文章目录
- 1. 网络基础 TCP/IP
- 2. 与HTTP密切相关的协议
- 2.1 负责传输的 IP 协议
- 路由选择
- 2.2 确保可靠性的 TCP 协议
- 三次握手
- 2.3 负责域名解析的 DNS 服务
- 2.4 各种协议和 HTTP 协议的关系
- 3. URL和编码问题
- 3.1 介绍
- 格式
- 3.2 编码问题
- 4. 初识 HTTP 协议
- 4.1 C-S 模式
- 4.2 通过响应和请求实现通信
- 4.3 请求和响应格式
- 请求格式
- 响应格式
- 4.4 分离报文中的有效载荷
- 4.5 初识HTTP
- 测试
- 4.6 构建响应
- 网根目录
- 字符串分割
- 完善 HTTP 请求处理函数
- 5. HTTP 方法
- 5.1 GET和POST
- 测试
- 表单
- 6. HTTP 状态码
- 6.1 重定向
- 永久性重定向
- 临时性重定向
- 302(Found)
- 307(Temporary Redirect)
- 重定向测试
- 7. HTTP Header
- 7.1 介绍
- 格式
- 类型
- 7.2 常见 Header
- Content-XX
- Host
- User-Agent
- Referer
- Keep-Alive
- 8. 会话管理
- 8.1 HTTP 是不保存状态的协议
- 8.2 使用 Cookie 的状态管理
- Set-Cookie Header
- Cookie 标记状态
- 安全问题
- 8.2 会话管理
- Session
- Session ID
- 8.3 只有相对的安全
- 8.4 测试
- 参考资料
- 8.4 测试
- 参考资料
1. 网络基础 TCP/IP
友情链接:网络基础入门
通常使用的网络(包括互联网)是在 TCP/IP 协议族的基础上运作的。而 HTTP 属于它内部的一个子集。
也就是说,HTTP通常运行在TCP之上。
协议(Protocol)是一种实现约定好的规则。对于进行网络通信的双方,想要保证通信方式的一致性,就要基于相同的方法。不论是网络通信还是硬件、操作系统之间的通信,都需要一个通信参与方都知晓的规则约束通信方式。
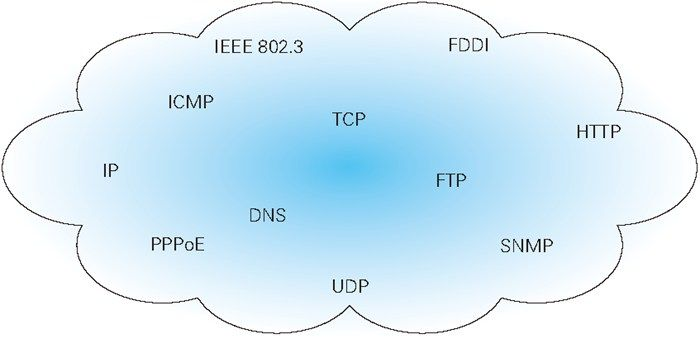
TCP/IP 是互联网相关的各类协议族的总称
协议中存在各式各样的内容。从电缆的规格到 IP 地址的选定方法、寻找异地用户的方法、双方建立通信的顺序,以及 Web 页面显示需要处理的步骤,等等。
像这样把与互联网相关联的协议集合起来总称为 TCP/IP。
也有说法认为,TCP/IP 是指 TCP 和 IP 这两种协议。还有一种说法认为,TCP/ IP 是在 IP 协议的通信过程中,使用到的协议族的统称。–《图解HTTP》
2. 与HTTP密切相关的协议
2.1 负责传输的 IP 协议
IP协议不同于IP地址,它是一种协议的名称(Internet Protocol)。IP协议的作用是将数据(包)传送给对端主机。这个过程需要烧录在物理设备上的MAC地址和IP地址协作完成。IP地址指明了节点被分配到的地址,MAC地址是指网卡所属的固定地址。IP地址可以和 MAC地址进行配对。IP地址可变换,但MAC地址基本上不会更改。
路由选择
在网络中的双方通过同一局域网(LAN)通信的情况占极少数,通常由多台计算机和网络设备中转后才能连接到对方。
在计算机网络中,数据包从源设备发送到目标设备的过程中,可能需要经过多个路由器进行转发。路由器是一种网络设备,它能够根据目标设备的IP地址,将数据包从一个网络转发到另一个网络。路由器通常会维护一个路由表,用于确定数据包应该从哪个接口进行转发。
当一台路由器收到一个数据包时,它会根据目标IP地址查找路由表,确定下一跳路由器,并将数据包转发到下一跳路由器。这个过程可能会在网络中经过多个路由器,直到数据包到达目标设备。而IP之间的通信依赖MAC地址。在数据被中转的过程中,每一个中转设备都是一环,它们无法知晓全局的传输情况,而对于当前中转设备,它的目标就是通过下一站中转设备的MAC地址来作为中转目标。这需要通过ARP协议(Address Resolution Protocol)。ARP是一种用以解析地址的协议,根据通信方的IP地址就可以反查出对应的MAC地址。
路由选择:
值得注意的是,每一个中转的设备都无法全面掌握网络上的传输情况,它们只能获取很粗略的传输路线。这个路线通常是指从源设备到目标设备的基本转发路径,包括起点和终点。路由器只知道数据包的目的地址和下一跳路由器的地址,而对于整个传输路径的细节,如中转路径中的所有设备、网络拓扑等信息,路由器无法获得完整的信息。这就是路由选择机制(routing)。
路由选择是指在计算机网络中,路由器通过选择最佳的路由路径将数据包从源设备转发到目标设备的过程。有点像快递公司的送货过程。想要寄快递的人,只要将自己的货物送到集散中心,就可以知道快递公司是否肯收件发货,该快递公司的集散中心检查货物的送达地址,明确下站该送往哪个区域的集散中心。接着,那个区域的集散中心自会判断是否能送到对方的家中。
在路由选择的过程中,路由器会根据自己的路由表,选择一个最佳的路由路径,将数据包转发到下一跳路由器,直到数据包到达目标设备。路由器选择最佳的路由路径通常基于多个因素,例如路由器与目标设备之间的网络拓扑、网络带宽、网络拥塞情况等。
为了选择最佳的路由路径,路由器通常会维护一个路由表,该表中包含了到达不同目标网络的路由路径信息。路由表中的路由路径信息可能是由网络管理员手动配置的,也可能是通过路由协议自动学习的。
路由选择是计算机网络中非常重要的一个过程,它直接影响了网络的性能和可靠性。一个好的路由选择算法可以减少网络延迟、提高带宽利用率、降低网络拥塞等问题,从而提高整个网络的性能和可靠性。
2.2 确保可靠性的 TCP 协议
TCP协议在传输层提供可靠的字节流服务。
所谓的字节流服务(Byte Stream Service)是指,为了方便传输,将大块数据分割成以报文段(segment)为单位的数据包进行管理。而可靠的传输服务是指,能够把数据准确可靠地传给对方。一言以蔽之,TCP 协议为了更容易传送大数据才把数据分割,而且 TCP 协议能够确认数据最终是否送达到对方。
可靠和不可靠是一个中性的词语,它描述的是服务的性质。
相比于UDP协议,它就是不可靠的协议,正因如此,它的传输速度往往很快,因为保证可靠性是需要代价的。
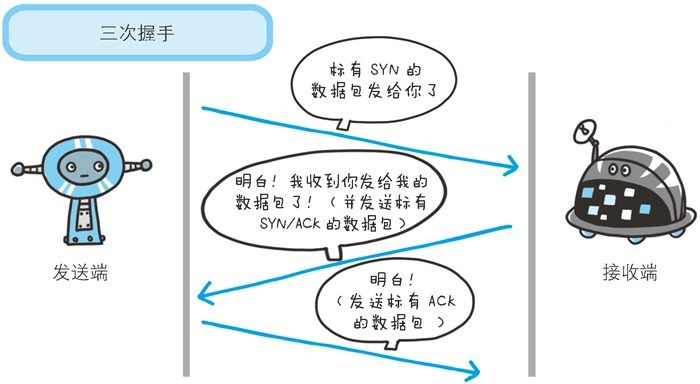
三次握手
双方在进行TCP通信之前需要先建立连接,建立连接的过程被称之为三次握手。
简要介绍握手过程,更深入的内容将在TCP协议专题介绍。
以下是TCP三次握手的简单介绍:
- 第一次握手:客户端向服务器发送一个SYN(同步)报文,指明客户端打算向服务器发起连接,并且随机选择一个初始序列号(ISN)。
- 第二次握手:服务器收到客户端的SYN报文后,向客户端发送一个SYN/ACK报文,表示确认客户端的请求,并且也指明服务器随机选择一个初始序列号。同时,服务器也向客户端发送一个确认号(ACK),该确认号为客户端的ISN+1。
- 第三次握手:客户端收到服务器的SYN/ACK报文后,向服务器发送一个ACK报文,表示确认收到了服务器的确认,并且也向服务器发送了一个确认号(ACK),该确认号为服务器的ISN+1。
至此,TCP连接建立完成,客户端和服务器可以开始进行数据传输。
三次握手的目的是确保客户端和服务器均已准备好进行数据传输,同时也确保了双方的初始序列号、确认号等信息正确无误。通过三次握手,TCP可以保证连接的可靠性和正确性,从而避免数据传输过程中的错误和丢失。
若在握手过程中某个阶段莫名中断,TCP 协议会再次以相同的顺序发送相同的数据包。
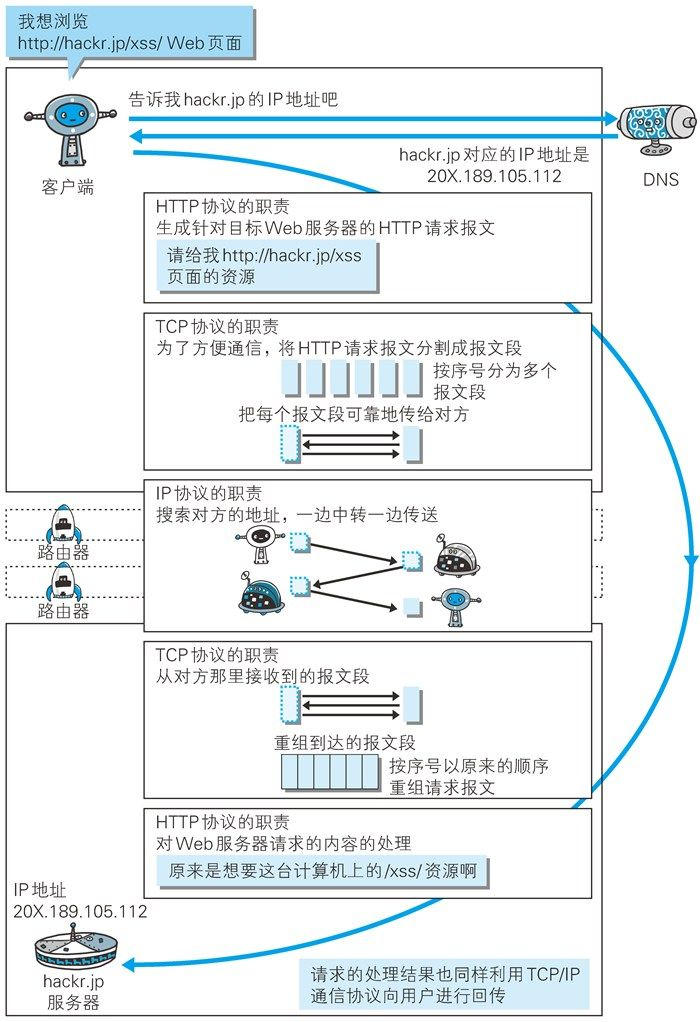
2.3 负责域名解析的 DNS 服务
DNS(Domain Name System)服务是和 HTTP 协议一样位于应用层的协议。它提供域名到 IP 地址之间的解析服务。
IP地址是计算机在网络中的标识,但不符合人类的使用习惯,也不方便记忆。因此DNS服务就相当于一张表,它保存了由字母数字组合的域名和IP地址之间的映射关系。当用户键入诸如www.baidu.com这样的域名,浏览器首先会通过DNS服务获取这个网址对应的IP地址,然后再通过IP地址访问服务端。
所谓DNS劫持就是非法地修改了域名和IP地址的映射关系,在真正获取到服务端的响应之前,用户是无感知的。
2.4 各种协议和 HTTP 协议的关系
通过以上对于HTTP协议密切相关的协议的简要介绍,HTTP协议和它们之间的关系大致如下:
3. URL和编码问题
3.1 介绍
URL/URL出现于DNS之后,当时Web还处于发展初期,Web页面通常只是简单的HTML文本文件。随着Web页面变得越来越复杂和丰富,需要一种更灵活和通用的标识方法来标识和访问各种资源。
URL(Uniform Resource Locator,统一资源定位符)和URI(Uniform Resource Identifier,统一资源标识符)都是用于标识互联网上资源位置和访问方式的标识符,它们之间有很紧密的关系,但是又有所区别。URL是URI的一种特定实现方式,它是用于标识Web页面等资源位置和访问方式的一种标准格式。URI则是一个更通用的概念,用于标识任何类型的资源位置和访问方式,包括URL在内。
- Uniform:规定统一的格式可方便处理多种不同类型的资源,而不用根据上下文环境来识别资源指定的访问方式。另外,加入新增的协议方案(如 http: 或 ftp:)也更容易。
- Resource:资源的定义是“可标识的任何东西”。除了文档文件、图像或服务(例如当天的天气预报)等能够区别于其他类型的,全都可作为资源。另外,资源不仅可以是单一的,也可以是多数的集合体。
- Identifier:表示可标识的对象。也称为标识符。
格式
我们通常对URL更熟悉,因此首先以它作为例子。
一个标准的URL通常由以下几部分组成:
URL = scheme “:” “//” authority path [ “?” query string] [ “#” fragment ]
// authority 表示资源所在的网络服务器的名称或 IP 地址,以及可选的端口
// path 表示资源在网络服务器上的位置
-
协议(Scheme):指定访问资源所使用的协议类型,例如http、https、ftp等。
-
主机名(Host):指定资源所在的服务器主机名或IP地址。
-
端口号(Port)[可选]:指定服务器监听的端口号,通常是80(HTTP协议)或443(HTTPS协议)。
-
路径(Path):指定服务器上资源的路径,可以是相对路径或绝对路径。这与 UNIX 系统的文件目录结构相似。
-
查询字符串(Query String)[可选]:包含URL中的附加参数,格式为key=value的形式。
-
片段标识符(Fragment)[可选]:指定访问资源的特定位置,例如页面中的某个部分,例如文档中的一个位置;视频或音频文档中的一个时间点。
下面是一个标准的URL示例:
https://www.example.com:443/index.html?id=123#section1
在这个URL中,协议是HTTPS,主机名是www.example.com,端口号是443,路径是/index.html,查询字符串是id=123,片段标识符是section1。
超文本标记语言(HyperText Markup Language,HTML)是一种用来结构化Web 网页及其内容的标记语言。 网页内容可以是:一组段落、一个重点信息列表、也可以含有图片和数据表。
注意:
- 使用 http: 或 https: 等协议方案名获取访问资源时要指定协议类型。不区分字母大小写,最后附一个冒号(:)。
- URL 中的 path 部分沿用了 Unix 风格的路径表示法,这可能是因为当时大部分网络服务器都运行在 Unix 或类 Unix 系统上(现在大部分网络服务器运行在 Linux 系统上),同时也是因为 Unix 风格的路径表示法比较简洁和通用。
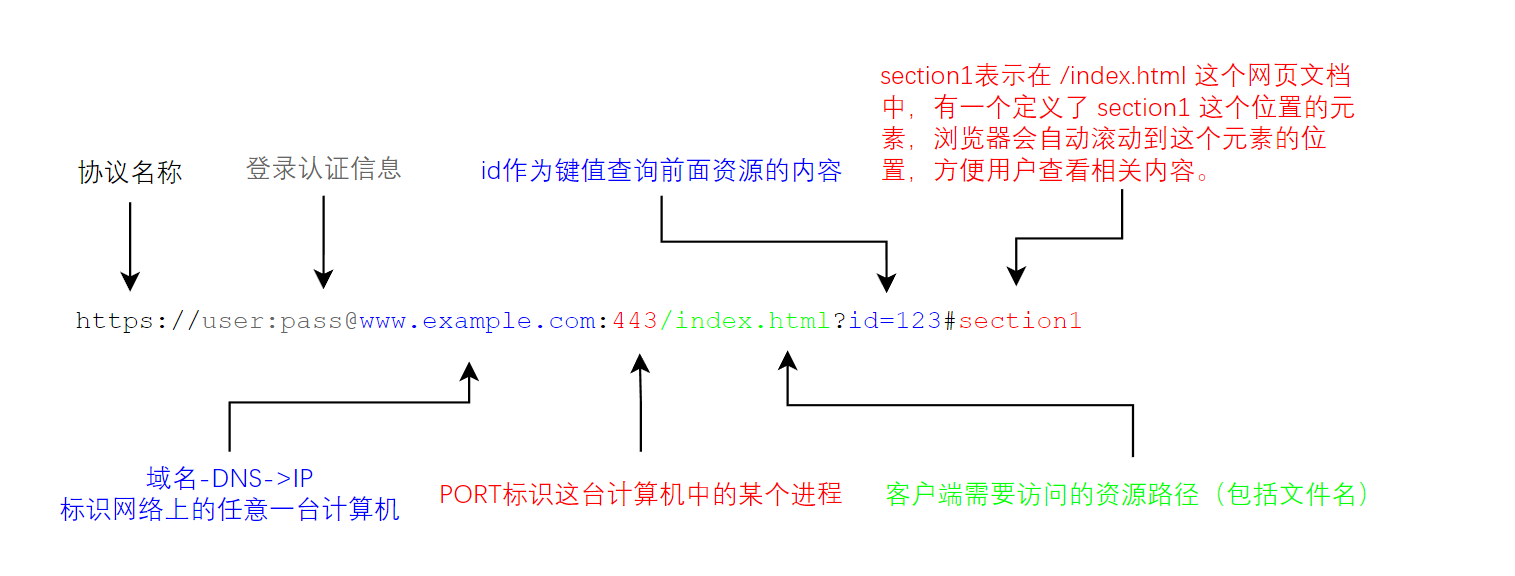
上图是一个URL中各个部分的解释,需要注意的是:
-
user:pass字段保存了用户名和密码,表示用户登录认证信息。大多数时候它们会被省略,通过其他方案传递给服务端,因为这么做非常不安全,相当于在网络中明文传输用户名和密码。 -
http://表示协议名称,另外,常见的HTTPS协议是以安全为目标的HTTP通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。 -
端口号往往与协议绑定,因此客户端在用某种协议发出请求时,协议本身就指定了端口号,因此现在URL中服务器的端口号也一般会省略。
-
后面两个是参数,它们是可选的。URL可以采用绝对路径或相对路径来指定资源的位置。绝对路径是指完整的资源路径,包括主机名、路径和文件名等所有信息,可以独立地指定资源的位置。相对路径则是相对于当前页面或基准URL的路径,可以更简洁地指定资源的位置。
客户端获取请求实际上是通过URL访问服务端中的资源,而服务端响应请求就是将这些资源通过网络传输给客户端。例如用户访问网页是通过浏览器向服务端发出请求,然后获取到服务端返回的html网页文件,浏览器再对这个html文件渲染,这样用户就能获取到网页中的内容。例如:
除了传输网页资源之外,服务端还能返回视频、音频、图片等等资源,这就是HTTP(Hyper Text Transfer Protocol,超文本传输协议)名称的由来。
3.2 编码问题
诸如?、/、:等字符,用户也有可能会使用,因为它们本身有固定的含义,但是对于计算机而言,它们是协议的组成部分,是划分不同模块的标识符,为了避免用户使用上和机器识别发生冲突,我们需要对用户输入的这些字符进行转义。
URLencode 和 URLdecode 是两个 PHP 函数,用于对 URL 中的字符串进行编码和解码。URLencode 函数会将字符串中的特殊字符(如空格、引号、问号等)替换为百分号(%)后跟两位十六进制数,以避免这些字符和 URL 的其他部分混淆或造成错误。例如:
urlencode(“Hello World!”) 会返回 “Hello+World%21”
urldecode 函数会将 URLencode 函数编码后的字符串还原为原始字符串,即将百分号后跟两位十六进制数的序列替换为对应的字符。例如:
urldecode(“Hello+World%21”) 会返回 “Hello World!”
URLencode 和 urldecode 函数通常用于在 URL 中传递参数或数据,以保证 URL 的有效性和安全性。另外,PHP 还提供了 rawurlencode 和 rawurldecode 函数,它们和 URLencode 和 urldecode 函数的区别是,它们遵循 RFC 3986 标准,即将空格编码为 %20 而不是 + 号。例如:
rawurlencode(“Hello World!”) 会返回 “Hello%20World%21”
rawurldecode(“Hello%20World%21”) 会返回 “Hello World!”
在线编码/解码工具:https://www.urlencoder.org/
4. 初识 HTTP 协议
HTTP作为应用层协议,它决定了向用户提供应用服务时通信的活动。前文提到,HTTP(应用层)通常运行在TCP(传输层)之上。在网络通信中,其他层次结构的实现细节是对任意一层透明的,应用层也不例外,在每一层协议眼中,它们都会认为数据是对方同层协议直接传输而来的。就像这样:
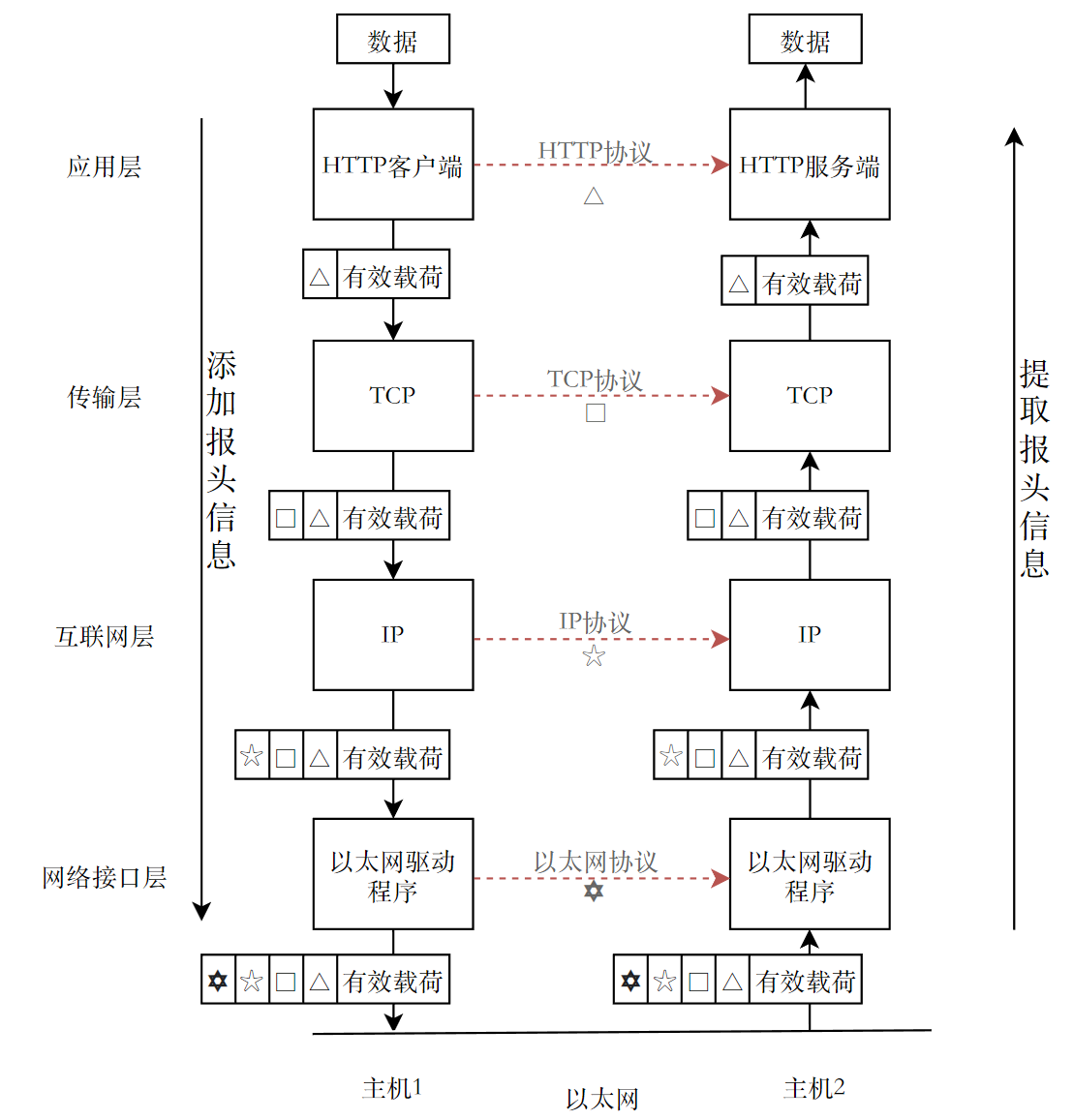
对于同层协议,不管是交付还是接收数据包,有效载荷和报头组合的整体都是同一个。这张图主要想表达的是红色的箭头,它不是真实存在的,但是右边主机的每一层协议在接收到数据时,就相当于直接从对端主机的同层协议接收
除了应用层之外的三层协议,它们实现了具体的通信细节,这是由操作系统完成的,在此并不做讨论,会在后续的专题中详细介绍它们。
4.1 C-S 模式
C-S模式,即客户端-服务器(client-server)模式的一种实现方式,是一种基于请求和响应的应用层服务。
客户端向服务器发送一个请求消息,服务器根据请求内容进行处理,并返回一个响应消息给客户端。这种服务通常使用一种应用层协议来规范请求和响应的格式、内容和语义,比如 HTTP、FTP、SMTP 等。
基于请求和响应的应用层服务的优点是简单、灵活、可扩展,可以支持多种类型的应用需求,比如网页浏览、文件传输、电子邮件等。基于请求和响应的应用层服务的缺点是可能存在延迟、重复、丢失等问题,需要在传输层或其他层提供可靠性和安全性的保障。
应用 HTTP 协议时,必定是一端担任客户端角色,另一端担任服务器端角色。但实际上没有绝对的客户端和服务端,这是根据用户的具体需求决定的。但就仅从一条通信路线来说,服务器端和客户端的角色是确定的,而用 HTTP 协议能够明确区分哪端是客户端,哪端是服务器端。
4.2 通过响应和请求实现通信
既然HTTP是应用于cs模式下的协议,而且它能明确区分客户端和服务端,那么数据的通信就是通过客户端的请求传输到服务端,服务端获取到请求数据以后对其解析,返回响应数据,这样就完成了通信。
这与前文以客户端、服务端为例而讨论的内容是一致的。
实际上交互的是双方通信的报文,即HTTP的请求和响应信息。
值得注意的是,HTTP 协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
由于HTTP建立在TCP之上,在发送请求报文之前,就已经完成了三次握手建立连接的过程。
4.3 请求和响应格式
HTTP请求和响应协议格式是快速构造HTTP响应和请求的报文格式。单纯从报文角度看,HTTP协议可以是基于行的文本协议。
请求格式
HTTP请求协议格式主要由以下部分组成:
请求行:[请求方法] [URL] [协议版本]
请求头部/请求报头/请求首部字段
空行
请求正文
-
请求行:由请求方法、URL和HTTP协议版本三部分组成,之间用空格分隔。例如:
GET /index.html HTTP/1.1,表示请求访问某台 HTTP 服务器上的 /index.htm 页面资源。GET表示请求访问服务器的类型,称为方法(method)。/index.htm指明了请求访问的资源对象,也叫做请求 URI(request-URI)。HTTP/1.1,即 HTTP 的版本号,用来提示客户端使用的 HTTP 协议功能。
-
请求报头:由若干个首部字段组成,每个首部字段由一个键值对构成,中间用冒号(:)分隔。每个首部字段占一行,以回车换行符结束。例如:
Host: www.example.com。 -
空行:用来表示请求报头的结束。
-
请求正文:用来传递一些额外的数据,一般是用户相关的信息或数据,比如表单提交的内容(有时候我们填表后进行刷新操作,会提示相关警告)。请求正文允许为空字符串,其长度和类型由首部字段
Content-Length和Content-Type指定。不是所有的请求都有请求正文,比如GET方法就没有。
除了请求正文之外的三部分是HTTP协议内置的,如果用户在请求时没有填充请求正文,那么请求正文就是一个空字符串。
例如下面就是一个完整的HTTP请求报文:
POST /Login/index HTTP/1.1 // 请求行
Host: www.everyonepiano.cn // 请求头部
Connection: keep-alive
Content-Length: 50
Cache-Control: max-age=0
Origin: http://www.everyonepiano.cn
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://www.everyonepiano.cn/Login/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
// 空行
username=admin&password=123456 // 请求正文
从逻辑上看,协议的内容按行陈列,但实际上网络通信时,“行”会被\r\n代替作为分隔符,整个报文就是一个字符串,通过字节流在网络中传输。
响应格式
HTTP协议的响应报文是指服务器返回给客户端的消息。一个HTTP响应报文由以下部分组成:
状态行:[协议版本] [状态码] [状态码描述]
响应头部/响应报头
空行
响应主题
- 一行状态行:用于描述请求是否成功或失败,包含三个元素:协议版本、状态码和状态文本。例如,
HTTP/1.1 200 OK表示请求成功。 - 响应头部[可选]:用于提供有关服务器或响应主体的附加信息,由不区分大小写的字符串、冒号和值组成。例如,
Content-Type: text/html表示响应主体是HTML文档。 - 一个空行:用于指示所有关于响应的元数据已经发送完毕。
- 响应主体[可选]:用于传递服务器返回的数据,比如HTML页面或图片文件。响应主体的长度和类型由响应头部中的
Content-Length和Content-Type字段指定。
一个典型的HTTP响应报文如下:
HTTP/1.1 200 OK // 状态行
Date: Fri, 01 Nov 2013 00:00:00 GMT // 响应头部
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
Content-Type: text/html
Content-Length: 88
// 空行
<html> // 响应主体
<body>
<h1>Hello, World!</h1>
</body>
</html>
其中:
- 在起始行开头的 HTTP/1.1 表示服务器对应的 HTTP 版本。
- 紧挨着的 200 OK 表示请求的处理结果的状态码(status code)和原因短语(reason-phrase)。
- 下一行显示了创建响应的日期时间,是首部字段(header field)内的一个属性。
- 接着以一空行分隔,之后的内容称为资源实体的主体(entity body)。
这个例子中,最后的响应主体是一个html文件,它作为服务端的返回信息被客户端获取后,可以被渲染为网页。在稍后的测试中,这部分内容可以自定义。
为什么请求和响应都要交互协议的版本号呢?这有什么意义?
为了保证兼容性,因为新版本的协议往往能提供更多服务:
- HTTP协议的版本号可以让客户端和服务器知道对方支持的协议特性和功能,从而进行适当的处理和优化。
- HTTP协议的版本号可以让客户端和服务器检查请求和响应的状态,从而判断成功或失败,并采取相应的行动,例如更新或使用本地缓存。
- HTTP协议的版本号可以让客户端和服务器在遇到不兼容或不支持的情况时,发送相应的错误代码,例如505(HTTP版本不支持)。
4.4 分离报文中的有效载荷
有效载荷(payload)是指真正传输数据的一部分,在HTTP协议中,真正有效的数据就是最后的请求正文。刚才提到,从逻辑上看报文是以“行”被分割的,但实际上是以\r\n分割。
当服务端获取到HTTP请求后(数据包),要对请求进行解析,取出其中真正有效的数据,只要通过\r\n为分隔符,由于空行在正文之前,那么空行的\n和它上一行的\r\n组合为\r\n\n,当客户端读取到2个\n后,就说明报头已经被读取完毕了,剩下的内容就是有效载荷。
其中,请求正文中的首部字段Content-Length和Content-Type指定了正文的长度和类型,这样服务端就能完整地取出有效载荷。
4.5 初识HTTP
上面提到,HTTP响应的响应主体可以是一个html文件,这是用户自定义的,下面就来实现它:让浏览器向服务端发起请求,然后服务端返回这个html文件,使得它能在显示器上显示。但这只是最后一环。最主要的是如何让服务端返回这个文件给客户端。
处于应用层的HTTP协议是运行在处于传输层的TCP协议之上的,因此建立主机之间的连接和通信等逻辑需要使用TCP socket来实现。
首先,将Linux中的网络操作例如创建套接字、监听、获取连接、连接等操作封装为函数,然后放在类Sock中。
然后,用一个类HttpServer封装服务端,其中有一个Sock类型的成员,以便在成员函数中调用封装好的网络接口。
// HttpServer.hpp
#include <iostream>
#include <functional>
#include <signal.h>
#include <sys/types.h>
#include "Sock.hpp"
class HttpServer
{
public:
using func_t = std::function<void(int)>;
private:
int _listen_sock;
uint16_t _port;
Sock _sock;
func_t _func;
public:
HttpServer(const uint16_t &port, func_t func, std::string ip = "")
: _port(port), _func(func)
{
_listen_sock = _sock.Socket();
_sock.Bind(_listen_sock, _port);
_sock.Listen(_listen_sock);
}
~HttpServer()
{
if (_listen_sock >= 0)
close(_listen_sock);
}
void Start()
{
signal(SIGCHLD, SIG_IGN);
while (1)
{
std::string client_ip;
uint16_t client_port;
int sockfd = _sock.Accept(_listen_sock, &client_ip, &client_port);
// std::cout << client_ip << ":" << client_port << std::endl; // for DEBUG
if (sockfd < 0)
continue;
if (fork() == 0) // 子进程
{
close(_listen_sock); // 子进程关闭不需要的监听套接字文件描述符
_func(sockfd); // 调用服务函数
close(sockfd); // 使用完毕后关闭
exit(0);
}
close(sockfd); // 父进程关闭不需要的socket套接字文件描述符
}
}
};
值得注意的是,Start()函数使用了常用的方法来避免出现僵尸进程的情况,即忽略SIGCHLD信号。除此之外,还可以使用孙子进程来调用服务函数来响应客户端请求。
// HttpServer.cc
#include "HttpServer.hpp"
#include <memory>
void Usage(const std::string &proc)
{
std::cout << "\nUsage: " << proc << " [PORT]\n" << std::endl;
}
void HttpRequestHandler(int sockfd)
{
char buffer[10240];
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (s > 0)
{
buffer[s] = '\0';
std::cout << "-------------------------- http request begin ------------------------" << std::endl;
std::cout << buffer << std::endl;
std::cout << "-------------------------- http request end --------------------------" << std::endl;
}
}
int main(int argc, char *argv[])
{
if(argc != 2)
{
Usage(argv[0]);
exit(1);
}
uint16_t port = atoi(argv[1]);
std::unique_ptr<HttpServer> server_ptr(new HttpServer(port, HttpRequestHandler));
server_ptr->Start();
return 0;
}
其中,HttpRequestHandler()函数就是服务端函数,这里只是简单地打印客户端的请求,这个请求是保存在一个用户提供的缓冲区中的,使用recv()函数时,相当于将缓冲区的内容拷贝到服务端提供的缓冲区中,为了观察现象,将它们打印出来。
源代码:HttpServer Version 1
测试
通常在测试时,将端口设置为8080或8081,浏览器本身就是一个客户端,键入服务器的公网IP和端口号,中间以:分隔:
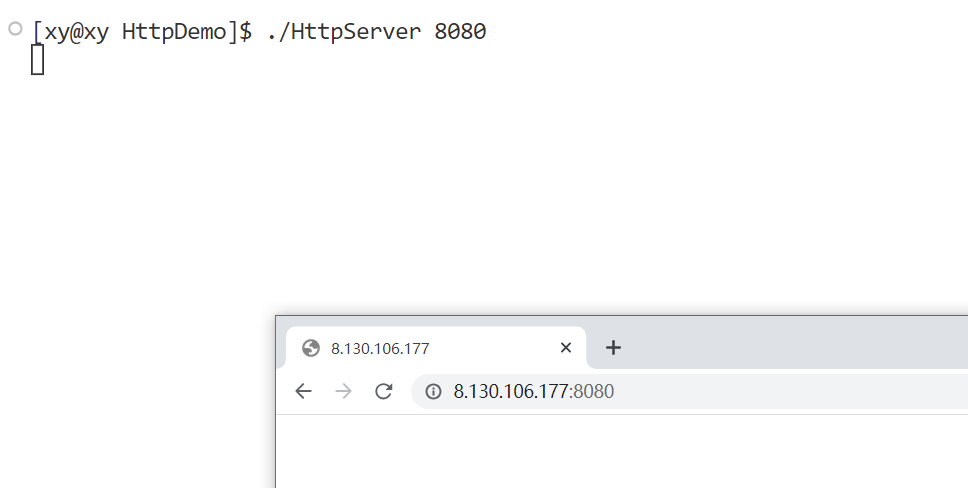
如果当你按下回车,服务端像这样什么都没显示,那么大概率是云服务器没有开放端口。可以搜索对应运营商的和系统的开放端口的方法。如果这样还不能解决,那么可能是系统的防火墙未开放端口。
以阿里云的CentOS 7系统为例(2023/6/8):

如果添加不了很多个的话,可以先添加,然后在最右侧的“编辑”按钮中修改。
他喵的这个问题让我调半天。
切入点是我调试发现被封装的Accept()函数阻塞在了accept()函数中,其中只可能是第一个参数,即监听套接字文件描述符出现了问题(因为另外两个是输出型参数),说明这个函数陷入了阻塞,一直在等待连接。结合
telnet工具的测试结果,发现每次用内网IP或127.0.0.1连接都能成功,用公网IP就一直连接不上(端口都是服务端启动时指定的8080或8081),怀疑是端口问题,各种搜索就解决了。收获:虽然用SSH能通过这个公网IP连接到机器,但是它和HTTP不是一个协议。
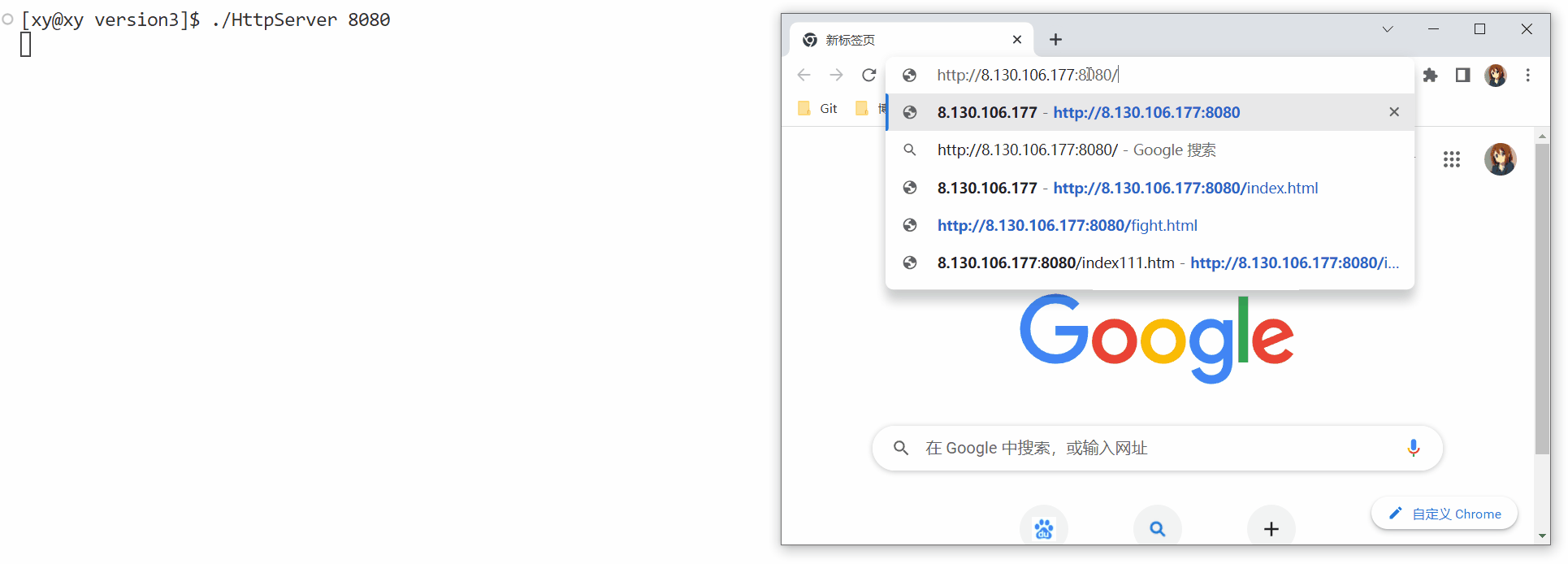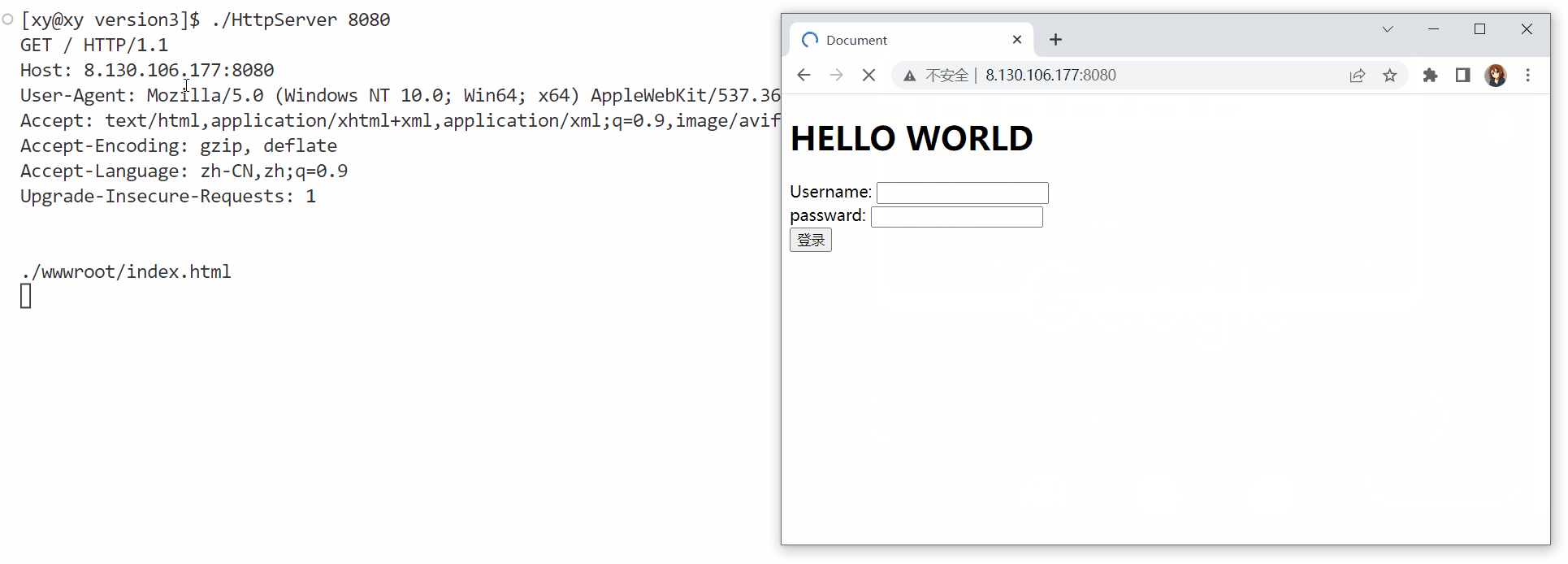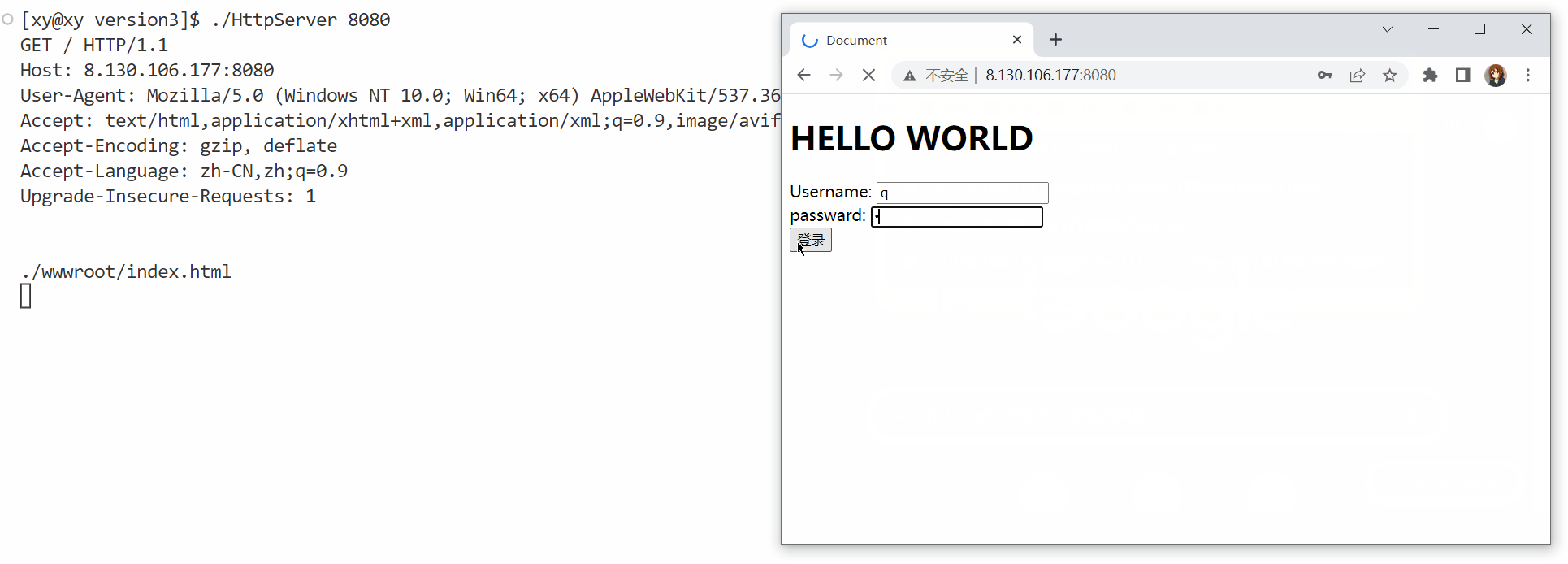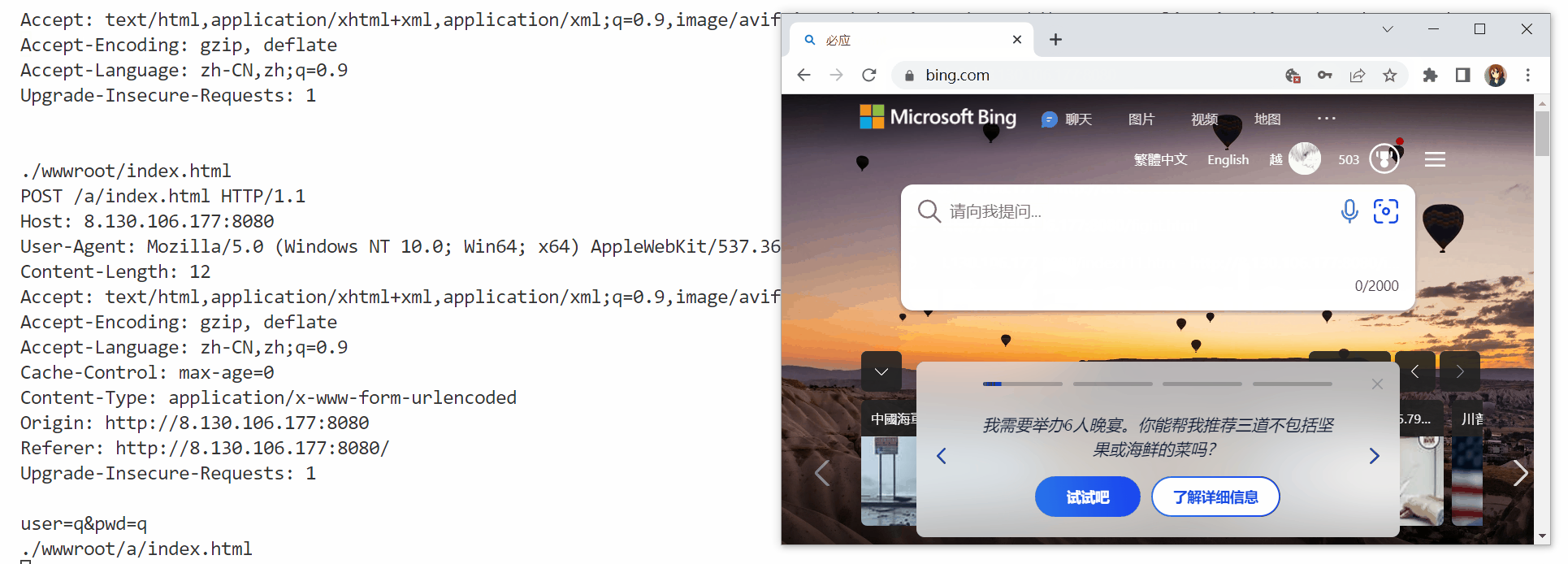
正常情况下键入IP地址和端口号,按下回车后,服务端应该会立即显示以下内容;
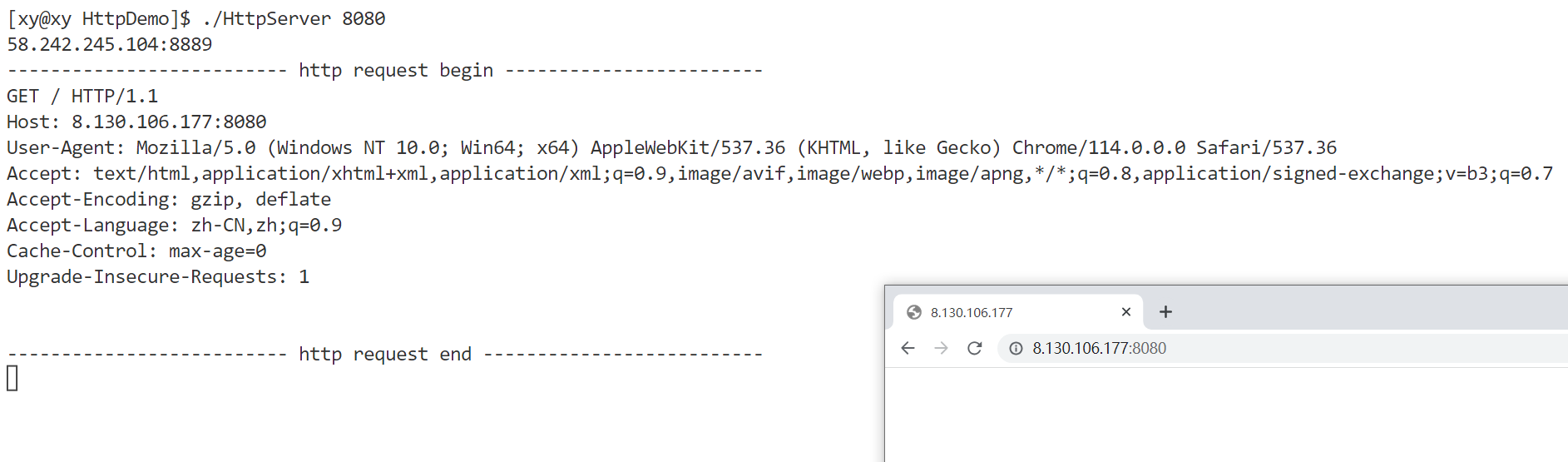
这就是上面介绍的响应报文。
由于这个客户端的逻辑只是打印,而未返回任何内容给客户端,因此浏览器显示的是错误信息:
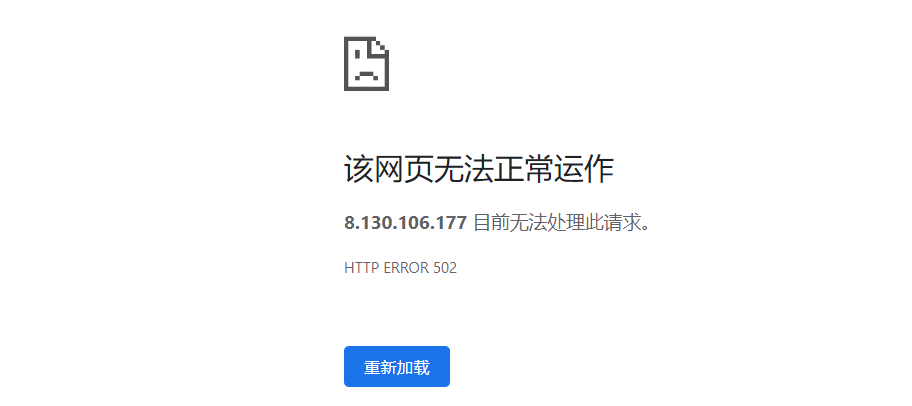
值得注意的是,很多时候键入URL不用指明协议名称,因为浏览器默认使用的协议是HTTP。
4.6 构建响应
如上文所说,服务端处理请求后会返回一些信息给客户端,这可以是一个HTML文件,虽然目前无法真正处理服务器的请求,但可以返回一个固定的HTML文件作为演示。
网根目录
网站根目录(web根目录)是指web服务器中存放网站的第一层文件夹,也就是网站文件上传存放的第一级目录,访问网站首页就是指向该目录。网站根目录的名称和位置可能因不同的服务器环境而有所不同,常见的有wwwroot、www、web、htdocs、public_html等。网站根目录是网站程序系统的安装目录,也是网站文件的存储位置。网站根目录是web服务器中存放网站的第一层文件夹,也就是网站程序系统的安装目录。因此,网站根目录对于网站的运行和管理具有重要的作用。
在本文件的目录下新建一个目录wwwroot,作为web根目录,然后将要响应的html文件放到这个目录中:
// 相对路径:/wwwroot/index.html
<html>
<h1>HELLO WORLD</h1>
</html>
VSCode的快捷键:
!然后回车,生成一个模板。
由于使用html文件的本质依然是文件流,也就是要将html中的所有字段拼接为一个字符串,服务端最后再发送给客户端。这需要一些文件流操作和字符串分离操作,为了测试html文件的可行性,我们直接返回一个按规则拼接好的字符串作为测试:
void HttpRequestHandler(int sockfd)
{
// 1. 读取请求
char buffer[10240];
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (s > 0)
buffer[s] = '\0';
// 2. 构建响应
std::string HttpResponse = "HTTP/1.1 200 OK\r\n";
HttpResponse += "\r\n";
HttpResponse += "<html><h1>HELLO WORLD</h1></html>";
send(sockfd, HttpResponse.c_str(), HttpResponse.size(), 0);
}
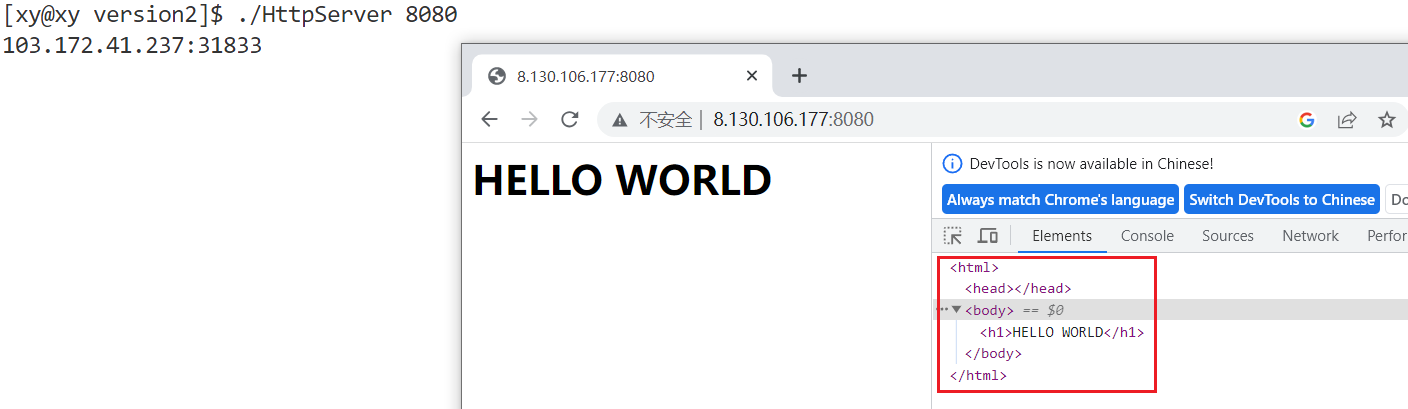
结果表明这是可行的。
显示客户端的IP和PORT是为了调试写的打印语句。
值得注意的是,wwwroot是一个常见的网根目录的名称,本文中指定wwwroot为网根目录(这个相对路径将会被define),那么它就是网根目录。否则,它只是一个普通的目录。
也就是说,网根目录只是名称上的规定,理论上取任何合法的名字都可以,只要在配置文件中声明就好了。对于HTTP协议,它本身并没有默认指定网根目录的名称,它只是规定了如何请求和响应资源。
网根目录的名称是由服务器软件决定的,不同的服务器软件可能有不同的默认名称。如果不在配置文件中声明网根目录的位置,那么服务器软件会使用它自己的默认值。如果想改变网根目录的位置,那么必须在配置文件中声明。
除此之外,HTTP客户端请求的是服务端的web根目录的哪个文件,取决于服务端的配置和操作系统。一般来说,有以下几种可能的文件:
- index.html
- index.php
- default.htm
- default.aspx
- index.asp
这也是用户可以自行指定的。
字符串分割
将一个字符串按照给定的分隔符切割成多个子字符串,并将这些子字符串存储在一个vector中。函数接受三个参数:一个输入字符串s,一个分隔符sep和一个用于存储结果的vector指针out。
函数首先初始化一个变量start,表示当前搜索的起始位置。然后进入一个循环,每次循环中都会在字符串s中从start位置开始查找分隔符sep。如果找到了分隔符,则将其前面的子字符串提取出来并存储到vector中,然后更新start的值,使其指向下一个子字符串的起始位置。如果没有找到分隔符,则退出循环。
最后,如果字符串s中还有剩余部分,则将其作为最后一个子字符串存储到vector中。
#pragma once
#include <iostream>
#include <vector>
class Util
{
public:
// example: text1\r\ntext2\r\ntext3\r\n\n
static void cutString(std::string s, const std::string &sep, std::vector<std::string> *out)
{
std::size_t start = 0;
while (start < s.size())
{
auto pos = s.find(sep, start);
if (pos == std::string::npos)
break;
std::string sub = s.substr(start, pos - start);
out->push_back(sub);
start += sub.size();
start += sep.size();
}
if (start < s.size())
out->push_back(s.substr(start));
}
};
完善 HTTP 请求处理函数
完善的逻辑实现了一个简单的HTTP服务器,能够处理客户端的GET请求并返回相应的文件内容:
#include <fstream>
#include <vector>
#include "Util.hpp"
void HttpRequestHandler(int sockfd)
{
// 1. 读取请求
char buffer[10240];
ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (s > 0)
buffer[s] = '\0';
// 2.0 准备响应
std::vector<std::string> vline;
Util::cutString(buffer, "\n", &vline);
std::vector<std::string> vblock;
Util::cutString(vline[0], " ", &vblock);
std::string file = vblock[1];
std::string target = ROOT;
if (file == "/")
file = "/index.html";
target += file;
std::cout << target << std::endl;
std::string content;
std::ifstream in(target);
if (in.is_open())
{
std::string line;
while (std::getline(in, line))
content += line;
in.close();
}
// 2. 构建响应
std::string HttpResponse;
HttpResponse = "HTTP/1.1 200 OK\r\n";
HttpResponse += "\r\n";
HttpResponse += content;
// 3. 返回给客户端
send(sockfd, HttpResponse.c_str(), HttpResponse.size(), 0);
}
首先,HandlerHttpRequest()函数从套接字中读取客户端发送的HTTP请求,并将其存储在一个缓冲区buffer中。然后使用Util::cutString函数将请求按照换行符切割成多行,并存储在vline容器中。再使用它将第一行(即请求行)按照空格切割成多个部分,并存储在vblock容器中。
然后函数提取出请求的文件名,并拼接成完整的文件路径。如果请求的文件名为/,则将其替换为默认的首页文件名/index.html。然后,函数尝试打开该文件,并读取其中的内容。
最后,函数根据读取到的文件内容构建HTTP响应。这样,客户端的请求默认访问的就是网根目录,也就是/下的index.html文件。
不过,在浏览器中可能会隐藏一些细节:
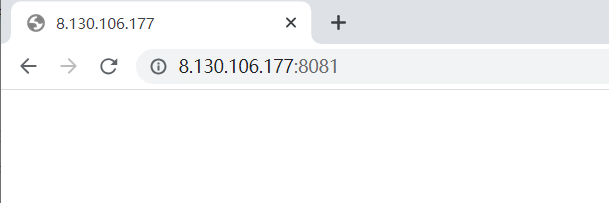
但事实上客户端的HTTP请求是:
http://8.130.106.177:8081/(复制网址框的内容,然后粘贴),后面自动追加了一个/,表示默认在网根目录下请求。我们设置的index.html文件也就是首页要显示的内容。同样地,例如在网址框中输入
baidu.com回车,实际上请求是https://www.baidu.com/,百度会返回客户端它的首页。
文件流操作:由于提取的参数是一个路径,它应该是web的根目录而不是系统的根目录,所以在执行文件操作之前,要通过字符串拼接完善路径。
测试结果:
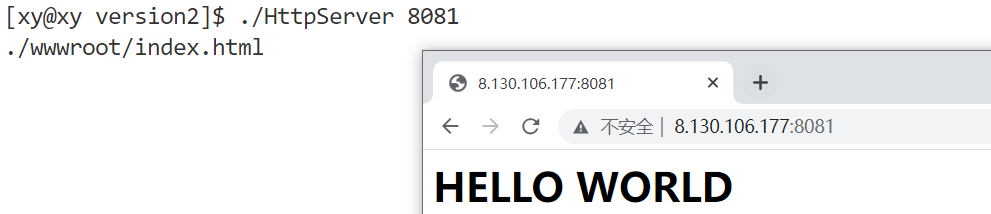


源代码:HttpServer Version 2
5. HTTP 方法
HTTP 方法是用来告知服务器意图的方式。
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
-
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法。
-
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
| 序号 | 方法 | 描述 | 协议支持版本 |
|---|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 | 1.0/1.1 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 | 1.0/1.1 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 | 1.0/1.1 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 | 1.0/1.1 |
| 5 | DELETE | 请求服务器删除指定的页面。 | 1.0/1.1 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 | 1.1 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 | 1.1 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 | 1.1 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 | 1.1 |
| 10 | LINK | 建立和资源之间的联系 | 1.0 |
| 11 | UNLINK | 断开连接关系 | 1.0 |
来源:RUNOOB:HTTP 请求方法
5.1 GET和POST
这两个方法是最常用的,它们对应着用户上网的两大行为:
- 获取服务端的资源和数据
- 将客户端的数据递交给服务器
它们分别对应着:
-
GET 方法用来请求访问已被 URI/URL 识别的资源。指定的资源经服务器端解析后返回响应内容。

-
POST 方法用来传输实体的主体。
虽然用 GET 方法也可以传输实体的主体,但一般不用 GET 方法进行传输,而是用 POST 方法。虽说 POST 的功能与 GET 很相似,但 POST 的主要目的并不是获取响应的主体内容。它们都可以将数据上传到服务器,但是 URL 的长度是有限制的,所以 GET 方法有局限性;POST 方法以正文作为参数,可以传输更多信息。
此外,POST 方法更加私密,因为 URL 会将私密信息作为参数显示,但这并不意味着将私密信息放在正文中传输就是安全的,如果不对信息进行加密,GET 和 PORT 方法都是在网络中传输明文,都不是安全的。
GET和POST的区别是:
-
GET是用来从指定的资源请求数据的方法,它会将查询字符串(键值对)附加到URL中
-
GET的特点:
- GET请求可以被缓存
- GET请求会保留在浏览器历史记录中
- GET请求可以被收藏
- GET请求不应该用于处理敏感数据
- GET请求有长度限制
- GET请求只用于请求数据(不修改)
-
POST是用来向服务器发送数据的方法,通常会创建或更新资源。POST请求的数据存储在HTTP请求的主体(body)中,例如:
POST /test/demo_form.php HTTP/1.1 Host: w3schools.com name1=value1&name2=value2 -
POST的特点:
-
POST请求不会被缓存
-
POST请求不会保留在浏览器历史记录中
-
POST请求不能被收藏
-
POST请求没有数据长度限制
-
POST请求可以发送任何类型的数据,包括二进制数据
-
POST请求相对于GET请求更安全,因为数据不会显示在URL中
-
测试
使用postman工具,测试GET和POST方法,观察结果。
GET方法:URL作为参数,在URL中再增加a和b两个参数(为了显示具体信息,在HttpRequestHandler()函数中打印了获取到的客户端请求):
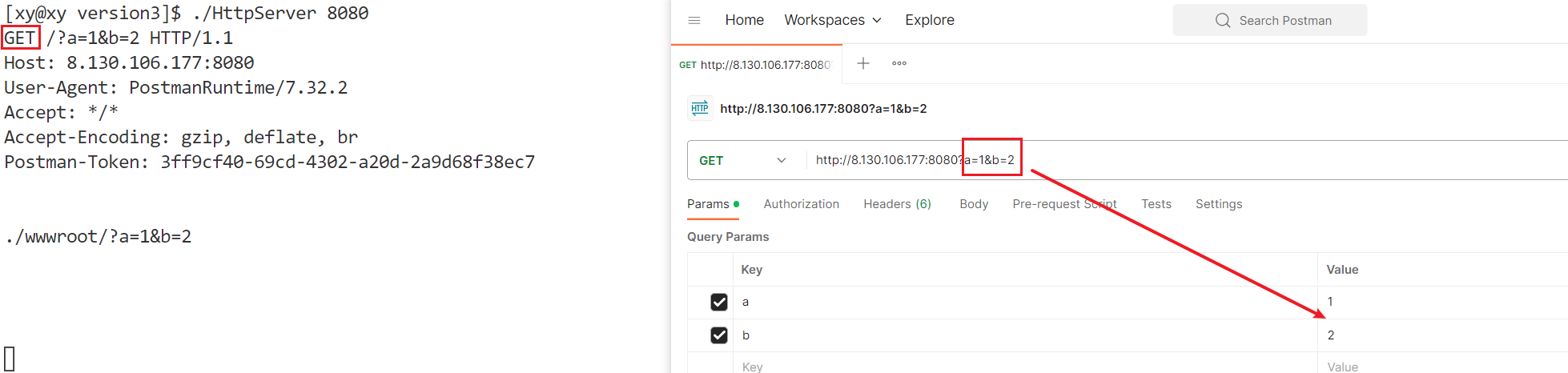
可以看到,请求行中也增加了传递的参数,这和第一栏"Params"(参数)是对应的。
POST方法:正文作为参数,应该在第4栏"Body"设置:
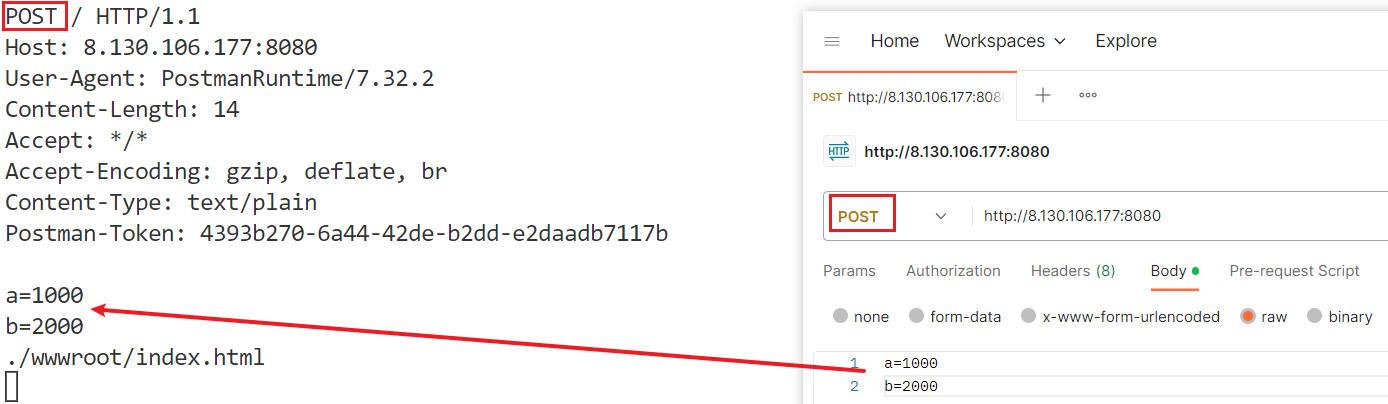
这样HTTP请求的正文就被这个字符串填充,而不再是空字符串。正因如此,服务端的响应报头中出现了Content-Length字段,表示响应正文的长度。
打印"./wwwroot/index.html"的原因是没有注释掉另一个打印客户端请求资源路径的语句。
表单
HTML 表单用于收集用户的输入信息,表示文档中的一个区域,此区域包含交互控件,将用户收集到的信息发送到 Web 服务器。在 HTTP 协议中,通常与 GET 与 POST 方法一起使用。
简单地说,表单对于用户而言就是一个框,用户可以在这个框中填充信息,这些信息会被转化为 HTTP 请求的一部分。那么表单是要被作为数据提交给服务器的,这就需要指明提交的方法,常见的方法是 GET 和 POST 方法。
- 表单的method属性用于指定使用哪种方法,例如:
<form method="POST">
<!-- 表单元素 -->
</form>
- 如果没有指定method属性,那么默认使用GET方法。
- GET方法会将表单数据附加到URL中,而POST方法会将表单数据存储在请求正文中。
- GET方法适合用于请求数据,而POST方法适合用于发送数据。
下面在一个html文件中写一个简单的表单,以供用户输入信息和提交,其中包含了部分提示信息:
<html>
<body>
<h1>HELLO WORLD</h1>
<form name="input" method="get" action="/index.html">
Username: <input type="text" name="user">
<br>
passward: <input type="password" name="pwd">
<br>
<input type="submit" value="登录">
</form>
</body>
</html>
注意,本文的重点不是html的语法,只要简单了解即可。
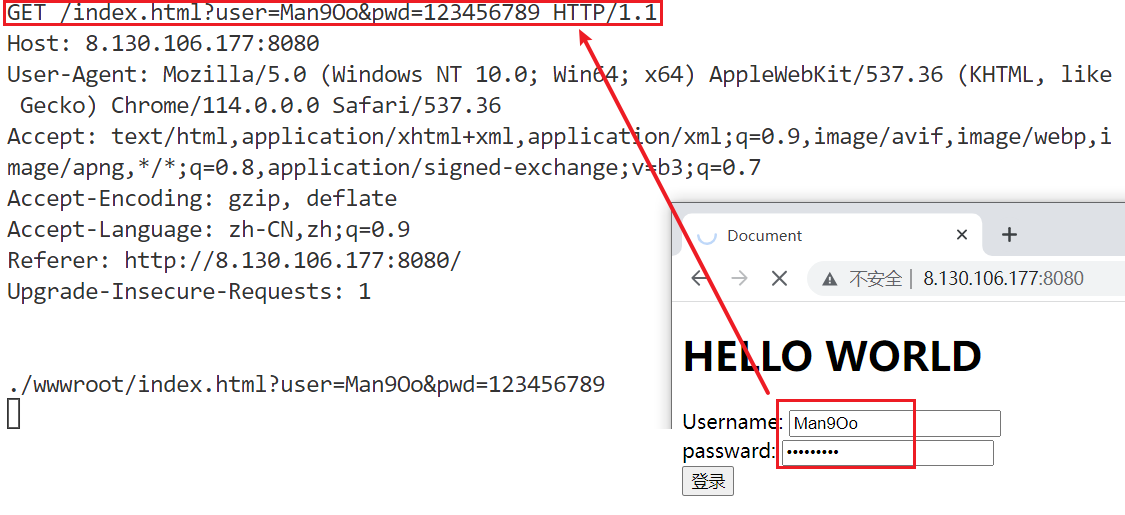
当用户访问服务端时,就会出现图中的表单,提交以后它们就会被作为参数插入到URL中。
如果将方法改为POST:
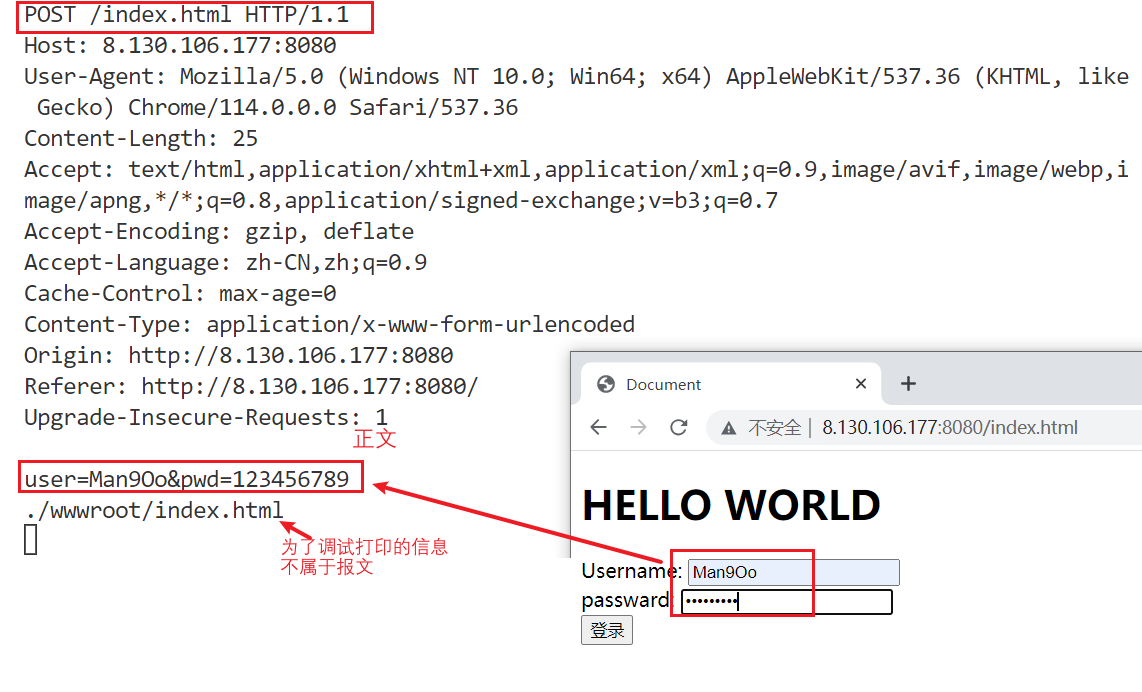
如果方法是 PORT,那么用户提交的两个属性不会在 URL 中体现,而是被放在了正文中传输给服务端。
值得注意的是,私密性≠安全,PORT 方法只是将URL中的参数放在了正文,但实际上它们都是通过明文在网络中传输的,这是不安全的,只有加密和解密之后才是安全的。
6. HTTP 状态码
HTTP 状态码(HTTP Status Code)的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(server header)用以响应浏览器的请求。
状态码的类别:
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
常见的 HTTP 状态码:
- 200:请求成功
- 301:资源(网页等)被永久转移到其它URL
- 404:请求的资源(网页等)不存在
- 500:内部服务器错误
对于4xx,标定的是客户端请求的合法与否,也就是说,请求对于服务端而言需要合理,因为服务端的服务范围是有限的。5xx是服务器内部错误,对于客户端而言很少看到,因为这可能会造成风险,而且这个信息一般是显示给程序员调试用的,所以一般服务端的状态码即使真正是5xx,也可能会对客户端显示为3xx或4xx,或者重定向到其他服务。
来源于网络(RUNOOB:HTTP 状态码)
程序员最想看到的:200-OK。
程序员不想看到的:500-Internal-Server-Error。
用户不想看到的:401-Unauthorized、403-Forbidden、408-Request-Time-out、404-not-found。
6.1 重定向
3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
永久性重定向
永久性重定向(301 Moved Permanently)。该状态码表示请求的资源已被分配了新的 URL,以后应使用资源现在所指的 URL。也就是说,原始资源已经被永久地移动到新的位置,客户端/浏览器应该不再尝试请求原始位置,而是使用新的位置。
这意味着如果某个IP或域名是永久性重定向,那么第一次访问该网站时,浏览器会进行重定向操作,后续再访问它,将直接访问重定向以后的网站。
为什么这和浏览器有关系呢?URL/URI不应该已经被更新了吗?
浏览器进行的重定向操作是指:
- 当浏览器请求一个URL时,服务器会返回一个响应,其中包含一个状态码和一个Location头部。
- 如果状态码是301,表示永久性重定向,那么浏览器会从Location头部获取新的URL,并再次发起请求。
- 浏览器会将这个重定向信息缓存起来,以便下次直接请求新的URL,而不是原始的URL。
- 如果您在浏览器中输入原始的URL,浏览器会自动替换为新的URL,并显示在地址栏中。这就是重定向操作。
也就是说,重定向后的地址是保存在Location头部的,这个信息是由服务器发出的。例如,如果服务器想要将http://example.com重定向到http://example.org,它会返回这样的响应:
HTTP/1.1 301 Moved Permanently
Location: http://example.org
浏览器会从Location头部获取新的地址,并再次发起请求。
事实上,从现实例子也很好理解:当用户第一次访问网站时,是不知道这个网站是否是被重定向的。可能原先的域名更加好记,更具有代表性,而重定向的IP地址可能由于某种需要而被设置。
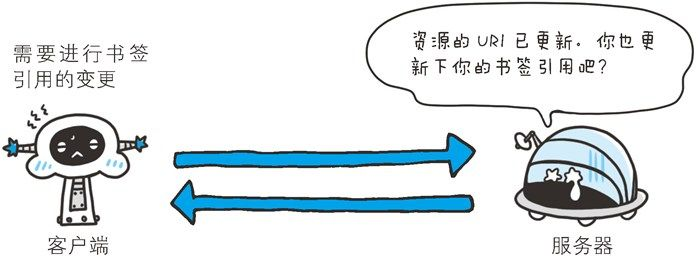
Location头部默认情况下会被浏览器缓存,没有任何过期日期。也就是说,它会一直保留在浏览器的缓存中,直到用户手动清除缓存,或者缓存条目被清理以腾出空间。
缓存行为只是浏览器在没有指定其他缓存控制指令的情况下的默认行为。用户可以使用一些HTTP头部来改变这种行为,例如Cache-Control和Expires。
临时性重定向
临时性重定向(Moved Temporarily 302、307)。这两个状态码表示请求的资源已被分配了新的 URL,希望用户(本次)能使用新的 URL 访问。
302(Found)
和 301 Moved Permanently 状态码相似,但 302 状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的 URL 将来还有可能发生改变。比如,用户把 URL 保存成书签,但不会像 301 状态码出现时那样去更新书签,而是仍旧保留返回 302 状态码的页面对应的 URL。
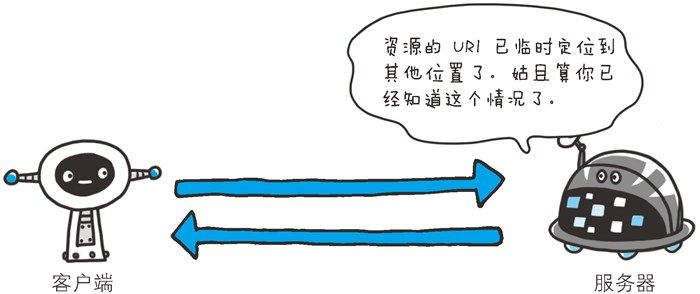
307(Temporary Redirect)
临时重定向。该状态码与 302 Found 有着相同的含义。尽管 302 标准禁止 POST 变换成 GET,但实际使用时大家并不遵守。
307 会遵照浏览器标准,不会从 POST 变成 GET。但是,对于处理响应时的行为,每种浏览器有可能出现不同的情况。
307(Temporary Redirect)和302(Found)状态码的区别是:
- 307和302都表示临时性重定向,即原始资源暂时位于其他地方,客户端/浏览器应该继续请求原始位置。
- 307保证重定向后的请求方法和主体不会改变,而302可能会导致一些旧的客户端/浏览器错误地将请求方法改为GET。
- 307的行为在Web上是可预测的,而302的行为在非GET方法上是不可预测的。
- 对于GET方法,307和302的行为是相同的。
重定向测试
这里只能进行临时重定向测试,实际上就是将响应字符串中拼接上Location字段:
void HttpRequestHandler(int sockfd)
{
// ...
std::string HttpResponse;
if (content.empty())
{
HttpResponse = "HTTP/1.1 302 Found\r\n";
HttpResponse += "Location: https://www.bing.com/\r\n";
}
// ...
send(sockfd, HttpResponse.c_str(), HttpResponse.size(), 0);
}
只要HTTP协议识别到了302/307状态码,就会去找Location字段,然后就会跳转到指定的域名:
源代码:HttpServer Version 3
7. HTTP Header
7.1 介绍
HTTP头字段(HTTP header fields)是指在超文本传输协议(HTTP)的请求和响应消息中的消息头部分。它们定义了一个HTTP协议事务中的操作参数。
格式
协议头的字段,是在请求(request)或响应(response)行(一条消息的第一行内容)之后传输的。协议头的字段是以明文的字符串格式传输,是以冒号分隔的键名与键值对,以回车(CR)加换行(LF)符号序列结尾(\r\n)。协议头部分的结尾以一个空白字段标识,结果就是,也就是传输两个连续的CR+LF。
在历史上,很长的行曾经可能以多个短行的形式传输;在下一行的开头,输出一个空格(SP)或者一个水平制表符(HT),表示它是一个后续行。在如今,这种换行形式已经被废弃。但是作为学习者是有必要知晓的。
类型
HTTP 头字段根据实际用途被分为以下 4 种类型:
- 通用Header可以提供关于整个消息的信息,例如日期、连接状态、缓存控制等 。
- 请求Header可以提供关于客户端或请求资源的信息,例如主机名、用户代理、接受的媒体格式等 。
- 响应Header可以提供关于服务器或响应资源的信息,例如服务器名称、位置、Cookie等 。
- 表示Header可以提供关于资源主体的信息,例如内容类型、内容编码、内容长度等 。
- 有效载荷Header可以提供与有效载荷数据无关的信息,例如传输编码、内容长度等 。
下面主要讨论响应 Header。
7.2 常见 Header
响应首部字段是由服务器端向客户端返回响应报文中所使用的字段,用于补充响应的附加信息、服务器信息,以及对客户端的附加要求等信息。常见响应 Header 有:
| Header | 说明 | 类型 |
|---|---|---|
| User-Agent | 声明用户的操作系统和浏览器的版本信息。 | 请求 |
| Referer | 当前页面是哪个页面跳转过来的。 | 请求 |
| Content-Length | 表示内容长度。 | 有效载荷 |
| Content-Type | 表示后面的文档属于什么MIME类型。 | 有效载荷 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 | 通用 |
| Host | 客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。 | 请求 |
| Cookie | 用于在客户端存储少量信息,通常用于实现会话(session)的功能。 | 请求 |
| Location | 令客户端重定向至指定URI | 响应 |
| Connection | 逐跳首部、连接的管理。使用关键字“Keep-Alive”来指示连接应保持开启以接收之后的信息(这是HTTP 1.1中的默认情形,而HTTP 1.0默认将为每对请求/回复对创建新连接)。 | 通用 |
RUNOOB:HTTP 响应头信息
Content-XX
例如下面指定了两个响应 Header,分别是Content-Type和Content-Length,其中"Content-Type: text/plain\r\n"的意思是,这个响应的主体是纯文本格式,不包含任何标记或格式化,并且用\r\n表示这个 Header 字段已经结束。
void HttpRequestHandler(int sockfd)
{
// ...
else
{
HttpResponse = "HTTP/1.1 200 OK\r\n";
HttpResponse += "Content-Type: text/plain\r\n";
HttpResponse += "Content-Length: " + std::to_string(content.size()) + "\r\n";
}
// ...
send(sockfd, HttpResponse.c_str(), HttpResponse.size(), 0);
}
这样浏览器就不会对这些HTML做渲染,显示出来的就是纯文本了。

如果要访问服务器上的图片,可以将响应报头改成这样:Content-Type: image/png\r\n
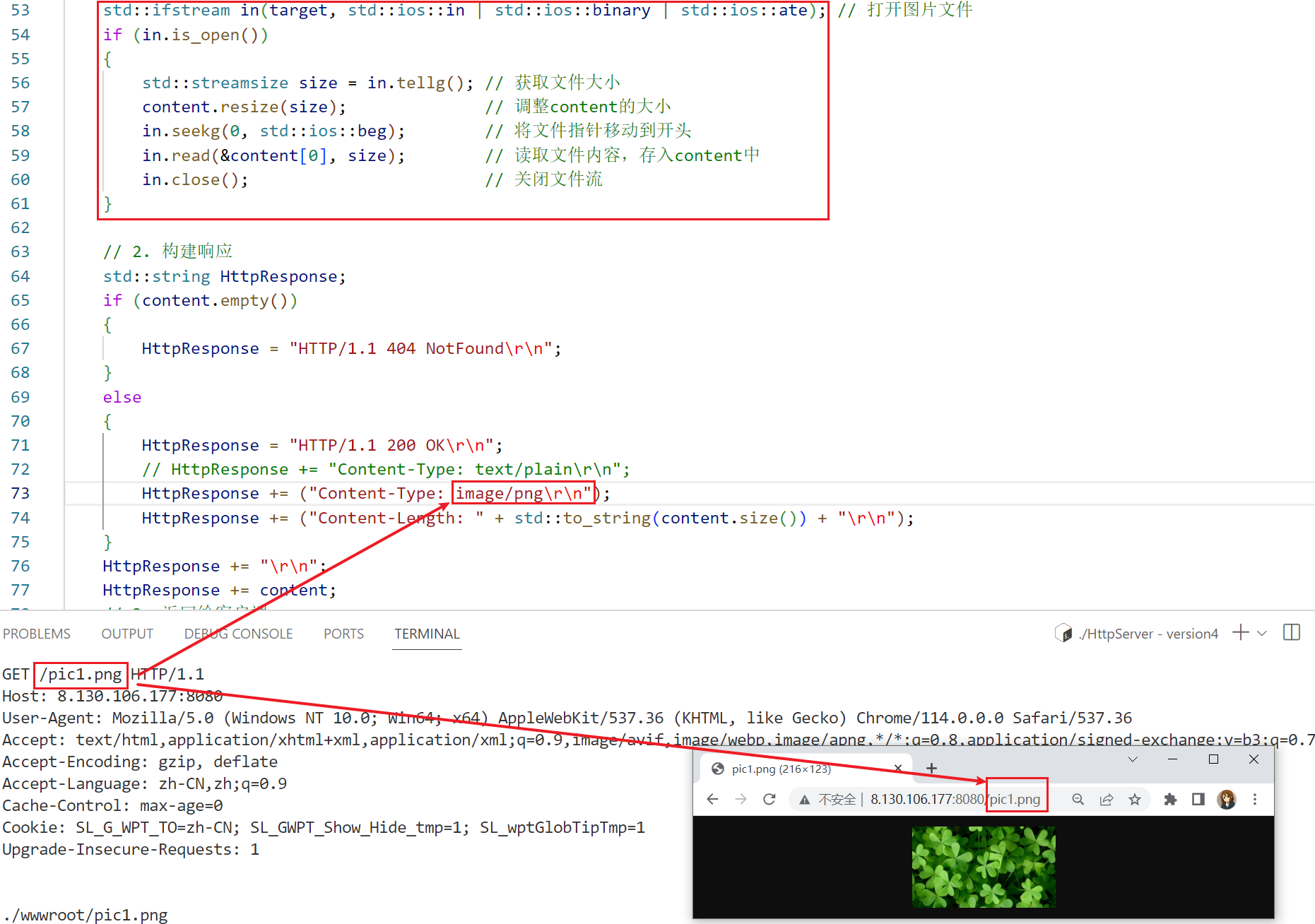
如果要传输图片,就要保证不能破坏图片的二进制格式,那么就不应该对它进行字符串分割,所以要用适合图片的方式,将图片的二进制序列放到content字符串中。
在测试的过程中,图片最好不要太大,因为服务器的网速可能不会太快。
Host
HTTP Header中的Host字段表示的是:
- 请求消息中的目标URI的主机和端口信息,使得源服务器能够在为多个主机提供服务时区分不同的资源。
- 如果请求消息中没有Host字段或者有多个Host字段,服务器会返回400 Bad Request的状态码。
- Host字段是HTTP/1.1协议中必须发送的请求头之一,它可以支持虚拟主机的功能,即在同一个IP地址和端口上运行多个网站。
host header存在的意义是什么?客户端本身就是要访问服务端的,IP和PORT属于客户端请求的一部分,服务端还要响应IP和端口,是不是多余的操作?
Host header存在的意义是支持虚拟主机的功能,即在同一个IP地址和端口上运行多个网站。如果没有Host header,服务器就无法根据请求的域名来判断应该返回哪个网站的内容。例如,假设有两个网站www.example.com和www.example.net,它们都使用同一个IP地址和端口80,那么当客户端请求http://www.example.com时,服务器就需要知道客户端想要访问的是www.example.com而不是www.example.net,这就需要客户端在请求头中发送Host: www.example.com这样的信息。如果没有这样的信息,服务器就只能返回默认的网站或者错误信息。
一般而言,同一个IP地址和端口上运行多个网站一般提供以下服务:
- 虚拟主机服务,即通过域名来区分不同的网站,让多个客户共享同一个服务器的资源,降低成本和管理复杂度。
- 网站建设和托管服务,即通过提供模板和工具来帮助客户创建和维护自己的网站,无需专业的技术知识。
- 云计算和云存储服务,即通过提供可扩展的计算和存储资源来满足客户的不同需求,提高性能和安全性。
User-Agent
客户端对应的操作系统和浏览器的版本信息。例如我用手机查看刚才的图片:

服务端接收到的请求内容就包含了客户端的设备和软件信息。
Referer
HTTP Referer Header是一个请求类型的Header,用于标识请求的前一个网页的地址,即用户是从哪个网页链接到当前请求的网页或资源的。这个Header可以让服务器和网站识别流量的来源,用于分析、日志、优化缓存等目的。但是,这个Header也会增加用户隐私和安全的风险,因为它可能会泄露用户的浏览历史或敏感信息。
下面是一个Referer: URL例子
Referer: https://developer.mozilla.org/en-US/docs/Web/JavaScript
阮一峰:HTTP Referer 教程
Keep-Alive
在使用TCP Socket实现客户端和服务端时,我们知道TCP是面向连接的,在双方通信之前,服务端和客户端必须建立连接。但是很多情况下服务端只有一个,HTTP/1.0的常用实现方式是在建立连接以后客户端发送请求给服务端,服务端处理请求,返回响应信息。
问题在于,如果每一次客户端和服务端交互时都重新建立连接,这对服务器是个灾难,十分浪费资源。HTTP/1.1支持长连接,即一个客户端可以连续像服务端一次性发送多个请求,这些请求将会同时发送,这种模式叫做HTTP管道化。但由于并没有很强的规范保证其安全性,HTTP管道化并没有广泛地被使用,而是被HTTP/2中的多路复用机制所取代。
如果HTTP请求或响应报头当中的Connect字段对应的值是Keep-Alive,就代表支持长连接。
HTTP Connect Header中的Keep-Alive是一个通用类型的Header,用于暗示连接的状态,以及设置超时时长和最大请求数。它还可以用于允许一个TCP连接保持打开,以便多个HTTP请求/响应复用(默认情况下,HTTP连接在每个请求后关闭)。
下面是一个Keep-Alive: parameters例子:
Keep-Alive: timeout=5, max=1000
timeout: 一个整数,表示空闲连接保持打开的最小时间(以秒为单位)。如果没有在传输层设置keep-alive TCP消息,那么大于TCP层面的超时设置会被忽略。
max: 一个整数,表示在连接关闭之前,可以在此连接上发送的最大请求数。在非管道连接中,除了0以外,这个值是被忽略的,因为需要在紧跟着的响应中发送新一次的请求。HTTP管道连接则可以用它来限制管道的使用。
8. 会话管理
8.1 HTTP 是不保存状态的协议
HTTP 是一种不保存状态,即无状态(stateless)协议。HTTP 协议自身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理。
简单地说,HTTP的每次请求与响应之间是没有任何关系的,但是我们实际体验中却并不是这样,例如你第一次使用了(请求)某个网站的登录服务(响应),即使重启了浏览器或机器以后,在很长一段时间内都可以保持登录状态。
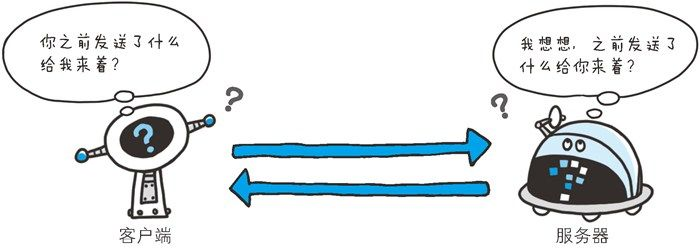
使用 HTTP 协议,每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计成如此简单的。
可是,随着 Web 的不断发展,因无状态而导致业务处理变得棘手的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能够掌握是谁送出的请求,需要保存用户的状态。
HTTP/1.1 虽然是无状态协议,但为了实现期望的保持状态功能,于是引入了 Cookie 技术。有了 Cookie 再用 HTTP 协议通信,就可以管理状态了。
8.2 使用 Cookie 的状态管理
HTTP 是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求处理。假设要求登录认证的 Web 页面本身无法进行状态的管理(不记录已登录的状态),那么每次跳转新页面不是要再次登录,就是要在每次请求报文中附加参数来管理登录状态。
不可否认,无状态协议当然也有它的优点。由于不必保存状态,自然可减少服务器的 CPU 及内存资源的消耗,如果让服务器管理全部客户端状态则会成为负担。从另一侧面来说,也正是因为 HTTP 协议本身是非常简单的,所以才会被应用在各种场景里。
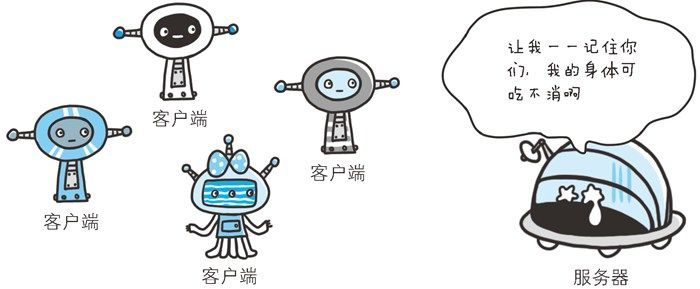
保留无状态协议这个特征的同时又要解决类似的矛盾问题,于是引入了 Cookie 技术。Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。
Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。
服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
Set-Cookie Header
当服务器准备开始管理客户端的状态时,会事先告知各种信息。
下面的表格列举了 Set-Cookie 的字段值。
| 属性 | 说明 |
|---|---|
| NAME=VALUE | 赋予 Cookie 的名称和其值(必需项) |
| expires=DATE | Cookie 的有效期(若不明确指定则默认为浏览器关闭前为止) |
| path=PATH | 将服务器上的文件目录作为Cookie的适用对象(若不指定则默认为文档所在的文件目录) |
| domain=域名 | 作为 Cookie 适用对象的域名 (若不指定则默认为创建 Cookie 的服务器的域名) |
| Secure | 仅在 HTTPS 安全通信时才会发送 Cookie |
| HttpOnly | 加以限制,使 Cookie 不能被 JavaScript 脚本访问 |
Cookie 标记状态
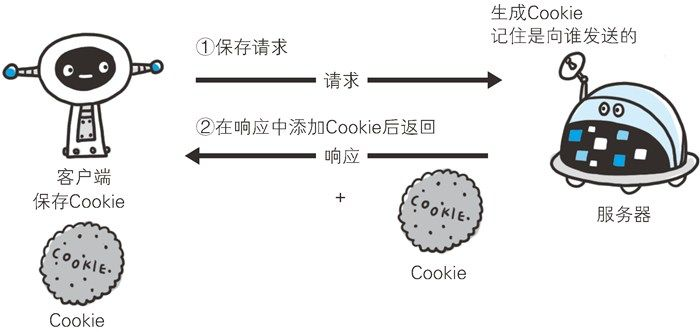
没有 Cookie 信息状态下的请求:
第 2 次以后(存有 Cookie 信息状态)的请求:
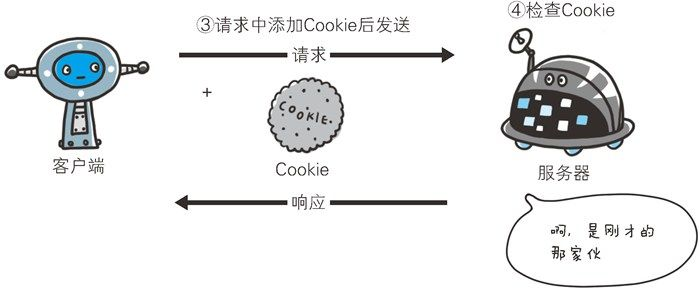
上图展示了发生 Cookie 交互的情景,我们可以体会到, Cookie 实际上就是一个保存着用户私密信息(如ID和PASSWORD)的数据包,它随着通信的方向一起传输。
对应的 HTTP 请求报文和响应报文的内容如下。
- 请求报文(没有 Cookie 信息的状态)
GET /reader/ HTTP/1.1
Host: hackr.jp
*首部字段内没有Cookie的相关信息
- 响应报文(服务器端生成 Cookie 信息)
HTTP/1.1 200 OK
Date: Thu, 12 Jul 2012 07:12:20 GMT
Server: Apache
<Set-Cookie: sid=1342077140226724; path=/; expires=Wed,
10-Oct-12 07:12:20 GMT>
Content-Type: text/plain; charset=UTF-8
- 请求报文(自动发送保存着的 Cookie 信息)
GET /image/ HTTP/1.1
Host: hackr.jp
Cookie: sid=1342077140226724
cookie数据可以由服务端生成,也可以由客户端生成。一般来说,服务端生成的cookie数据是用于保存用户的登录状态、购物车信息、偏好设置等,而客户端生成的cookie数据是用于保存用户在浏览器中输入的表单信息、浏览历史等。
-
服务端生成的cookie数据是通过在响应头中发送Set-Cookie字段来传递给客户端的,客户端收到后会将cookie数据存储在本地,并在后续的请求头中发送Cookie字段来回传给服务。
-
[暂不考虑]客户端生成的cookie数据是通过JavaScript中的document.cookie属性来创建和修改的,这个属性可以读取和写入当前页面的cookie数据。
例如在Chrome浏览器中,可以管理Cookie数据,只要删除了保存着用户登录信息的cookie文件,就意味着这个用户的登录状态被抹掉,需要重新登录。
安全问题
由于Cookie数据保存着用户的私密信息,如果机器被植入木马或其他安全问题而造成Cookie文件被盗取,那么对方就能使用cookie文件以用户的身份登录网站。
解决办法是改变使用cookie的方式,即使用Session ID标定Cookie文件属于哪个会话。
8.2 会话管理
Session
会话(Session)指的是客户端和服务器之间的一系列交互,从客户端第一次请求服务器,到客户端关闭浏览器或者会话超时结束。
会话可以用来保存客户端的状态信息,比如登录状态,购物车内容等。会话是一种服务器端的机制,它使用Session ID来关联客户端的请求和会话对象。
“会话超时结束”是指当客户端在一定时间内没有向服务器发送任何请求时,服务器会认为该会话已经结束,并销毁对应的会话对象。会话超时的时间可以由服务器端设置,一般默认为20分钟。如果用户设置了长连接,也就是Keep-Alive,那么只要客户端和服务器之间保持TCP连接,就不会触发会话超时。但是,如果客户端清除了Cookie,或者服务器端主动销毁了会话,那么会话也会结束,无论是否设置了Keep-Alive。
Session ID
Session ID是一种用于标识客户端和服务器之间会话的唯一标识符。
“标识性”主要取决于Cookie的domain和path属性。Cookie的domain属性指定了Cookie所属的域名,只有在该域名下的请求才会携带该Cookie。Cookie的path属性指定了Cookie所属的路径,只有在该路径下的请求才会携带该Cookie。通过这两个属性,可以限制Session ID只在特定的域名和路径下有效,从而保证了Cookie文件的归属性。
注意:
- Session ID 通常是一个随机生成的字符串,存储在 Cookie 中,或者附加在 URL 后面。服务器可以根据 Session ID 检索或创建与客户端相关的会话信息,比如用户的登录状态,购物车内容等。Session ID 可以保持客户端和服务器之间的状态,因为 HTTP 协议本身是无状态的。
- Session ID本身并不包含客户端的信息,它只是一个随机生成的字符串,用来标识服务器端的会话。 但是,通过 Session ID,服务器可以从会话中获取客户端的相关信息,比如用户名,密码等。所以,Session ID 可以间接地标识客户端的身份。
- 一个 Session ID 只能标识一个会话,但是一个会话可以包含多次请求和响应。 当客户端关闭浏览器或者会话超时结束时,会话就结束了,Session ID 也就失效了。 下次客户端再次请求服务器时,就会生成一个新的Session ID,开始一个新的会话。 除非服务器端设置了 Session ID 的持久化,否则 Session ID 是不会被重用的。
“Session ID的持久化”指的是服务器端在会话结束后,不会删除Session ID,而是将其保存到磁盘或数据库中,以便下次客户端请求时可以重新加载。这样可以避免客户端每次请求都需要重新生成Session ID,提高了效率和安全性。但是,这也需要客户端保留Cookie文件,否则无法携带Session ID。
Cookie的安全性和Session ID的持久化是两个不同的问题,Cookie的安全性主要涉及到Cookie的加密,签名,域名,路径等属性,以及客户端和服务器端的验证机制。 Session ID的持久化主要涉及到服务器端的存储和加载机制,以及客户端是否保留Cookie文件。
xx持久化,一般指的就是将内存中的数据保存到磁盘中。

Session ID的存在,使得Cookie文件不再存储私密信息,而是存储私密信息通过算法得到的唯一ID值,只要用户第一次登录,服务器就会为这个会话生成一个唯一的ID,然后通过网络传输到客户端,后续再访问时浏览器会自动携带Session ID作为报文的一部分递交给服务端,这样就相当于拿到了一个长期门禁,服务端只要验证客户端发来的Session ID和本地的Session ID的一致性就能实现保存用户(登录)状态的效果。
8.3 只有相对的安全
Session ID不是绝对安全的,它可能会被劫持,伪造,破解等。例如保存着Session ID的Cookie文件被盗取,那么中间人也能通过它来登录网站,和之前保存着用户的隐私信息的Cookie文件不同的是,中间人无法得知用户的隐私信息,因为隐私信息在服务端通过算法被映射为了一个唯一的字符串ID。
Session ID的安全性取决于多个因素,比如Cookie的设置,网络的加密,服务器端的存储和验证等。为了提高Session ID的安全性,可以采取一些措施,比如使用HTTPS,设置Cookie的HttpOnly和Secure属性,使用加密和签名算法,设置Session ID的有效期和更新机制等。
有了Session ID,用户的隐私信息就被客户端维护,而不是由浏览器维护。
以SessionID的有效性为例:
- 当异地登录QQ时,它会显示警告信息,当服务器发现IP地址发生更改后,很可能会立即清除之前保存的Session ID,那么用户就要重新登录以更新Session ID。盗号者的“养号”行为就相当于渡过Cookie设置的有效期。
- 对于某些高风险的服务,服务器可能会要求客户端再次输入密码以验证身份,这个步骤的目的不仅是给用户再次考虑的时间,更是验证用户的身份信息。因为中间人盗取了Session ID后,是有可能进行这一步骤的,但是生成Session ID的算法并不是可逆的,无法倒推出用户的隐私信息。所以即使中间人盗取了用户的Session ID,也无法进行这些被限制的操作,在一定程度上减轻了信息被盗取的风险。
“不存在绝对安全的算法或机制”:
在这个问题上,不同的人可能有不同的观点。 有些人认为,只要有足够的时间和资源,任何算法或机制都可能被破解,所以不存在绝对安全的算法或机制。 有些人认为,有些算法或机制是基于数学原理或物理定律的,所以它们是无法被破解的,比如一次性密码本,量子密码等。
我个人认为,不存在绝对安全的算法或机制,只有相对安全的算法或机制。理论上可以穷举所有的可能性,只不过其代价会超出想象,如果破解带来的利益远远小于破解的成本,那也就没有破解的必要,这就是相对安全的算法或机制。技术本身一直在进步,或许当下需要千年才能破译的算法,在不久的以后只要十几分钟,安全性在风险下才是有意义的。
突然想到《纸牌屋》里的黑客运用社会工程学不惜冒着风险肉身接近别人,操纵人的心理,这间接证明了直接破解的难度。
此外,Cookie分为两种类型:
-
会话Cookie是一种临时的Cookie,它保存在浏览器的内存中,当浏览器关闭后,它就会消失。会话Cookie用来保存用户在访问网站时的一些状态信息,比如登录状态,购物车内容等。
-
持久Cookie是一种长期的Cookie,它保存在用户的硬盘或数据库中,有一个过期时间,除非用户手动清除或到了过期时间,否则它不会被删除。持久Cookie用来保存用户的一些偏好设置,比如语言,主题等,或者用来实现自动登录等功能。
意义:
Cookie的类型对于用户和网站的体验和安全性都有影响。一般来说,会话Cookie比持久Cookie更安全,因为它不会被长期保存在用户的设备上,也不容易被劫持或伪造。但是,会话Cookie也有一些缺点,比如它不能跨浏览器使用,也不能保留用户的个性化设置。持久Cookie则相反,它可以提高用户的体验和便利性,但也增加了安全风险。所以,在使用Cookie时,应该根据不同的场景和需求,选择合适的类型,并且注意设置合理的过期时间和其他属性。
8.4 测试
在服务端响应信息中增加set-cookie字段,这样客户端就会创建Cookie文件,并将信息填充。
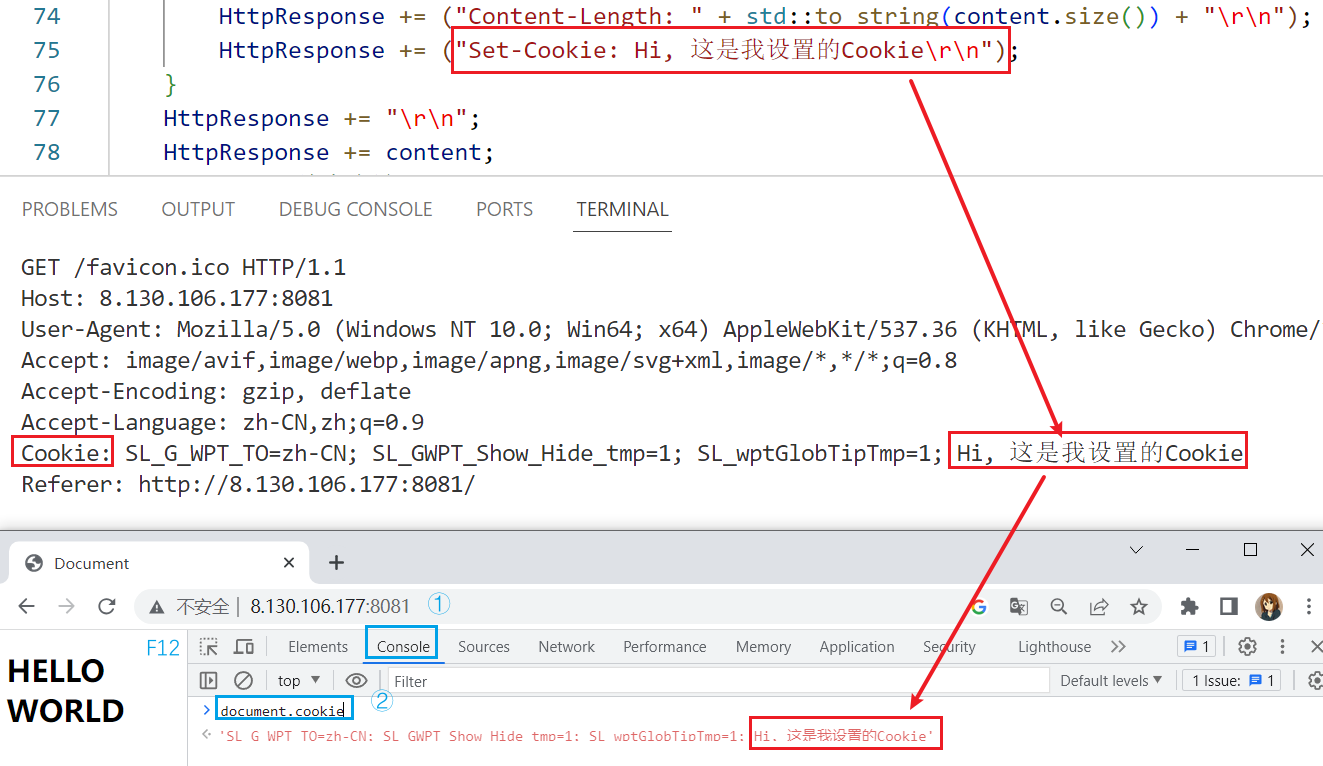
由于当前版本的Chrome浏览器(114.0.5735.110)无法像旧版本一样直接从网址框旁边的按钮查看Cookie信息。所以首先要按F12进入调试模式,然后在Console(控制台)键入document.cookie,就能看到服务端填充的Cookie数据。
这只是一个简单的代码,演示了服务端是如何填充信息到客户端生成的Cookie文件中的,并不能做到会话管理,因为还缺少身份验证和时效性等细节。事实上,这些用户信息一般都是从表单中获取的。
另外,还能用一个抓包工具fiddler来测试:
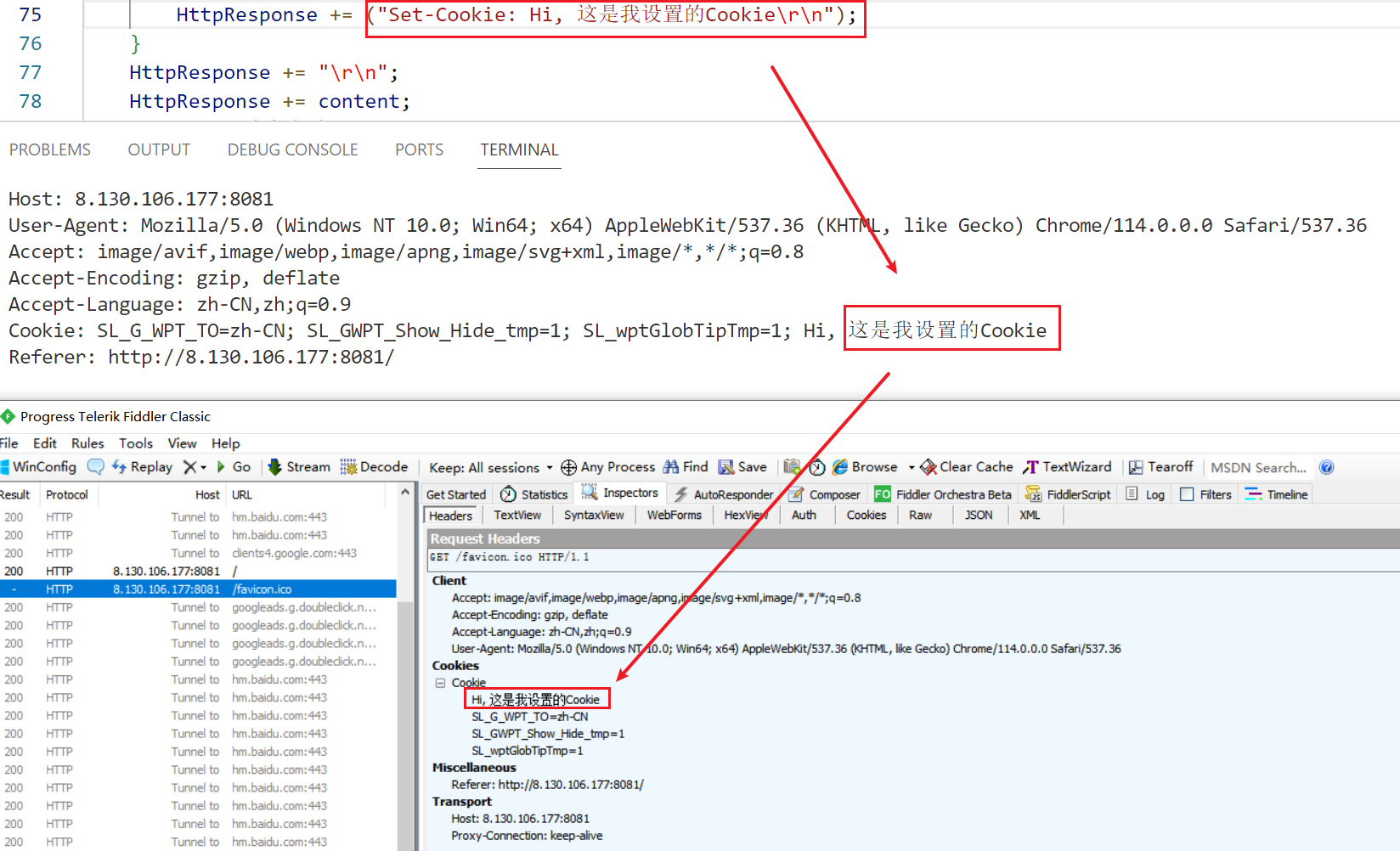
fiddler是一个针对HTTP的抓包工具,可以抓取到本机的所有HTTP请求。
源代码:HttpServer Version 4
参考资料
- 图解HTTP.epub。本文中的许多插图和概念阐述都来源于本书,一图胜千言,十分推荐初学者学习,可以使用工具calibre阅读。
- 维基百科
- 博客:应用层协议 ——— HTTP协议
Cookie的类型对于用户和网站的体验和安全性都有影响。一般来说,会话Cookie比持久Cookie更安全,因为它不会被长期保存在用户的设备上,也不容易被劫持或伪造。但是,会话Cookie也有一些缺点,比如它不能跨浏览器使用,也不能保留用户的个性化设置。持久Cookie则相反,它可以提高用户的体验和便利性,但也增加了安全风险。所以,在使用Cookie时,应该根据不同的场景和需求,选择合适的类型,并且注意设置合理的过期时间和其他属性。
8.4 测试
在服务端响应信息中增加set-cookie字段,这样客户端就会创建Cookie文件,并将信息填充。
由于当前版本的Chrome浏览器(114.0.5735.110)无法像旧版本一样直接从网址框旁边的按钮查看Cookie信息。所以首先要按F12进入调试模式,然后在Console(控制台)键入document.cookie,就能看到服务端填充的Cookie数据。
这只是一个简单的代码,演示了服务端是如何填充信息到客户端生成的Cookie文件中的,并不能做到会话管理,因为还缺少身份验证和时效性等细节。事实上,这些用户信息一般都是从表单中获取的。
另外,还能用一个抓包工具fiddler来测试:
fiddler是一个针对HTTP的抓包工具,可以抓取到本机的所有HTTP请求。
源代码:HttpServer Version 4
参考资料
- 图解HTTP.epub。本文中的许多插图和概念阐述都来源于本书,一图胜千言,十分推荐初学者学习,可以使用工具calibre阅读。
- 维基百科
- 博客:应用层协议 ——— HTTP协议