Vision Transformer综述
- 1. Transformer简介
- 2. Transformer组成
- 2.1 Self-Attention
- Multi-Head Attention(多头注意力)
- 2.2 Transformer的其他关键概念
- 2.2.1 Feed-Forward Network 前馈网络
- 2.2.2 Residual Connection 残差连接
- 2.2.3 解码器中的最后一层
1. Transformer简介
Transformer首先应用于自然语言处理领域,是一种以自我注意机制为主的深度神经网络。由于其强大的表示能力,研究人员正在寻找将变压器应用于计算机视觉任务的方法。在各种视觉基准测试中,基于变压器的模型表现类似或优于其他类型的网络,如卷积和循环神经网络。由于其高性能和较少的视觉特异性感应偏倚需求,变压器正受到计算机视觉界越来越多的关注。在本文中,我们对这些视觉转换器模型进行了综述,并根据不同的任务对其进行了分类,分析了它们的优缺点。我们探讨的主要类别包括骨干网络、高/中级视觉、低级视觉和视频处理。我们还包括高效的变压器方法,用于将变压器推入基于实际设备的应用程序。此外,我们还简要介绍了计算机视觉中的自注意机制,因为它是变压器的基本组件。在本文的最后,我们讨论了视觉变压器所面临的挑战,并提出了进一步的研究方向。
在这里,我们回顾了与基于变压器的视觉模型相关的工作,以跟踪这一领域的进展。图1展示了视觉变压器的发展时间表——毫无疑问,未来会有更多的里程碑。
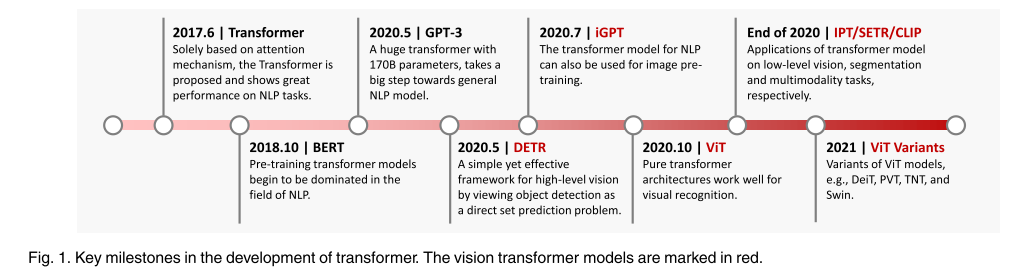
图1,Transformer发展的关键里程碑。视觉Transformer型号用红色标注。
2. Transformer组成
Transformer首次被用于机器翻译任务的自然语言处理(NLP)领域。如图2,原始变压器的结构。它由一个编码器和一个解码器组成,其中包含几个具有相同架构的转换器块。
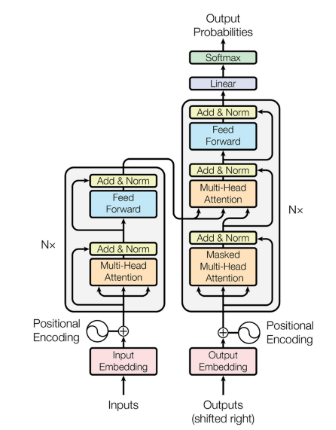
编码器生成输入的编码,而解码器获取所有编码并使用它们合并的上下文信息来生成输出序列。每个变压器块由多头注意层、前馈神经网络、快捷连接和层归一化组成。下面,我们详细描述变压器的每个组成部分。
2.1 Self-Attention
在自注意层,首先将输入向量转换为三个不同的向量:
-
查询向量(query vector)q
-
键(key vector)向量k
-
值向量(value vector)v
三种向量的维数d(q、k、v)=d(model)=512,由不同输入导出的向量被打包成三个不同的矩阵,即Q、K和V。然后,计算出不同输入向量之间的注意函数,如下图3所示:
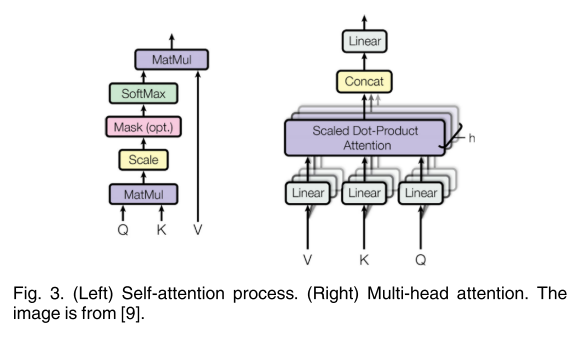
Step 1:计算不同输入向量之间的得分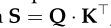
Step 2:对梯度的稳定性分数进行归一化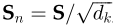
Step 3:使用softmax函数将得分转化为概率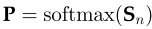
Step 4:求加权值矩阵Z=V*P
该过程可以统一为一个单一函数(dk=模型维度=512)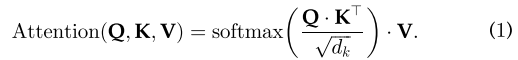
公式(1)背后的逻辑很简单。
Step 1 计算每对不同向量之间的分数,这些分数决定了我们在编码当前位置的单词时给予其他单词的关注程度
Step 2 将分数归一化,以增强梯度稳定性,用于改进训练;
Step 3 将分数转化为概率。
最后,将每个值向量乘以概率的和。具有较大概率的向量将获得额外的注意。
解码器模块中的编码器-解码器注意层类似于编码器模块中的自注意层,但有以下例外:密钥矩阵K和值矩阵V由编码器模块导出,查询矩阵Q由上一层导出。
注意,前面的过程对每个单词的位置是不变的,这意味着自我注意层缺乏捕捉单词在句子中的位置信息的能力。然而,语言中句子的顺序性要求我们在编码中整合位置信息。为了解决这个问题并获得单词的最终输入向量,在原始的输入嵌入中添加了一个维度为dmodel的位置编码。具体地说,这个位置是用下面的公式编码的

Pos表示单词在句子中的位置,i 表示位置编码的当前维度。通过这种方式,位置编码的每个元素都对应于一个正弦波,它允许变压器模型学习通过相对位置参与,并在推理过程中外推到更长的序列长度。
除了vanilla transformer中的固定位置编码外,各种模型中还使用了习得的位置编码和相对位置编码。
Multi-Head Attention(多头注意力)
多头注意是一种可以用来提高vanilla自我注意层性能的机制。
注意,对于一个给定的参考词,我们通常想要在整个句子中关注其他几个词。一个单一的自我注意层限制了我们专注于一个或多个特定位置的能力,而不会同时影响对其他同等重要位置的注意。这是通过给注意层不同的表示子空间来实现的。
具体来说,对于不同的头部使用不同的查询矩阵、键值矩阵,这些矩阵通过随机初始化,训练后可以将输入向量投射到不同的表示子空间中。
为了更详细地说明这一点,给定一个输入向量和注意头数量h,dmodel=模型维度
-
首先将输入向量转换为三组不同的向量:查询组(query group)、键组(key group)和值组(value group)
-
在每一个组中。有h个维度为dq=dk’=dv’=dmodel/h=64的向量
-
然后,从不同输入导出的向量被打包成三组不同的矩阵:
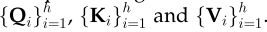
-
多头注意过程如下图所示:

其中,Q’(K’,V’同理)是{Qi}的串联,Wo是投影权值。
2.2 Transformer的其他关键概念
2.2.1 Feed-Forward Network 前馈网络
在每个编码器和解码器的自注意层之后采用前馈网络(FFN)。它由两个线性变换层和其中的一个非线性激活函数组成,可以表示为以下函数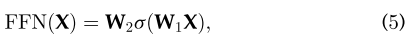 其中w1、w2为两个线性变换层的两个参数矩阵,s为非线性激活函数,如GELU。隐藏层的维度为dh=2048。
其中w1、w2为两个线性变换层的两个参数矩阵,s为非线性激活函数,如GELU。隐藏层的维度为dh=2048。
2.2.2 Residual Connection 残差连接
如图2中所示,在编码器和解码器的每个子层中增加一个剩余的连接(黑色箭头)。
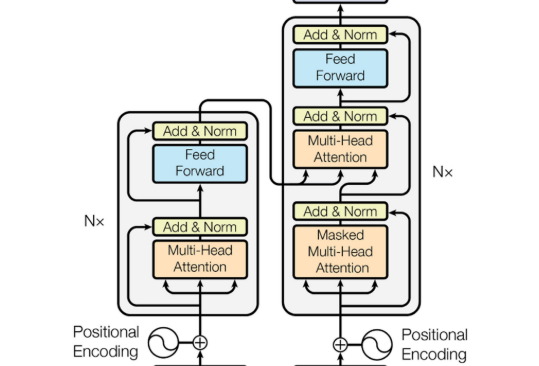
这加强了信息流,以实现更高的性能。在剩余连接之后,采用层归一化。这些操作的输出可以描述为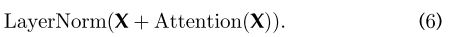
X作为自我注意层的输入,查询、键值矩阵Q、K和V都来自同一个输入矩阵X。
2.2.3 解码器中的最后一层
解码器中的最后一层用于将向量堆栈转换回一个单词。这是通过一个线性层和一个softmax层实现的。
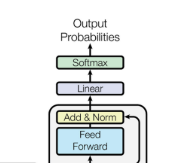
线性层将该向量投影为具有dword维数的logits向量,其中dword是词汇表中的单词数。然后使用softmax层将logit向量转换为概率。
当用于CV(计算机视觉)任务时,大多数变压器采用原变压器的编码器模块。这种变压器可以看作是一种新型的特征提取器。与只关注局部特征的CNN(卷积神经网络)相比,变压器可以捕获长距离的特征,这意味着它可以很容易地获得全局信息。
与必须顺序计算隐藏状态的RNN(循环神经网络)相比,变压器的效率更高,因为自注意层和全连接层的输出可以并行计算,且易于加速。由此,我们可以得出结论,进一步研究变压器在计算机视觉和自然语言处理中的应用将会产生有益的结果。