要落地一个机器学习的项目,是有章可循的,通过这六个步骤,小白也能搞定机器学习。
看我闪电六连鞭!🤣
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8fokt0Mq-1686313603676)(image/image-20230604123237459.png)]](https://img-blog.csdnimg.cn/d3b2350880c945fa89329782bb221f25.png)
数据的预处理通常包括 5 个步骤,如下:这个是比较完整的一个步骤,不同的算法可能会缺少一些步骤,例如无监督学习中,没有标签也就没有特征工程。
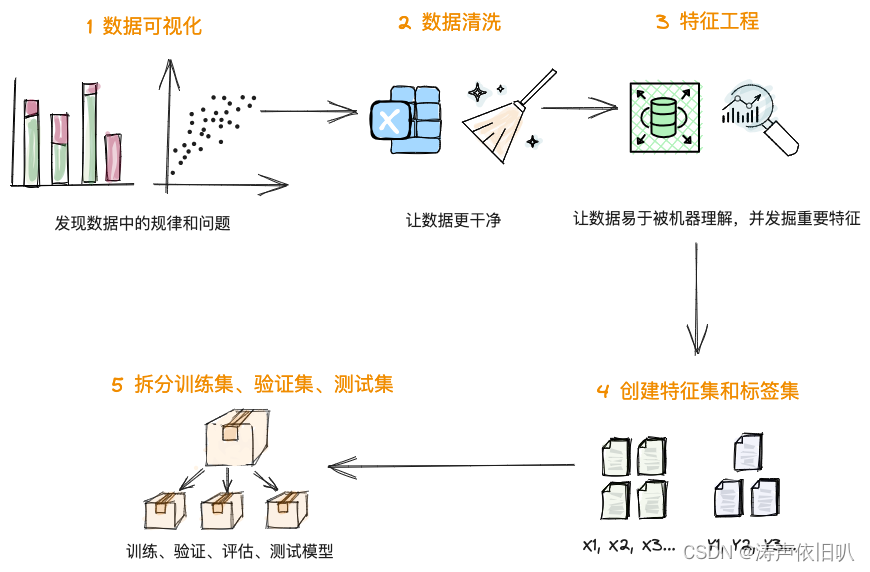
1、数据可视化
数据的可视化,可以帮我们发现数据中的规律和问题。通过数据可视化,我们可以从整体“俯瞰”数据的全貌。可以观察特征和标签之间可能存在哪些关系,以及观测 特殊数据。
可视化工具:自动化地进行数据可视化,并提供丰富的交互功能和可视化效果。常见的可视化工具包括Matplotlib、Seaborn等。
下面我们通过两个小例子感受一下 Matplotlib、Seaborn这两款可视化工具。
1)Matplotlib
首先我们要导入Matplotlib
#导入数据可视化所需要的库
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
matplotlib 包中的 plot API,来绘制出“点赞数”和“浏览量”之间的散点图,看看它们的分布状态。
plt.plot(df_ads['点赞数'],df_ads['浏览量'],'r.', label='Training data') # 用matplotlib.pyplot的plot方法显示散点图
plt.xlabel('点赞数') # x轴Label
plt.ylabel('浏览量') # y轴Label
plt.legend() # 显示图例
plt.show() # 显示绘图结果!

从这张图中我们可以看出来,这些数据基本上集中在一条线附近,所以点赞数和浏览量具有线性函数的关系,还可以发现其中有一些散点,他们就是 爆款文章。
2)SeaBorn
通过SeaBorn的 boxplot 工具画个箱线图。箱线图主要是看数据的分布和离散程度。通过下个图看看这个数据集里有没有“离群点”。
data = pd.concat([df_ads['浏览量'], df_ads['热度指数']], axis=1) # 浏览量和热度指数
fig = sns.boxplot(x='热度指数', y="浏览量", data=data) # 用seaborn的箱线图画图
fig.axis(ymin=0, ymax=800000); #设定y轴坐标

箱线图是由五个数值点组成,分别是最小值 (min)、下四分位数 (Q1)、中位数 (median)、上四分位数 (Q3) 和最大值 (max)。在统计学上,这叫做五数概括。这五个数值可以清楚地为我们展示数据的分布和离散程度。
这个图中下四分位数、中位数、上四分位数组成一个“带有隔间的盒子”,就是所谓的箱;上四分位数到最大值之间建立一条延伸线,就是所谓的线,也叫“胡须”;胡须的两极就是最小值与最大值;此外,箱线图还会将离群的数据点单独绘出
在上面这个箱线图中,我们发现,热度指数越高,浏览量的中位数越大。我们还可以看到,有一些离群的数据点,比其它的文章浏览量大了很多,这些“离群点”也是属于爆款文章。
2、数据清洗
数据清洗的目的是让数据变得更干净。不要小瞧它,越是干净的数据,模型的效果就越好。而脏数据会严重影响模型的效果

- 第一种是处理缺失的数据。如果备份系统里面有缺了的数据,那我们尽量修复;如果无法修复,我们可以剔除掉残缺的数据。
- 第二个是处理重复的数据:如果是完全相同的重复数据处理,删掉就行了。
- 第三个是处理错误的数据:比如商品的销售量、销售金额出现负值,这时候就需要删除异常数据。再比如表示百分比或概率的字段,如果值大于 1,也属于逻辑错误数据。
- 第四个是处理不可用的数据:这指的是整理数据的格式,比如身高来说有的记录成m 还有的记录成 cm,那我们需要把单位统一。另一个常见例子是把“是”、“否”转换成“1”、“0”值再输入机器学习模型。
除了手动清理数据,我们还可以借助工具来进行数据清理,比如Pandas库下的DataFrame。下面介绍几种常用的数据清理办法:
import pandas as pd # 导入Pandas
# 统计NaN数据
DataFrame.isna().sum()
# 删除重复行
DataFrame.drop_duplicates()
# 删除指定列的缺失值
DataFrame.dropna(subset=['订单时间', '订单编号', '企业名称', '订单总金额'])
3、特征工程
特征工程是一个专门的机器学习的子领域,是数据处理过程中最具创造力的一个环节。是机器学习当中非常重要的一环!
有句行话说的好:**数据和特征决定了机器学习的上限,而模型和算法只是无限逼近这个上限而已。**足见特征工程的重要性!
什么是特征工程?
特征工程是将原始数据转化成更好的表达问题本质的特征的过程,使得将这些特征运用到预测模型中能提高对不可见数据的模型预测精度。
通俗的讲,特征工程简单讲就是发现对因变量y(标签)有明显影响作用的自变量x(特征),特征工程的目的是发现重要特征。
特征工程通常需要对业务有足够的了解,它是基于业务逻辑,从众多的特征中摒弃掉冗余的特征、降低特征的维度,提升机器学习模型的性能。
举例:BMI指标就是一个特征工程,它能够客观的评估一个人身体的健康情况。

特征工程的步骤:
特征工程通常分为:特征选择、特征变换、特征构建。

3.1、特征选择
特征选择定义:
在一个数据集中,每个特征对标签的影响作用或大或小。对于那些没作用和作用小的特征,就可以删掉,来降低数据的维度,以便提高模型的准确性和效率。这个就是特征选择。
特征选择手段:

我们既可以手动选择特征,又可以借助特征选择工具让工具帮我选择特征。手动选择特征通常使用相关性热力图,借助 seaborn.heatmap()工具可以画出。
相关性热力图:方格里的数字,这类数字叫做皮尔逊相关系数,表示两个变量间的线性相关性,数值越接近 1,就代表相关性越大。
年度LTV是指在一年时间内,一个客户在平均情况下为公司带来的价值总和,也称为年度客户生命周期价值
我们还可以借助工具来帮我们选择特征,sklearn库的 feature_selection 模块有很多特征选择工具,他们可以自动帮我们完成特征选择。
3.2、特征变换
特征变换是指在机器学习中对原始特征进行一些数学变换或转换,以便更好地适应模型的要求和数据的特征。特征变换的目的是增强数据的表达能力,提取更有用的特征信息,从而提高模型的准确性和可解释性。
特征变换根据数值型特征和分类特征有不同的手段。
特征变换的手段:

数值型特征 - 特征缩放
特征缩放的目的就是压缩特征区间,可以提高模型的精度和稳定性。在深度学习中神经网络等模型,都要求对特征进行缩放,否则模型会跑不起来!
特征缩放的方法主要有两种:标准化和归一化。标准化是指将特征值转换为均值为0,方差为1的标准正态分布,常用的方法为 Sklearn库StandardScaler工具;而归一化是将特征值缩放到0和1之间,常用的方法有Sklearn库MinMaxScaler工具。这些方法可以根据特征的分布情况对特征值进行调整,使得各特征值的范围相同,从而更好地用于模型的训练和预测。
数值型特征 - 特征离散
当特征的数量级跨度过大,而且与标签的关系又非线性的时候,模型可能只对大数量级的特征值敏感,也就是说模型可能会向大特征值的那一侧倾斜。这时候我们需要对特征进行离散处理。常见的方法是分桶。
例子:比如我们的特征是 [3.5, 2.7, 16.9, 5.5, 199] 199偏离其他数据,这里我们对其分桶 X<5记作0,5<X<10记作1,X>10记作2,就可以吧数据变成 0 1 2这样的离散值
分类型特征:
虚拟变量其实就是把男和女这种类似的分类数据转换成1和0。
独热编码就是将每个特征值都被表示为一个二进制向量,其中只有一个元素为1,其余元素为0。
假设我们要做一个狗、狼、猫的动物分类,其独热编码为:
- [1,0,0] 代表狗
- [0,1,0] 代表狼
- [0,0,1] 代表猫
3.3、特征构建
特征构建是整个特征工程领域最具创造力的部分。在我看来,这就是对业务逻辑理解和抽象的过程,是领域专家擅长的工作。用户的RFM模型,其实就是领域专家构建出来的特征。
特征工程做的好,直接决定了机器学习的上限!在那些给定数据集的机器学习竞赛中,高手们为什么能在数据集相同、模型也类似的前提下,让模型达到一个很高的预测准确率?其实,就是因为他们大都通过漂亮的特征工程,提高了机器学习的上限。
4、构建特征集和标签集
数据集分为特征集和标签集,我们要把这些数据喂给模型。特征集就是自变量X的数据的集合,标签集就是因变量Y的数据的集合。
再来回顾一下之前的案例

假设现在要做一个猫狗图片分类的功能?特征和标签长什么样呢?

5、拆分训练集、验证集、测试集
一些特征和标签组成了数据集,接下来就是拆分数据集了。
拆分的原则一般是20%或30%的数据集留作测试,剩余的70%或80%留作训练数据集和验证数据集。这个也不是绝对的拆分比例,是根据具体的数据集做调整的。
数据集的拆分,可以使用机器学习工具包 scikit-learn 里的数据集拆分工具 train_test_split
#将数据集进行80%(训练集)和20%(验证集)的分割
from sklearn.model_selection import train_test_split #导入train_test_split工具
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
虽然是随机分割,但我们要指定一个 random_state 值,这样就保证程序每次运行都分割一样的训练集和测试集。训练集和测试集每次拆分都不一样的话,那比较模型调参前后的优劣就失去了固定的标准。
现在,训练集和测试集拆分也完成了,你会发现原始数据现在变成了四个数据集,分别是:特征训练集(X_train)特征测试集(X_test)标签训练集(y_train)标签测试集(y_test)
数据集又分为训练数据集、验证数据集、测试数据集,训练数据集顾名思义就是用作训练的数据,通过训练数据集找到一个函数,同时会使用验证数据集验证和评估函数。测试数据就负责对训练和评估后的函数进行测试。







![P2[1-2]STM32简介(stm32简介+ARM介绍+片上外设+命名规则+系统结构+引脚定义+启动配置+最小系统电路+实物图介绍)](https://img-blog.csdnimg.cn/83b9ac2eb8a342b59391756331150525.png)






![[Daimayuan] 模拟输出受限制的双端队列(C++,模拟)](https://img-blog.csdnimg.cn/img_convert/c579fddf4fe58f965959dc262fc69109.png)

