系列文章目录
广告数仓:采集通道创建
文章目录
- 系列文章目录
- 前言
- 一、环境和模拟数据准备
- 1.hadoop集群
- 2.mysql安装
- 3.生成曝光测试数据
- 二、广告管理平台数据采集
- 1.安装DataX
- 2.上传脚本生成器
- 3.生成传输脚本
- 4.编写全量传输脚本
- 三、曝光点击检测数据采集
- 1.安装Zookeeper
- 2.安装Kafka
- 3.安装Flume
- 4.Local Files->Flume->Kafka
- 1.编写Flume配置文件
- 2.功能测试
- 3.编写启动脚本
- 5.Kafka->Flume->HDFS
- 1.编写拦截器
- 2.编写配置文件
- 3.测试功能
- 4.编写启动脚本
- 总结
前言
常用的大数据技术,基本都学完,啃个项目玩玩,这个项目来源于尚桂谷最新的广告数仓
一、环境和模拟数据准备
1.hadoop集群
集群搭建可以看我的hadoop专栏
这里不在演示了。
建议吧hadoop把hadoop版本换成3.3.4不然后期可能会有依赖错误(血的教训)
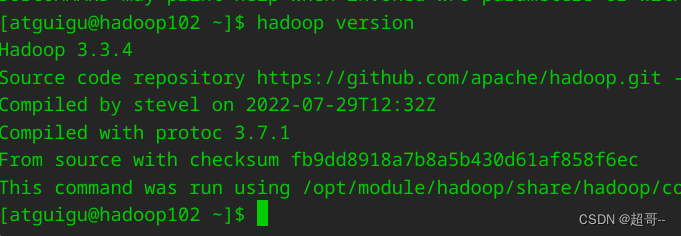
2.mysql安装
此次项目使用的是Mysql8,所有实验需要的软件可以在B站尚桂谷平台找到。
上传jar包

卸载可能影响的依赖
sudo yum remove mysql-libs
安装需要的依赖
sudo yum install libaio autoconf
用安装脚本一键安装
sudo bash install_mysql.sh
安装完成后后远程连接工具测试一下。
由于mysql8新增了一个公钥验证,所以我们要修改一个默认参数
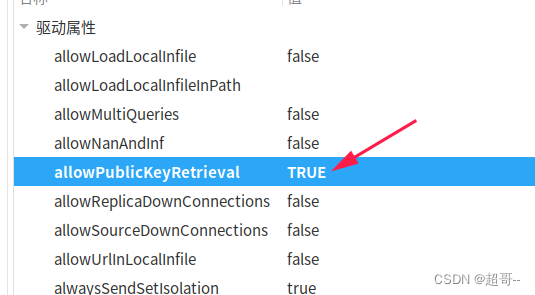
之后新建数据库,将我们的广告平台管理数据导入

3.生成曝光测试数据
上传数据模拟器文件
这里稍微修改一个配置文件,把刚刚的公钥检测加上

java -jar NginxDataGenerator-1.0-SNAPSHOT-jar-with-dependencies.jar

我门用hadoop102和hadoop103来生成曝光数据
scp -r ad_mock/ 192.168.10.103:/opt/module/ad_mock
创建一个生成脚本
#!/bin/bash
for i in hadoop102 hadoop103
do
echo "========== $i =========="
ssh $i "cd /opt/module/ad_mock ; java -jar /opt/module/ad_mock/NginxDataGenerator-1.0-SNAPSHOT-jar-with-dependencies.jar >/dev/null 2>&1 &"
done
二、广告管理平台数据采集
1.安装DataX
datax是阿里的一个开源工具,作用和sqoop差不多,主要是用来在不同数据库之间传输数据
github官方下载链接
也可以用资料里给的
直接解压即可
然后执行自带的一个测试脚本

python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json

2.上传脚本生成器

按需要修改一下脚本

mysql.username=root
mysql.password=000000
mysql.host=hadoop102
mysql.port=3306
hdfs.uri=hdfs://hadoop102:8020
is.seperated.tables=0
mysql.database.import=ad
mysql.tables.import=
import_out_dir=/opt/module/datax/job/import
3.生成传输脚本
java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
4.编写全量传输脚本
vim ~/bin/ad_mysql_to_hdfs_full.sh
#!/bin/bash
DATAX_HOME=/opt/module/datax
# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {
hadoop fs -test -e $1
if [[ $? -eq 1 ]]; then
echo "路径$1不存在,正在创建......"
hadoop fs -mkdir -p $1
else
echo "路径$1已经存在"
fs_count=$(hadoop fs -count $1)
content_size=$(echo $fs_count | awk '{print $3}')
if [[ $content_size -eq 0 ]]; then
echo "路径$1为空"
else
echo "路径$1不为空,正在清空......"
hadoop fs -rm -r -f $1/*
fi
fi
}
#数据同步
#参数:arg1-datax 配置文件路径;arg2-源数据所在路径
import_data() {
handle_targetdir $2
python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$2" $1
}
case $1 in
"product")
import_data /opt/module/datax/job/import/ad.product.json /origin_data/ad/db/product_full/$do_date
;;
"ads")
import_data /opt/module/datax/job/import/ad.ads.json /origin_data/ad/db/ads_full/$do_date
;;
"server_host")
import_data /opt/module/datax/job/import/ad.server_host.json /origin_data/ad/db/server_host_full/$do_date
;;
"ads_platform")
import_data /opt/module/datax/job/import/ad.ads_platform.json /origin_data/ad/db/ads_platform_full/$do_date
;;
"platform_info")
import_data /opt/module/datax/job/import/ad.platform_info.json /origin_data/ad/db/platform_info_full/$do_date
;;
"all")
import_data /opt/module/datax/job/import/ad.product.json /origin_data/ad/db/product_full/$do_date
import_data /opt/module/datax/job/import/ad.ads.json /origin_data/ad/db/ads_full/$do_date
import_data /opt/module/datax/job/import/ad.server_host.json /origin_data/ad/db/server_host_full/$do_date
import_data /opt/module/datax/job/import/ad.ads_platform.json /origin_data/ad/db/ads_platform_full/$do_date
import_data /opt/module/datax/job/import/ad.platform_info.json /origin_data/ad/db/platform_info_full/$do_date
;;
esac
赋予执行权限
然后启动hadoop集群
执行脚本
ad_mysql_to_hdfs_full.sh all 2023-01-07
三、曝光点击检测数据采集
1.安装Zookeeper
Zookeeper安装
2.安装Kafka
Kafka安装
kafka安装大部分都要把专栏方法相同,不同点是要添加一个配置参数。
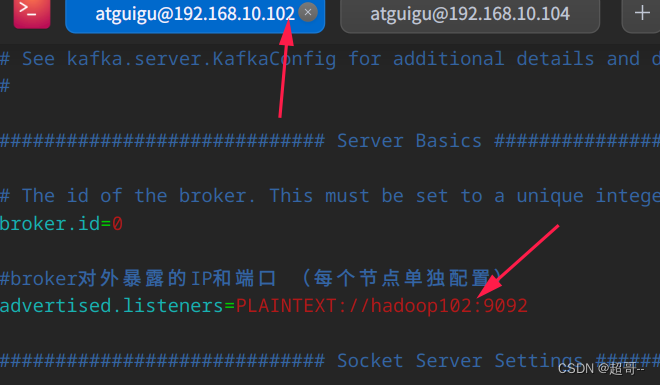
每个节点都要做对应的修改
3.安装Flume
Flume安装
我们还需要修改一下日志文件


修改完成后分发即可。
4.Local Files->Flume->Kafka
1.编写Flume配置文件

#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/ad_mock/log/.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092
a1.channels.c1.kafka.topic = ad_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
2.功能测试
我们先启动zookeeper和kafka
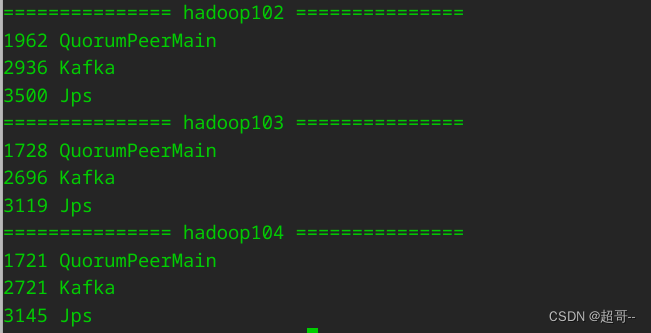
然后启动Flume进行日志采集
bin/flume-ng agent -n a1 -c conf/ -f job/ad_file_to_kafka.conf -Dflume.root.logger=info,console

然后在kafka启动一个ad_log消费者,如果没有他会自动创建
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ad_log
然后用ad_mock.sh生成数据,观察消费者是否能消费到数据。

3.编写启动脚本
因为ad_mock.sh在102和103同时生成数据,所以我们需要把102的配置文件同步过去。
scp -r job/ hadoop103:/opt/module/flume/
为flume编写一个启动脚本
vim ~/bin/ad_f1.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/ad_file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep ad_file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
编写之后启动它
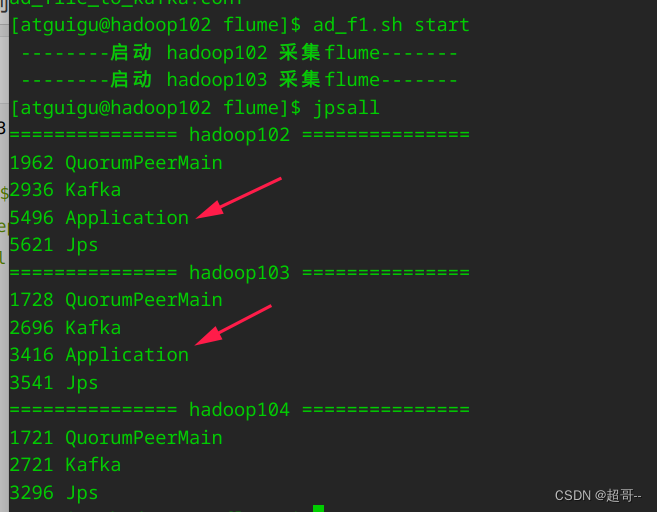
再次启动kafka消费者,然后生成数据,如果仍然能出现数据,说明脚本没问题。
5.Kafka->Flume->HDFS
1.编写拦截器
用idea创建一个Maven工程,名字随意。
添加Maven依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.11.0</version>
</dependency>
</dependencies>
创建拦截器类
TimestampInterceptor.java
package com.atguigu.ad.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TimestampInterceptor implements Interceptor {
private Pattern pattern;
@Override
public void initialize() {
pattern = Pattern.compile(".*t=(\\d{13}).*");
}
@Override
public Event intercept(Event event) {
// 提取数据中的时间戳,补充到header中
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
//去除日志中的双引号
String sublog = log.substring(1, log.length() - 1);
String result = sublog.replaceAll("\"\u0001\"", "\u0001");
event.setBody(result.getBytes(StandardCharsets.UTF_8));
// 正则匹配获取时间戳
Matcher matcher = pattern.matcher(result);
if (matcher.matches()) {
String ts = matcher.group(1);
headers.put("timestamp", ts);
} else {
return null;
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
Iterator<Event> iterator = events.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
Event intercept = intercept(next);
if (intercept == null) {
iterator.remove();
}
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
直接打包上传到104 flume/lib目录

2.编写配置文件
vim job/ad_kafka_to_hdfs.conf
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics = ad_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.ad.flume.interceptor.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/ad/log/ad_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.测试功能
将hadoop,zookeeper,kafka和之前配置的flume脚本全部启动
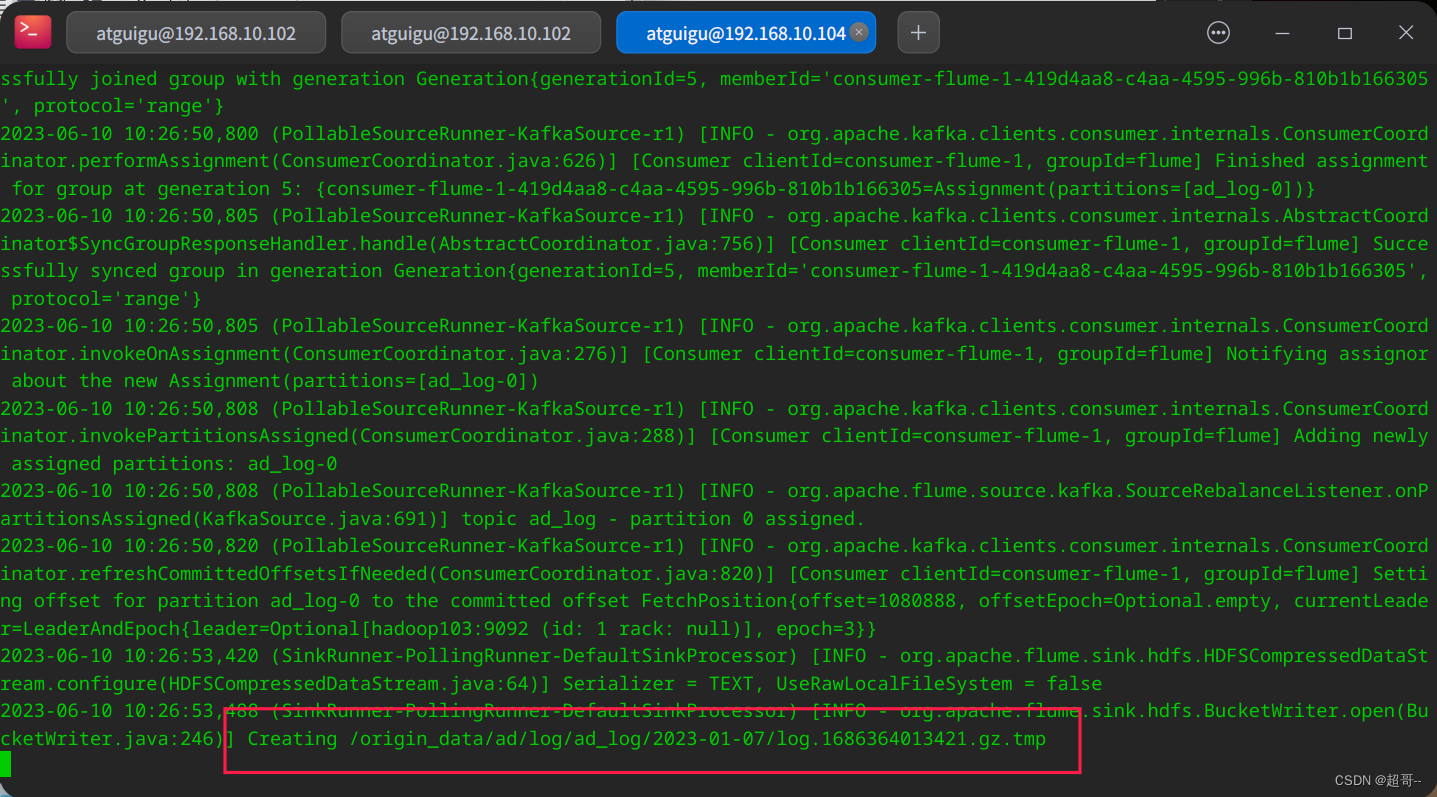
在104开启Flume采集
bin/flume-ng agent -n a1 -c conf/ -f job/ad_kafka_to_hdfs.conf -Dflume.root.logger=info,console
用ad_mock.sh生成数据。
4.编写启动脚本
vim ~/bin/ad_f2.sh
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/ad_kafka_to_hdfs.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep ad_kafka_to_hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
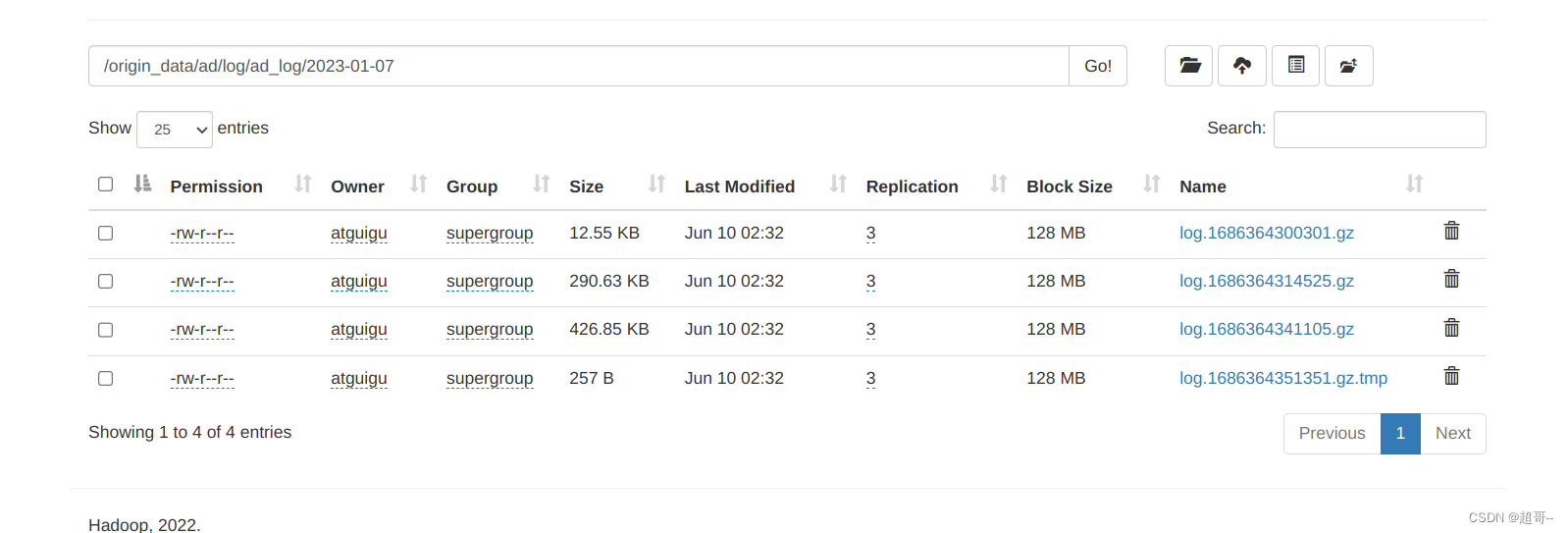
最后启动脚本在测试一下
总结
采集通道的创建就到这里了。