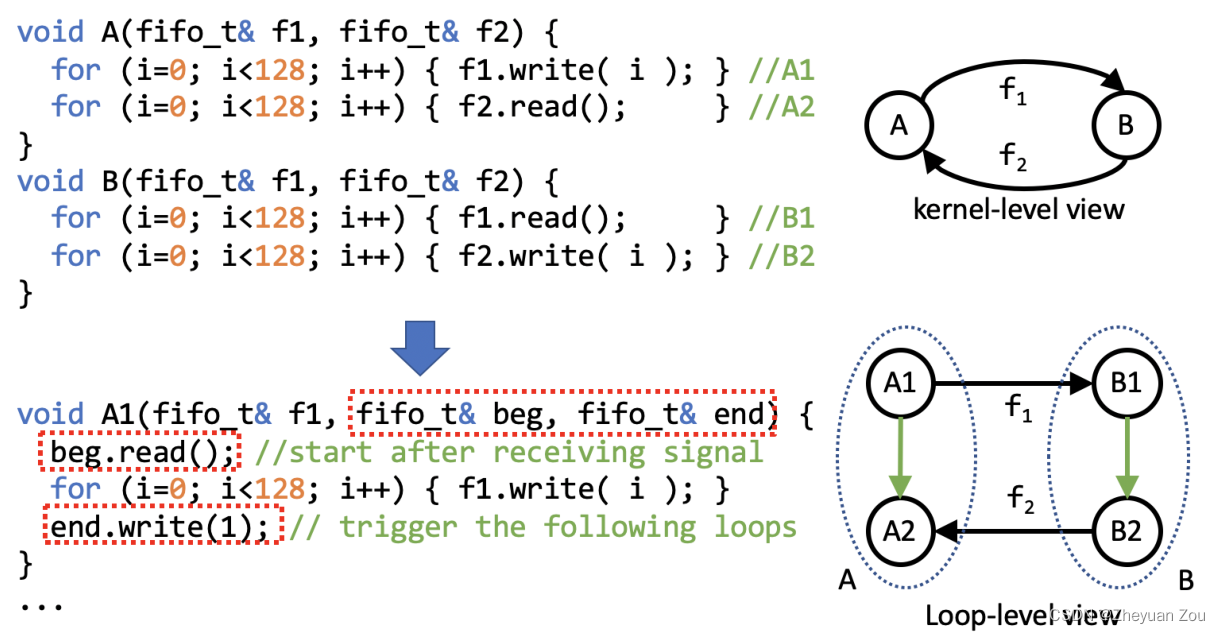
支持向量机是一种监督学习技术,主要用于分类,也可用于回归。它的关键概念是算法搜索最佳的可用于基于标记数据(训练数据)对新数据点进行分类的超平面。
一般情况下算法试图学习一个类的最常见特征(区分一个类与另一个类的特征),分类是基于学习到的这些代表性特征(因此分类是基于类之间的差异)。支持向量机的工作方式正好相反。它会找到类之间最相似的例子,这些就是支持向量。
SVM的核方法
核或核方法(也称为内核函数)是用于模式分析的不同类型算法的集合。它们可以使用线性分类器来解决非线性问题。核方法被应用于支持向量机(Support Vector Machines, SVM),用于分类和回归问题。SVM使用所谓的核技巧(Kernel Trick),即对数据进行转换,为可能的输出找到最佳边界。

核方法的使用条件
支持向量机算法使用一组定义为核的数学函数。核的功能是将数据作为输入,并将其转换为所需的形式。不同的支持向量机算法使用不同类型的核函数。这些函数可以是不同的类型。
例如线性、非线性、多项式、径向基函数(RBF)和sigmoid。核函数是一个相似函数。它是我们作为领域专家,提供给机器学习算法的一个功能。它接受两个输入,并计算出它们的相似程度。
假设我们的任务是学习对图像进行分类。我们有(图像,标签)对作为训练数据。想想典型的机器学习流程:我们获取图像,计算特征,将每张图像的特征串成一个向量,然后将这些“特征向量”和标签输入到学习算法中。
核函数提供了另一种选择。我们不需要定义大量的特征,而是定义了一个核函数来计算图像之间的相似性。将这个内核与图像和标签一起提供给学习算法,从而得到一个分类器。标准的支持向量机/逻辑回归/感知机公式不适用于核:它们适用于特征向量。那么如何使用核函数呢?下面两个定理解决了这个问题:
- 在某些条件下,每个核函数都可以表示为(可能是无限维)特征空间中的点积(Mercer定理)。
- 许多机器学习算法可以完全用点积来表示。
这两个事实意味着我可以用用点积的形式表示我们喜欢的机器学习算法,然后由于我的核在某些空间中也是一个点积,我们还可以用核来替换点积。
为什么使用核而不是特征向量?
一个很大的原因是,在很多情况下,计算核很容易,但是计算核对应的特征向量很困难。即使是简单核的特征向量也会在产生维度爆炸,对于像 RBF 内核这样的内核(k(x,y) = exp( -||x-y||²))相应的特征向量是无限维的。然而,相比之下核的维度几乎可以忽略不记。
许多机器学习算法可以只使用点积进行替代,所以我们可以用核替换点积,这样的话根本不必使用特征向量。这意味着我们可以使用高度复杂、计算效率高且性能高的核,而无需写下巨大且可能无限维的特征向量。所i如果不能直接使用核函数,我们将只能使用相对低维、低性能的特征向量。这个“技巧”被称为核技巧。
扩展解释
我们将进一步解释,以澄清一些关于核的一些容易混淆的概念,这些混淆往往会给数据专业人员带来麻烦:
将一个特征向量转换为更高维特征向量的函数不是核函数。因此 f(x) = [x, x²] 不是核函数。它只是一个新的特征向量。我们不需要用核来做到这一点。如果你想这样做需要在不破坏维度的情况下进行更复杂的特征转换。
核不仅仅限于 SVM。任何仅适用于点积的学习算法都可以使用核来进行改写。SVM 的想法很美,内核技巧很美,凸优化很美,而且它们完全独立的。
数学理解
为了从数学上理解核,我们先来理解Lili Jiang的公式,即:
K(x, y)=<f(x), f(y)=“”></f(x),>
这里的:
K是核函数,,X和Y是维度输入,F是从n维空间到m维空间的映射,< x, y >是点积。
我们假设有两个点,x= (2,3,4) y= (3,4,5)
那么K(x, y) = < f(x) f(y) >,让我们先计算< f(x) f(y) >

如上所示,f(x).f(y)和K(x, y)给出了相同的结果,但前一种方法需要大量的计算(因为将3个维度投影到9个维度),而使用核函数要简单得多。
常用核函数
1、线性核 Linear Kernel
它是最基本核类型,本质上通常是一维的。当有很多特征时,它被证明是最好的函数。对于文本分类问题,线性核是首选的方法,因为这类分类问题大多可以线性分离。
另外就是线性核函数比其他函数更快。
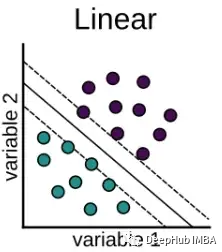
线性核公式
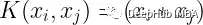
这里的xi和xj表示试图分类的数据。
2、多项式核 Polynomial Kernel
它是线性核的一种更广义的表示。但它不像其他核函数那样受欢迎,因为它的效率和准确性都较低。
多项式核公式
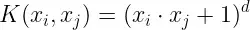
在这里‘.’表示两个值的点积,d表示度数。K(xi, xj)表示划分给定类的决策边界。
3、高斯核 Gaussian Kernel
这是一个常用的内核。它用于对给定数据集没有先验知识的情况。
高斯核公式
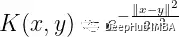
4、高斯径向基函数 Gaussian Radial Basis Function (RBF)
它是支持向量机中最常用的核函数之一。通常用于非线性数据。当没有数据的先验知识时,它有助于进行适当的分离。
高斯径向基公式

这里必须在代码中手动提供gamma的值(的值从0到1)。gamma的首选值是0.1。
5、拉普拉斯RBF核 Laplace RBF Kernel
它也是一个通用内核;在没有关于数据的先验知识时使用。
拉普拉斯RBF核公式

结果比较

6、贝塞尔函数核 Bessel Function Kernel
它主要用于去除数学函数中的交叉项。
公式

这里J是贝塞尔函数。
7、双曲正切核 Hyperbolic Tangent Kernel
我们可以在神经网络中使用它。
双曲正切核公式
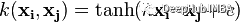
对于某些(不是所有)时候k>0和c<0。
8、Sigmoid核 Sigmoid Kernel
我们可以用它作为神经网络的代理。sigmoid核的激活函数是双极sigmoid函数。
Sigmoid核公式
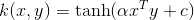
图像如下:
9、ANOVA kernel
它也被称为径向基函数核。它通常在多维回归问题中表现良好。
公式
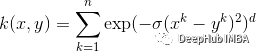
10、一维线性样条核 Linear Splines Kernel in One-Dimension
它在处理大型稀疏数据向量时很有用。它常用于文本分类。样条核在回归问题中也有很好的表现。
一维线性样条核公式
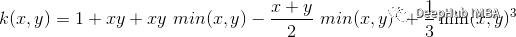
Sklearn中的核函数
到目前为止,我们已经讨论了关于核函数的理论信息。让我们看看Python中如何使用
这里我们使用sklearn中的iris 数据集
第一步是导入所需的包。
## Requried Python Packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
## Load iris dataset
iris = datasets.load_iris()
## Create features and target data
X = iris.data[:, :2]
y = iris.target
## Plotting
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
在上面的代码中,在加载所需的python包之后我们将加载的数据分成特征和目标数据。然后编写代码来绘制它。
现在让我们实现本文中讨论的几个SVM内核函数。
线性核
使用线性核来创建svc分类器。
## Creating the linear kernel
svc_classifier = svm.SVC(kernel='linear', C=C).fit(X, y)
C = 1.0
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
## Code of plotting
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.set_cmap("gist_rainbow")
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with linear kernel')
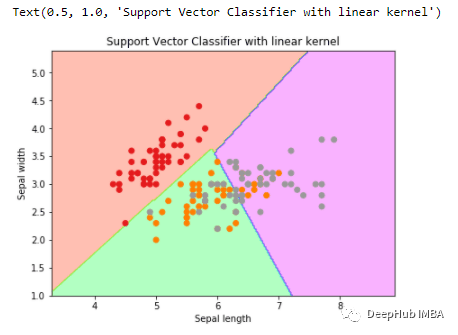
Sigmoid核
使用sigmoid核来创建svc分类器。
## Sigmoid kernel
svc_classifier = svm.SVC(kernel='sigmoid', C=C).fit(X, y)
C = 1.0
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
## Code for plotting
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.set_cmap("gist_rainbow")
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with sigmoid kernel')
pl.plot()
RBF核
使用RBF核来制作我们的svc分类器。
## rbf kernel
svc_classifier = svm.SVC(kernel='rbf', C=C).fit(X, y)
C=1.0
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
## Code for creating plots
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.set_cmap("gist_rainbow")
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with rbf kernel')
plt.plot()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0sSW7bH1-1670207446410)(http://images.overfit.cn/upload/20221205/f9a45aafdbbb42eab7a330bbd01a3f93.png)]
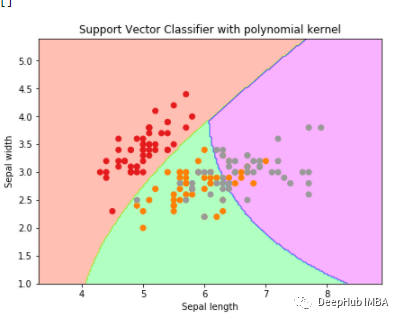
多项式核
使用多项式核来创建svc分类器。
## Polynomial kernel
svc_classifier = svm.SVC(kernel='poly', C=C).fit(X, y)
C = 1.0
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
## Code for creating the graph
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.set_cmap("gist_rainbow")
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with polynomial kernel')
plt.plot()
如何选择最佳核函数
如何选择最佳的内核函数呢?
这完全取决于你要解决的问题是什么。如果你的数据是线性可分的,不用多想,就用线性核。
因为与其他核函数相比,线性核函数需要更少的训练时间。
- 线性核在文本分类问题中最受青睐,因为它对大型数据集表现良好。
- 当没有关于不可用数据的附加信息时,高斯核往往能给出良好的结果。
- RBF核也是一种高斯核,它对高维数据进行投影,然后寻找其线性分离。
- 多项式核对于所有训练数据都进行了归一化会有很好的结果。
https://avoid.overfit.cn/post/aeb97550b8ee4e1bba782806c1012f3d
作者:Amrita Sarkar
![[附源码]JAVA毕业设计律师事务所网站(系统+LW)](https://img-blog.csdnimg.cn/8403344456ae4ffbbe538c1716c6c7dd.png)