为什么需要分片
在服务端领域,主要特点是支撑7*24小时不间断的服务,而最终对各种行为会生产对应的数据,比如用户登陆/注册,发起订单交易、支付、身份验证,短信验证等情况都需要存储起来,其中包括各种各样的数据,而采用格式的存储中间件进行保存数据,可以有效的进行数据查询和存储,比如MySQL支持关系型数据的存储,Redis支持NoSQL,ES支持快速查询等。但是如果只是单实例的话,其实存储的数据是有上限的,即使将一台机器从PC->小型机->大型机,所能存储的数据还是有上限的。所以分片或者分区的本质是为了解决单机存储和性能瓶颈带来的问题,让分布式系统的计算和存储能力可以线性扩展。而数据复制解决的是数据的高可用。
好了既然说明白为什么需要数据分片,那么有哪些形式的数据分片呢?
水平分片/ 垂直分片 / 混合分片
其实目前业界比较主流的分片主要就是水平、垂直、混合三种模式。
水平分片
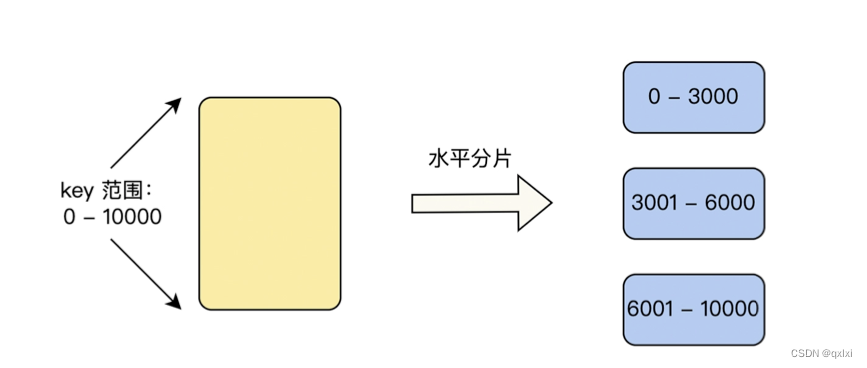
水平分片是将数据按照水平进行切分数据,比如原来有1000W数据,但是采用水平分片后,可以切分出3个表,第一个表存储前3000W数据,第二个表存储3000W-6000W数据,第三个表存储最后4000W数据。这样就可以实现将单机的存储进行分摊到不同的实例上。
垂直分片
相对于水平分片来说,垂直分片其实按照列进行切分,比如一个用户表,按照用户id 年龄、性别、体重等进行切分,这种方式按照不同的数据纬度记性切分和保存。但是在数据查询的时候是非常困难,如果设计多个表之间的查询,所以就需要开发出一个数据代理中间件来解决这个问题,而对于中小型公司来说,是不需要垂直分片。在初期,会使用读写分离的数据镜像方式,而后期会采用分库分表的方式。而分库分表的方式大多数也都是采用水平分片的方式。所以说这种方式了解即可。
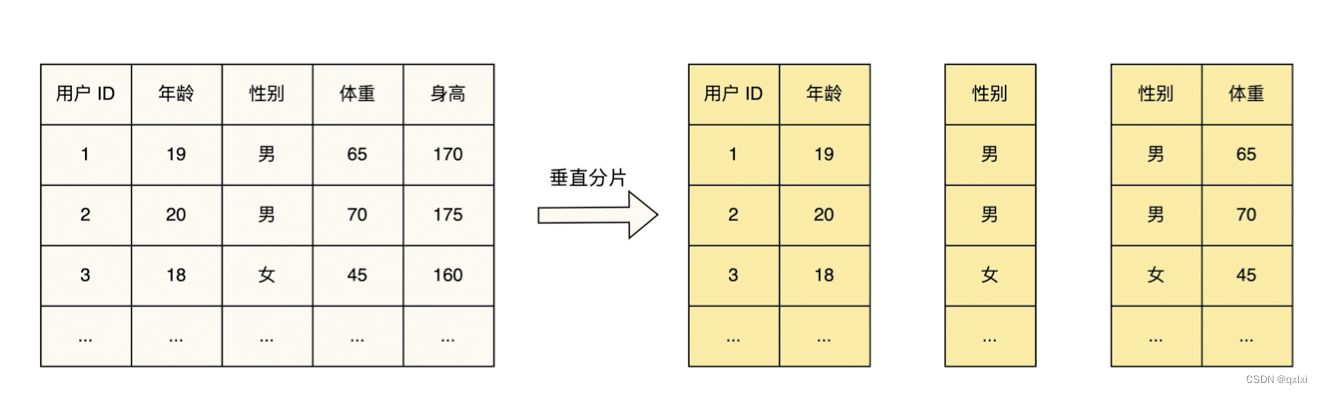
混合分片
混合分片其实就是垂直和水平两种结合,一种是垂直在水平,另一种是先水平在垂直。
水平分片算法
1.范围分片
水平划分其实就是按照数据的一个范围进行划分,比如说存储中国所有人的身份证信息,就是按照省市区级别,分别存储到对应的户籍所在地。这样的方式比较好管理,也方便查询。但是缺点就是数据分布不会平均,比如北京的密度和山西的密度就不是一个数量级。一个是直辖市2000多W的人口,一个是省级3000多W的人口。
优点:可以按照范围快速查找数据。
缺点:数据分布不均匀,数据的存储和访问不均匀。
2.哈希分片
Hash分片其实比较简单,比如用身份证的或者手机号进行数据取余数,比如100个数据库,那么余数是几,就存储到第几号数据库中,这样数据比较分散,但是范围查询不支持,因为只能通过关键字key进行查询。
优点:数据分布存储和查询比较均匀。
缺点:不支持范围查询。其实哈希分片这里还有一个隐藏的问题,如果存储的节点是不固定的话,可能存在删除或者添加节点的情况,那么就会导致整体数据的key需要重新计算。而这个计算和存储是非常耗费性能和资源。那么如何解决的呢?使用一致性哈希
如何选择呢?其实不管是范围分片还是哈希分片,都需要建立的所在业务数据了解的前提下进行选择。如果了解具体业务数据可以根据具体情况决定,但是不了解的话,推荐还是使用哈希分片进行存储,这样不论是数据分布还是访问都不会出现热度不均匀的情况。
3.一致性哈希分片
首先声明下 一致性哈希所解决的问题是用来解决分布式存储中哈希分区删除或者增加节点导致数据大规模移动的问题,是一种特殊的哈希分片算法。在各种存储中间件中,也会出现节点的下线和上线,所以为保证数据可以均匀的落在每个节点上,在发生节点删除和增加的时候,不会出现大规模数据访问和迁移的情况。就需要引入一致性哈希。
核心原理
一致性哈希的原理比较好理解,使用一个哈希函数,构建出一个虚拟环,每个节点都存储在环上。比如Node0、Node1、Node2等。按照顺时针的方向,比如key1存储在Node0上,key2存储在Node2上。
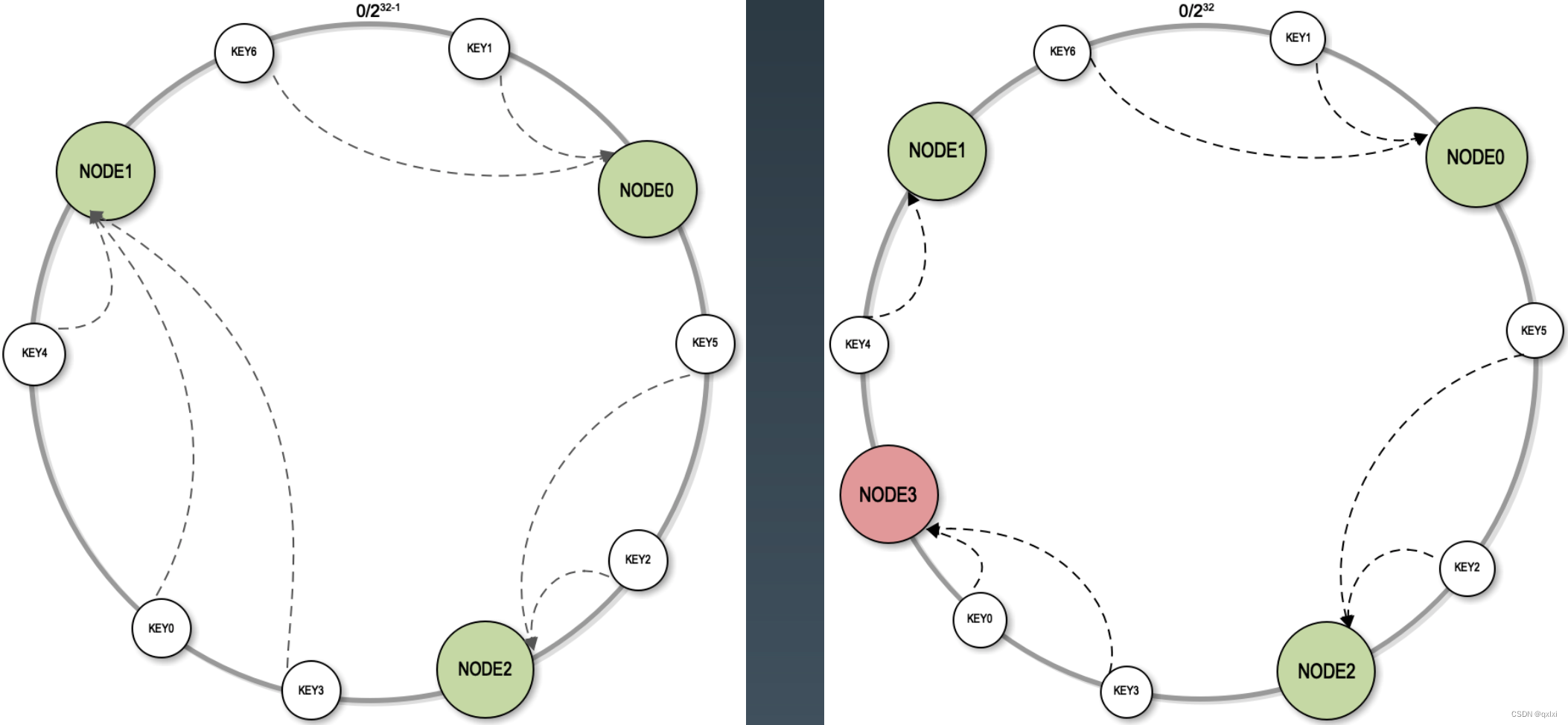
当出现Node3节点宕机下线时,原本存储在Node3中的数据会按照顺时针的方向落在Node1上,所以即使出现节点的下线和增加节点的情况,也只会影响一部分的节点。但是当出现节点数比较少的时候,那么都会集中趋向于其中几台机器。这样时候并不能很好的数据分布均匀。
基于虚拟节点的一致性哈希算法
其实就是在整个环中将节点的副本构建多个,平均去分担其中的流量,比如Node0 拷贝出2个,分别是Node 0 1 2。那么即使出现下线,也会比较均匀的分布式其中环中的节点上。可以很好的实现数据存储负载的均衡性。

实际应用
本篇主要介绍了数据存储的分片机制中的几种常见机制,垂直分片、水平分片、混合形式,但是一般常用的方式是采用垂直分片,垂直分片中范围分片、哈希分片,但是哈希分片存在节点的删除和增加导致数据的重新hash,所以进一步进入了一致性哈希,以及基于虚拟界定的一致性哈希算法。
在具体的实际应用中,mysql、redis、Kafka其实都有对应的分片机制,redis中为保证可以存储更多的数据,使用了切片集群的方式。通过使用不同的slot存储数据。具体可以参考 redis切片集群的原理,而kafka中为了保证消息写入Broker的存储高性能,也采用分片机制存储数据。比如将一个消息ABC,会进行存储到不同的broker节点上,保证数据的高性能。Kafka topic分区机制原理,当然了,其实其他的存储中间件也肯定有相关的机制,这个后边学到别的在进行统一汇总。