文档总目录
英文原文(Benchmark of dense decompositions)
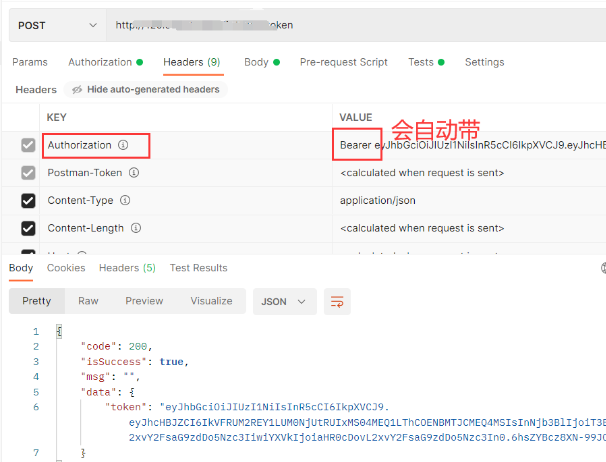
本页介绍了 Eigen 为各种方阵和过约束问题提供的稠密矩阵分解的速度比较。
有关线性求解器、分解的特征和数值鲁棒性的更一般概述,请查看 此表。
该基准测试已在配备英特尔酷睿 i7 @ 2.6 GHz 的笔记本电脑上运行,并使用启用了 AVX 和 FMA 指令集但没有多线程的 clang 进行编译。使用单精度浮点数,对于 double,可以通过将时间乘以一个因子 2 来得到一个很好的估计。
方阵是对称的,对于过约束矩阵,测试报告的时间包括计算对称协方差矩阵
A
T
A
A^TA
ATA 的成本,对于前四个基于 Cholesky 和 LU 的求解器,用符号 * 表示(表的右上角部分)。计时以毫秒为单位,因素与LLT分解有关, LLT分解速度最快,但也是最不通用和鲁棒的。

* : 此分解不支持对过度约束问题的直接最小二乘求解,并且报告的时间包括计算对称协方差矩阵
A
T
A
A^TA
ATA 的成本。
总结:
- LLT始终是最快的求解器。
- 对于很大程度上过度约束的问题,Cholesky/LU 分解的成本主要由对称协方差矩阵的计算决定。
- 对于大型问题,只有实现缓存友好阻塞策略的分解才能很好地扩展。包括LLT、PartialPivLU、HouseholderQR和BDCSVD。这解释了为什么对于
4k x 4k矩阵,HouseholderQR比LDLT更快。后面的Eigen版本,LDLT和ColPivHouseholderQR也会实现缓存友好阻塞策略。 - CompleteOrthogonalDecomposition基于ColPivHouseholderQR,因此它们达到了相同的性能水平。
上表由 bench/dense_solvers.cpp 文件生成,可以随意修改它以生成与你的硬件、编译器和问题大小相匹配的表格。