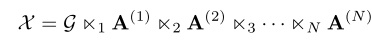每个产品和公司都需要做用户的精细化运营,它是实现用户价值最大化和企业效益最优化的利器。通过将用户进行分层:如高价值用户、潜在价值用户、新用户、流失用户等,针对不同群体制定个性化的营销策略和客户服务,进而促进业务的增长和盈利。
RFM模型是用户分层最常用的模型之一。其他常见的用户分析模型还有:用户生命周期模型、行为分析模型、人口统计学模型等
- 用户生命周期模型:将用户分为不同阶段,如获取、活跃、留存、流失等。是促活的重要模型。
- 行为分析模型:基于用户行为和偏好的分类方法,将用户根据特定的行为和偏好进行分类,如购买偏好、浏览偏好、搜索偏好等
- 人口统计学模型:基于用户基本信息和特征的分类方法,将用户根据性别、年龄、职业、地域等用户的基础属性进行分类用户标签。
RFM模型是一种基于用户购买行为的分析模型,R(Recency)表示用户上一次交易的间隔时间,F(Frequency)表示用户的消费频率,M(Monetary)表示消费金额。通过RFM值对用户进行分类和评估,以确定不同用户群体的价值和行为特征,从而优化营销策略和客户服务。

下面我们开始实战,实战之前,回顾一下六步法!

1、数据收集
这里是从测试商家导出的已完成的订单,使用的是测试数据,在数据准确性方面是不靠谱的,但是不影响我们实战练手!
依据RFM模型,我们需要关注的数据是:企业名称,订单时间,订单总金额
2、数据预处理
再来回顾一下数据预处理的套路!

2.1、数据可视化
Pandas 是数据预处理阶段的利器。他可以读入数据,清洗数据。
matplotlib 是数据可视化的利器。我们先观察一下,月订单数量的走势图。
import Pandas as pd
"""
1.数据可视化
"""
# 读入数据
orders_pd = pd.read_excel('用户订单.xlsx')
# 转化日期格式
orders_pd['订单时间'] = pd.to_datetime(orders_pd['订单时间'])
# 每个月的订单数量
df_orders = orders_pd.set_index('订单时间')['订单编号'].resample('M').nunique()
# 画布
pd.DataFrame(df_orders.values).plot(grid=True, figsize=(12, 6), legend=False)
# 设定X轴显示年月
plt.xticks(
range(len(df_orders.index)),
[x.strftime('%Y.%m') for x in df_orders.index],
rotation=45)
# 绘图
plt.show()

可以看到,自2022年10月份以后,订单数量严重的下跌!可能是活动减少了!
2.2、数据清洗
统计空值(NaN)数据
"""
2.数据清洗
"""
# 统计NaN数据
nan_sum = orders_pd.isna().sum()
print(nan_sum)
运行结果:

统计NaN结果看到表格中有一些空值数据的,而我们关注的是企业名称、订单时间、订单总金额字段,他们都是只有1个数据是空值的,我们需要清理掉这些空值数据。
# 删除指定列的缺失值
orders_pd.dropna(subset=['订单时间', '订单编号', '企业名称', '订单总金额'])
对于数量、金额等类型的数据,我们还常常会使用 describe 方法来查看这些字段的统计信息是否有脏数据。
# 统计订单数据
describe = orders_pd['订单总金额'].describe()
print(describe)
输出结果:(按照顺序依次是总数、均值、标准差、最小值、25% 分位数、中位数、75% 分位数和最大值)

describe 统计结果中可以看到,订单总金额 这个Excel列,最小值是 -12131,说明Excel中是有异常数据的,针对这种数据,我们需要清理掉,使用 DataFrame 过滤功能。
# 在 DataFrame 对象中,通过 loc 通过行、列的名称来访问数据
orders_pd = orders_pd.loc[orders_pd['订单总金额'] > 0]
清理后的订单金额数据正常了!

2.3特征工程 - 求RFM值
特征工程就是基于业务特性,从众多的特征中发现对标签有明显作用的特征,而摒弃掉无用的特征,降低特征的维度,提升机器学习模型的性能。
求用户的RFM值,严格意义上来讲并不算是特征工程,我们只是把表格中的数据加工成对应的RFM特征值。
RFM值如何获得呢?
- R值:用户上一次交易的间隔时间,通过订单时间可以求得。
- F值:用户的消费频率,根据下单次数可以求得。
- M值:用户的消费金额,根据订单总金额可以求得。
构建以用户(企业名称)为主键的表格
"""
3.求RFM值
"""
# 1.构建以企业名称为主键的表格
user = pd.DataFrame(orders_pd['企业名称'].unique())
print(user)
可以看到一共有149个用户下单。

下面我们开始分别求RFM值:
1)求R值:用户上一次交易的间隔时间
# 2.求R值
# 转化日期格式
orders_pd['订单时间'] = pd.to_datetime(orders_pd['订单时间'])
# 构建消费日期信息
user_recent_buy = orders_pd.groupby('企业名称').订单时间.max().reset_index()
# 设定字段名
user_recent_buy.columns = ['企业名称', '最近日期']
# 计算最新日期与上次消费日期的天数
user_recent_buy['R值'] = (user_recent_buy['最近日期'].max() - user_recent_buy['最近日期']).dt.days
# 把上次消费距最新日期的天数(R值)合并至df_user结构
user = pd.merge(user, user_recent_buy[['企业名称', 'R值']], on='企业名称')
print(user)

在 149 个用户中,大哥大已经915天没有消费了,这个用户已经流失了。
2)求F值:用户的消费频率,通过 count() 计算订单总数获得。
# 3.求F值
# 计算每个用户消费次数
df_frequency = orders_pd.groupby('企业名称').订单时间.count().reset_index()
df_frequency.columns = ['企业名称', 'F值']
# 把F值合并到user表
user = pd.merge(user, df_frequency, on='企业名称')
print(user)
输出结果:

企业名称:0716企业名称992 用户消费了92次,而大哥大只消费了1次。
3)求M值:用户的消费金额,通过 sum()计算用户的累计订单金额。
# 4.求M值
# sum 函数计算总金额
user_total_money = orders_pd.groupby('企业名称').订单总金额.sum().reset_index()
user_total_money.columns = ['企业名称', 'M值']
# 把M值合并到user表
user = pd.merge(user, user_total_money, on='企业名称')
print(user)
输出结果:

用户:0716企业名称992 虽然消费了92次,但是订单金额只有6.76;大哥大虽然只消费了1次,但是消费金额1211元。
3、选择算法
请注意这个问题,这个案例到底属于哪类问题呢?监督学习?无监督学习?
这个问题是一个无监督学习类问题。别看RFM值我们已经计算得出来了!我们的数据集是没有标签的,在数据集中并没有标注出哪个用户价值高,哪个用户价值低,所以这属于无监督学习问题。并且是无监督学习中的聚类问题(我们要按照用户的高低价值,对用户进行分类)。
无监督学习算法又分为聚类算法和降维算法,那这里我们选择聚类算法中的K-Means算法

K-Means算法介绍
K-Means算法是一种基于距离的聚类方法,其原理是将数据集划分为K个簇。使得每个簇内的数据点距离簇中心最近,而不同簇之间的数据点距离簇中心最远。
K-Means算法原理图如下:3个簇表示有3个聚类,K = 3。每个簇内的数据点距离质心最近。

具体实现过程如下:
- 随机选择K个初始簇中心。
- 计算每个数据点到K个簇中心的距离,并将每个数据点划分到距离最近的簇。
- 对于每个簇,重新计算簇中心。
- 重复步骤2和3,直到簇中心不再发生变化或达到最大迭代次数。
K值是最重要的参数,那么K值该如何确定呢?
由于RFM模型是比较成熟的用户分析模型了!通常通过三维坐标系来对用户进行分层。共计分为8种类型,那在K-Means聚类算法中,就是分为8个簇也就是8种不同的用户群体。

对三维坐标进行拆解,得到如下表格形式的用户分层规则数据。

4、通过K-Means算法聚类
当K值确定好以后,我们就可以通过K-Means算法对用户RFM进行聚类了。聚类分为三步:创建K-Means模型、拟合模型、聚类。

1、创建K-Means模型,K = 8
# 创建了一个 K-Means 聚类模型。
# K = 8
kmeans_R = KMeans(n_clusters=8)
kmeans_F = KMeans(n_clusters=8)
kmeans_M = KMeans(n_clusters=8)
2、fit 拟合模型
# 拟合模型
kmeans_R.fit(user[['R值']])
kmeans_F.fit(user[['F值']])
kmeans_M.fit(user[['M值']])
3、predict 聚类
# 通过聚类模型求出R值的层级
user['R值层级'] = kmeans_R.predict(user[['R值']])
user['F值层级'] = kmeans_F.predict(user[['F值']])
user['M值层级'] = kmeans_M.predict(user[['M值']])
观察一下聚类后的数据情况
1)统计R值的层级
#R值层级分组统计信息
user.groupby('R值层级')['R值'].describe()
输出如下:可以看到按照期望分成了8个簇,但是这里有一个问题,就些数据是没有任何顺序的!这是聚类这种算法本身的问题。聚类只是把相邻数据分成一个簇,但是它并不知道簇是什么含义,更不知道如何排序。

很关键的一步:聚类的结果,需要我们人为地给这些用户组贴标签,看看哪一组价值高,哪一组价值低。
这里我们定义一个排序的方法 order_cluster
定义一个order_cluster函数为聚类排序
def order_cluster(cluster_name, target_name , df ,ascending=False):
# 新的聚类名称
new_cluster_name = 'new_' + cluster_name
# 按聚类结果分组,创建df_new对象
user_new = df.groupby(cluster_name)[target_name].mean().reset_index()
# 排序
user_new = user_new.sort_values(by=target_name,ascending=ascending).reset_index(drop=True)
# 创建索引字段
user_new['index'] = user_new.index
# 基于聚类名称把user_new还原为df对象,并添加索引字段
user_new = pd.merge(df,user_new[[cluster_name,'index']], on=cluster_name)
# 删除聚类名称
user_new = user_new.drop([cluster_name],axis=1)
# 将索引字段重命名为聚类名称字段
user_new = user_new.rename(columns={"index":cluster_name})
# 返回排序后的user_new对象
return user_new
对R值层级的簇进行排序:
# 调用簇排序函数
user = order_cluster('R值层级', 'R值', user, False)
# 根据用户码排序
user = user.sort_values(by='企业名称', ascending=True).reset_index(drop=True)
统计排序后的R值层级的信息:
# R值层级分组统计信息
user.groupby('R值层级')['R值'].describe()
统计R值层级输出结果如下:此时输出了8个簇,从 07簇平均值依次减少的,表示用户距离上一次消费间隔时间逐渐变小,因此R值层级,从07价值依次是升高的。

2)同样方案统计F值数据
user = order_cluster('F值层级', 'F值', user, True)
print(user.groupby('F值层级')['F值'].describe())

3)同样方案统计M值数据
user = order_cluster('M值层级', 'M值', user, True)
print(user.groupby('M值层级')['M值'].describe())

至此,用户的RFM值全部计算出来了,以及RFM层级都已经通过聚类算法计算出来了。

根据用户的指标,我们将 RFM值分为高低

根据RFM模型将用户分为8个不同的群体

对聚类后的数据,按照8个群体为用户贴标签
#在df_user对象中添加总体价值这个字段
user.loc[(user['R值层级']>=4) & (user['F值层级']>=5) & (user['M值层级']>=2), '用户群体'] = '重要价值客户'
user.loc[(user['R值层级']>=4) & (user['F值层级']<5) & (user['M值层级']>=2), '用户群体'] = '重要发展客户'
user.loc[(user['R值层级']<4) & (user['F值层级']>=5) & (user['M值层级']>=2), '用户群体'] = '重要保持客户'
user.loc[(user['R值层级']<4) & (user['F值层级']<5) & (user['M值层级']>=2), '用户群体'] = '重要挽留客户'
user.loc[(user['R值层级']>=4) & (user['F值层级']>=5) & (user['M值层级']<2), '用户群体'] = '一般价值客户'
user.loc[(user['R值层级']>=4) & (user['F值层级']<5) & (user['M值层级']<2), '用户群体'] = '一般发展客户'
user.loc[(user['R值层级']<4) & (user['F值层级']>=5) & (user['M值层级']<2), '用户群体'] = '一般保留客户'
user.loc[(user['R值层级']<4) & (user['F值层级']<5) & (user['M值层级']<2), '用户群体'] = '一般挽留客户'
输出一下用户分群体后的User表

通过 describe函数汇总一下各个用户群体及数量

可以看到这个商家的经营状况不好,大部分用户都流失了!需要考虑为不同用户群体制定运营策略,以提升客户价值和营收水平。
本案例中,我们使用K-Means聚类算法依据RFM模型实现了对用户的分层。除此之外,K-Means算法常见的应用场景还有文本聚类、风险监测等。
- 文本聚类:根据文档内容或主题对文档进行聚类,用以帮助文本挖掘和信息检索等领域对文本进行有效分类和分析,识别潜在的主题和信息,提高文本处理和分析的效率和精度。
- 风险监测:在金融风控场景中,通过对用户交易行为做聚类分析。根据每个群体的特征识别潜在的欺诈行为,并及时采取措施防范风险。