正文
1. 页面加载时间线
我们先来一个老生常谈的面试题:从输入 URL 到页面加载完成的过程中都发生了什么事情? 这个面试题本身也是一个开放题,不同方向的工程师侧重也不一样。大抵的过程可以简化为: st=>start: 输入URL e=>end: 呈现页面 op1=>operation: 发起请求:URL解析/DNS解析 op2=>operation: 网络连接:三次握手 op3=>operation: 服务器响应请求:返回数据 op4=>operation: 客户端接收响应:浏览器加载/渲染页面 st->op1->op2->op3->op4->e 本文主要关注的是倒数两个过程。期间我们将要分析浏览器并行、串行执行了那些操作,以及根据这些操作我们能够如何优化首屏的加载。
2. 浏览器内部发生了什么?
2.1 了解浏览器组成
浏览器主要由7个部分组成:用户界面(User Interface)、浏览器引擎(Browser engine)、渲染引擎(Rendering engine)、网络(Networking)、JavaScript解释器(JavaScript Interpreter)、用户界面后端(UI Backend)、数据持久化(Data Persistence)。

图中箭头表示调用相关模块的接口关系,箭头指向表示调用该模块 用户界面:定义了一些常用的浏览器组件,比如地址栏,返回、书签等等 数据持久化:指浏览器的cookie、local storage等组件 浏览器引擎:平台应用的相关接口,在用户界面和呈现引擎之间传送指令。 渲染引擎:处理HTML、CSS的解析与渲染 JavaScript解释器:解析和执行JavaScript代码 UI后端:指浏览器的的图形库等 网络:用于网络调用,比如HTTP请求
问题:Webkit与V8有什么关系?
Webkit的祖师爷是Safari,是浏览器引擎,而V8的是老爸是Google,是JavaScript解释器引擎。在上图中,我们看到Webkit其实是包含JavaScript解释器的,但是Google觉得这个解释器还要很多优化的空间,于是就单独开发了一个V8,Chrome在运行的时候其实直接调用了V8。(PS. Webkit其实有很多分支,腾讯的X5也是一个,这些分支对Webkit进行了优化和补充,不过Chrome里面具体保留了哪些,丢弃了哪些,我也不知道==)
2.2 浏览器渲染流程
浏览器渲染的流程分为四步:解析HTML为DOM树;渲染树结构;布局渲染树、绘制渲染树。

2.2.1 解析HMTL为DOM树
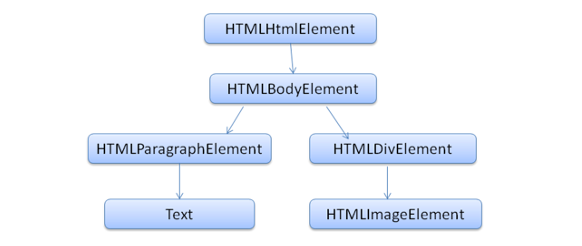
这个过程实际上包括HTML的解析和CSS的解析。 HTML的解析分为两个过程,词法解析和语法解析。如果我们把一段代码比喻成一段英文,词法解析的作用就相当于把一段英文拆成一个一个单词;语法解析相当于分析这段英文的各种语法结构。
<html> <body> <p>Hello World</p> <div><img src="example.png"/></div> </body> </html>
CSS解析比较容易,根据CSS规范中词法和语法,调用解析器生成器(只要向其提供您所用语言的词汇和语法规则,它就会生成相应的解析器),生成解析器后就可以进行解析了。
p,div { margin-top: 3px; } .error { color: red; }
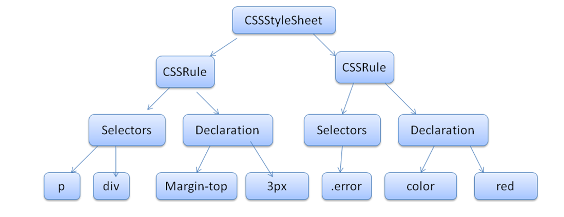
2.2.2 渲染树结构
构建完DOM树后,开始对每一个DOM元素进行渲染。我们可以用CSS的盒模式来理解:每一个DOM元素对应一个盒子,每个盒子对应CSS属性,渲染树结构的过程就是把每个盒子都“装扮”完。
2.2.3 布局渲染树
每个盒子“装扮”完,接着就把盒子装配到浏览器上,即这个过程确定每个盒子对应的浏览器坐标。
2.2.4 绘制渲染树
这个过程就将所有的元素绘制到浏览器上了。
2.3 HTML、CSS、JavaScript的顺序
这里引用一段代码来解释可能更加清楚一些:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Demo</title> <link rel="stylesheet" href="./style1.css"> </head> <body> <P>Hello Tencent!</P> <section> Hello weixin!</section> <img src="./apple.jpg" /> <script src="./main1.js"></script> </body> </html>
上述代码是最普通也是最简单的一个HTML模板页面,也遵循了样式表置于head、脚本置于与底端这些基本准则,下面我们来分析一下浏览器如何按时间一步一步的加载出这个页面:
浏览器接收到HTML模板文件,开始从上到下依次解析HTML; 遇到样式表文件style1.css,这时候浏览器停止解析HTML,接着去请求CSS文件; 服务端返回CSS文件,浏览器开始解析CSS; 浏览器解析完CSS,继续往下解析HTML,碰到DOM节点,解析DOM; 浏览器发现img,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码; 服务器返回图片文件,由于图片占用了一定面积,影响了页面排布,因此浏览器需要回过头来重新渲染这部分代码; 碰到脚本文件,这时停止所有加载和解析,去请求脚本文件,并执行脚本; 加载完所有的HTML、CSS、JS后,页面就出现在屏幕上了。 现代浏览器的优化策略及注意事项 上述的描述是为了更好的理解,实际上现代浏览器都做了一些优化,我们在看
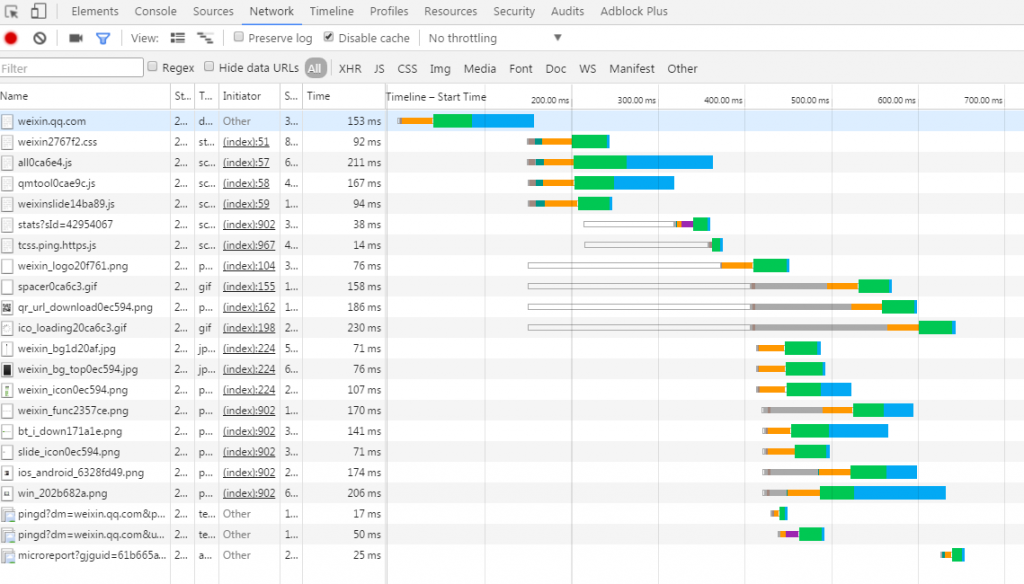
浏览器支持并行下载静态文件(只是下载文件),所以当浏览器解析到某个css文件或者js文件时,可能该文件已经缓存在浏览器里了。PS. 不同的浏览器并行加载的资源数不一样,一般在2-8个之间。 实际上,浏览器边加载HTMl、CSS,边解析; CSS放在head里面是为了浏览器更早的渲染页面,放在页面底部,可能造成短暂的无样式页面或者白屏的现象; 浏览器在加载、执行JavaScript脚本时,会停止页面的解析过程,包括HTML、CSS,所以通常我们将JS放在页面底部,特别是不是首屏必须加载的JavaScript脚本,可以采用延迟加载或者异步的方式。
PS. 延迟加载和异步加载的区别:

3. 首屏优化加载
弄清楚了浏览器的加载的原理和过程,我们就明白了从哪些方面来优化首屏的加载啦。
减少首屏CGI的计算量:比如在微信8.8无现金日中,前端希望拿到用户的个人信息、消费记录、排名三类数据,如果只通过一个CGI来处理,那么后台响应时间肯定会变长;由于在H5的首屏中,只包含了用户信息,消费记录、排名都在第2屏和第3屏,此时其实可以利用异步的方式来拿消费记录、排名的数据。 页面瘦身:压缩HTML、CSS、JavaScript。 减少请求:CSS、JavaScript文件数尽量少,甚至当CSS、JS的代码不多时,可以考虑直接将代码内嵌到页面中。 多用缓存:缓存能大幅度降低页面非首次加载的时间。 少用table布局,浏览器在渲染table时会消耗较多资源,而且只有table里有一点变化,整个table都会重新渲染。 做预加载:部分H5页面首屏可能要下载较多的静态资源,比如图片,这时为了避免加载时出现“难看”的页面,用预加载(loading的方式)做一个过渡。
4.附录
什么是白屏和FOUC(无样式内容闪烁)? 不同的浏览器对于CSS和HTML的处理方式不同,有的是等待CSS加载完成之后,对HTML元素进行渲染和展示(白屏问题)。有的是先对HTML元素进行展示,然后等待CSS加载完成之后重新对样式进行修改(FOUC无样式内容闪烁)