一、死锁的定义&危害
1、死锁是什么
- 发生在
并发中 互不想让:当两个(或更多)线程(或进程)相互持有对方所需要的资源,又不主动释放,导致所有人都无法继续前进,导致程序陷入无尽的阻塞,这就是死锁。
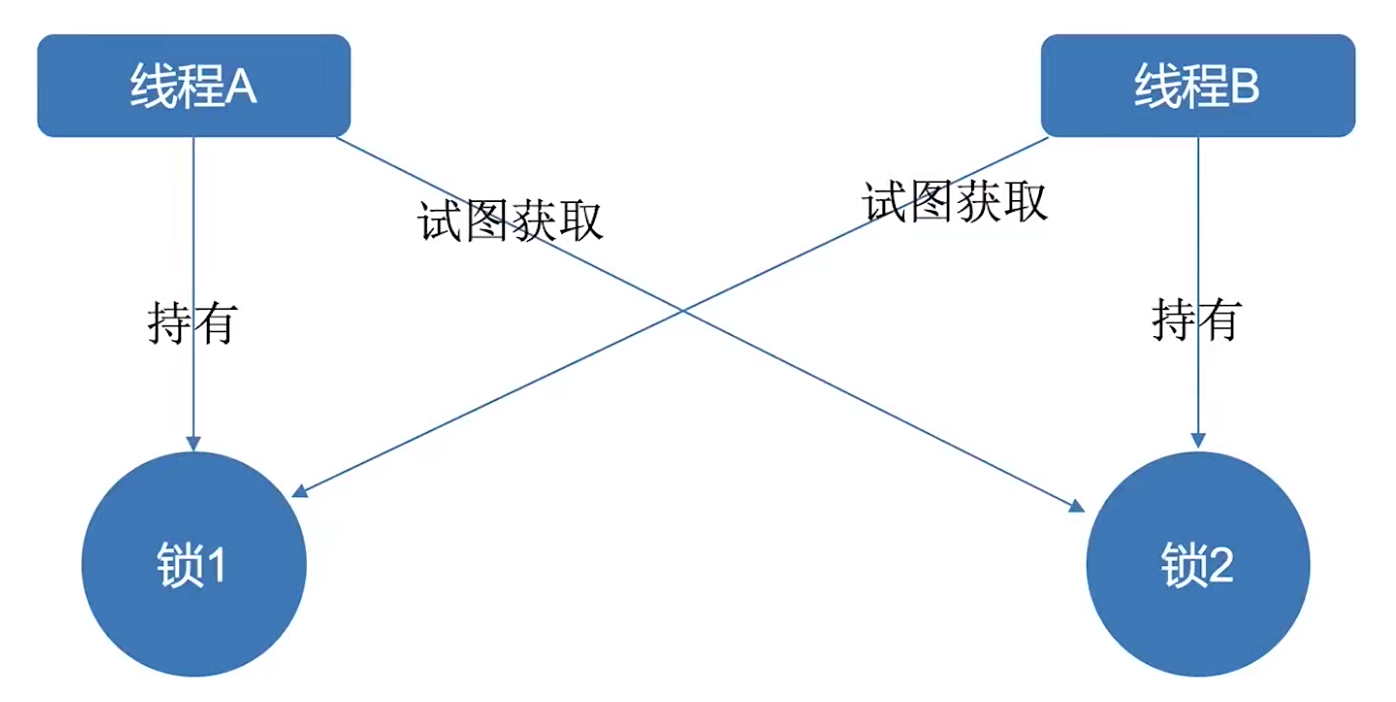
- 多个线程造成死锁的情况
- 如果多个线程之间的依赖关系是环形,存在环路的锁的依赖关系,那么也可能会发送死锁
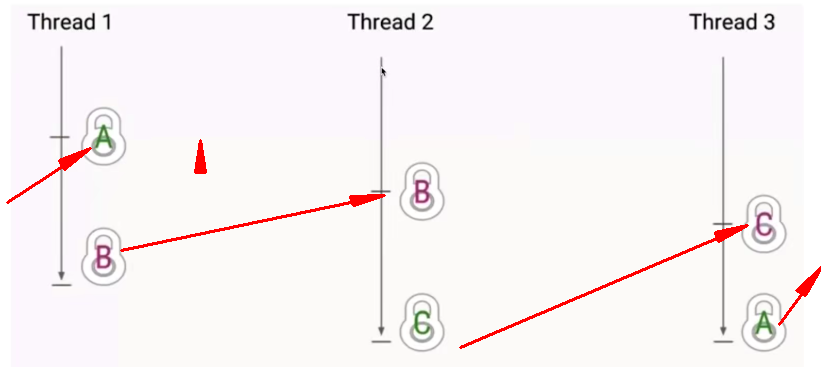
2、死锁的影响
死锁的影响在不同的系统中是不一样的,这取决于系统对死锁的处理能力
数据库中: 数据库可以检测到并介入,可以通过放弃其中某个事物的锁来解决JVM中: JVM 无法自动处理锁,需要人工处理
3、死锁的危害
死锁发生的几率不高但危害大,一旦发生,多是高并发场景,影响用户多;甚至可能造成整个系统奔溃,或者子系统崩溃,或者性能降低;而且在压力测试过程无法找出所有潜在的死锁。
二、发生死锁的例子
1. 两个线程的简单场景
代码展示:
/**
* 必定发生死锁的情况
*/
public class MustDeadLock implements Runnable {
int flag = 1;//标记位
static Object lock1 = new Object();
static Object lock2 = new Object();
public static void main(String[] args) {
MustDeadLock r1 = new MustDeadLock();
MustDeadLock r2 = new MustDeadLock();
r1.flag=1;
r2.flag=0;
Thread thread1 = new Thread(r1);
Thread thread2 = new Thread(r2);
thread1.start();
thread2.start();
}
@Override
public void run() {
System.out.println("flag= " + flag);
if (flag == 1) {
synchronized (lock1){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2){
System.out.println("线程1成功拿到两把锁");
}
}
}
if (flag == 0) {
synchronized (lock2){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1){
System.out.println("线程2成功拿到两把锁");
}
}
}
}
}
结果如下:
thread1 启动之后拿到 lock1 并休眠 500ms ,与此同时,thread2 启动之后拿到了 lock2 并休眠 500ms ;thread1 醒来之后想去获取 lock2 ,但是 lock2 被 thread2 拥有,因此 thread1 会陷入阻塞,而 thread2 醒来之后会去拿 lock1 ,但是 lock 在 thread1 手上,thread2 也会陷入阻塞, thread1 和 thread2 都进入了阻塞,相互等待,结果进入了死锁。
2. 银行转账的案例
具体案例可参考文章:《银行转账(死锁)》
三、死锁发生的必要条件
1、互斥条件
一个资源每一次只能被一个进程或者线程使用。比如我这里有锁,我拿了这锁之后,其他线程就不能拿到他,除非我释放了他
2、请求与保持条件
第一个线程请求第二把锁同时保持第一把锁。比如线程1想要请求一把锁B,在请求期间,他对已经拿到的锁A一直保持不释放
3、不剥夺条件
不被外界干扰剥夺锁。即没有外界干扰结束死锁的情况。
4、循环等待条件
两个或者多个互相等待或者环形等待锁的释放。比如两个线程等待条件,就是你等我释放,我等你释放;多个线程等待条件,就是A等B,B等C,C等D,D等E,E等F,F等A,无尽不释放,无尽陷入等待,构成环路。
以上四个条件:缺一不可, 只需要破解以上4个条件任意一个条件,这个死锁就不会发生了!!
四、如何定位死锁的位置
1、jstack 命令
该代码来自文章《银行转账(死锁)》中,代码如下:
public class TransferMoney implements Runnable {
Integer flag = 1;
static Account a = new Account(1000);
static Account b = new Account(1000);
//主函数
public static void main(String[] args) throws InterruptedException {
TransferMoney t1 = new TransferMoney();
TransferMoney t2 = new TransferMoney();
t1.flag = 1;
t1.flag = 0;
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t2);
thread1.start();
thread2.start();
thread1.join();
thread1.join();
System.out.println("a的余额为:"+a.balance);
System.out.println("a的余额为:"+b.balance);
}
@Override
public void run() {
if (flag == 1) {
transferMoney(a, b, 500);
}
if (flag == 0) {
transferMoney(b, a, 500);
}
}
// 转账
private void transferMoney(Account from, Account to, int amount) {
synchronized (from) {
System.out.println(Thread.currentThread().getName()+"获取到第一把锁");
//加入线程睡眠500ms
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (to) {
System.out.println(Thread.currentThread().getName()+"获取到第二把锁");
if (from.balance - amount < 0) {
System.out.println("余额不足,转账失败。");
return;
}
from.balance -= amount;
to.balance += amount;
System.out.println("成功转账" + i + "元");
}
}
}
static class Account {
//余额
int balance;
public Account(int balance) {
this.balance = balance;
}
}
}
下面通过使用java自带的jstack命令,来查找我们项目中的死锁问题
## 需要首先获取程序的进程 pid
jps
## 然后在 终端界面执行如下命令
jstack 8359 #javahome下的jastack命令 进程的pid
执行结果图:
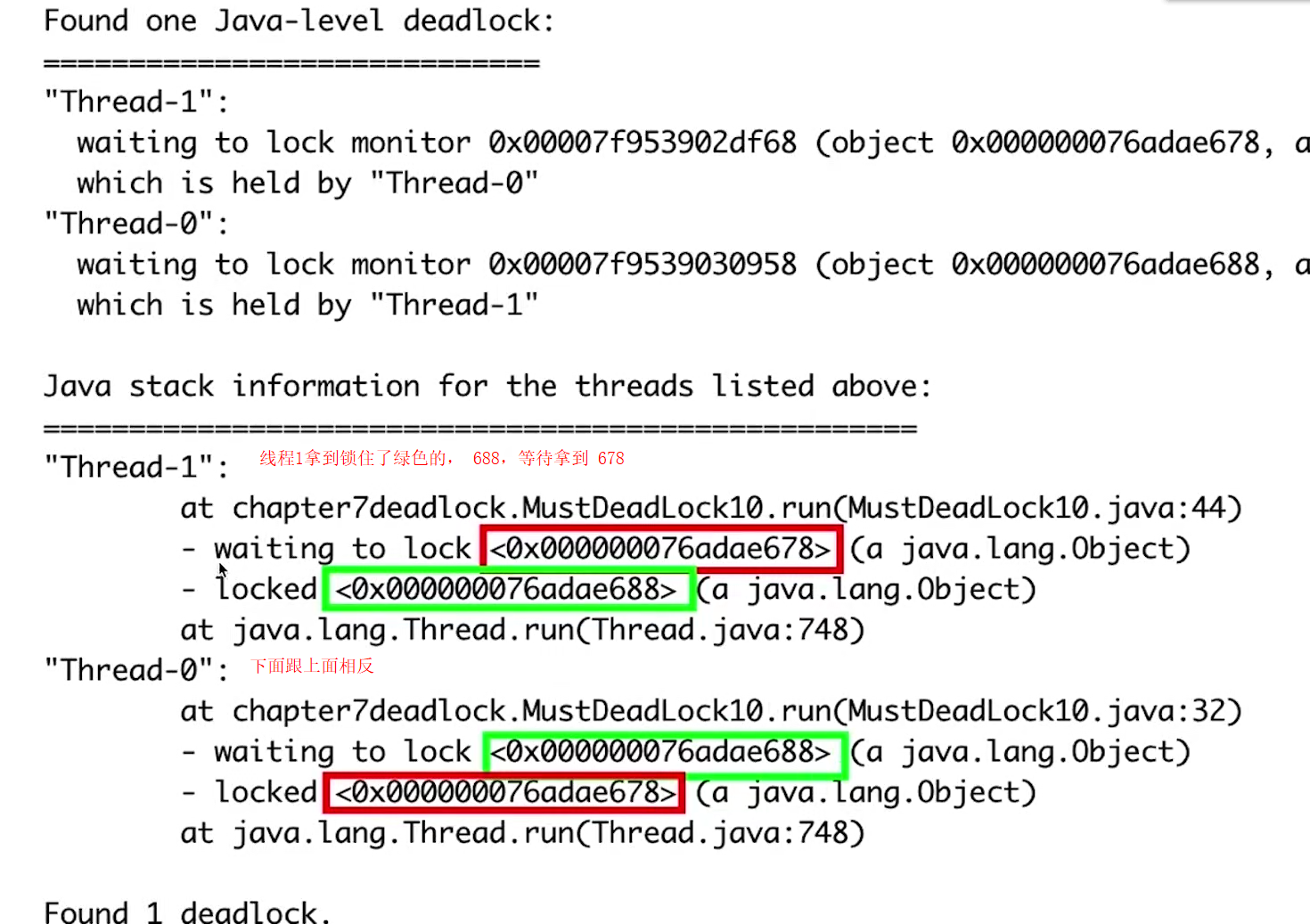
可以清晰地看到 Thread-1 拿到了锁 <0x000000076adae688> ,正在等待 <0x000000076adae678>,而 Thread-0 拿到了锁 <0x000000076adae678>,正在等待 <0x000000076adae688>,于是两者互相等待,造成死锁。
2、ThreadMXBean代码
/**
* 通过 ThreadMXBean 检测死锁
*/
import java.lang.management.ManagementFactory;
import java.lang.management.ThreadInfo;
import java.lang.management.ThreadMXBean;
public class ThreadMXBeanDetection implements Runnable{
int flag = 1;//标记位
static Object lock1 = new Object();
static Object lock2 = new Object();
public static void main(String[] args) throws InterruptedException {
ThreadMXBeanDetection r1 = new ThreadMXBeanDetection();
ThreadMXBeanDetection r2 = new ThreadMXBeanDetection();
r1.flag=1;
r2.flag=0;
Thread thread1 = new Thread(r1);
Thread thread2 = new Thread(r2);
thread1.start();
thread2.start();
Thread.sleep(1000);
//得到实例
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
long[] deadlockedThreads = threadMXBean.findDeadlockedThreads();
//发现死锁
if (deadlockedThreads != null && deadlockedThreads.length>0){
//迭代
for (long item : deadlockedThreads) {
//获取线程信息
ThreadInfo threadInfo = threadMXBean.getThreadInfo(item);
//获取死锁线程的名字
System.out.println("发现死锁:"+threadInfo.getThreadName());
}
}
}
@Override
public void run() {
System.out.println("flag= " + flag);
if (flag == 1) {
synchronized (lock1){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2){
System.out.println(flag);
}
}
}
if (flag == 0) {
synchronized (lock2){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1){
System.out.println(flag);
}
}
}
}
}
打印结果:
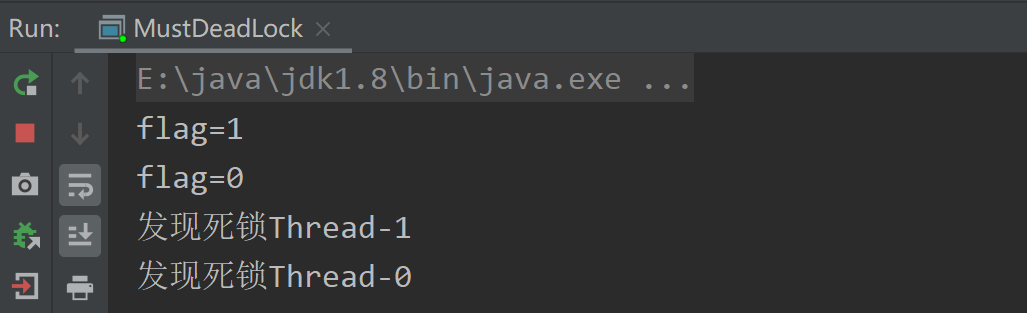
如上图所示,ThreadMXBean 可以检测死锁,如果我们检测到了之后,就可以编写对应的逻辑,比如重启线程、通知告警系统、发消息提醒运维人员等。
五、修复死锁策略
1、线上发生死锁应该怎么办
保存案发现场,然后立即重启服务器,确保线上服务能运行下去,之后在利用保存的信息,排查死锁,修改代码,重新发布。
2、常见修复策略
-
避免策略:
哲学家就餐的换手方案、转账换序方案。可参考下面两篇文章:- 《哲学家就餐问题》
- 《银行转账》
-
检测与恢复策略:一段时间
检测是否有死锁,如果有就剥夺某一个资源,来打开死锁- 检测算法: 锁的调用链路图
允许发生死锁- 每次调用锁的
记录,并绘成一个有向的数据结构图 - 定期检查
'锁的调用链路图'中是否存在环路 - 一旦发现死锁,就用死锁
恢复机制恢复
- 死锁恢复机制
- 进程终止:
逐个终止线程,直到死锁消除- 终止顺序:
- 线程的优先级(是前台交互还是后台处理);
- 已占用资源多少、还需要的资源多少;
- 已运行时间长短
- 终止顺序:
- 资源抢占:
- 把已经分发出去的锁
收回 - 让线程
回退让几步,这样就不用结束整个线程,成本比较低- 缺点:可能造成线程
饥饿
- 缺点:可能造成线程
- 把已经分发出去的锁
- 进程终止:
- 检测算法: 锁的调用链路图
-
鸵鸟策略:鸵鸟这种动物在遇到危险的时候,通常就会把头埋在地上,这样一来它就看不到危险了。而鸵鸟策略的意思就是说,如果我们发生死锁的概率极其低,那么我们就直接
忽略它,直到死锁发生的时候,再人工修复。这是一种消极的处理方式,不推荐。
六、如何在工程中避免死锁
1、设置超时时间
- 由于 synchronized
不具备尝试锁的能力,可以使用 Lock的tryLock(long timeout, TimeUnit unit) 替代。 - 造成超时的可能性多:发生了死锁、线程陷入死循环、线程执行很慢,无论是哪种情况,只要过了超时时间,就认为失败
- 获取锁失败的时候,要执行一些应对措施:比如打日志、发报警邮件、重启等
/**
* 使用Lock中的tryLock()避免死锁
*/
public class TryLockDeaLock implements Runnable {
int flag = 1;
static Lock lock1 = new ReentrantLock();
static Lock lock2 = new ReentrantLock();
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (flag == 1){
try {
if (lock1.tryLock(800, TimeUnit.MILLISECONDS)){
System.out.println("线程1,拿到lock1");
Thread.sleep(new Random().nextInt(1000));
if (lock2.tryLock(800,TimeUnit.MILLISECONDS)){
System.out.println("线程1,成功获取到 lock1 & lock2");
//释放
lock2.unlock();
lock1.unlock();
break;
}else {
System.out.println("线程1,获取lock2,失败,已重试");
lock1.unlock();
Thread.sleep(new Random().nextInt(1000));
}
}else {
System.out.println("线程1,获取lock1,失败,已重试");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
if (flag ==0){
try {
if (lock2.tryLock(3000, TimeUnit.MILLISECONDS)){
System.out.println("线程2,拿到lock2");
Thread.sleep(new Random().nextInt(1000));
if (lock1.tryLock(3000,TimeUnit.MILLISECONDS)){
System.out.println("线程2,成功获取到 lock1 & lock2");
//释放
lock2.unlock();
lock1.unlock();
break;
}else {
System.out.println("线程2,获取lock1,失败,已重试");
lock1.unlock();
Thread.sleep(new Random().nextInt(1000));
}
}else {
System.out.println("线程2,获取lock2,失败,已重试");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//主函数
public static void main(String[] args) {
TryLockDeaLock t1 = new TryLockDeaLock();
TryLockDeaLock t2 = new TryLockDeaLock();
t1.flag = 1;
t2.flag = 0;
Thread thread1 = new Thread(t1);
Thread thread2 = new Thread(t2);
thread1.start();
thread2.start();
}
}
2、多使用并发工具类,而不是自己设计锁
- ConcurrentHashMap、ConcurrentLinkedQueue、AtomicBoolean等
- 实际应用中java.util.concurrent.atomic十分有用,简单方便且效率比使用Lock更高
- 多用并发集合少用同步集合,并发集合比同步集合的可扩展性更好
- 并发场景需要用到map,首先想到用ConcurrentHashMap
3、尽量降低锁的使用粒度:
用不同的锁而不是一个锁
4、如果能使用同步代码块,就不使用同步方法
在代码块中,可以自己指定锁对象(方便掌控锁)
5、给你的线程起个有意义的名字
如果遇到问题,在debug和排查时事倍功半,更容易定位到问题,框架和JDK都遵守这个最佳实践
6、避免锁嵌套
比如下图中在已经持有 lock1 的情况下,还要继续请求 lock2,锁互相嵌套,更容易导致死锁

7、分配资源前先看能不能收回
银行家算法:在放贷之前,首先对资源的进行有效计算,看看资源能不能收回来。
8、不要几个功能用同一把锁
每一个功能都要有自己专门的锁,专锁专用
七. 其它线程活跃性故障:活锁、饥饿
死锁是最常见的活跃性问题,不过除了之前的死锁之外,还有一些类似的问题,会导致程序无法顺利执行,统称为 活跃性问题
1. 活锁
(1)什么是活锁
- 虽然线程并没有阻塞,也
始终在运行(所以被称为“活锁”,线程是“活的”),但是程序却得不到进展,因为线程始终重复做同样的事 - 如果是死锁,只会是等待,不会消耗CPU资源,但活锁除了程序无法进行,还会消耗 cpu 资源
(2)代码演示
可参考文章:《牛郎织女的幸福生活》
(3)生产中的活锁:消息队列
如果在消息队列中使用策略:消息处理失败,就放在队列开头重试。但是若该消息失败的原因是由于某个依赖的服务出了问题,会导致该消息一直失败。那么消息就会不停地重新放回队列头,不停地重试,虽然没阻塞,但是由于一直在处理该消息,程序也无法继续执行。
解决方案:
- 放到队列尾部
- 设置重试次数限制
(4)活锁问题突破口
增加随机因素:出现活锁的原因大都是因为重试机制不变,每一次重试的触发时机总是相同导致。所以可以参考以太网的指数退避算法:连接重试时间不是固定的,而是随机的,并且随机范围随着碰撞强度的升高而逐渐扩大。我们也可以加入一些随机因素,改变每次重试的条件或时机,或者每次重试的执行逻辑等。
2. 饥饿
(1)什么是饥饿
- 当线程需要某些资源(例如CPU),但是却一直
始终得不到 - 线程的
优先级设置过低,或者有某个线程持有锁同时又无限循环从而不释放锁,或者某程序始终占用某文件的写锁
(2)饥饿的影响
饥饿可能会导致响应性差:比如,我们的浏览器有一个线程负责处理前台响应(打开收藏夹等动作),另外的后台线程负责下载图片和文件、计算渲染等。在这种情况下,如果后台线程把CPU资源都占用了,那么前台线程将无法得到很好地执行,这会导致用户的体验很差
(3)解决方案
- 注意到程序上不应该有锁使用完却不释放的逻辑错误
- 不应该在程序中设置优先级