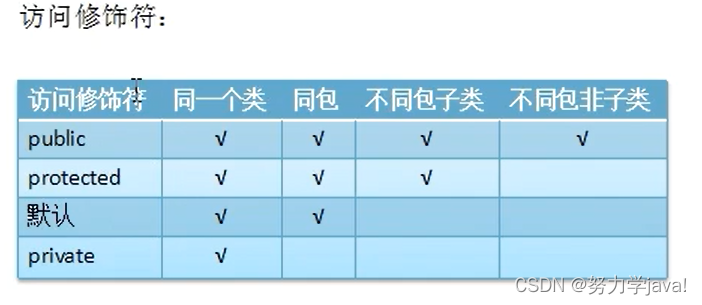
目的:优化基于yolov5-obb旋转目标检测算法的证件区域检测,之前的方法是基于anchor,每次使用都要调试anchor;而ppyoloe-r是free anchor的算法;
源码位置:https://github.com/PaddlePaddle/PaddleDetection/issues/7291
本次尝试使用PaddleDetection中的 ppyoloe-r进行效果优化;
本次的目的:保持backbone一致的情况下,从anchor转移到free anchor;
基本的步骤如下:
1.PaddleDetection工程的安装和试运行;
paddle的安装我就不再详述,可参照官网,其他细节的补充:
# pip install cython
# pip install lap -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install terminaltables -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install typeguard -i https://pypi.tuna.tsinghua.edu.cn/simple
# git clone https://github.com/cocodataset/cocoapi
# pip install pycocotools==2.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install numba==0.56.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
# cd PaddleDetection-release-2.6
# python setup.py install
# cd ppdet/ext_op
# python setup.py install
#安装后确认测试通过:
#python ppdet/modeling/tests/test_architectures.py
#测试通过后会提示如下信息:
#.......
#----------------------------------------------------------------------
#Ran 7 tests in 12.816s
#OK2.数据格式的变化;
数据格式从txt转换到coco格式,可以通过tools/x2coco.py来进行处理,自己对其中的代码进行了修改,因为自己的数据格式不符合其中的任意一种选项;我这边是将yolov5-obb的数据转换成coco格式,训练样本不同批次的数据在各个子文件夹中,子文件夹中包含images子文件夹和labels文件夹,其中images子文件夹中包含的是图片,而labels文件夹包含的是用于yolov5-obb中旋转目标检测的标签:
修改后的x2coco.py中的代码如下:
import argparse
import glob
import json
import os
import os.path as osp
import shutil
import xml.etree.ElementTree as ET
import numpy as np
import PIL.ImageDraw
from tqdm import tqdm
import cv2
from tqdm import tqdm
# label_to_num = {}
categories_list = []
labels_list = []
label_to_num = {}
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
def images_labelme(data, num, file_):
image = {}
image['height'] = data['imageHeight']
image['width'] = data['imageWidth']
image['id'] = num + 1
if '\\' in data['imagePath']:
image['file_name'] = os.path.join(file_, data['imagePath'].split('\\')[-1])
else:
image['file_name'] = os.path.join(file_, data['imagePath'].split('/')[-1])
return image
def images_cityscape(data, num, img_file):
image = {}
image['height'] = data['imgHeight']
image['width'] = data['imgWidth']
image['id'] = num + 1
image['file_name'] = img_file
return image
def categories(label, labels_list):
category = {}
category['supercategory'] = 'component'
category['id'] = len(labels_list) + 1
category['name'] = label
return category
def annotations_rectangle(points, label, image_num, object_num, label_to_num):
annotation = {}
seg_points = np.asarray(points).copy()
seg_points[1, :] = np.asarray(points)[2, :]
seg_points[2, :] = np.asarray(points)[1, :]
annotation['segmentation'] = [list(seg_points.flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = image_num + 1
annotation['bbox'] = list(
map(float, [
points[0][0], points[0][1], points[1][0] - points[0][0], points[1][
1] - points[0][1]
]))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
annotation['category_id'] = label_to_num[label]
annotation['id'] = object_num + 1
return annotation
def annotations_polygon(height, width, points, label, image_num, object_num,
label_to_num):
annotation = {}
annotation['segmentation'] = [list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = image_num + 1
annotation['bbox'] = list(map(float, get_bbox(height, width, points)))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
annotation['category_id'] = label_to_num[label]
annotation['id'] = object_num + 1
return annotation
def get_bbox(height, width, points):
polygons = points
mask = np.zeros([height, width], dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
left_top_r = np.min(rows)
left_top_c = np.min(clos)
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
return [
left_top_c, left_top_r, right_bottom_c - left_top_c,
right_bottom_r - left_top_r
]
def deal_json(ds_type, img_dir, files):
data_coco = {}
images_list = []
annotations_list = []
image_num = -1
object_num = -1
for file_ in files:
print(file_)
img_path = os.path.join(img_dir, file_)
json_path = os.path.join(img_dir, file_.replace('/images', '/labels'))
for img_file in tqdm(os.listdir(img_path)):
img = cv2.imread(os.path.join(img_path, img_file))
height, width = img.shape[:2]
img_label = os.path.splitext(img_file)[0]
if img_file.split('.')[
-1] not in ['bmp', 'jpg', 'jpeg', 'png', 'JPEG', 'JPG', 'PNG']:
continue
# label_file = osp.join(json_path, img_label + '.json')
label_file = osp.join(json_path, img_label + '.txt')
# print('Generating dataset from:', label_file)
image_num = image_num + 1
# with open(label_file) as f:
with open(label_file, 'r', encoding='utf-8') as f:
# data = json.load(f)
data_str = f.readlines()
# point_list = []
# label_list = []
data = {}
data['imageHeight'] = height
data['imageWidth'] = width
data['imagePath'] = os.path.join(img_path, img_file)
data['shapes'] = []
for data_ in data_str:
shapes = {}
data_list = data_.strip().split(' ')
points = data_list[:-2]
label = data_list[-2]
# point_list.append(points)
# label_list.append(label)
shapes['label'] = label
point_s = list(map(int, points))
shapes['points'] = [[point_s[0], point_s[1]], [point_s[2], point_s[3]], [point_s[4], point_s[5]], [point_s[6], point_s[7]]]
shapes['shape_type'] = 'polygon'
data['shapes'].append(shapes)
if ds_type == 'labelme':
images_list.append(images_labelme(data, image_num, file_))
elif ds_type == 'cityscape':
images_list.append(images_cityscape(data, image_num, img_file))
# images_list.append(annotations_polygon(height, width, points, label, image_num, object_num,
# label_to_num))
if ds_type == 'labelme':
for shapes in data['shapes']:
object_num = object_num + 1
label = shapes['label']
if label not in labels_list:
categories_list.append(categories(label, labels_list))
labels_list.append(label)
label_to_num[label] = len(labels_list)
p_type = shapes['shape_type']
if p_type == 'polygon':
points = shapes['points']
annotations_list.append(
annotations_polygon(data['imageHeight'], data[
'imageWidth'], points, label, image_num,
object_num, label_to_num))
if p_type == 'rectangle':
(x1, y1), (x2, y2) = shapes['points']
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [[x1, y1], [x2, y2], [x1, y2], [x2, y1]]
annotations_list.append(
annotations_rectangle(points, label, image_num,
object_num, label_to_num))
elif ds_type == 'cityscape':
for shapes in data['objects']:
object_num = object_num + 1
label = shapes['label']
if label not in labels_list:
categories_list.append(categories(label, labels_list))
labels_list.append(label)
label_to_num[label] = len(labels_list)
points = shapes['polygon']
annotations_list.append(
annotations_polygon(data['imgHeight'], data[
'imgWidth'], points, label, image_num, object_num,
label_to_num))
data_coco['images'] = images_list
data_coco['categories'] = categories_list
data_coco['annotations'] = annotations_list
return data_coco
def voc_get_label_anno(ann_dir_path, ann_ids_path, labels_path):
with open(labels_path, 'r') as f:
labels_str = f.read().split()
labels_ids = list(range(1, len(labels_str) + 1))
with open(ann_ids_path, 'r') as f:
ann_ids = [lin.strip().split(' ')[-1] for lin in f.readlines()]
ann_paths = []
for aid in ann_ids:
if aid.endswith('xml'):
ann_path = os.path.join(ann_dir_path, aid)
else:
ann_path = os.path.join(ann_dir_path, aid + '.xml')
ann_paths.append(ann_path)
return dict(zip(labels_str, labels_ids)), ann_paths
def voc_get_image_info(annotation_root, im_id):
filename = annotation_root.findtext('filename')
assert filename is not None
img_name = os.path.basename(filename)
size = annotation_root.find('size')
width = float(size.findtext('width'))
height = float(size.findtext('height'))
image_info = {
'file_name': filename,
'height': height,
'width': width,
'id': im_id
}
return image_info
def voc_get_coco_annotation(obj, label2id):
label = obj.findtext('name')
assert label in label2id, "label is not in label2id."
category_id = label2id[label]
bndbox = obj.find('bndbox')
xmin = float(bndbox.findtext('xmin'))
ymin = float(bndbox.findtext('ymin'))
xmax = float(bndbox.findtext('xmax'))
ymax = float(bndbox.findtext('ymax'))
assert xmax > xmin and ymax > ymin, "Box size error."
o_width = xmax - xmin
o_height = ymax - ymin
anno = {
'area': o_width * o_height,
'iscrowd': 0,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id,
'ignore': 0,
}
return anno
def voc_xmls_to_cocojson(annotation_paths, label2id, output_dir, output_file):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": []
}
bnd_id = 1 # bounding box start id
im_id = 0
print('Start converting !')
for a_path in tqdm(annotation_paths):
# Read annotation xml
ann_tree = ET.parse(a_path)
ann_root = ann_tree.getroot()
img_info = voc_get_image_info(ann_root, im_id)
output_json_dict['images'].append(img_info)
for obj in ann_root.findall('object'):
ann = voc_get_coco_annotation(obj=obj, label2id=label2id)
ann.update({'image_id': im_id, 'id': bnd_id})
output_json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
im_id += 1
for label, label_id in label2id.items():
category_info = {'supercategory': 'none', 'id': label_id, 'name': label}
output_json_dict['categories'].append(category_info)
output_file = os.path.join(output_dir, output_file)
with open(output_file, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def widerface_to_cocojson(root_path):
train_gt_txt = os.path.join(root_path, "wider_face_split", "wider_face_train_bbx_gt.txt")
val_gt_txt = os.path.join(root_path, "wider_face_split", "wider_face_val_bbx_gt.txt")
train_img_dir = os.path.join(root_path, "WIDER_train", "images")
val_img_dir = os.path.join(root_path, "WIDER_val", "images")
assert train_gt_txt
assert val_gt_txt
assert train_img_dir
assert val_img_dir
save_path = os.path.join(root_path, "widerface_train.json")
widerface_convert(train_gt_txt, train_img_dir, save_path)
print("Wider Face train dataset converts sucess, the json path: {}".format(save_path))
save_path = os.path.join(root_path, "widerface_val.json")
widerface_convert(val_gt_txt, val_img_dir, save_path)
print("Wider Face val dataset converts sucess, the json path: {}".format(save_path))
def widerface_convert(gt_txt, img_dir, save_path):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": [{'supercategory': 'none', 'id': 0, 'name': "human_face"}]
}
bnd_id = 1 # bounding box start id
im_id = 0
print('Start converting !')
with open(gt_txt) as fd:
lines = fd.readlines()
i = 0
while i < len(lines):
image_name = lines[i].strip()
bbox_num = int(lines[i + 1].strip())
i += 2
img_info = get_widerface_image_info(img_dir, image_name, im_id)
if img_info:
output_json_dict["images"].append(img_info)
for j in range(i, i + bbox_num):
anno = get_widerface_ann_info(lines[j])
anno.update({'image_id': im_id, 'id': bnd_id})
output_json_dict['annotations'].append(anno)
bnd_id += 1
else:
print("The image dose not exist: {}".format(os.path.join(img_dir, image_name)))
bbox_num = 1 if bbox_num == 0 else bbox_num
i += bbox_num
im_id += 1
with open(save_path, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def get_widerface_image_info(img_root, img_relative_path, img_id):
image_info = {}
save_path = os.path.join(img_root, img_relative_path)
if os.path.exists(save_path):
img = cv2.imread(save_path)
image_info["file_name"] = os.path.join(os.path.basename(
os.path.dirname(img_root)), os.path.basename(img_root),
img_relative_path)
image_info["height"] = img.shape[0]
image_info["width"] = img.shape[1]
image_info["id"] = img_id
return image_info
def get_widerface_ann_info(info):
info = [int(x) for x in info.strip().split()]
anno = {
'area': info[2] * info[3],
'iscrowd': 0,
'bbox': [info[0], info[1], info[2], info[3]],
'category_id': 0,
'ignore': 0,
'blur': info[4],
'expression': info[5],
'illumination': info[6],
'invalid': info[7],
'occlusion': info[8],
'pose': info[9]
}
return anno
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--dataset_type',default='labelme',
help='the type of dataset, can be `voc`, `widerface`, `labelme` or `cityscape`')
parser.add_argument('--image_label_dir_train',
default=['2347/train/images'],
help='image and label dir')
parser.add_argument('--image_label_dir_test',
default=['2347/test/images'],
help='image and label dir')
parser.add_argument('--image_input_dir',
default='./card_det/process_ok',
help='image directory')
parser.add_argument(
'--output_dir', help='output dataset directory', default='./card_det/process_ok/ppyoloer/demo')
parser.add_argument(
'--train_proportion',
help='the proportion of train dataset',
type=float,
default=1.0)
parser.add_argument(
'--val_proportion',
help='the proportion of validation dataset',
type=float,
default=1.0)
parser.add_argument(
'--test_proportion',
help='the proportion of test dataset',
type=float,
default=0.0)
parser.add_argument(
'--voc_anno_dir',
help='In Voc format dataset, path to annotation files directory.',
type=str,
default=None)
parser.add_argument(
'--voc_anno_list',
help='In Voc format dataset, path to annotation files ids list.',
type=str,
default=None)
parser.add_argument(
'--voc_label_list',
help='In Voc format dataset, path to label list. The content of each line is a category.',
type=str,
default=None)
parser.add_argument(
'--voc_out_name',
type=str,
default='voc.json',
help='In Voc format dataset, path to output json file')
parser.add_argument(
'--widerface_root_dir',
help='The root_path for wider face dataset, which contains `wider_face_split`, `WIDER_train` and `WIDER_val`.And the json file will save in this path',
type=str,
default=None)
args = parser.parse_args()
try:
assert args.dataset_type in ['voc', 'labelme', 'cityscape', 'widerface']
except AssertionError as e:
print(
'Now only support the voc, cityscape dataset and labelme dataset!!')
os._exit(0)
img_dir_list = []
label_dir_list = []
if args.dataset_type == 'voc':
assert args.voc_anno_dir and args.voc_anno_list and args.voc_label_list
label2id, ann_paths = voc_get_label_anno(
args.voc_anno_dir, args.voc_anno_list, args.voc_label_list)
voc_xmls_to_cocojson(
annotation_paths=ann_paths,
label2id=label2id,
output_dir=args.output_dir,
output_file=args.voc_out_name)
elif args.dataset_type == "widerface":
assert args.widerface_root_dir
widerface_to_cocojson(args.widerface_root_dir)
else:
files_list = args.image_label_dir_train
for file in files_list:
img_file = os.path.join(args.image_input_dir, file)
label_file = os.path.join(args.image_input_dir, file.replace('/images','/labels'))
try:
assert os.path.exists(img_file)
img_dir_list.append(img_file)
except AssertionError as e:
print(img_file, 'The json folder does not exist!')
os._exit(0)
try:
assert os.path.exists(label_file)
label_dir_list.append(label_file)
except AssertionError as e:
print(label_file, 'The json folder does not exist!')
os._exit(0)
files_list = args.image_label_dir_test
for file in files_list:
img_file = os.path.join(args.image_input_dir, file)
label_file = os.path.join(args.image_input_dir, file.replace('/images', '/labels'))
try:
assert os.path.exists(img_file)
img_dir_list.append(img_file)
except AssertionError as e:
print(img_file, 'The json folder does not exist!')
os._exit(0)
try:
assert os.path.exists(label_file)
label_dir_list.append(label_file)
except AssertionError as e:
print(label_file, 'The json folder does not exist!')
os._exit(0)
try:
assert os.path.exists(args.image_input_dir)
except AssertionError as e:
print('The image folder does not exist!')
os._exit(0)
# Deal with the json files.
if not os.path.exists(args.output_dir + '/annotations'):
os.makedirs(args.output_dir + '/annotations')
if args.train_proportion != 0:
train_data_coco = deal_json(args.dataset_type,
args.image_input_dir, #所在主文件夹
args.image_label_dir_train) #各个子文件夹
train_json_path = osp.join(args.output_dir + '/annotations',
'instance_train.json')
json.dump(
train_data_coco,
open(train_json_path, 'w'),
indent=4,
cls=MyEncoder)
if args.val_proportion != 0:
val_data_coco = deal_json(args.dataset_type,
args.image_input_dir,
args.image_label_dir_test)
val_json_path = osp.join(args.output_dir + '/annotations',
'instance_val.json')
json.dump(
val_data_coco,
open(val_json_path, 'w'),
indent=4,
cls=MyEncoder)
if __name__ == '__main__':
main()
3.训练参数配置;
可以参考该链接:手把手教你使用PP-YOLOE-R进行旋转框检测 - 飞桨AI Studio
我这边还修改了图片的输入尺寸为640*640:
PaddleDetection-release-2.6/configs/rotate/ppyoloe_r/_base_/ppyoloe_r_reader.yml

修改了epoch后,还对max_epochs和预热的epoch进行了修改:
PaddleDetection-release-2.6/configs/rotate/ppyoloe_r/_base_/optimizer_3x.yml

4.主干的迁移;
正在处理中;(计划是将yolov5_obb中的轻量级主干运用到PPYOLOE-R)
其中遇到的问题:
1.数据转化问题
(略)训练使用的json文件和测试的json文件同时生成;
2.修改yaml问题:
ERROR: yaml.parser.ParserError: while parsing a block mapping in “./docker-peer.yaml“原因:空格导致的未对齐(严格意义上的对齐)
解决方案,添加或者删除空格,使得同一层的保持对齐。
问题详情查看:
yaml.parser.ParserError: while parsing a block mapping · Issue #8339 · PaddlePaddle/PaddleDetection · GitHub
3.训练时回报问题:
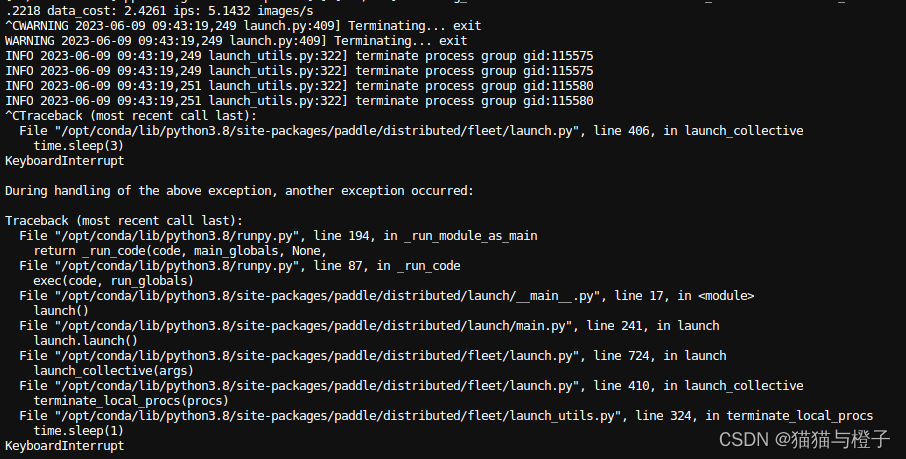
不知道什么原因导致的,重新训练就可以了;
4.使用 PaddleDetection-release-2.6/configs/rotate/ppyoloe_r/ppyoloe_r_crn_s_3x_dota.yml训练结果分析:
长宽比明显的目标效果较好,当图像中的目标接近正方形的时候,效果就比较差;这个问题issue中有人进行了提问,没有得到解答;参考链接:使用自己的数据集训练ppyoloe_r模型,dfl_loss下降到0.8左右不下降,可视化训练后预测结果角度预测有偏差 · Issue #8013 · PaddlePaddle/PaddleDetection · GitHub
目前没有最新回复,后续我这边是将计算角度的loss从0.05调到了0.25,(同事说有好的预训练模型可以进行这种尝试,没有好的预训练模型,这种尝试会失败),我这边已经进行了修改,正在训练,结果还没有出来;
PaddleDetection-release-2.6/configs/rotate/ppyoloe_r/_base_/ppyoloe_r_crn.yml

5.安装pycocotool遇到的问题
# pip install pycocotools==2.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple参考链接:https://wenku.csdn.net/answer/e2e2016ef0955f357421520784e2e8bf
补充一下知识点:
1.PPYOLOE-R的角度预测使用的是0-90°;yolov5-obb中角度和长宽比是分离的且基于anchor,所以yolov5obb在对接近方形的目标预测效果较好,但是宽高比远离1的目标效果较差;
未来的工作:
1.搜索文献的时候发现有yolov6旋转目标检测和mmrotate旋转目标检测,后期可以进行尝试;