文章目录
- OneFormer: One Transformer to Rule Universal Image Segmentation
- 摘要
- 本文方法
- 实验结果
OneFormer: One Transformer to Rule Universal Image Segmentation
摘要
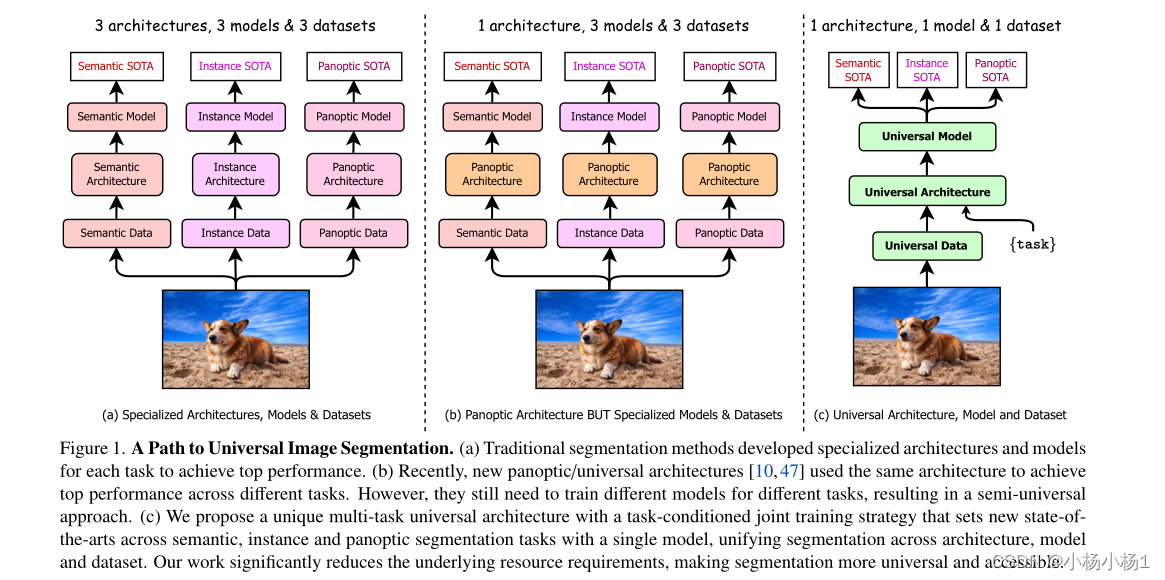
通用图像分割并不是一个新概念。过去统一图像分割的尝试包括场景解析、全景分割,以及最近的新全景架构。然而,这种全景架构并不能真正统一图像分割,因为它们需要在语义、实例或全景分割上单独训练,以获得最佳性能。理想情况下,一个真正通用的框架应该只训练一次,并在所有三个图像分割任务中实现SOTA性能。
本文方法
- 提出了OneFormer,这是一种通用的图像分割框架,将分割与多任务一次训练设计相结合。
- 首先提出了一种任务条件联合训练策略,该策略能够在单个多任务训练过程中对每个领域的标签(语义、实例和全景分割)进行训练。
- 其次,引入了一个他task token来将我们的模型以手头的任务为条件,使我们的模型任务是动态的,以支持多任务训练和推理。
- 第三,我们建议在训练过程中使用查询文本对比损失来建立更好的任务间和类间区分。
代码地址
本文方法
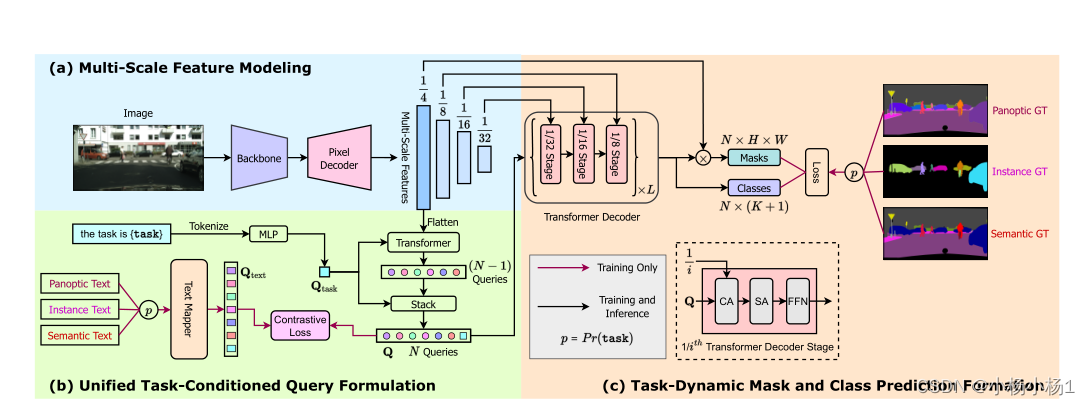
OneFormer框架架构:
(a) 我们使用主干网络提取输入图像的多尺度特征,然后使用像素解码器。
(b) 我们在任务令牌(Qtask)的指导下,在变换器内部建立了一组统一的N−1任务条件对象查询和平坦的1/4尺度特征
接下来,我们将Qtask和来自transformer的N-1个查询连接起来。
我们在训练期间对任务进行统一(p=1/3)采样,并使用文本映射器生成相应的文本查询(Qtext)。
我们计算一个查询文本对比损失来学习任务间的区别。我们可以在推理过程中丢弃文本映射器,从而使我们的模型参数高效。
(c) 我们使用多级L层transformer解码器来获得任务动态类和掩码预测
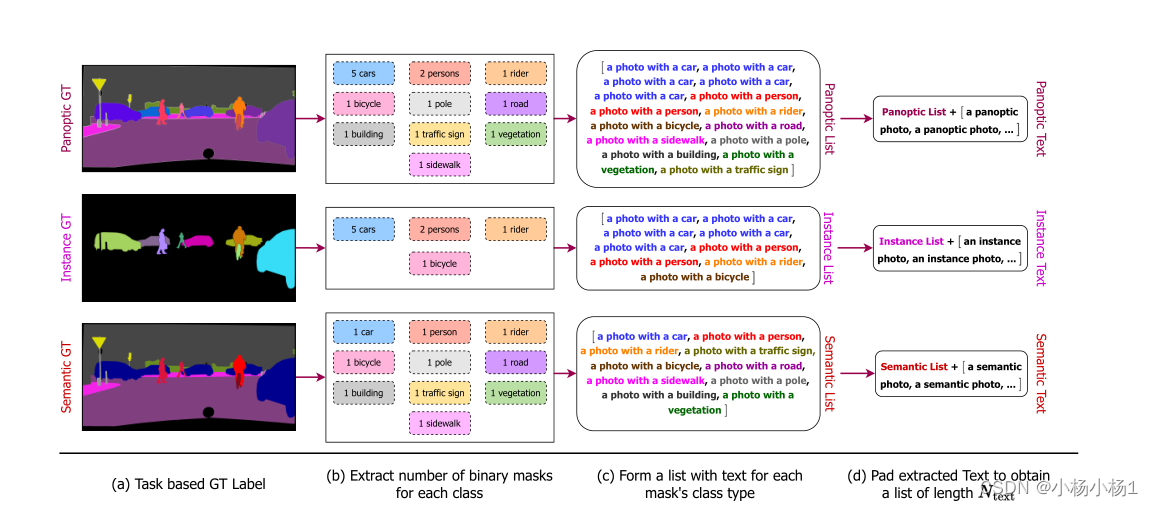
输入文本格式
(a) 我们在训练中统一对任务进行抽样
(b) 我们从对应的GT标签中提取每个类的不同二进制掩码的数量
(c) 我们使用模板“带有{CLS}的照片”为每个掩码形成一个包含文本描述的列表,其中CLS表示对象掩码的相应类名
(d) 最后,我们使用表示无对象检测的“a/an{task}photo”条目将文本列表填充为恒定长度的Ntext;其中task∈{panoptic, instance, semantic}。
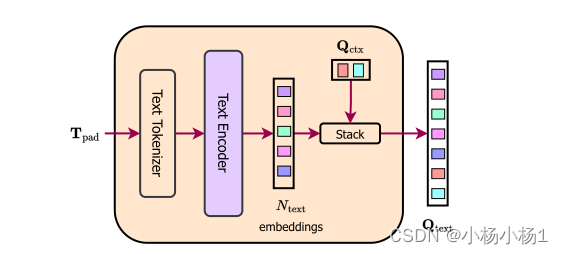
Text Mapper:我们使用6层transformer文本编码器对输入文本列表(Tpad)进行 tokenize化,然后对其进行编码,以获得一组Ntext嵌入。我们将一组Nctx可学习嵌入连接到编码的表示,以获得最终的N个文本查询(Qtext)。N个文本查询代表图像中存在的对象的基于文本的表示。
详情可以看原论文
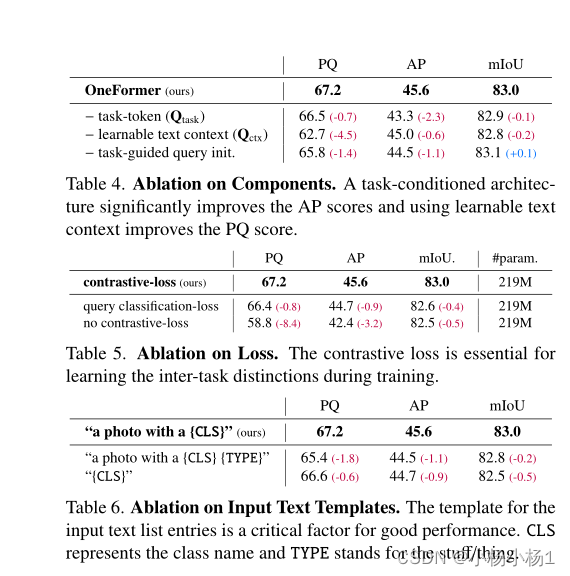
实验结果


![[LeetCode周赛复盘] 第 106 场双周赛20230611](https://img-blog.csdnimg.cn/796d90e5376a490aaaf432e5acd0f166.png)
![Vue 封装ajax请求[接口]函数](https://img-blog.csdnimg.cn/7614f81d8a20497f806b911e3c450a87.png)




![[ICNN 1993] Optimal brain surgeon and general network pruning](https://img-blog.csdnimg.cn/8002965a019349669a6c4090a342d4ca.png#pic_center)


