【 图像分割 2022 ECCV】CP2
论文题目:CP2: Copy-Paste Contrastive Pretraining for Semantic Segmentation
中文题目:CP2:语义分割的复制粘贴对比预训练
论文链接:https://arxiv.org/abs/2203.11709
论文代码:https://github.com/wangf3014/CP2
论文团队:清华大学&约翰·霍普金斯大学&海交通大学
发表时间:
DOI:
引用:Wang F, Wang H, Wei C, et al. CP 2: Copy-Paste Contrastive Pretraining for Semantic Segmentation[C]//Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXX. Cham: Springer Nature Switzerland, 2022: 499-515.
引用数:10
摘要
自监督对比学习的最新进展产生了良好的图像级表征,这有利于分类任务,但通常忽略了像素级的详细信息,导致转移到密集预测任务(如语义分割)的性能不尽人意。
在这项工作中,我们提出了一种被称为CP2(Copy-Paste Contrastive Pretraining)的像素级对比学习方法,它有利于图像和像素级表征的学习,因此更适用于下游的密集预测任务。
具体来说,我们将一幅图像(前景)的随机裁剪部分复制粘贴到不同的背景图像上,并对语义分割模型进行预训练,目的是:1)区分前景像素和背景像素;2)识别共享同一前景的组成图像。
实验表明,CP2在下游语义分割方面有很强的性能: 通过在PASCAL VOC 2012上对CP2的预训练模型进行网络化,我们用ResNet-50获得78.6%的mIoU,用ViT-S获得79.5%。
1. 介绍
学习不变的图像级表征并转移到下游任务中,已经成为自监督对比学习的一个常见范式。具体来说,这些方法的目标是最小化同一图像的增强视图的图像级特征之间的欧氏( l 2 l_2 l2)距离[26,13]或交叉熵[5,6],或者通过优化InfoNCE[38]损失[28,12,14,10,11,41]将正面图像特征从一组负面图像特征中区分出来。
尽管在下游分类任务中取得了成功,但这些对比目标建立在图像中的每个像素都属于单个标签的假设之上,并且缺乏对空间变化图像内容的感知。 我们认为,这些面向分类的目标对于下游密集预测任务(如语义分割)并不理想,在语义分割中,模型应该区分图像中不同的语义标签。 对于语义分割任务,现有的对比学习模型容易过度适应于图像层表示的学习,而忽略了像素层的方差。
此外,目前用于下游语义分割任务的预训练优化范式存在体系结构失调:
1)与面向分类的预训练主干相比,语义分割模型通常需要较大的转换速率和较小的输出步幅[34,8];
2)经过良好预训练的主干和随机初始化的分割头的精细调整可能不同步,
例如,随机头可能产生对预训练主干有害的随机梯度,对性能产生负面影响。 这两个问题阻碍了面向分类的预训练主干促进密集的预测任务,如语义分割。
在本文中,我们提出了一种新型的自监督预训练方法,该方法是为下游语义分割而设计的,名为复制粘贴对比预训练(CP2)。具体来说,我们用Copy-Pasted输入图像预训练语义分割模型,这些图像是通过从前景图像中随机裁剪并粘贴到不同的背景图像上组成的。图2中显示了组成图像的例子。除了用于学习实例判别的图像对比损失[2,44,47,28],我们还引入了像素对比损失来加强密集预测。分割模型的训练是通过最大化前景像素之间的余弦相似度,同时最小化前景和背景像素之间的余弦相似度。总的来说,CP2产生了特定像素的致密表示,并对下游分割有两个关键优势: 1)CP2对骨干和分割头进行预训练,解决了架构错位的问题;2)CP2以密集预测为目标对模型进行预训练,建立了模型对图像中空间变化信息的感知。
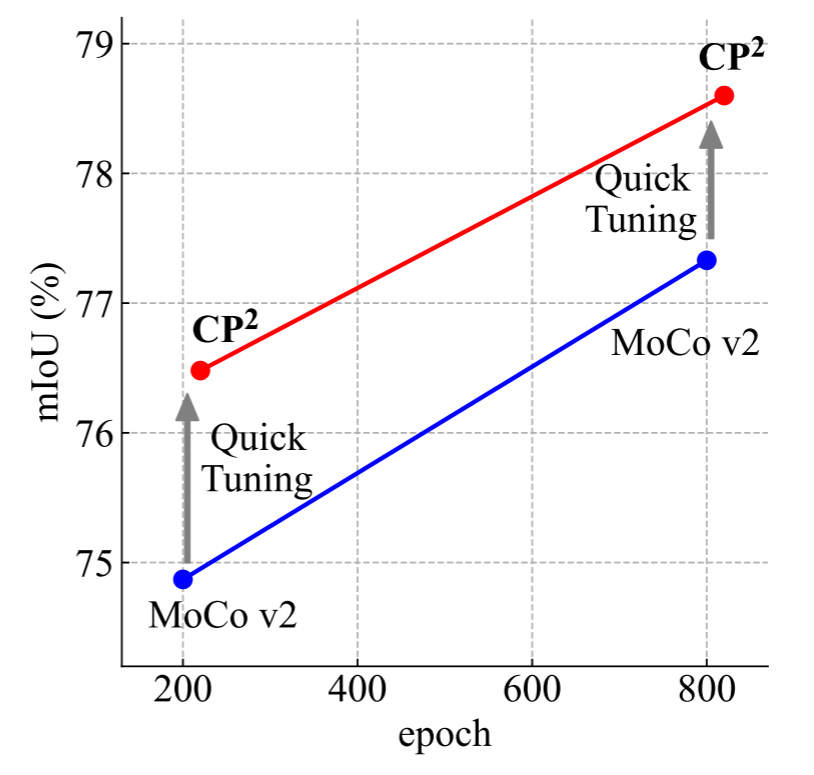
图1: 通过对PASCAL VOC的语义分割评估,使用CP2快速调整MoCo v2。使用CP2的20个波段的快速调整产生了巨大的mIoU改进。
此外,我们发现在相当短的时间内,CP2训练能够使预先训练的面向分类的模型快速适应语义分割任务,从而产生更好的下游性能。 特别地,我们首先用一个预先训练过的面向分类的模型(例如由MOCO V2[12]预先训练过的Resnet-50[29])的权重初始化主干,附加一个随机初始化的分割头,然后用CP2对整个分割模型进行额外的20个周期的调整。 结果,整个分割模型在下游语义分割上的性能显著提高了miou(%),例如Pascal VOC 2012[23]数据集上的+1.6%miou。 我们将该训练协议称为快速调谐,因为它可以有效地将学习从图像级的实例识别转移到像素级的密集预测。
对于技术细节,我们主要遵循MOCO V2[12],包括它的体系结构、数据增强和实例对比丢失,以便完全隔离我们新引入的复制粘贴机制和密集对比丢失的有效性,因此MOCO V2[12]作为CP2的直接基线。 在语义切分的实证评价中,CP2 200-epoch模型在Pascal VOC 2012[23]上的MIOU为77.6%,比MOCO V2[12]200-epoch模型的MIOU高出+2.7%。 此外,如图1所示,CP2的快速调优协议比MOCO V2200-epoch和800-epoch模型分别产生了+1.5%和+1.4%的MIOU改进。 该改进也可推广到其他分割数据集和视觉变换中。
2. 相关工作
自我监督学习和代理任务。 视觉理解的自监督学习利用图像的内在特性作为训练的监督信息,而视觉表征的能力在很大程度上依赖于托词任务的制定。 在实例识别[2,44,47,28]流行之前,人们已经探索了许多借口任务,包括图像去噪和重建[39,51,3]、对抗学习[19,20,22]以及启发式任务,如图像彩色化[50]、拼图[36,43]、上下文和旋转预测[18,33]和深度聚类[4]。
对比学习的出现,或者更具体地说,实例判别方案[2,44,47,28]的出现,在无监督学习中取得了突破,因为MOCO[28]在广泛的下游任务中取得了比监督训练更好的迁移性能。 受这一成功的启发,许多后续工作对自监督对比学习进行了更深入的探索,提出了不同的优化目标[26,41,42,5,6,54]、模型结构[13]和训练策略[10,12,14]。
密集对比学习。 为了在密集预测任务中获得更好的自适应,最近的一项工作[37]将图像级的对比度损失扩展到像素级。 尽管对比损失的扩展有助于模型学习更细粒度的特征,但它无法建立模型对空间变化信息的感知,因此模型必须在下游精细化中重新设计。 最近的一些工作试图通过鼓励像素级表示的一致性[45],或者通过使用启发式掩码[24,1]和应用片状对比损失[30]来增强模型对图像中位置信息的理解。
复制粘贴的对比性学习。复制粘贴,即复制一张图片的裁剪并粘贴到另一张图片上,曾经作为监督下的实例分割和语义分割中的一种数据增强方法[25],因为它的简单性和丰富图片的位置和语义信息的显著效果。同样,通过混合图像[49,31]或图像裁剪[48]作为数据增强,监督模型在各种任务中也获得了相当大的性能改进。在最近的自监督物体检测的工作中也报道了复制粘贴的使用[46,30]。受复制粘贴成功的启发,我们在密集对比学习方法中利用这种方法作为自我监督信息。
3. 方法
在这一节中,我们给出了我们的CP2目标和损失函数,用于学习像素级稠密表示。 我们还讨论了我们的模型体系结构,并提出了一个快速调整协议来有效地训练CP2。
3.1 复制粘贴对比预训练
我们提出了一种新的预训练方法CP2,通过该方法,我们希望预训练的模型能够学习实例识别和密集预测。
为此,我们通过将前景作物粘贴到背景上来人工合成图像组成。 具体来说,如图2所示,我们从前景图像生成两个随机作物,然后将它们覆盖到两个不同的背景图像上。
CP2的目标是:1)区分每个合成图像中的前景和背景;2)从阴性样本中识别具有相同前景的合成图像。
3.1.1 复制-粘贴
给定一个原始的前景图像 I f o r e I^{fore} Ifore,我们首先通过数据增强生成它的两个不同的视图 I q f o r e , I k f o r e ∈ R 224 × 224 × 3 \boldsymbol{I}_{q}^{f o r e},\boldsymbol{I}_{k}^{f o r e}\in\mathbb{R}^{224\times224\times3} Iqfore,Ikfore∈R224×224×3,一个是查询,另一个是正关键。增强策略遵循SimCLR[10]和MoCo v2[12],即首先将图像随机调整大小并裁剪为 224 × 224 224\times224 224×224的分辨率,然后进行颜色抖动、灰度、高斯模糊和水平翻转。
接下来,我们用同样的增强方法为两幅随机背景图像各生成一个视图,表示为 I q b a c k , I k b a c k ∈ R 224 × 224 × 3 \boldsymbol{I}_q^{b a c k},\boldsymbol{I}_k^{b a c k}\in\mathbb{R}^{224\times224\times3} Iqback,Ikback∈R224×224×3。
我们通过二进制前景-背景掩码
M
q
,
M
k
∈
{
0
,
1
}
224
×
224
\boldsymbol{M}_{q},\boldsymbol{M}_{k}\in\{0,1\}^{224\times224}
Mq,Mk∈{0,1}224×224组成图像对,其中每个元素
m
=
1
m=1
m=1表示一个前景像素,
m
=
0
m=0
m=0表示一个背景像素。从形式上看,组成的图像是通过以下方式产生的
I
q
=
I
q
f
o
r
e
⊙
M
q
+
I
q
b
a
c
k
⊙
(
1
−
M
q
)
,
I
k
=
I
k
f
o
r
e
⊙
M
k
+
I
k
b
a
c
k
⊙
(
1
−
M
k
)
,
\begin{gathered} \boldsymbol{I}_{q}=\boldsymbol{I}_{q}^{f o r e}\odot\boldsymbol{M}_{q}+\boldsymbol{I}_{q}^{b a c k}\odot(1-\boldsymbol{M}_{q}), \\ \boldsymbol{I}_{k}=\boldsymbol{I}_{k}^{f o r e}\odot\boldsymbol{M}_{k}+\boldsymbol{I}_{k}^{b a c k}\odot(1-\boldsymbol{M}_{k}), \end{gathered}
Iq=Iqfore⊙Mq+Iqback⊙(1−Mq),Ik=Ikfore⊙Mk+Ikback⊙(1−Mk),
其中
⊙
\odot
⊙表示元素乘积。 现在我们得到两个合成图像
I
q
I_q
Iq和
I
k
I_k
Ik,它们共享前景源图像,但背景不同。
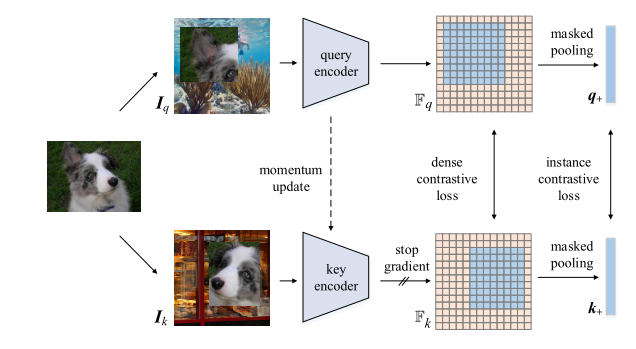
图2:通过将两组前景图像随机粘贴到不同的背景上,丰富了未标注图像的空间信息。 密集对比损失应用于其编码特征映射,实例对比损失应用于前景特征向量的平均值(掩蔽池)。 我们遵循MOCO和BYOL中动量更新的训练架构。
3.1.2 对比目标
然后用语义分割模型对合成的图像进行处理,我们在第3.2节中详细介绍了该模型。
给定输入 I q I_q Iq,分割模型的输出是一组 r × r r\times r r×r特征 F q = { f q i ∈ R C ∣ i = 1 , 2 , … , r 2 } \mathbb{F}_{q}=\{\pmb{f}_{q}^{i}\in\mathbb{R}^{C}|i=1,2,\ldots,r^{2}\} Fq={fqi∈RC∣i=1,2,…,r2},其中 C C C是输出通道数, R R R是特征映射分辨率。 对于 224 × 224 224\times224 224×224的输入图像,当输出步幅 s = 16 s=16 s=16时, r = 14 r=14 r=14。
在所有的输出特征 f q ∈ F q {\boldsymbol{f}}_{q}\in\mathbb{F}_{q} fq∈Fq中,我们将前景特征,即与前景像素相对应的特征称为 f q + ∈ F q + ⊂ F q \boldsymbol{f}_{q}^{+}\in\mathbb{F}_{q}^{+}\subset\mathbb{F}_{q} fq+∈Fq+⊂Fq,其中 F q + \mathbb{F}_q^{+} Fq+是前景特征子集。 同样地,我们得到了输入图像 I k I_k Ik的所有特征 f k ∈ F k {\boldsymbol{f}}_{k}\in\mathbb{F}_{k} fk∈Fk,其中前景特征表示为 f k + ∈ F k + ∼ ⊂ F k {\boldsymbol{f}}_{k}^{+}\in\mathbb{F}_{k}^{+}\sim{\subset}\mathbb{F}_{k} fk+∈Fk+∼⊂Fk。
我们使用了两个损耗项,一个是密集对比损耗,一个是实例对比损耗。 对比损失 L d e n s e \mathcal{L}_{dense} Ldense通过区分前景和背景特征来学习局部的细粒度特征,帮助完成下游的语义分割任务,而实例对比损失则旨在保持全局的实例级表示。
在密集对比损失中,我们希望图像 I q I_q Iq的所有前景特征 ∀ f q + ∈ F q + \forall f_q^+\in\mathbb{F}_q^+ ∀fq+∈Fq+与图像 I k I_k Ik的所有前景特征 ∀ f k + ∈ F k + \forall\boldsymbol{f}_k^+\in\mathbb{F}_k^+ ∀fk+∈Fk+相似,并且与图像Ik的背景特征 F k − = F k ∖ F k + \mathbb{F}_k^-=\mathbb{F}_k\setminus\mathbb{F}_k^+ Fk−=Fk∖Fk+不相似。
形式上,对于每个前景特征
∀
f
q
+
∈
F
q
+
\forall\boldsymbol{f}_{q}^{+}\in\mathbb{F}_{q}^{+}
∀fq+∈Fq+和
∀
f
k
+
∈
F
k
+
\forall\boldsymbol{f}_{k}^{+}\in\mathbb{F}_{k}^{+}
∀fk+∈Fk+,密集对比损失由以下方式得到
L
d
e
n
s
e
=
−
1
∣
F
q
+
∣
∣
F
k
+
∣
∑
e
f
q
+
∈
F
q
+
,
∀
f
k
+
∈
F
k
+
log
exp
(
f
q
+
⋅
f
k
+
/
τ
d
e
n
s
e
)
∑
∀
f
k
∈
F
k
exp
(
f
q
+
⋅
f
k
/
τ
d
e
n
s
e
)
,
\mathcal{L}_{d e n s e}=-\frac{1}{|\mathbb{F}_{q}^{+}||\mathbb{F}_{k}^{+}|}\sum_{\mathcal{e f}_{q}^{+}\in\mathbb{F}_{q}^{+},\forall\mathcal{f}_{k}^{+}\in\mathbb{F}_{k}^{+}}\log\frac{\exp\left(\boldsymbol{f}_{q}^{+}\cdot\boldsymbol{f}_{k}^{+}/\tau_{d e n s e}\right)}{\sum_{\forall\boldsymbol{f}_{k}\in\mathbb{F}_{k}}\operatorname{exp}\left(\boldsymbol{f}_{q}^{+}\cdot\boldsymbol{f}_{k}/\tau_{d e n s e}\right)},
Ldense=−∣Fq+∣∣Fk+∣1efq+∈Fq+,∀fk+∈Fk+∑log∑∀fk∈Fkexp(fq+⋅fk/τdense)exp(fq+⋅fk+/τdense),
其中
τ
d
e
n
s
e
τ_{dense}
τdense是温度系数。 图3也说明了这种密集的对比损失。 遵循监督对比学习方法[32,52],我们把总和放在日志之外。
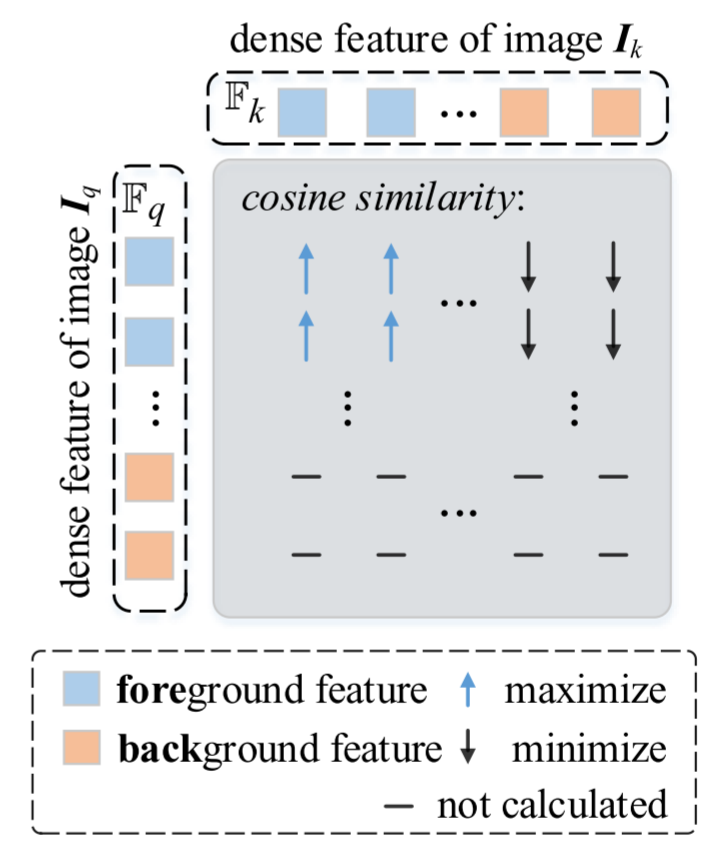
密集对比损失,使每个前景对的相似性最大化,同时使每个前景背景对的相似性最小化。
除了密集的对比损失,我们保留了实例对比损失,目的是学习全局的、实例级的表示。 我们主要遵循MOCO[28,12]的实践,在给定查询图像的情况下,需要该模型来区分正键和负键的存储库。 但是在我们的例子中,我们使用合成图像
I
q
I_q
Iq作为查询图像,并使用合成图像
I
k
I_k
Ik作为与图像
I
q
I_q
Iq共享前景的正关键图像。 此外,我们不使用全局平均池特性作为MOCO中的表示,而是只使用前景特征的归一化屏蔽平均,如图2所示。 形式上,实例对比损失计算如下
L
i
n
s
=
−
log
exp
(
q
+
⋅
k
+
/
τ
i
n
s
)
exp
(
q
+
⋅
k
+
/
τ
i
n
s
)
+
∑
n
=
1
N
exp
(
q
+
⋅
k
n
/
τ
i
n
s
)
,
\mathcal{L}_{ins}=-\log\frac{\exp(\mathbf{q}_+\cdot\mathbf{k}_+/\tau_{ins})}{\exp(\mathbf{q}_+\cdot\mathbf{k}_+/\tau_{ins})+\sum_{n=1}^N\exp(\mathbf{q}_+\cdot\mathbf{k}_n/\tau_{ins})},
Lins=−logexp(q+⋅k+/τins)+∑n=1Nexp(q+⋅kn/τins)exp(q+⋅k+/τins),
其中
q
+
,
k
+
\boldsymbol{q_{+}},\boldsymbol{k_{+}}
q+,k+是
F
q
+
\mathbb{F}_{q}^{+}
Fq+和
F
k
+
\mathbb{F}_k^+
Fk+的归一化掩蔽平均:
q
+
=
∑
∀
f
q
+
∈
F
q
+
f
q
+
∣
∣
∑
∀
f
q
+
∈
F
q
+
f
q
+
∣
∣
2
,
k
+
=
∑
∀
f
k
+
∈
F
k
+
f
k
+
∣
∣
∑
∀
f
k
+
∈
F
k
+
f
k
+
∣
∣
2
.
\begin{aligned} \\ \boldsymbol{q} _{+}=\frac{\sum_{\forall f_{q}^{+}\in\mathbb{F}_{q}^{+}}\boldsymbol{f}_{q}^{+}}{||\sum_{\forall f_{q}^{+}\in\mathbb{F}_{q}^{+}}\boldsymbol{f}_{q}^{+}||_{2}},\boldsymbol{k}_{+}=\frac{\sum_{\forall f_{k}^{+}\in\mathbb{F}_{k}^{+}}\boldsymbol{f}_{k}^{+}}{||\sum_{\forall\boldsymbol{f}_{k}^{+}\in\mathbb{F}_{k}^{+}}\boldsymbol{f}_{k}^{+}||_{2}}. \end{aligned}
q+=∣∣∑∀fq+∈Fq+fq+∣∣2∑∀fq+∈Fq+fq+,k+=∣∣∑∀fk+∈Fk+fk+∣∣2∑∀fk+∈Fk+fk+.
k n k_n kn表示来自n个向量的存储体[28,44]的负样本的表示,τins是温度系数
总损失L简单地是密集和实例对比损失的线性组合
L
=
L
i
n
s
+
α
L
d
e
n
s
e
,
\mathcal L=\mathcal L_{ins}+\alpha\mathcal L_{dense},
L=Lins+αLdense,
其中α是两种损失的折中系数。
3.2 模型体系结构
接下来,我们将详细讨论我们的 C P 2 CP^2 CP2模型架构,它由一个骨干和一个分割头组成,用于预训练和微调。与现有的对比学习框架[28,12]只对骨干进行预训练不同,CP2能够对骨干和分割头进行预训练,与下游分割任务使用的架构几乎相同。通过这种方式, C P 2 CP^2 CP2防止了微调错位问题(第1节),即用经过预训练的骨干和随机初始化的头对下游模型进行微调。这种错位可能需要仔细的超参数调整(例如,头部的学习率较大),并导致传输性能下降,特别是在使用重度随机初始化头部时。因此, C P 2 CP^2 CP2能够实现更好的分割性能,也能够使用更强的分割头。
特别是,我们研究了两个系列的骨干,CNNs[29]和ViT[21]。对于CNN骨干,我们使用原始的ResNet-50[29],用7×7卷积作为第一层,而不是常用于分割任务的inception stem 。这种设置确保了与以前的自监督学习方法进行公平的比较。为了使ResNet骨干适应分割,我们遵循常见的分割设置[7,8,28],并在最后阶段的3×3卷积中使用atrous rate 2和stride 1。对于ViT骨干,我们选择了ViT-S[21],其补丁大小为16×16,它的参数数量与ResNet-50相似。请注意,我们的ResNet-50和ViT-S都有一个输出stride s = 16,这使得我们的骨干网与大多数现有的分割头兼容。
鉴于骨干输出特征的输出跨度s=16,我们研究两种类型的分割头。默认情况下,我们采用常见的DeepLab v3[8]分割头(即带有图像池的ASPP头),因为它能够提取多尺度的空间特征并产生非常有竞争力的结果。除了DeepLab v3 ASPP头之外,我们还研究了通常用于评估自监督学习方法的轻型FCN头[34]。
在为预训练和微调而训练的骨干和分割头的基础上,我们尽可能地少做改动。具体来说,对于 C P 2 CP^2 CP2预训练,我们在分割头的输出上增加了两个1×1的卷积层,将像素上的密集特征投射到一个128维的潜空间(即C=128)。然后,每个像素的潜伏特征被单独 ℓ 2 \ell_2 ℓ2归一化。我们的密集投影设计类似于常见的对比学习框架中的2层MLP设计[12],然后进行 ℓ 2 \ell_2 ℓ2。在 C P 2 CP^2 CP2训练收敛后,我们简单地用分割输出卷积代替2层卷积投影,将分割头特征投射到输出类的数量上,类似于图像对比框架的典型设计[28,10]。按照MoCo[28],我们通过查询编码器中的权重来更新由骨干和分割头组成的关键编码器。
3.3 快速调优
为了在可管理的计算预算内快速训练我们的CP2模型,我们提出了一个新的训练协议,称为快速调整,用现有的骨干检查点在线初始化我们的骨干。这些骨干通常是通过图像对比损失来训练的,时间表非常长(例如,800个历时[12]或1000个历时[10])。在这些现有的编码良好的图像级语义表征的检查点之上,我们应用我们的CP2训练,只需几个历时(例如,20个历时),以微调仍然在ImageNet上没有人类标签但用于语义分割的表示。具体来说,我们在预训练的骨干上附加一个随机初始化的分割头,并以适当的曲率来训练整个分割模型,使用我们的CP2损失函数。最后,在ImageNet上学习到的不使用任何标签的分割模型在各种下游分割数据集上进一步微调,以评估学习到的表征。
快速调谐能够为自监督对比学习提供高效实用的训练,因为它利用了大量训练过的自监督骨干,让它们快速适应所需的目标或下游任务。根据我们的经验评估,20个历时的快速调谐足以在各种数据集上产生显著的改善(例如,在PASCAL VOC 2012上的微调mIoU经过20个历时的快速调谐后,改善了1.6%)。这对有效地预训练分割模型特别有帮助,因为分割模型由于主干和ASPP模块的迂回卷积,在计算成本上通常比主干要重得多。在这种情况下,快速调谐通过短时间的分割模型自我监督预训练表现出明显的改善,节省了大量的计算资源。