1 数据库
[ ] 里的都是可选的操作。
1.1 创建数据库
语法:
create database [if not exists] database_name
[comment database_comment(注释)]
[location hdfs_path]
[with dbproperties (property_name-property=property_value,...)];
如:
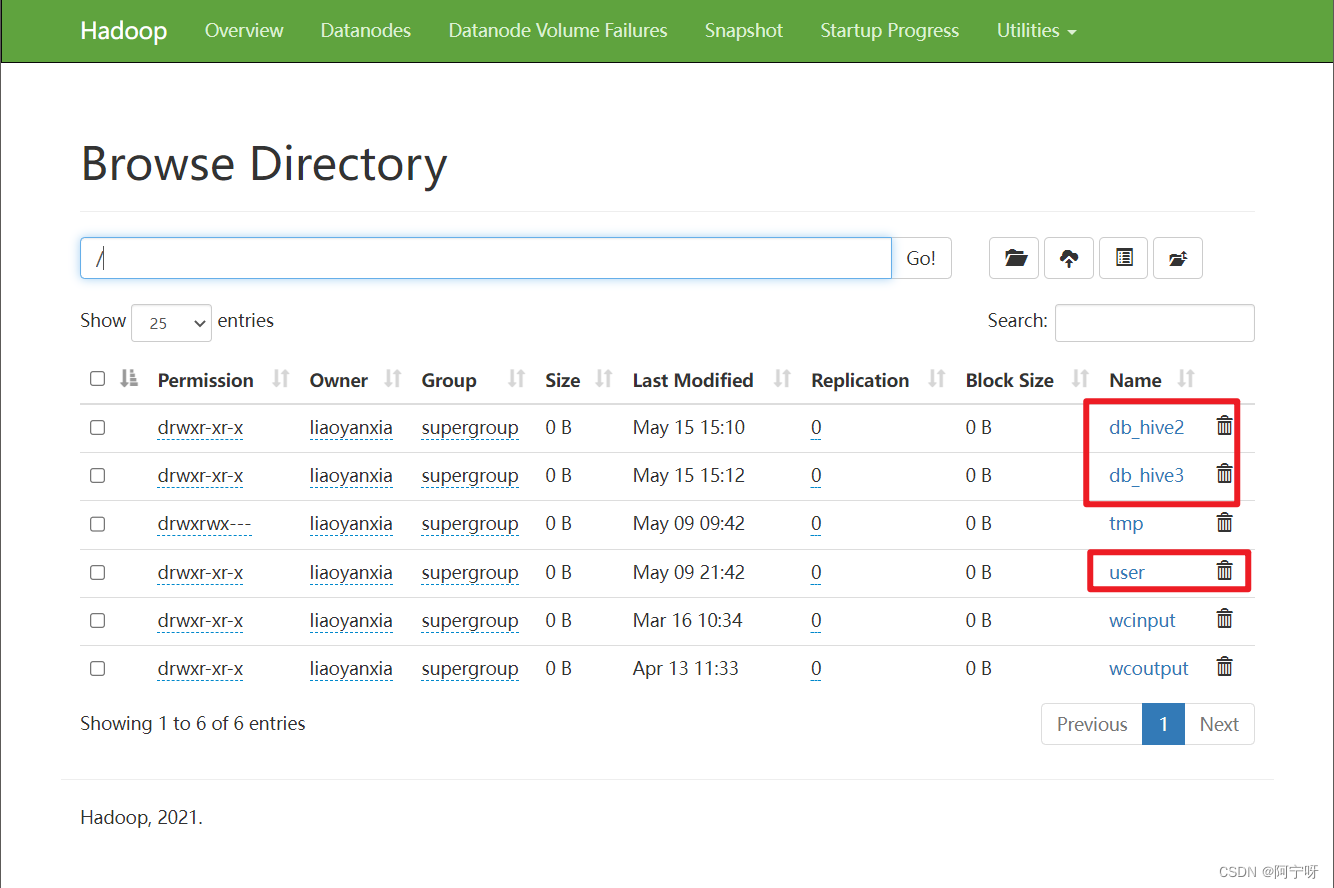
create database db_hive1;
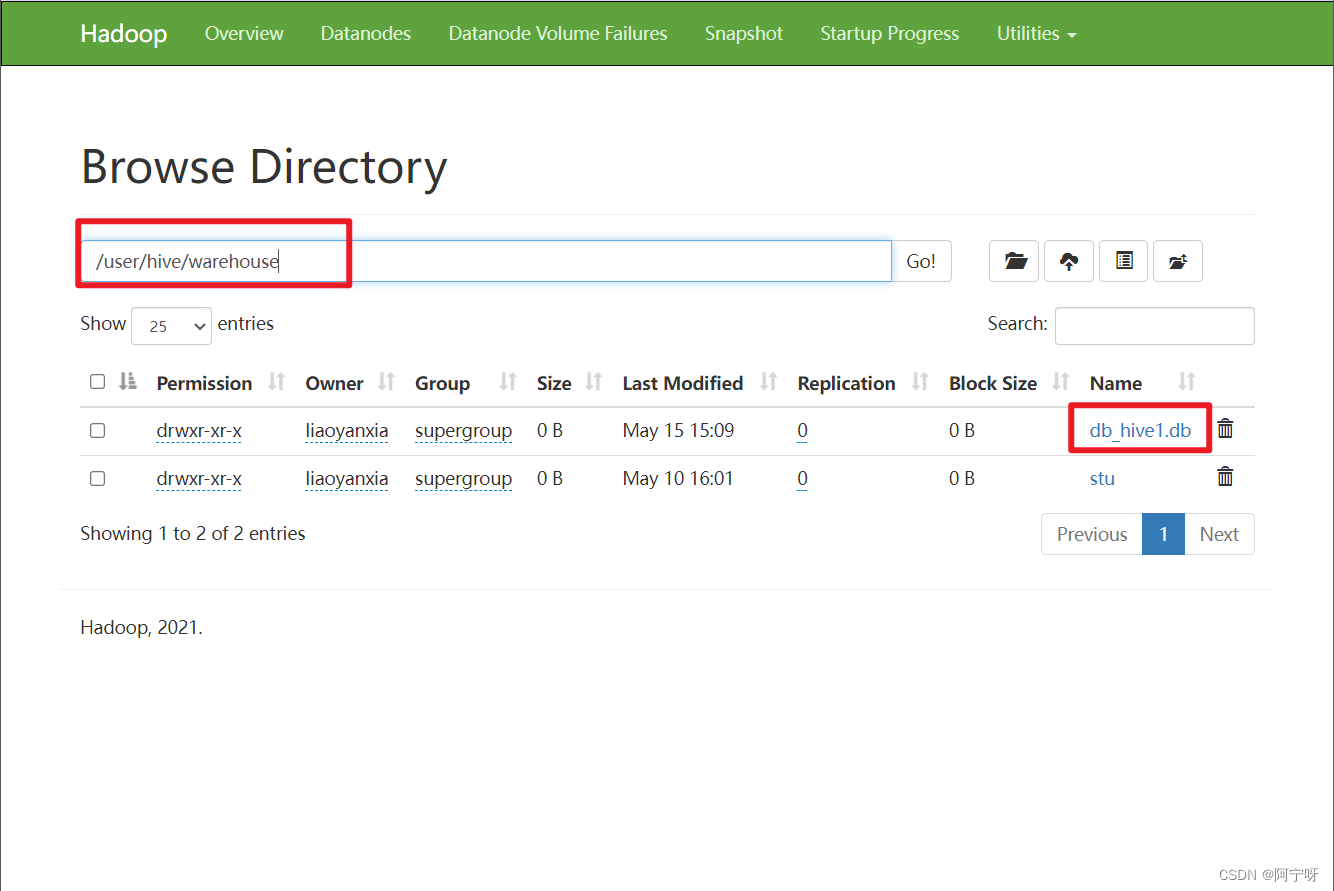
create database db_hive2 location '/db_hive2';
create database db_hive3 location '/db_hive3' with dbproperties ('create_date'='2023-5-12');
如果不指定路径则默认路径为:${hive.metastore.warehouse.dir}/database_name.db
1.2 查询数据库
(1)查看数据库
语法:
show databases [like 'identifier_with_wildcards'];
模糊匹配:like通配表达式说明:*表示任意个任意字符,|表示或的关系。
如:
show databases like 'db_hive*';
(2)查看数据库信息
语法:
describe database [extended] db_name;
[extended]:是否要展示更详细信息。
如:
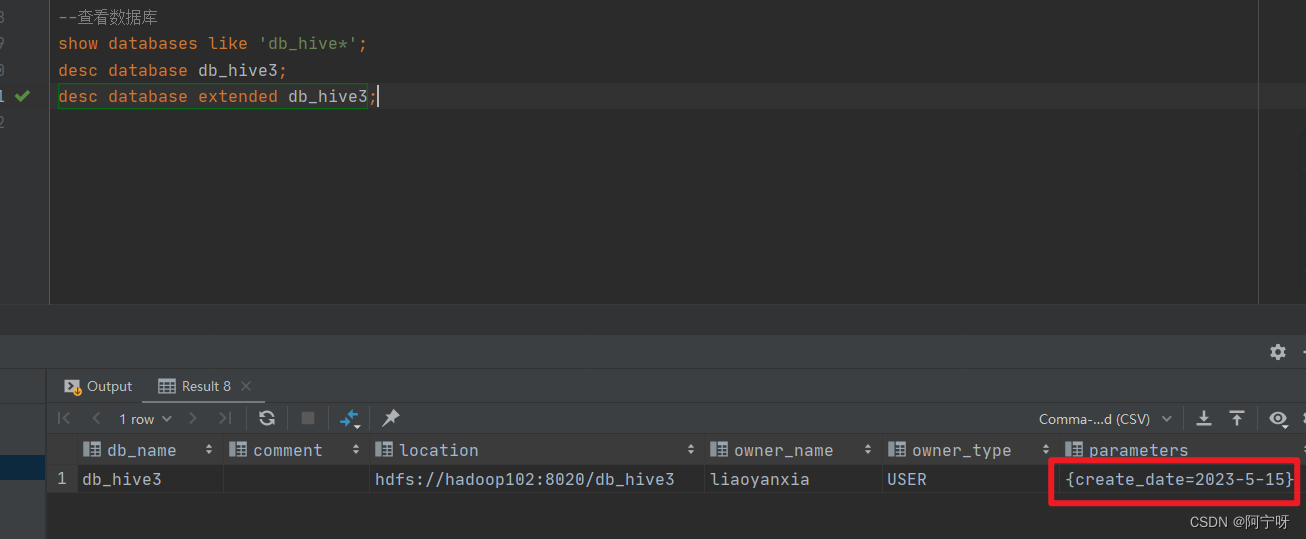
desc database db_hive3;
desc database extended db_hive3;
1.3 修改数据库
用户可以使用 alter database 命令修改dbproperties、location、owner user信息。
PS:在修改location时不会改变当前已有表的路径信息,只改变后续创建的新表的默认父目录。
语法:
--修改dbproperties:
alter database database_name set dbproperties (property_name=property_value,...);
--修改location:
alter database database_name set location hdfs_path;
--修改owner user:
alter database database_name set owner user user_name;
如:
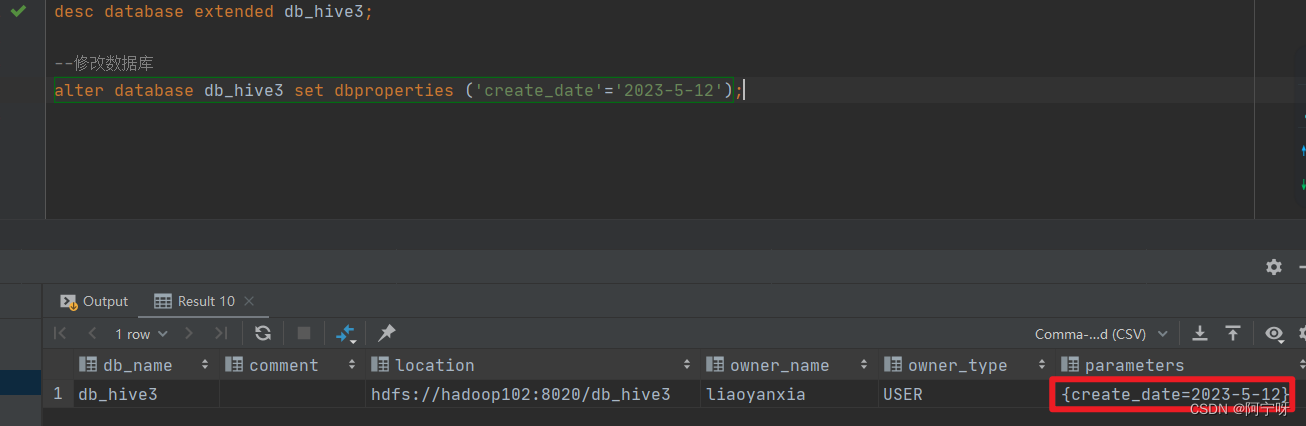
alter database db_hive3 set dbproperties ('create_date'='2023-5-12');
1.4 删除数据库
语法:
drop database [if not exists] database_name [restrict|cascade];
restrict:严格模式,若数据库不为空,则删除失败,默认为严格模式。
cascade:级联模式,若数据库不为空,则会把库中的表一起删除。
如:
--删除空数据库:
drop database db_hive2;
--删除非空数据库:
drop database db_hive3 cascade;
1.5 切换当前数据库
语法:
use database_name;
2 表
2.1 创建表
2.1.1 普通建表
语法:
create [temporary] [external] table [if not exists]
[db_name.]table_name
[(col_name data_type [comment col_comment], ...)]
[comment table_comment]
[partitioned by (col_name data_type [comment col_comment], ...)]
[clustered by (col_name,col_name, ...)
[sorted by (col_name [asc|desc], ...)] into num_buckets buckets]
[row format row_format]
[sorted as file_format]
[location hdfs_path]
[tblproperties (property_name=property_value, ...)]
关键字说明:
(1)temporary:
临时表,该表只在当前会话可见,会话结束表会被删除,常用于测试。
(2)external(重点):
表示外部表:Hive只接管元数据,而不完全接管HDFS中的数据;在删除表时只有元数据会被删除,而hdfs文件不会被删除。
而内部表(管理表):Hive会完全接管该表,包括元数据和HDFS中的数据;在删除表时会把hdfs数据和元数据一起删除。
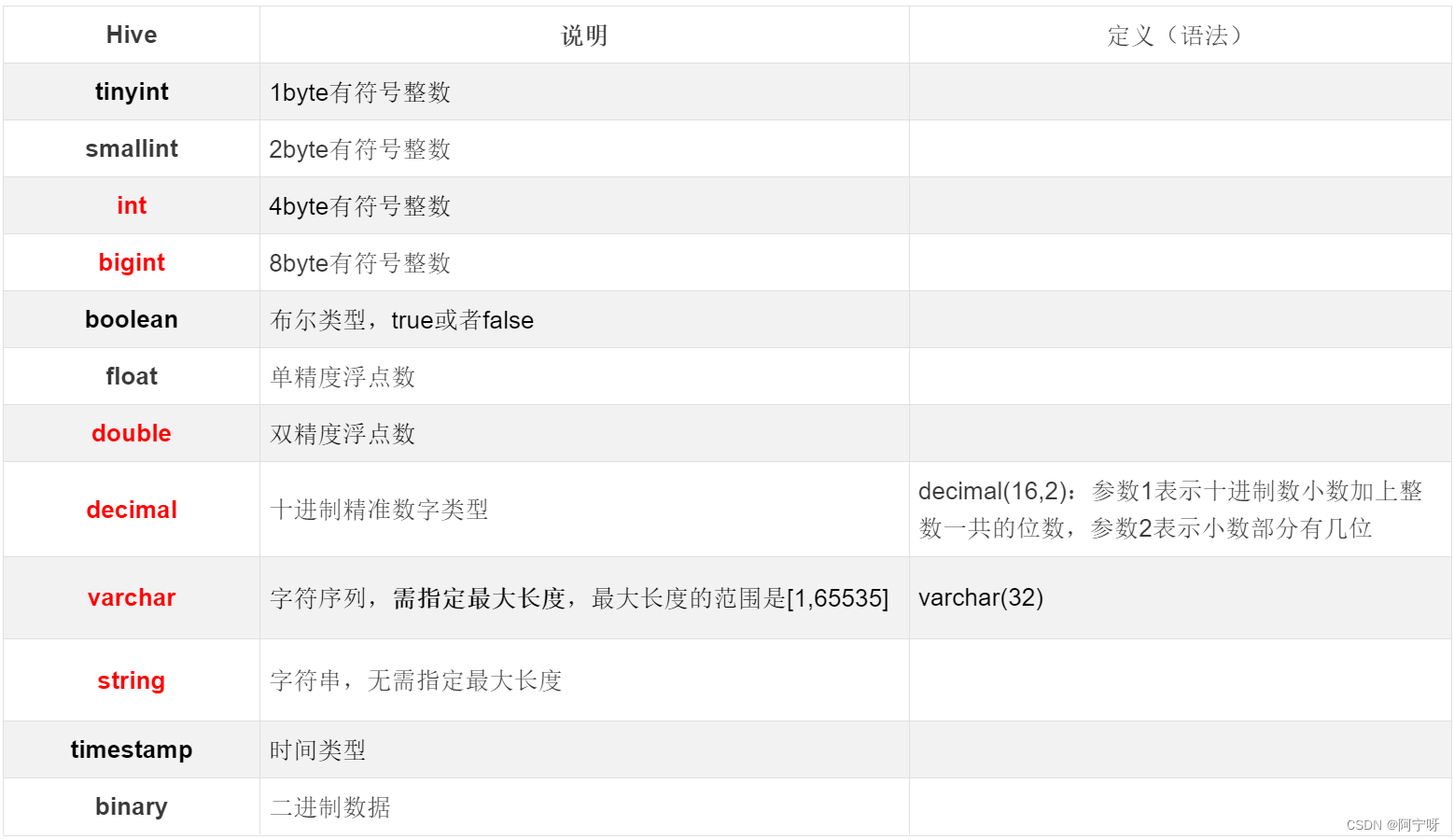
(3)data_type(重点):
Hive中字段类型分为基本数据类型和复杂数据类型。
基本数据类型:
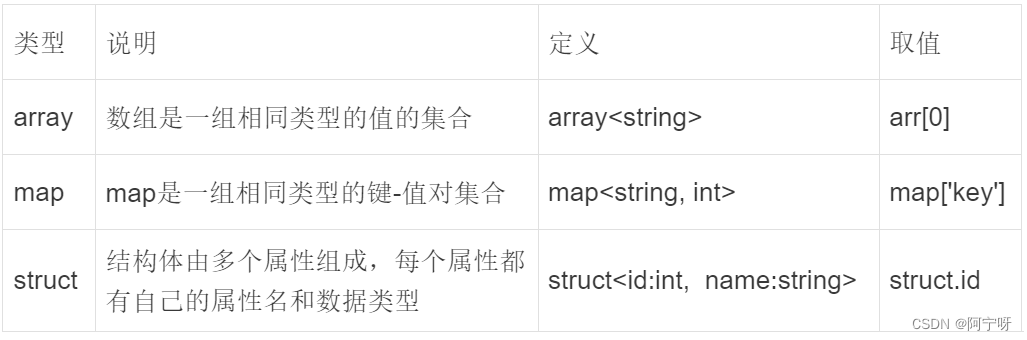
复杂数据类型:
类型转换:
Hive的基本数据类型可以进行类型转换。
隐式转换:
用户不需要显式修改sql语句,hive会根据预置规则完成转换。
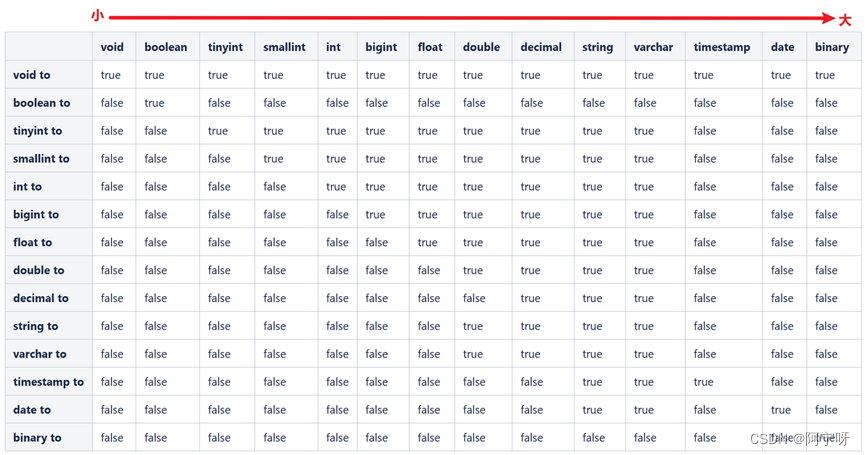
表中小的类型可以转为大的类型。
规则:
(i)任何整数类型可以隐式转换为范围更广的类型:tinyint->int->bigint。
(ii)所有整数类型、float和string可以隐式转为double。
(iii)boolean不可以转为任何其它类型。
如:select ‘1’+1; 结果为double类型的2,隐式转换中会找到两者可以参与转换的最小数据类型进行转换。
显式转换:
由用户显示修改sql语句,可以借助cast函数完成显式类型转换。
语法:
cast(expr as <type>)
--如string->int
select cast('111' as int);
select '1' +2, cast('1' as int) +2;
--结果:
_c0 _c1
3.0 3
(4)partitioned by(重点):
创建分区表(可以加快查询),将一张表的数据按照指定的分区字段分到不同的路径里,之后的一个路径就代表hive表的一个分区。
分区根据:指定字段相同的值放到同一个分区,或按日期分区。
(5)clustered by … sorted by … into … buckets(重点):
创建分桶表(可以加快查询),将hive一张表的数据分散存储到多个文件中。
分散规则:指定一个或多个字段(用clustered by …),和指定buckets个数(一个buckets一个文件),对id进行取模运算并放到buckets中,sorted by … 表示对分桶里的数据进行排序。
(6)row format(重点):
指定SERDE,SERDE是Serializer and Deserializer的简写。Hive使用SERDE序列化和反序列化每行数据。
Hive表的读数据流程:HDFS files --> InputFileFormat --> <key, value> --> Deserializer --> Row object
Hive表的写数据流程:Row object --> Serializer --> <key, value> --> OutputFileFormat --> HDFS files
语法一:
row format delimited
[fields terminated by char]
[collection items terminated by char]
[map keys terminated by char]
[lines terminated by char]
[null defined as char]
关键字说明:
(i)delimited:
表示对文件中的每个字段按照特定分割符进行分割,其会使用默认的SERDE对每行数据进行序列化和反序列化。
(ii)fields terminated by:列分割符。
(iii)collection items terminated by:map、struct(结构体只会保存字段的值,每个字段的分隔符)和array中每个元素之间的分隔符。
(iv)map keys terminated by:map中的key与value的分隔符。
(v)lines terminated by:行分隔符。
(vi)null defined as:如果某个字段为null时也必须要存储,默认”\n”。
语法二:
row format serde serde_name [with serdeproperties(property_name=property_value, ...)]
serde:用于指定其它内置的serde或者用户自定义的serde。如JSON SERDE可用于出来json字符串,serde_name为全列名(用于序列化和反序列化)。
(7)stored as(重点):
指定文件格式,常用的文件格式有,textfile(默认值),sequence file,orc file(列式存储)、parquet file(列式存储)等等,stored as 声明的文件格式由hive自动进行转换操作。
(8)location:
指定表所对应的HDFS路径,若不指定路径,其默认值为${hive.metastore.warehouse.dir}/db_name.db/table_name。
(9)tblproperties:
用于配置表的一些键值对参数。
案例
(1)内部表:
Hive中默认 创建的表都是内部表(管理表),Hive会完全管理表的元数据和数据文件。
在 /opt/module/hive/datas/下创建一个txt文件:
vim /opt/module/hive/datas/student.txt
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
创建内部表:
create table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t'
localtion '/user/hive/warehouse/student';
上传文件到hive表的指定路径:
hadoop fs -put student.txt /user/hive/warehouse/student
删除表,观察HDFS中的数据文件是否存在:
drop table student; --HDFS中的数据被删除
(2)外部表:
外部表用于处理其它工具上传的数据文件,只负责管理元数据,不负责管理HDFS中的数据文件。
创建外部表:
create external table if not exists student(
id int,
name string
)
roe format delimited fields terminated by '\t'
location '/user/hive/warehouse/student';
上传文件到Hive表指定的路径:
hadoop fs -put syudent.txt /user/hive/warehouse/student
删除表,观察HDFS中的数据文件是否存在:
drop table student; --HDFS中的数据还存在,因为删除外部表只会删除元数据,不会删除与之相关的HDFS数据文件。
(3)SERDE和复杂数据类型:
要求:
JSON格式的文件交由Hive处理分析。
在/opt/module/hive/datas/下创建teacher.txt文件:
{
"name":"zhangsan"
"friends":[
"lisi",
"wangwu"
],
"student":{
"chenming":20,
"ligui":23
},
"address":{
"city":"beijing",
"street":"jingsong",
"postal_code":10010
}
}
使用 json serde设计表字段,表字段与JSON字符串的一级字段一样;使用复杂数据类型保持JSON中的嵌套结构,创建表:
create table teacher
(
name string,
friends array<string>,
student map<string,int>,
address struct<city:string,street:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/user/hive/warehouse/teacher';
将teacher.txt文件上传到Hive表的指定路径:
hadoop fs -put teacher.txt /user/hive/warehouse/teacher
在复杂数据类型的字段中取值:
select name form teacher;
--取array中的值:
select friends[0] from teacher;
select size(friends) from teacher;
--取map<string,int>里的字段值:
select map_keys(students) from teacher;
select map_values(students) from teacher;
--判断map中是否含有某个key的值:
select array_contains(map_keys(students),'ligui') from taecher;
--取struct里的字段值:
select address.city from teacher;

2.1.2 create table as select (CTAS)建表
用create table as select 建表之后有数据,且只能创建内部表。
用select查询的结果直接建表,新建的表结构和查询语句的结构保持一致,且select查询的结构放入新建的表中。
语法:
create [temporary] table [if not exists] table_name
[comment table_comment]
[row format row_format]
[stored as file_format]
[location hdfs_path]
[tblproperties (property_name=property_value, ...)]
[as select_statement]
如:
create table teacher1 as select * from teacher;
2.1.3 create table like建表
允许用户复刻一张以及存在的表结构,且创建的新表无数据。
create [temporary] [external] table [if not exists]
[db_name.]table_name
[like exist_table_name]
[row format row_format]
[stored as file_format]
[location hdfs_path]
[tblproperties (property_name=property_value, ...)]
如:
create table teacher2 like teacher;
2.2 查看表
2.2.1 查看完整表的创建语句
语法:
show create table table_name;
ROW FORMAT SERDE
‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’ 对一行数据进行序列化和反序列化
STORED AS INPUTFORMAT stored as与文件底层格式有关,因为读写数据流,声明怎么读写文件
‘org.apache.hadoop.mapred.TextInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.sq.io.HiveIgnoreKeyTextOutputFormat’
LOCATION
‘hdfs://hadoop102:8020/user/hive/warehouse/stu’
TBLPROPERTIES(
‘bucketing_version’=’2’,
‘last_modified_by’=’liaoyanxia’
‘last_modified_time’=’1668755681’
‘transient_clastDdlTime’=’1668755681’)
2.2.2 查看所有表
语法:
show tables [in database_name] like ['identifier_with_wildcards'];
like:通配表达式说明,*表示任意个任意字符,|表示或。
如:
show tables like 'db_hive*';
2.2.3 查看表信息
语法:
describe [extended | formatted] [db_name.]table_name;
extended:展示详细信息。
formatted:对详细信息进行格式化展示。
如:
--查看基本信息:
desc stu;
--查看更多信息:
desc formatted stu;
2.3 修改表
2.3.1 重命名表
语法:
alter table table_name rename to new_table_name;
如:
alter table stu rename to stu1;
2.3.2 修改列信息
语法:
--增加列:新增列位于末尾
alter table table_name add columns (col_name data_type [comment col_comment], ...);
--更新列:修改列名、数据类型、注释信息以及在表中的位置
alter table table_name change [column] col_old_name col_new_name column_type [comment col_comment] [first|after column_name];
--替换列
alter table table_name replace columns (col_name data_type [comment col_comment], ...);
如:
--添加列:
alter table stu add columns(age int);
--更新列:
alter table stu change column age ages double;
--替换列:
alter table stu replace columns(id int,name string);
--查询表结构:
desc stu;
2.4 删除表
语法:
drop table [if not exists] table_name;
如:
drop table stu;
2.5 清空表
语法:
truncate [table] table_name;
truncate只能清空内部表(管理表),不能删除外部表中的数据。
如:
truncate table student;