: Prompt-Tuning——深度解读一种新的微调范式
与Prefix-Tuning类似的方法还有P-tuning V2,不同之处在于Prefix-Tuning是面向文本生成领域的,P-tuning V2面向自然语言理解.
二、与Bert对比
Bert
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
因为我这里是二分类, 所以最后一层多了个Linear层
Prefix Tuning Bert
PeftModelForSequenceClassification(
(base_model): BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): ModulesToSaveWrapper(
(original_module): Linear(in_features=768, out_features=2, bias=True)
(modules_to_save): ModuleDict(
(default): Linear(in_features=768, out_features=2, bias=True)
)
)
)
(prompt_encoder): ModuleDict(
(default): PrefixEncoder(
(embedding): Embedding(20, 18432)
)
)
(word_embeddings): Embedding(21128, 768, padding_idx=0)
)
比Bert多了prompt_encoder, 查阅peft源码可以看到PrefixEncoder的实现:
class PrefixEncoder(torch.nn.Module):
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
token_dim = config.token_dim
num_layers = config.num_layers
encoder_hidden_size = config.encoder_hidden_size
num_virtual_tokens = config.num_virtual_tokens
if self.prefix_projection and not config.inference_mode:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
self.transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
else:
self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.transform(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
其实就是多了个embedding层
二、分类
好在huggingface的peft库对几个经典的prompt tuning都有封装, 实现起来并不难:
import logging
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PrefixTuningConfig,
PromptEncoderConfig,
PromptTuningConfig,
LoraConfig,
)
from torch.optim import AdamW
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from common.path.model.bert import get_chinese_roberta_wwm_ext
import os
import time
import torch
import math
from torch.utils.data import DataLoader
from datasets import load_dataset
import evaluate
from tqdm import tqdm
from server.tag.common.data_helper import TagClassifyDataHelper
logger = logging.getLogger(__name__)
class BlogTitleAttractorBertConfig(object):
max_length = 32
batch_size = 128
p_type = "prefix-tuning"
model_name_or_path = get_chinese_roberta_wwm_ext()
lr = 3e-4
num_epochs = 50
num_labels = 2
device = "cuda" # cuda/cpu
evaluate_every = 100
print_every = 10
def get_tokenizer(model_config):
if any(k in model_config.model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_config.model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
return tokenizer
def get_model(model_config, peft_config):
model = AutoModelForSequenceClassification.from_pretrained(model_config.model_name_or_path, num_labels=model_config.num_labels)
if model_config.p_type is not None:
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
return model
def get_peft_config(model_config):
p_type = model_config.p_type
if p_type == "prefix-tuning":
peft_type = PeftType.PREFIX_TUNING
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
elif p_type == "prompt-tuning":
peft_type = PeftType.PROMPT_TUNING
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
elif p_type == "p-tuning":
peft_type = PeftType.P_TUNING
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
elif p_type == "lora":
peft_type = PeftType.LORA
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
else:
print(f"p_type:{p_type} is not supported.")
return None, None
logger.info(f"训练: {p_type} bert 模型")
return peft_type, peft_config
def get_lr_scheduler(model_config, model, data_size):
optimizer = AdamW(params=model.parameters(), lr=model_config.lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (data_size * model_config.num_epochs),
num_training_steps=(data_size * model_config.num_epochs),
)
return optimizer, lr_scheduler
class BlogTtileAttractorBertTrain(object):
def __init__(self, config, options) -> None:
self.config = config
self.options = options
self.model_path = "./data/models/blog_title_attractor/prefix-tuning"
self.data_file = './data/datasets/blogs/title_attractor/train.csv'
self.tag_path = "./data/models/blog_title_attractor/prefix-tuning/tag.txt"
self.model_config = BlogTitleAttractorBertConfig()
self.tag_dict, self.id2tag_dict = TagClassifyDataHelper.load_tag(self.tag_path)
self.model_config.num_labels = len(self.tag_dict)
_, peft_config = get_peft_config(self.model_config)
self.tokenizer = get_tokenizer(self.model_config)
self.model = get_model(self.model_config, peft_config)
self.model.to(self.model_config.device)
def replace_none(self, example):
example["title"] = example["title"] if example["title"] is not None else ""
example["label"] = self.tag_dict[example["label"].lower()]
return example
def load_data(self):
# 加载数据集
dataset = load_dataset("csv", data_files=self.data_file)
dataset = dataset.filter(lambda x: x["title"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
dataset = dataset.map(self.replace_none)
return dataset
def process_function(self, examples):
tokenized_examples = self.tokenizer(examples["title"], truncation=True, max_length=self.model_config.max_length)
return tokenized_examples
def collate_fn(self, examples):
return self.tokenizer.pad(examples, padding="longest", return_tensors="pt")
def __call__(self):
datasets = self.load_data()
tokenized_datasets = datasets.map(self.process_function, batched=True, remove_columns=['title'])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=self.collate_fn, batch_size=self.model_config.batch_size)
eval_dataloader = DataLoader(
tokenized_datasets["test"], shuffle=False, collate_fn=self.collate_fn, batch_size=self.model_config.batch_size
)
optimizer, lr_scheduler = get_lr_scheduler(self.model_config, self.model, len(train_dataloader))
metric = evaluate.load("accuracy")
start_time = time.time()
best_loss = math.inf
for epoch in range(self.model_config.num_epochs):
self.model.train()
for step, batch in enumerate(train_dataloader):
batch.to(self.model_config.device)
outputs = self.model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if step > 0 and step % self.model_config.print_every == 0:
now_time = time.time()
predictions = outputs.logits.argmax(dim=-1)
eval_metric = metric.compute(predictions=predictions, references=batch["labels"])
if loss < best_loss:
best_loss = loss
self.model.save_pretrained(self.model_path)
print("***TRAIN, steps:{%d}, loss:{%.3f}, accuracy:{%.3f}, cost_time:{%.3f}h" % (
step, loss, eval_metric["accuracy"], (now_time - start_time) / 3600))
else:
print("TRAIN, steps:{%d}, loss:{%.3f}, accuracy:{%.3f}, cost_time:{%.3f}h" % (
step, loss, eval_metric["accuracy"], (now_time - start_time) / 3600))
if step > 0 and step % self.model_config.evaluate_every == 0:
self.model.eval()
total_loss = 0.
for step, batch in enumerate(tqdm(eval_dataloader)):
batch.to(self.model_config.device)
with torch.no_grad():
outputs = self.model(**batch)
loss = outputs.loss
total_loss += loss
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print("epoch:%d, VAL, loss:%.3f, accuracy:%.3f" % (epoch, total_loss, eval_metric["accuracy"]))
三、效果
Prefix Tuning Bert
在标题党上的准确率为: 0.9368932038834952
在非标题党上的准确率为: 0.937015503875969
Bert
在标题党上的准确率为: 0.7006472491909385
在非标题党上的准确率为: 0.9728682170542635
直接微调的效果与Prefix Tuning 相比差距有点大, 理论上不应该有这么大差距才对, 应该和数据集有关系
四、参阅
- Prompt-Tuning——深度解读一种新的微调范式
- Continuous Optimization:从Prefix-tuning到更强大的P-Tuning V2
- [代码学习]Huggingface的peft库学习-part 1- prefix tuning
温馨提示: 标题党文章在推荐流会被降权哦