如果遵循以下六种策略来构建 Prompt 提示词,在和 ChatGPT 对话中我们将获得更好、更符合我们要求的回答。

这些策略,后几种更适合在编程调用 ChatGPT API 时使用,不过也适用直接和 ChatGPT 对话,让它更好的理解我们的意图。
1、写清楚说明,
2、提供参考文本,
3、将复杂任务拆分为更简单的子任务,
4、给 ChatGPT 时间“思考”,
5、使用外部工具,
6、系统地测试更改。
点燃创作灵感:Prompt 实践指南揭秘!让 ChatGPT 更智能的六种策略(上)解释和举例了前两个策略和具体操作方法。
三、将复杂任务拆分为更简单的子任务
本策略适用于调用 API ,编写自己的特定类型的定制智能助手使用。
调用 API 示范如下
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)主要输入是消息参数。消息必须是一组消息对象,其中每个对象都有一个角色(“系统”、“用户”或“助手”)和内容。对话可以短到一条消息,也可以来回多次。
通常,对话首先使用系统消息进行格式化,然后是交替的用户和助手消息。
系统消息有助于设置助手(即ChatGPT)的行为。例如,您可以修改助手的个性或提供有关它在整个对话过程中应如何表现的具体说明。但是请注意,系统消息是可选的,没有系统消息的模型行为可能类似于使用通用消息,例如“你是一个有帮助的助手”。
用户消息提供请求或评论以供助手响应。助手消息存储以前的助手响应,但也可以由开发人员编写以提供所需行为的示例。
当用户说明引用之前的消息时,包括对话历史记录很重要。比如:用户的最后一个问题是“它在哪里播放?” 仅在有关 2020 年世界职业棒球大赛的先前消息的上下文中才有意义。由于模型对过去的请求没有记忆,因此所有相关信息都必须作为每个请求中对话历史记录的一部分提供,因此,助手消息可以存放之前对话的响应回答。
理解了调用API 的消息格式和约定,我们来看后续的操作策略。
3.1 使用意图分类(即扮演特定类型的AI助手)来识别与用户查询最相关的指令
对于需要大量独立指令集来处理不同情况的任务,首先对查询类型进行分类并使用该分类来确定需要哪些指令可能是有益的。
可以通过定义与处理给定类别中的任务相关的固定类别和硬编码指令来实现。这个过程也可以递归地应用于将任务分解为一系列阶段。
这种方法的优点是每个查询将仅包含执行任务下一阶段所需的指令,与使用单个查询执行整个任务相比,这可以降低错误率。
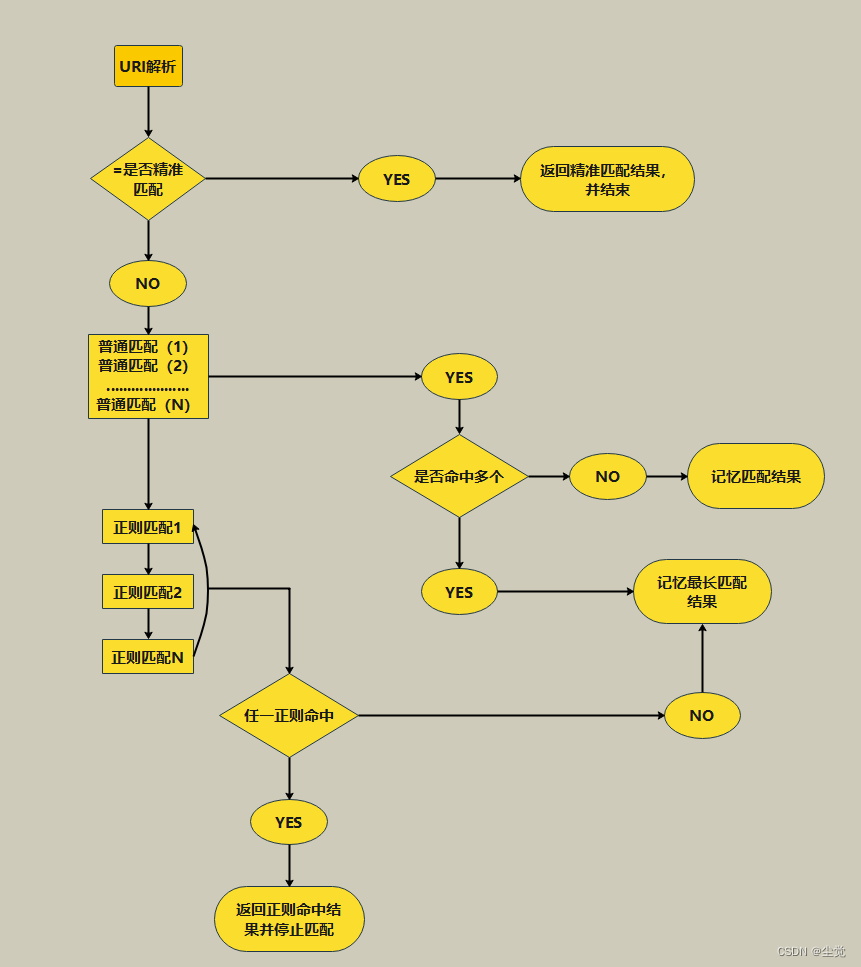
例如,假设对于客户服务应用程序,可以将查询分类如下:
| 系统 | 您将收到客户服务查询。将每个查询分为主要类别和次要类别。以 json 格式提供带有键的输出:primary 和 secondary。主要类别:计费、技术支持、账户管理或一般查询。计费次要类别: - 取消订阅或升级 - 添加付款方式 - 收费说明 - 对收费提出异议 技术支持次要类别: - 故障排除 - 设备兼容性 - 软件更新 账户管理次要类别: - 密码重置 - 更新个人信息 - 关闭帐户 -帐户安全 一般查询二级类别: - 产品信息 - 定价 - 反馈 - 与人交谈 |
| 用户 | 我需要让我的互联网重新工作。 |
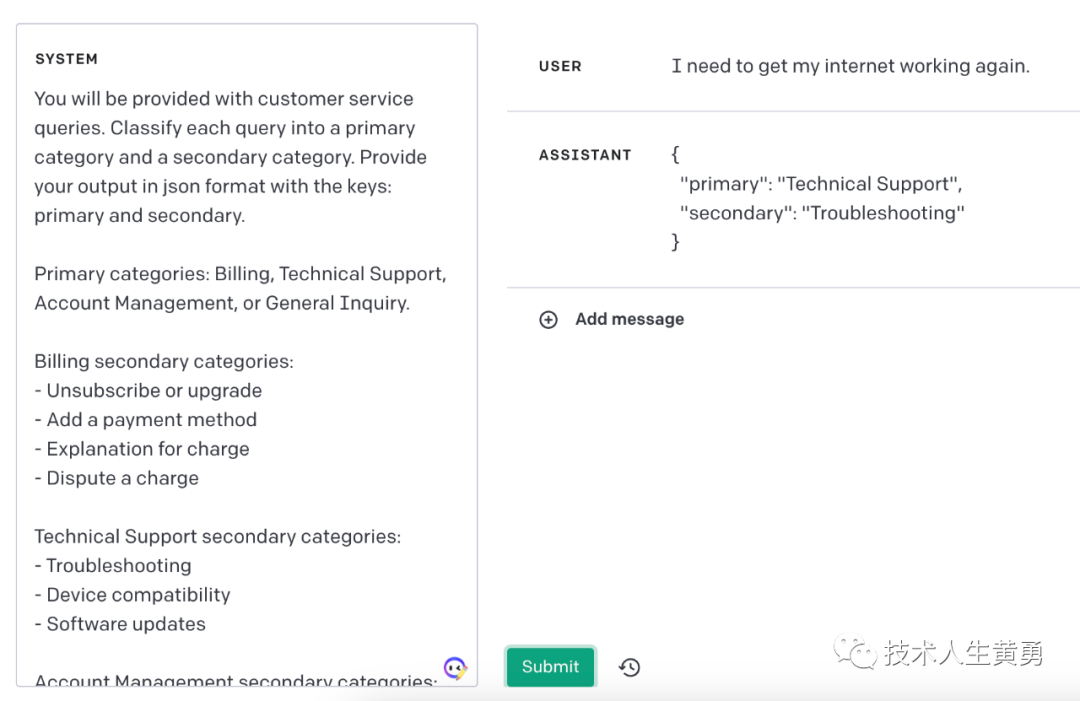
基于这类技术支持客户查询的分类,可以向 ChatGPT 提供一组更具体的指令来处理后续步骤。例如,假设客户需要“故障排除”方面的帮助。
| 系统 | 您将收到需要在技术支持环境中进行故障排除的客户服务查询。通过以下方式帮助用户: - 要求他们检查所有进出路由器的电缆是否已连接。请注意,电缆随时间松动是很常见的。- 如果所有电缆都已连接但问题仍然存在,请询问他们使用的是哪种路由器型号 - 现在您将建议他们如何重新启动他们的设备: -- 如果型号是 MTD-327J,建议他们按下红色按钮并按住它 5 秒钟,然后等待 5 分钟,然后再测试连接。-- 如果型号是 MTD-327S,建议他们拔下并重新插入,然后等待 5 分钟,然后再测试连接。- 如果客户的问题在重启设备并等待 5 分钟后仍然存在,请通过输出 {"IT support requested"} 将他们连接到 IT 支持。 |
| 用户 | 我需要让我的互联网重新工作。 |
3.2 对于需要很长对话的对话应用,总结或过滤之前的对话
由于 ChatGPT 具有固定的上下文长度,因此整个对话都包含在上下文窗口中的用户和助手之间的对话不能无限期地继续。
这个问题有多种解决方法,其中之一是总结对话中的先前回合。一旦输入的大小达到预定的阈值长度,这可能会触发一个查询,该查询总结了部分对话,并且先前对话的摘要可以作为系统消息的一部分包含在内。或者,可以在整个对话过程中在后台异步总结先前的对话。
另一种解决方案是动态选择与当前查询最相关的对话的先前部分。需要参考后面的例子:“5.1 使用基于嵌入的搜索来实现高效的知识检索”。
3.3 分段总结长文档并递归构建完整摘要
由于 ChatGPT 具有固定的上下文长度,上下文长度减去单个查询中生成的摘要长度是能处理的最大文本范围。
要总结一个很长的文档,比如一本书,我们可以使用一系列查询来总结文档的每个部分。
节摘要可以被连接和总结生成摘要的摘要。这个过程可以递归地进行,直到总结了整个文档。如果有必要使用有关前面部分的信息来理解后面的部分,我们可以在书中任何给定点之前包括文本的连续摘要,同时总结该点的内容。
四、给 GPT 时间“思考”
4.1 在匆忙下结论之前,指示模型自己制定解决方案
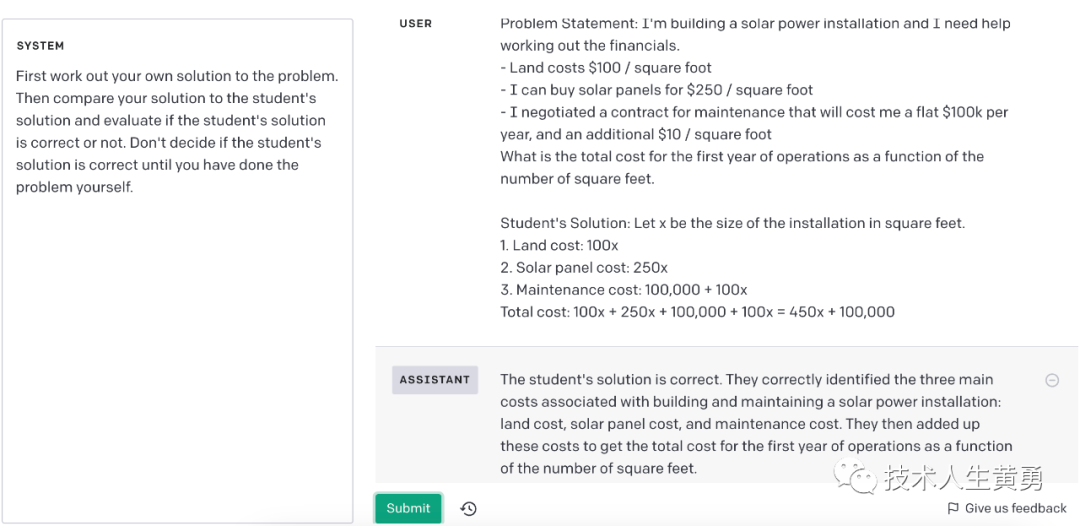
当我们明确指示模型在得出结论之前根据第一原则进行推理时,我们会得到更好的结果。例如,假设我们想要一个模型来评估学生对数学问题的解决方案。解决这个问题的最明显方法是简单地询问模型学生的解决方案是否正确。
| 系统 | 判断学生的答案是否正确。 |
用户 | 问题陈述:我正在建造一个太阳能装置,我需要帮助来计算财务。- 土地成本 100 美元/平方英尺 - 我可以以 250 美元/平方英尺的价格购买太阳能电池板 - 我协商了一份维护合同,每年将花费我 10 万美元,外加 10 美元/平方英尺 的总成本是多少第一年的运营作为平方英尺数的函数。学生的解答:令 x 为以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 100x 总成本:100x + 250x + 100,000 + 100x = 450x + 100,000 |
| 助手 | 这位同学的答案是正确的。 |
但是这位同学的解法其实是不正确的!我们可以通过提示模型首先生成自己的解决方案来让模型纠正这种错误回答。
| 系统 | 首先想出你自己解决问题的方法。然后将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。在您自己完成问题之前,不要判断学生的解决方案是否正确。 |
| 用户 | 问题陈述:我正在建造一个太阳能装置,我需要帮助来计算财务。- 土地成本 100 美元/平方英尺 - 我可以以 250 美元/平方英尺的价格购买太阳能电池板 - 我协商了一份维护合同,每年将花费我 10 万美元,外加 10 美元/平方英尺 的总成本是多少第一年的运营作为平方英尺数的函数。学生的解答:令 x 为以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 100x 总成本:100x + 250x + 100,000 + 100x = 450x + 100,000 |
| 助手 | 设 x 是以平方英尺为单位的安装尺寸。1.土地成本:100x 2.太阳能电池板成本:250x 3.维护成本:100,000 + 10x 总成本:100x + 250x + 100,000 + 10x = 360x + 100,000 学生的答案是错误的。他们在维护成本计算中犯了一个错误,使用 100x 而不是 10x。第一年运营的正确总成本是 360x + 100,000。 |
4.2 策略:使用内心独白或一系列查询来隐藏模型的推理过程
前面的策略表明,模型在回答特定问题之前详细推理问题有时很重要。对于某些应用程序,模型用于得出最终答案的推理过程不适合与用户共享。例如,在辅导应用程序中,我们可能希望鼓励学生自己找出答案,但模型对学生答案的推理过程可能会向学生揭示答案。
内心独白是一种可以用来解决这种情况的策略。内心独白的想法是指示模型将本应对用户隐藏的输出部分放入结构化格式中,以便于解析它们。然后在将输出呈现给用户之前,对输出进行解析并有选择的部分输出。
| 系统 | 按照以下步骤回答用户查询。第 1 步 - 首先找出您自己的问题解决方案。不要依赖学生的解决方案,因为它可能不正确。用三引号 (""") 将此步骤的所有作业括起来。第 2 步 - 将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。将此步骤的所有作业用三引号 ("") 括起来”)。第 3 步 - 如果学生犯了错误,请确定您可以在不给出答案的情况下给学生什么提示。将此步骤的所有工作用三重引号 (""") 括起来。第 4 步 - 如果学生犯了错误,请向学生提供上一步的提示(在三重引号之外)。而不是写“第 4 步 - ...”写“提示:”。 |
| 用户 | 问题陈述:<插入问题陈述> 学生解决方案:<插入学生解决方案> |
或者,也可以通过一系列查询来实现,除最后一个之外的所有查询都对最终用户隐藏。
系列查询的步骤如下:首先,我们可以让模型自己解决问题。由于此初始查询不需要学生的解决方案,因此可以省略系统设置。
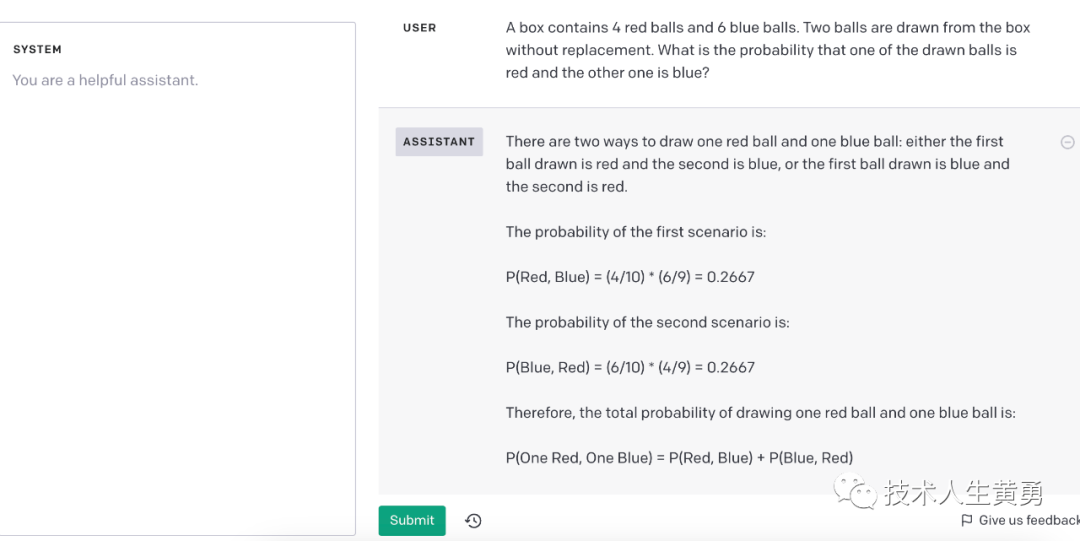
接下来,让模型使用所有可用信息来评估学生解决方案的正确性。
| 系统 | 将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。 |
| 用户 | 问题陈述:"""<插入问题陈述>""" 您的解决方案:"""<插入模型生成的解决方案>""" 学生的解决方案:"""<插入学生的解决方案>""" |
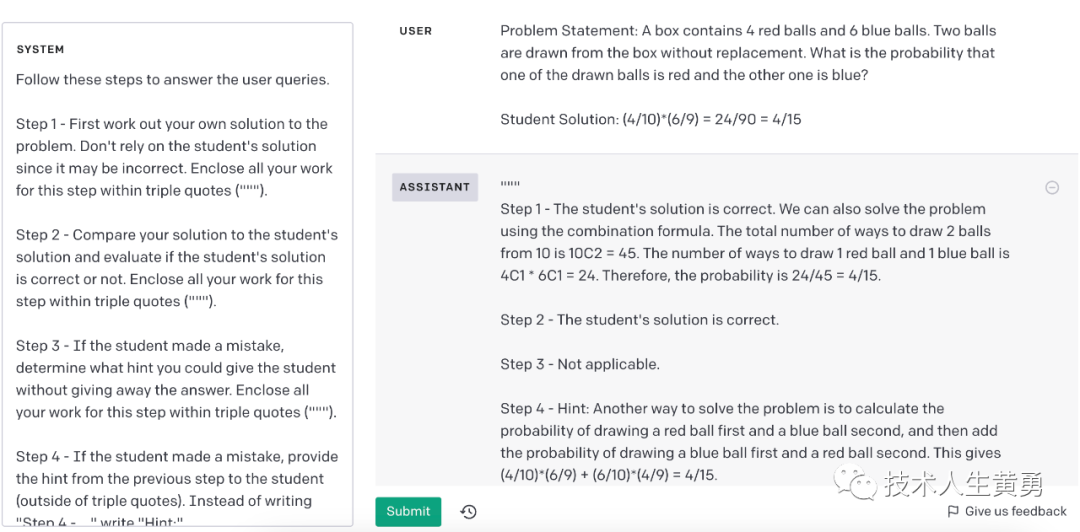
最后,让模型使用自己的分析来构建一个乐于助人导师角色的回复。
| 系统 | 你是数学老师。如果学生犯了错误,请以不透露答案的方式向学生提供提示。如果学生没有犯错,只需给他们一个鼓励的评论。 |
| 学生 | 问题陈述:"""<插入问题陈述>""" 您的解决方案:"""<插入模型生成的解决方案>""" 学生的解决方案:"""<插入学生的解决方案>""" 分析:"""<插入模型从上一步生成的分析 >""" |

4.3 询问模型是否遗漏了之前传递的任何内容
假设我们正在使用一个模型来列出与特定问题相关的来源的摘录。在列出每个摘录后,模型需要确定是否应该开始编写另一个摘录或是否应该停止。如果源文档很大,模型通常会过早停止并且无法列出所有相关摘录。在这种情况下,通常使用后续查询提示模型来查找它在先前传递中遗漏的任何摘录。
| 系统 | 您将获得一份由三重引号分隔的文件。你的任务是选择与以下问题相关的摘录:“人工智能历史上发生了哪些重大的范式转变。” 确保摘录包含解释它们所需的所有相关上下文——换句话说,不要提取缺少重要上下文的小片段。以 JSON 格式提供输出,如下所示:[{"excerpt": "..."}, ... {"excerpt": "..."}] |
| 用户 | """<在此处插入文档>""" |
| 助手 | [{“摘录”:“模型在这里写了一个摘录”},... {“摘录”:“模型在这里写了另一个摘录”}] |
| 用户 | 有更多相关的摘录吗?注意不要重复摘录。还要确保摘录包含解释它们所需的所有相关上下文——换句话说,不要提取缺少重要上下文的小片段。 |

下期预告:六种策略(下)
我写了一本小册子《AI 绘画零基础入门手册》,你可以学习如何使用 AI 绘图神器 Midjourney 来设计、绘画,并用它来为你赚钱。
看完全部内容,并且实践一遍,就可以上手做一个生成头像的 AI 变现项目。现在漫画头像,手机壁纸在小红书,闲鱼上都是很火的赚钱项目。
价格只需 19.9 元,买不了吃亏,买不了上当,并承诺无条件退款。

点击上面图片,长按,选择“识别图中的二维码”,即可下单购买。