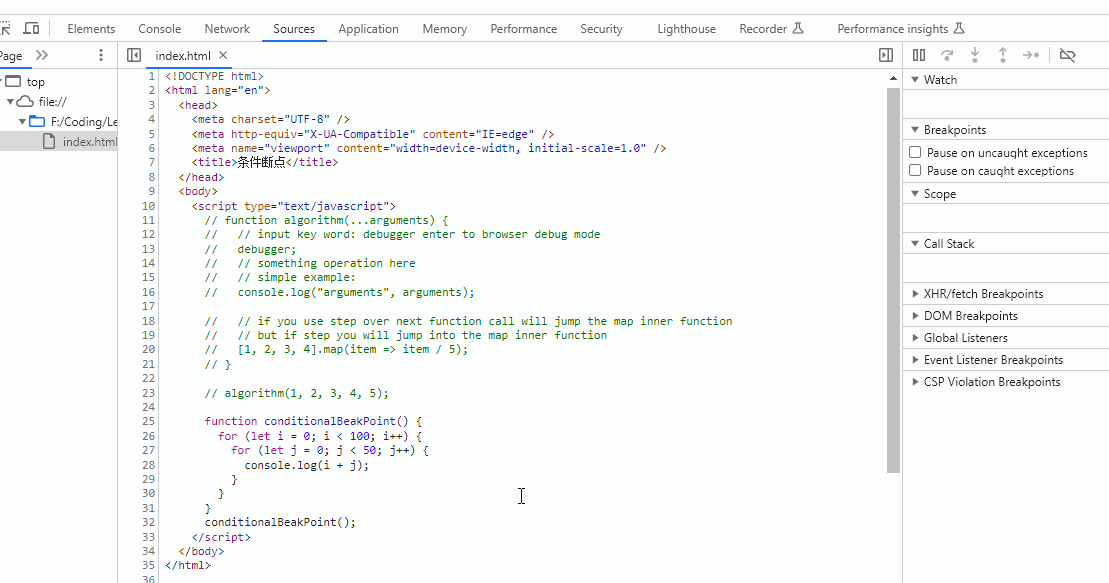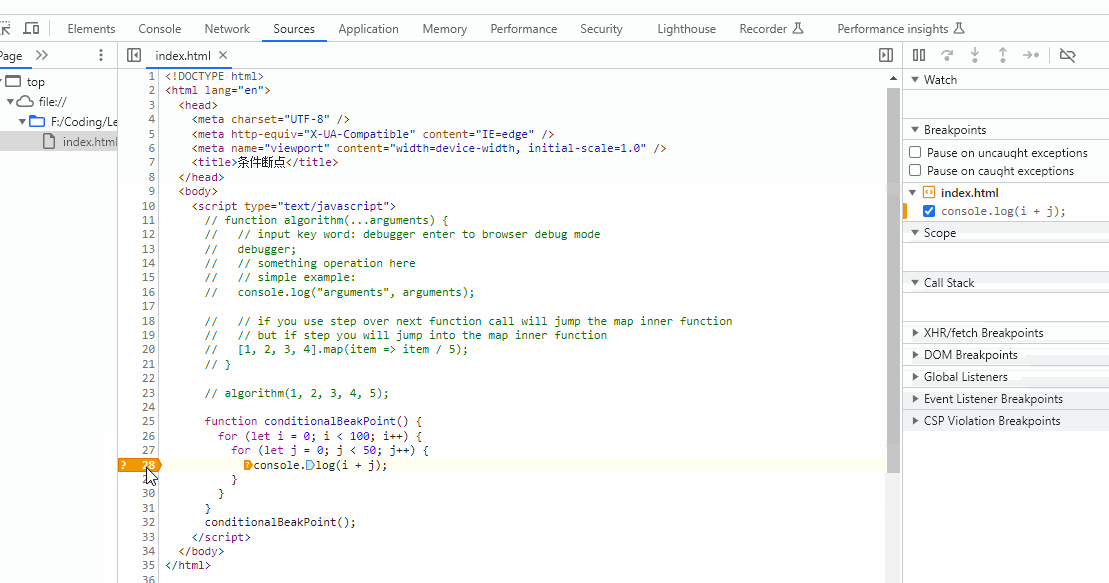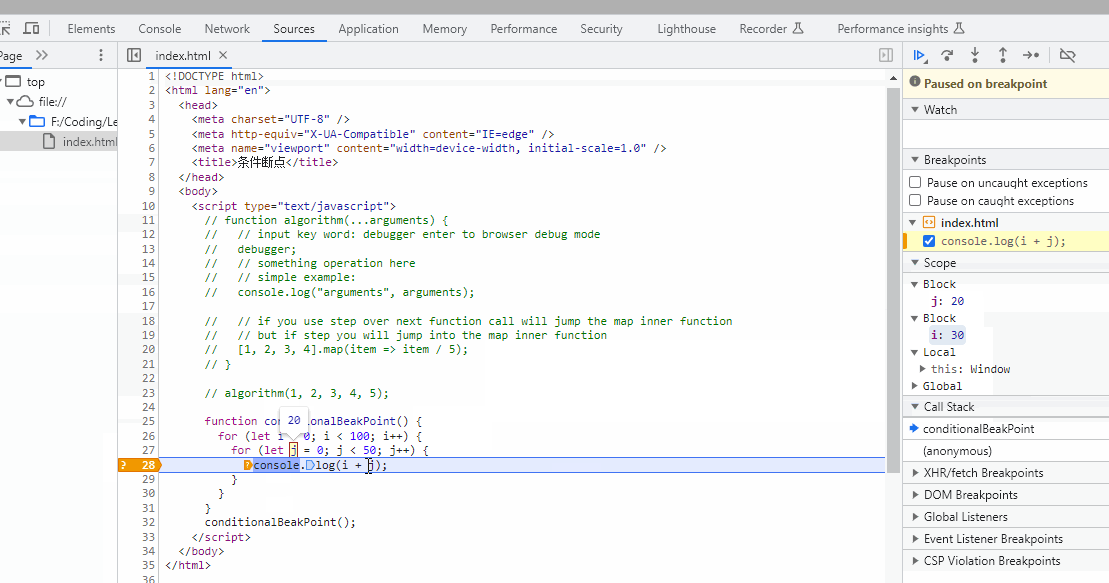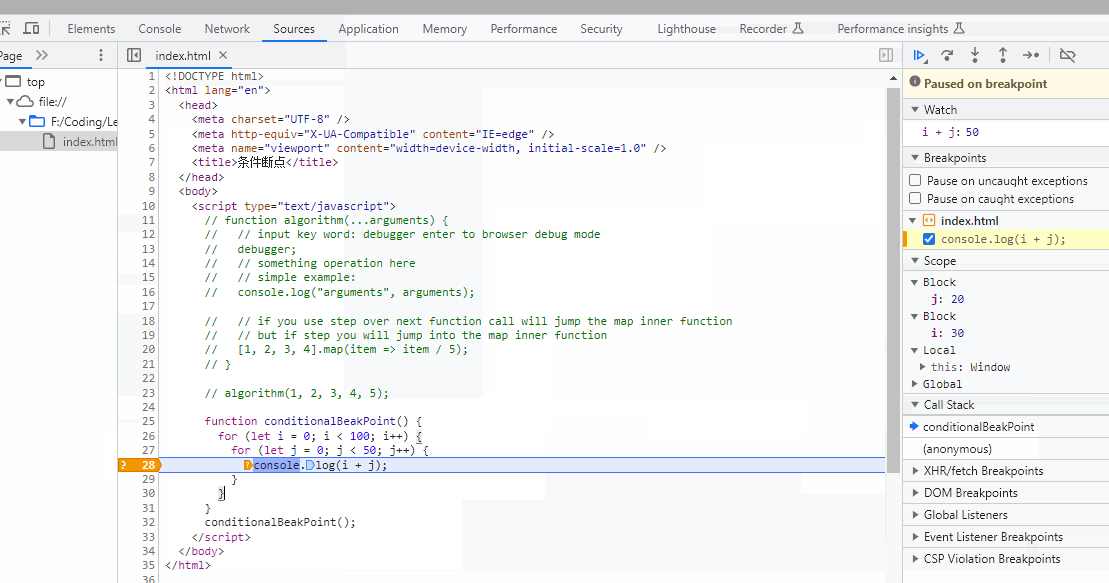
前言
本篇文章主要介绍的关于本人从刚工作到现在使用kafka的经验,内容非常多,包含了kafka的常用命令,在生产环境中遇到的一些场景处理,kafka的一些web工具推荐等等。由于kafka这块的记录以及经验是从我刚开始使用kafka,从2017年开始,可能里面有些内容过时,请见谅。温馨提醒,本文有3w多字,建议收藏观看~
Kafka理论知识
kafka基本介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Kafka 有如下特性:
-以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
-高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持KafkaServer间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
kafka的术语
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker。
-Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
-Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition。
- Producer:负责发布消息到Kafka broker。
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer
Group(可为每个Consumer指定group name,若不指定group
name则属于默认的group)。
kafka核心Api
kafka有四个核心API
- 应用程序使用producer API发布消息到1个或多个topic中。
- 应用程序使用consumer API来订阅一个或多个topic,并处理产生的消息。
- 应用程序使用streams
API充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个topic,有效地将输入流转换到输出流。
- connector
API允许构建或���行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。
示例图如下:

kafka面试问题
Kafka的用途有哪些?使用场景如何?
使用kafka的目的是为了解耦、异步、削峰。
消息系统: Kafka
和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka
还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
存储系统: Kafka
把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于
Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka
作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为"永久"或启用主题的日志压缩功能即可。
流式处理平台: Kafka
不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader
副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync
Replicas),ISR 集合是 AR 集合中的一个子集。
ISR的伸缩:
leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当
follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。如果
OSR 集合中有 follower 副本"追上"了 leader 副本,那么 leader 副本会把它从
OSR 集合转移至 ISR 集合。默认情况下,当 leader 副本发生故障时,只有在
ISR 集合中的副本才有资格被选举为新的 leader,而在 OSR
集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
replica.lag.time.max.ms : 这个参数的含义是 Follower 副本能够落后 Leader
副本的最长时间间隔,当前默认值是 10 秒。
unclean.leader.election.enable:是否允许 Unclean 领导者选举。开启
Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader
副本一直存在,不至于停止对外提供服务,因此提升了高可用性。
Kafka中的HW、LEO、LSO、LW等分别代表什么?
HW 是 High Watermark
的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个
offset 之前的消息。
LSO是LogStartOffset,一般情况下,日志文件的起始偏移量 logStartOffset
等于第一个日志分段的 baseOffset,但这并不是绝对的,logStartOffset
的值可以通过 DeleteRecordsRequest 请求(比如使用 KafkaAdminClient 的
deleteRecords()方法、使用 kafka-delete-records.sh
脚本、日志的清理和截断等操作进行修改。
如上图所示,它代表一个日志文件,这个日志文件中有9条消息,第一条消息的
offset(LogStartOffset)为0,最后一条消息的 offset 为8,offset
为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的 HW
为6,表示消费者只能拉取到 offset 在0至5之间的消息,而 offset
为6的消息对消费者而言是不可见的。
LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的
offset,上图中 offset 为9的位置即为当前日志文件的 LEO,LEO
的大小相当于当前日志分区中最后一条消息的 offset 值加1。分区 ISR
集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的
HW,对消费者而言只能消费 HW 之前的消息。
LW 是 Low Watermark 的缩写,俗称"低水位",代表 AR 集合中最小的
logStartOffset
值。副本的拉取请求(FetchRequest,它有可能触发新建日志分段而旧的被清理,进而导致
logStartOffset 的增加)和删除消息请求(DeleteRecordRequest)都有可能促使 LW
的增长。
Kafka中是怎么体现消息顺序性的?
可以通过分区策略体现消息顺序性。
分区策略有轮询策略、随机策略、按消息键保序策略。
按消息键保序策略:一旦消息被定义了 Key,那么你就可以保证同一个 Key
的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略
Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
序列化器:生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给
Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从 Kafka
中收到的字节数组转换成相应的对象。
分区器:分区器的作用就是为消息分配分区。如果消息 ProducerRecord
中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算
partition 的值。
Kafka 一共有两种拦截器:生产者拦截器和消费者拦截器。
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
消费者拦截器主要在消费到消息或在提交消费位移时进行一些定制化的操作。
消息在通过 send() 方法发往 broker
的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往
broker。拦截器(下一章会详细介绍)一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息
ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为
partition 代表的就是所要发往的分区号。
处理顺序 :拦截器->序列化器->分区器
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend()
方法来对消息进行相应的定制化操作。
然后生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给
Kafka。
最后可能会被发往分区器为消息分配分区。
Kafka生产者客户端的整体结构是什么样子的?
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender
线程(发送线程)。
在主线程中由 KafkaProducer
创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。
Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
RecordAccumulator 主要用来缓存消息以便 Sender
线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
Kafka生产者客户端中使用了几个线程来处理?分别是什么?
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender
线程(发送线程)。在主线程中由 KafkaProducer
创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender
线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper
是一个分布式的协调服务框架,Kafka
重度依赖它实现各种各样的协调管理。将位移保存在 ZooKeeper
外部系统的做法,最显而易见的好处就是减少了 Kafka Broker
端的状态保存开销。
ZooKeeper 这类元框架其实并不适合进行频繁的写更新,而 Consumer Group
的位移更新却是一个非常频繁的操作。这种大吞吐量的写操作会极大地拖慢
ZooKeeper 集群的性能
"消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据"这句话是否正确?如果正确,那么有没有什么hack的手段?
一般来说如果消费者过多,出现了消费者的个数大于分区个数的情况,就会有消费者分配不到任何分区。
开发者可以继承AbstractPartitionAssignor实现自定义消费策略,从而实现同一消费组内的任意消费者都可以消费订阅主题的所有分区:
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
在旧消费者客户端中,消费位移是存储在 ZooKeeper
中的。而在新消费者客户端中,消费位移存储在 Kafka
内部的主题__consumer_offsets 中。
当前消费者需要提交的消费位移是offset+1
有哪些情形会造成重复消费?
Rebalance
一个consumer正在消费一个分区的一条消息,还没有消费完,发生了rebalance(加入了一个consumer),从而导致这条消息没有消费成功,rebalance后,另一个consumer又把这条消息消费一遍。
消费者端手动提交
如果先消费消息,再更新offset位置,导致消息重复消费。
消费者端自动提交
设置offset为自动提交,关闭kafka时,如果在close之前,调用
consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
生产者端
生产者因为业务问题导致的宕机,在重启之后可能数据会重发
那些情景下会造成消息漏消费?
自动提交
设置offset为自动定时提交,当offset被自动定时提交时,数据还在内存中未处理,此时刚好把线程kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
生产者发送消息
发送消息设置的是fire-and-forget(发后即忘),它只管往 Kafka
中发送消息而并不关心消息是否正确到达。不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。
消费者端
先提交位移,但是消息还没消费完就宕机了,造成了消息没有被消费。自动位移提交同理
acks没有设置为all
如果在broker还没把消息同步到其他broker的时候宕机了,那么消息将会丢失
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?#
线程封闭,即为每个线程实例化一个 KafkaConsumer 对象
一个线程对应一个 KafkaConsumer
实例,我们可以称之为��费线程。一个消费线程可以消费一个或多个分区中的消息,所有的消费线程都隶属于同一个消费组。
消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。
获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer
实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。具体架构如下图所示:
简述消费者与消费组之间的关系
Consumer Group 下可以有一个或多个 Consumer
实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer
Group。
Consumer Group 下所有实例订阅的主题的单个分区,只能分配给组内的某个
Consumer 实例消费。这个分区当然也可以被其他的 Group 消费。
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
在执行完脚本之后,Kafka 会在 log.dir 或 log.dirs
参数所配置的目录下创建相应的主题分区,默认情况下这个目录为/tmp/kafka-logs/。
在 ZooKeeper
的/brokers/topics/目录下创建一个同名的实��点,该节点中记录了该主题的分区副本分配方案。示例如下:
[zk: localhost:2181/kafka(CONNECTED) 2] get
/brokers/topics/topic-create
{“version”:1,“partitions”:{“2”:[1,2],“1”:[0,1],“3”:[2,1],“0”:[2,0]}}
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加,使用 kafka-topics 脚本,结合 --alter
参数来增加某个主题的分区数,命令如下:
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter
–topic <topic_name> --partitions <新分区数>
当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
首先,Rebalance 过程对 Consumer Group 消费过程有极大的影响。在 Rebalance
过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成。这是
Rebalance 为人诟病的一个方面。
其次,目前 Rebalance 的设计是所有 Consumer
实例共同参与,全部重新分配所有分区。其实更高效的做法是尽量减少分配方案的变动。
最后,Rebalance 实在是太慢了。
topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不支持,因为删除的分区中的消息不好处理。如果直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于
Spark、Flink
这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题,以及分区和副本的状态机切换问题都是不得不面对的。
创建topic时如何选择合适的分区数?副本数?
分区
在 Kafka
中,性能与分区数有着必然的关系,在设定分区数时一般也需要考虑性能的因素。对不同的硬件而言,其对应的性能也会不太一样。
可以使用Kafka 本身提供的用于生产者性能测试的 kafka-producer-
perf-test.sh 和用于消费者性能测试的
kafka-consumer-perf-test.sh来进行测试。
增加合适的分区数可以在一定程度上提升整体吞吐量,但超过对应的阈值之后吞吐量不升反降。如果应用对吞吐量有一定程度上的要求,则建议在投入生产环境之前对同款硬件资源做一个完备的吞吐量相关的测试,以找到合适的分区数阈值区间。
分区数的多少还会影响系统的可用性。如果分区数非常多,如果集群中的某个
broker 节点宕机,那么就会有大量���分区需要同时进行 leader
角色切换,这个切换的过程会耗费一笔可观的时间,并且在这个时间窗口内这些分区也会变得不可用。
分区数越多也会让 Kafka
的正常启动和关闭的耗时变得越长,与此同时,主题的分区数越多不仅会增加日志清理的耗时,而且在被删除时也会耗费更多的时间。
如何设置合理的分区数量
可以遵循一定的步骤来尝试确定分区数:创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)
说明:Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。Tc表示consumer的吞吐量。测试Tc通常与应用的关系更大, 因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试通常也要麻烦一些。
副本
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。
Kafka分配Replica的算法如下:
将所有Broker(假设共n个Broker)和待分配的Partition排序
将第i个Partition分配到第(imod n)个Broker上
将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
如何保证kafka的数据完整性
生产者不丢数据:
- 设置 acks=all,leader会等待所有的follower同步完成。这个确保消息不会丢失,除非kafka集群中所有机器挂掉。这是最强的可用性保证。
2.retries = max ,客户端会在消息发送失败时重新发送,直到发送成功为止。为0表示不重新发送。
消息队列不丢数据:
1.replication.factor 也就是topic的副本数,必须大于1
2.min.insync.replicas 也要大于1,要求一个leader至少感知到有至少一个follower还跟自己保持联系
消费者不丢数据:
改为手动提交。
kafka配置参数
kafka配置参数
-
broker.id:broker的id,id是唯一的非负整数,集群的broker.id不能重复。
-
log.dirs:kafka存放数据的路径。可以是多个,多个使用逗号分隔即可。
-
port:server接受客户端连接的端口,默认6667
-
zookeeper.connect:zookeeper集群连接地址。
格式如:zookeeper.connect=server01:2181,server02:2181,server03:2181。
如果需要指定zookeeper集群的路径位置,可以:zookeeper.connect=server01:2181,server02:2181,server03:2181/kafka/cluster。这样设置后,在启动kafka集群前,需要在zookeeper集群创建这个路径/kafka/cluster。 -
message.max.bytes:server可以接受的消息最大尺寸。默认1000000。
重要的是,consumer和producer有关这个属性的设置必须同步,否则producer发布的消息对consumer来说太大。 -
num.network.threads:server用来处理网络请求的线程数,默认3。
-
num.io.threads:server用来处理请求的I/O线程数。这个线程数至少等于磁盘的个数。
-
background.threads:用于后台处理的线程数。例如文件的删除。默认4。
-
queued.max.requests:在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数。默认500。
-
host.name:broker的hostname
如果hostname已经设置的话,broker将只会绑定到这个地址上;如果没有设置,它将绑定到所有接口,并发布一份到ZK -
advertised.host.name:如果设置,则就作为broker
的hostname发往producer、consumers以及其他brokers -
advertised.port:此端口将给与producers、consumers、以及其他brokers,它会在建立连接时用到;
它仅在实际端口和server需要绑定的端口不一样时才需要设置。 -
socket.send.buffer.bytes:SO_SNDBUFF 缓存大小,server进行socket
连接所用,默认100*1024。 -
socket.receive.buffer.bytes:SO_RCVBUFF缓存大小,server进行socket连接时所用。默认100
* 1024。 -
socket.request.max.bytes:server允许的最大请求尺寸;这将避免server溢出,它应该小于Java
heap size。 -
num.partitions:如果创建topic时没有给出划分partitions个数,这个数字将是topic下partitions数目的默认数值。默认1。
-
log.segment.bytes:topic
partition的日志存放在某个目录下诸多文件中,这些文件将partition的日志切分成一段一段的;这个属性就是每个文件的最大尺寸;当尺寸达到这个数值时,就会创建新文件。此设置可以由每个topic基础设置时进行覆盖。默认1014*1024*1024 -
log.roll.hours:即使文件没有到达log.segment.bytes,只要文件创建时间到达此属性,就会创建新文件。这个设置也可以有topic层面的设置进行覆盖。默认24*7
-
log.cleanup.policy:log清除策略。默认delete。
-
log.retention.minutes和log.retention.hours:每个日志文件删除之前保存的时间。默认数据保存时间对所有topic都一样。
-
log.retention.minutes 和 log.retention.bytes
都是用来设置删除日志文件的,无论哪个属性已经溢出��这个属性设置可以在topic基本设置时进行覆盖。 -
log.retention.bytes:每个topic下每个partition保存数据的总量。
注意,这是每个partitions的上限,因此这个数值乘以partitions的个数就是每个topic保存的数据总量。如果log.retention.hours和log.retention.bytes都设置了,则超过了任何一个限制都会造成删除一个段文件。注意,这项设置可以由每个topic设置时进行覆盖。 -
log.retention.check.interval.ms:检查日志分段文件的间隔时间,以确定是否文件属性是否到达删除要求。默认5min。
-
log.cleaner.enable:当这个属性设置为false时,一旦日志的保存时间或者大小达到上限时,就会被删除;如果设置为true,则当保存属性达到上限时,就会进行log
compaction。默认false。 -
log.cleaner.threads:进行日志压缩的线程数。默认1。
-
log.cleaner.io.max.bytes.per.second:进行log compaction时,log
cleaner可以拥有的最大I/O数目。这项设置限制了cleaner,以避免干扰活动的请求服务。 -
log.cleaner.io.buffer.size:log
cleaner清除过程中针对日志进行索引化以及精简化所用到的缓存大小。最好设置大点,以提供充足的内存。默认500*1024*1024。 -
log.cleaner.io.buffer.load.factor:进行log cleaning时所需要的I/O
chunk尺寸。你不需要更改这项设置。默认512*1024。 -
log.cleaner.io.buffer.load.factor:log
cleaning中所使用的hash表的负载因子;你不需要更改这个选项。默认0.9 -
log.cleaner.backoff.ms:进行日志是否清理检查的时间间隔,默认15000。
-
log.cleaner.min.cleanable.ratio:这项配置控制log
compactor试图清理日志的频率(假定log compaction是打开的)。默认避免清理压缩超过50%的日志。这个比率绑定了备份日志所消耗的最大空间(50%的日志备份时压缩率为50%)。更高的比率则意味着浪费消耗更少,也就可以更有效的清理更多的空间。这项设置在每个topic设置中可以覆盖。 -
log.cleaner.delete.retention.ms:保存时间;保存压缩日志的最长时间;也是客户端消费消息的最长时间,与log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据;会被topic创建时的指定时间覆盖。
-
log.index.size.max.bytes:每个log
segment的最大尺寸。注意,如果log尺寸达到这个数值,即使尺寸没有超过log.segment.bytes限制,也需要产生新的log
segment。默认10*1024*1024。 -
log.index.interval.bytes:当执行一次fetch后,需要一定的空间扫描最近的offset,设置的越大越好,一般使用默认值就可以。默认4096。
-
log.flush.interval.messages:log文件"sync"到磁盘之前累积的消息条数。
因为磁盘IO操作是一个慢操作,但又是一个"数据可靠性"的必要手段,所以检查是否需要固化到硬盘的时间间隔。需要在"数据可靠性"与"性能"之间做必要的权衡,如果此值过大,将会导致每次"发sync"的时间过长(IO阻塞),如果此值过小,将会导致"fsync"的时间较长(IO阻塞),导致"发sync"的次数较多,这也就意味着整体的client请求有一定的延迟,物理server故障,将会导致没有fsync的消息丢失。 -
log.flush.scheduler.interval.ms:检查是否需要fsync的时间间隔。默认Long.MaxValue
-
log.flush.interval.ms:仅仅通过interval来控制消息的磁盘写入时机,是不足的,这个数用来控制"fsync"的时间间隔,如果消息量始终没有达到固化到磁盘的消息数,但是离上次磁盘同步的时间间隔达到阈值,也将触发磁盘同步。
-
log.delete.delay.ms:文件在索引中清除后的保留时间,一般不需要修改。默认60000。
-
auto.create.topics.enable:是否允许自动创建topic。如果是true,则produce或者fetch
不存在的topic时,会自动创建这个topic。否则需要使用命令行创建topic。默认true。 -
controller.socket.timeout.ms:partition管理控制器进行备份时,socket的超时时间。默认30000。
-
controller.message.queue.size:controller-to-broker-channles的buffer尺寸,默认Int.MaxValue。
-
default.replication.factor:默认备份份数,仅指自动创建的topics。默认1。
-
replica.lag.time.max.ms:如果一个follower在这个时间内没有发送fetch请求,leader将从ISR重移除这个follower,并认为这个follower已经挂了,默认10000。
-
replica.lag.max.messages:如果一个replica没有备份的条数超过这个数值,则leader将移除这个follower,并认为这个follower已经挂了,默认4000。
-
replica.socket.timeout.ms:leader
备份数据时的socket网络请求的超时时间,默认30*1000 -
replica.socket.receive.buffer.bytes:备份时向leader发送网络请求时的socket
receive buffer。默认64*1024。 -
replica.fetch.max.bytes:备份时每次fetch的最大值。默认1024*1024。
-
replica.fetch.max.bytes:leader发出备份请求时,数据到达leader的最长等待时间。默认500。
-
replica.fetch.min.bytes:备份时每次fetch之后回应的最小尺寸。默认1。
-
num.replica.fetchers:从leader备份数据的线程数。默认1。
-
replica.high.watermark.checkpoint.interval.ms:每个replica检查是否将最高水位进行固化的频率。默认5000.
-
fetch.purgatory.purge.interval.requests:fetch
请求清除时的清除间隔,默认1000 -
producer.purgatory.purge.interval.requests:producer请求清除时的清除间隔,默认1000
-
zookeeper.session.timeout.ms:zookeeper会话超时时间。默认6000
-
zookeeper.connection.timeout.ms:客户端等待和zookeeper建立连接的最大时间。默认6000
-
zookeeper.sync.time.ms:zk follower落后于zk leader的最长时间。默认2000
-
controlled.shutdown.enable:是否能够控制broker的关闭。如果能够,broker将可以移动所有leaders到其他的broker上,在关闭之前。这减少了不可用性在关机过程中。默认true。
-
controlled.shutdown.max.retries:在执行不彻底的关机之前,可以成功执行关机的命令数。默认3.
-
controlled.shutdown.retry.backoff.ms:在关机之间的backoff时间。默认5000
-
auto.leader.rebalance.enable:如果这是true,控制者将会自动平衡brokers对于partitions的leadership。默认true。
-
leader.imbalance.per.broker.percentage:每个broker所允许的leader最大不平衡比率,默认10。
-
leader.imbalance.check.interval.seconds:检查leader不平衡的频率,默认300
-
offset.metadata.max.bytes:允许客户端保存他们offsets的最大个数。默认4096
-
max.connections.per.ip:每个ip地址上每个broker可以被连接的最大数目。默认Int.MaxValue。
-
max.connections.per.ip.overrides:每个ip或者hostname默认的连接的最大覆盖。
-
connections.max.idle.ms:空连接的超时限制,默认600000
-
log.roll.jitter.{ms,hours}:从logRollTimeMillis抽离的jitter最大数目。默认0
-
num.recovery.threads.per.data.dir:每个数据目录用来日志恢复的线程数目。默认1。
-
unclean.leader.election.enable:指明了是否能够使不在ISR中replicas设置用来作为leader。默认true
-
delete.topic.enable:能够删除topic,默认false。
-
offsets.topic.num.partitions:默认50。
由于部署后更改不受支持,因此建议使用更高的设置来进行生产(例如100-200)。 -
offsets.topic.retention.minutes:存在时间超过这个时间限制的offsets都将被标记为待删除。默认1440。
-
offsets.retention.check.interval.ms:offset管理器检查陈旧offsets的频率。默认600000。
-
offsets.topic.replication.factor:topic的offset的备份份数。建议设置更高的数字保证更高的可用性。默认3
-
offset.topic.segment.bytes:offsets topic的segment尺寸。默认104857600
-
offsets.load.buffer.size:这项设置与批量尺寸相关,当从offsets
segment中读取时使用。默认5242880 -
offsets.commit.required.acks:在offset
commit可以接受之前,需要设置确认的数目,一般不需要更改。默认-1。
kafka生产者配置参数
-
boostrap.servers:用于建立与kafka集群连接的host/port组。
数据将会在所有servers上均衡加载,不管哪些server是指定用于bootstrapping。
这个列表格式:host1:port1,host2:port2,… -
acks:此配置实际上代表了数据备份的可用性。
-
acks=0:
设置为0表示producer不需要等待任何确认收到的信息。副本将立即加到socket
buffer并认为已经发送。没有任何保障可以保证此种情况下server已经成功接收数据,同时重试配置不会发生作用 -
acks=1:
这意味着至少要等待leader已经成功将数据写入本地log,但是并没有等待所有follower是否成功写入。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。 -
acks=all:
这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。 -
buffer.memory:producer可以用来缓存数据的内存大小。如果数据产生速度大于向broker发送的速度,producer会阻塞或者抛出异常,以"block.on.buffer.full"来表明。
-
compression.type:producer用于压缩数据的压缩类型。默认是无压缩。正确的选项值是none、gzip、snappy。压缩最好用于批量处理,批量处理消息越多,压缩性能越好。
-
retries:设置大于0的值将使客户端重新发送任何数据,一旦这些数据发送失败。注意,这些重试与客户端接收到发送错误时的重试没有什么不同。允许重试将潜在的改变数据的顺序,如果这两个消息记录都是发送到同一个partition,则第一个消息失败第二个发送成功,则第二条消息会比第一条消息出现要早。
-
batch.size:producer将试图批处理消息记录,以减少请求次数。这将改善client与server之间的性能。这项配置控制默认的批量处理消息字节数。
-
client.id:当向server发出请求时,这个字符串会发送给server。目的是能够追踪请求源头,以此来允许ip/port许可列表之外的一些应用可以发送信息。这项应用可以设置任意字符串,因为没有任何功能性的目的,除了记录和跟踪。
-
linger.ms:producer组将会汇总任何在请求与发送之间到达的消息记录一个单独批量的请求。通常来说,这只有在记录产生速度大于发送速度的时候才能发生。
-
max.request.size:请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
-
receive.buffer.bytes:TCP receive缓存大小,当阅读数据时使用。
-
send.buffer.bytes:TCP send缓存大小,当发送数据时使用。
-
timeout.ms:此配置选项控制server等待来自followers的确认的最大时间。如果确认的请求数目在此时间内没有实现,则会返回一个错误。这个超时限制是以server端度量的,没有包含请求的网络延迟。
-
block.on.buffer.full:当我们内存缓存用尽时,必须停止接收新消息记录或者抛出错误。
默认情况下,这个设置为真,然而某些阻塞可能不值得期待,因此立即抛出错误更好。设置为false则会这样:producer会抛出一个异常错误:BufferExhaustedException,
如果记录已经发送同时缓存已满。 -
metadata.fetch.timeout.ms:是指我们所获取的一些元素据的第一个时间数据。元素据包含:topic,host,partitions。此项配置是指当等待元素据fetch成功完成所需要的时间,否则会抛出异常给客户端。
-
metadata.max.age.ms:以微秒为单位的时间,是在我们强制更新metadata的时间间隔。即使我们没有看到任何partition
leadership改变。 -
metric.reporters:类的列表,用于衡量指标。实现MetricReporter接口,将允许增加一些类,这些类在新的衡量指标产生时就会改变。JmxReporter总会包含用于注册JMX统计
-
metrics.num.samples:用于维护metrics的样本数。
-
metrics.sample.window.ms:metrics系统维护可配置的样本数量,在一个可修正的window
size。这项配置配置了窗口大小,例如。我们可能在30s的期间维护两个样本。当一个窗口推出后,我们会擦除并重写最老的窗口。 -
recoonect.backoff.ms:连接失败时,当我们重新连接时的等待时间。这避免了客户端反复重连。
-
retry.backoff.ms:在试图重试失败的produce请求之前的等待时间。避免陷入发送-失败的死循环中。
kafka消费者配置参数
-
group.id:用来唯一标识consumer进程所在组的字符串,如果设置同样的group
id,表示这些processes都是属于同一个consumer group。 -
zookeeper.connect:指定zookeeper的连接的字符串,格式是hostname:port,
hostname:port… -
consumer.id:不需要设置,一般自动产生
-
socket.timeout.ms:网络请求的超时限制。真实的超时限制是max.fetch.wait+socket.timeout.ms。默认3000
-
socket.receive.buffer.bytes:socket用于接收网络请求的缓存大小。默认64*1024。
-
fetch.message.max.bytes:每次fetch请求中,针对每次fetch消息的最大字节数。默认1024*1024
这些字节将会督导用于每个partition的内存中,因此,此设置将会控制consumer所使用的memory大小。
这个fetch请求尺寸必须至少和server允许的最大消息尺寸相等,否则,producer可能发送的消息尺寸大于consumer所能消耗的尺寸。 -
num.consumer.fetchers:用于fetch数据的fetcher线程数。默认1
-
auto.commit.enable:如果为真,consumer所fetch的消息的offset将会自动的同步到zookeeper。这项提交的offset将在进程挂掉时,由新的consumer使用。默认true。
-
auto.commit.interval.ms:consumer向zookeeper提交offset的频率,单位是秒。默认60*1000。
-
queued.max.message.chunks:用于缓存消息的最大数目,每个chunk必须和fetch.message.max.bytes相同。默认2。
-
rebalance.max.retries:当新的consumer加入到consumer
group时,consumers集合试图重新平衡分配到每个consumer的partitions数目。如果consumers集合改变了,当分配正在执行时,这个重新平衡会失败并重入。默认4 -
fetch.min.bytes:每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。
-
fetch.wait.max.ms:如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。默认100
-
rebalance.backoff.ms:在重试reblance之前backoff时间。默认2000
-
refresh.leader.backoff.ms:在试图确定某个partition的leader是否失去他的leader地位之前,需要等待的backoff时间。默认200
-
auto.offset.reset:zookeeper中没有初始化的offset时,如果offset是以下值的回应:
-
lastest:自动复位offset为lastest的offset
-
earliest:自动复位offset为earliest的offset
-
none:向consumer抛出异常
-
consumer.timeout.ms:如果没有消息可用,即使等待特定的时间之后也没有,则抛出超时异常
-
exclude.internal.topics:是否将内部topics的消息暴露给consumer。默认true。
-
paritition.assignment.strategy:选择向consumer
流分配partitions的策略,可选值:range,roundrobin。默认range。 -
client.id:是用户特定的字符串,用来在每次请求中帮助跟踪调用。它应该可以逻辑上确认产生这个请求的应用。
-
zookeeper.session.timeout.ms:zookeeper 会话的超时限制。默认6000
如果consumer在这段时间内没有向zookeeper发送心跳信息,则它会被认为挂掉了,并且reblance将会产生 -
zookeeper.connection.timeout.ms:客户端在建立通zookeeper连接中的最大等待时间。默认6000
-
zookeeper.sync.time.ms:ZK follower可以落后ZK leader的最大时间。默认1000
-
offsets.storage:用于存放offsets的地点:
zookeeper或者kafka。默认zookeeper。 -
offset.channel.backoff.ms:重新连接offsets
channel或者是重试失败的offset的fetch/commit请求的backoff时间。默认1000 -
offsets.channel.socket.timeout.ms:当读取offset的fetch/commit请求回应的socket
超时限制。此超时限制是被consumerMetadata请求用来请求offset管理。默认10000。 -
offsets.commit.max.retries:重试offset
commit的次数。这个重试只应用于offset commits在shut-down之间。默认5。 -
dual.commit.enabled:如果使用"kafka"作为offsets.storage,你可以二次提交offset到zookeeper(还有一次是提交到kafka)。
在zookeeper-based的offset storage到kafka-based的offset
storage迁移时,这是必须的。对任意给定的consumer
group来说,比较安全的建议是当完成迁移之后就关闭这个选项 -
partition.assignment.strategy:在"range"和"roundrobin"策略之间选择一种作为分配partitions给consumer
数据流的策略。
循环的partition分配器分配所有可用的partitions以及所有可用consumer线程。它会将partition循环的分配到consumer线程上。如果所有consumer实例的订阅都是确定的,则partitions的划分是确定的分布。
循环分配策略只有在以下条件满足时才可以:(1)每个topic在每个consumer实力上都有同样数量的数据流。(2)订阅的topic的集合对于consumer
group中每个consumer实例来说都是确定的
kafka ack容错机制(应答机制)
在Producer(生产者)向kafka集群发送消息,kafka集群会在接受完消息后,给出应答,成功或失败,如果失败,producer(生产者)会再次发送,直到成功为止。
producer(生产者)发送数据给kafka集群,kafka集群反馈有3种模式:
-
0:producer(生产者)不会等待kafka集群发送ack,producer(生产者)发送完消息就算成功。
-
1:producer(生产者)等待kafka集群的leader接受到消息后,发送ack。producer(生产者)接收到ack,表示消息发送成功。
-
-1:producer(生产者)等待kafka集群所有包含分区的follower都同步消息成功后,发送ack。producer(生产者)接受到ack,表示消息发送成功。
kafka segment
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文���中。但每个段segment
file消息数量不一定相等,这种特性方便old segment
file快速被删除。默认保留7天的数据。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。(什么时候创建,什么时候删除)
数据有序性:只有在一个partition分区内,数据才是有序的。
Segment file组成:由2大部分组成,分别为i**ndex file**和data
file,此2个文件一一对应,成对出现,后缀".index"和".log"分别表示为segment索引文件、数据文件。(在目前最新版本,又添加了另外的约束)。
Segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
segment机制的作用:
- 可以通过索引快速找到消息所在的位置。
用于超过kafka设置的默认时间,清除比较方便。
kafka从零开始使用
这里之前写过一些kafka使用的文章,这里就不在复制到此文章上面来了,以免文章内容太多太多了。
kafka安装
文章:
- Kafka安装教程
kafka的可视化软件
kafka-eagle
地址:https://github.com/smartloli/kafka-eagle
下载之后解压
需要配置环境
Windows环境
KE_HOME = D:\\kafka_eagle\\kafka-eagle-web-1.2.3
LINUX环境
export KE_HOME=/home/jars/kafka_eagle/kafka-eagle-web-1.2.3
配置mysql,执行ke.sql
脚本,然后在D:\kafka_eagle\kafka-eagle-web-1.2.0\conf
中修改system-config.properties 配置文件
zookeeper 服务的配置地址,支持多个集群,多个用逗号隔开
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=192.169.0.23:2181,192.169.0.24:2181,192.169.0.25:2181
cluster2.zk.list=192.169.2.156:2181,192.169.2.98:2181,192.169.2.188:2181
然后配置mysql服务的地址
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
配置完成之后,在切换到/bin目录下,windows双击ke.bat ,linux输入 ke.sh
start,启动程序,然后在浏览器输入ip:port/ke
进入登录界面,输入ke数据库中的ke_users设置的用户名和密码,即可查看。

kafka-manager
地址:https://github.com/yahoo/kafka-manager
下载编译
git clone https://github.com/yahoo/kafka-manager
cd kafka-manager
sbt clean distcd target/
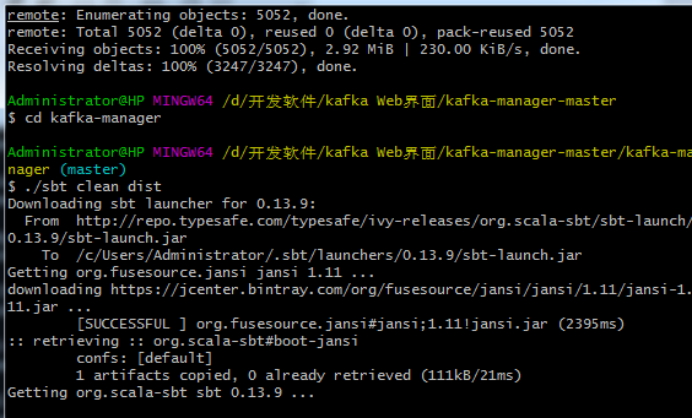
编译完成之后,解压该文件
在 conf/application.properties路径下找到 kafka-manager.zkhosts 配置,添加zookeeper的地址,如果是多个,用逗号隔开。
kafka-manager.zkhosts = master:2181,slave1:2181,slave2:2181
修改完成之后,就可以进行启动了。
kafka-manager 默认的端口是9000,我们可以通过 -Dhttp.port来指定端口。
nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8765 &
启动成功之后,在浏览器输入地址即可进行访问了。
Kafka Tool(offset Explorer)
地址:https://www.kafkatool.com/
Offset Explorer(以前称为Kafka Tool)是一个用于管理和使用Apache Kafka ®集群的GUI应用程序。它提供了一个直观的用户界面,允许人们快速查看其中的对象 一个 Kafka 集群以及存储在集群主题中的消息。它包含面向开发人员和管理员的功能。一些主要功能包括
- 快速查看所有 Kafka 集群,包括其代理、主题和使用者
- 查看分区中的消息内容并添加新消息
- 查看消费者的偏移量,包括 Apache Storm Kafka 喷口消费者
- 以漂亮的打印格式显示 JSON、XML 和 Avro 消息
- 添加和删除主题以及其他管理功能
- 将分区中的单个消息保存到本地硬盘驱动器
- 编写自己的插件,允许您查看自定义数据格式
- Offset Explorer 可在 Windows、Linux 和 Mac OS 上运行

demo代码
文章:
- Kafka 使用Java实现数据的生产和消费demo
- 关于Kafka 的 consumer 消费者手动提交详解
代码地址:
https://github.com/xuwujing/kafka-study
https://github.com/xuwujing/java-study/tree/master/src/main/java/com/pancm/mq/kafka
kafka生产环境问题排查和解决方案
这里主要是记录在使用kafka的时候遇到的一些生产环境问题和解决方案,有的可能不是问题,而是需求,有的问题解决方案按照现在来说不完美,毕竟很多时候,快速解决才是第一要素。总之这些就按照我之前的笔记记录进行分享吧,如有更好的思路或者解决办法,欢迎提出!
先介绍一些kafka的常用命令
kafka常用命令
官方文档: http://kafka.apache.org/quickstart
1.启动和关闭kafka
bin/kafka-server-start.sh config/server.properties \>\>/dev/null 2\>&1 &
bin/kafka-server-stop.sh
zookeeper启动命令:
./zookeeper-server-start.sh -daemon
…/config/zookeeper.properties
kafka启用命令:
./kafka-server-start.sh -daemon
…/config/server.properties
2.查看kafka集群中的消息队列和具体队列
查看集群所有的topic
kafka-topics.sh \--zookeeper master:2181,slave1:2181,slave2:2181 \--list
查看一个topic的信息
kafka-topics.sh \--zookeeper master:2181 \--describe \--topic
1004_INSERT
查看kafka consumer消费的offset
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker \--zookeeper
master:2181 \--group groupB \--topic KAFKA_TEST
在kafka中查询数据
./kafka-console-consumer.sh \--zookeeper 172.16.253.91:2181 \--topic
MO_RVOK \--from-beginning \| grep -c \'13339309600\'
3.创建Topic
partitions指定topic分区数,replication-factor指定topic每个分区的副本数
kafka-topics.sh \--zookeeper master:2181 \--create \--topic t_test
\--partitions 30 \--replication-factor 1
4.生产数据和消费数据
kafka-console-producer.sh \--broker-list master:9092 \--topic t_test
Ctrl+D 退出
kafka-console-consumer.sh \--zookeeper master:2181 \--topic t_test
\--from-beginning
kafka-console-consumer.sh \--bootstrap-server localhost:9092 \--topic
t_test \--from-beginning
–from-beginning 是表示从头开始消费
Ctrl+C 退出
5.kafka的删除命令
1.kafka命令删除
kafka-topics.sh \--delete \--zookeeper
master:2181,slave1:2181,slave2:2181 \--topic test
注:如果出现 This will have no impact if delete.topic.enable is not set
to true. 表示没有彻底的删除,而是把topic标记为:marked for deletion
。可以在server.properties中配置delete.topic.enable=true 来删除。
2.进入zk删除
zkCli.sh -server master:2181,slave1:2181,slave2:2181
找到topic所在的目录:ls /brokers/topics
找到要删除的topic,执行命令:rmr /brokers/topics/【topic
name】即可,此时topic被彻底删除。
进入/admin/delete_topics目录下,找到删除的topic,删除对应的信息。
6.添加分区
kafka-topics.sh \--alter \--topic INSERT_TEST1 \--zookeeper master:2181
\--partitions 15
7.查看消费组
查看所有
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--list
查看某一个消费组
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--describe
\--group groupT
8.查看offset的值
最小值:
kafka-run-class.sh kafka.tools.GetOffsetShell \--broker-list master:9092
-topic KAFKA_TEST \--time -2
最大值:
kafka-run-class.sh kafka.tools.GetOffsetShell \--broker-list master:9092
-topic KAFKA_TEST \--time -1
9,查看kafka日志文件中某一个topic占用的空间
du -lh --max-depth=1 TEST*
遇到的问题
offset下标丢失问题
kafka版本:V1.0
因为某种原因,kafka集群中的topic数据有一段时间(一天左右)没有被消费,再次消费的时候,所有的消费程序读取的offset是从头开始消费,产生了大量重复数据。
问题原因:offset的过期时间惹的祸,offsets.retention.minutes这个过期时间在kafka低版本的默认配置时间是1天,如果超过1天没有消费,那么offset就会过期清理,因此导致数据重复消费。在2.0之后的版本这个默认值就设置为了7天。
解决办法:
临时解决办法,根据程序最近打印的日志内容,找到最后消费的offset值,然后批量更改kafka集群的offset。
kafka 的offset偏移量更改
首先通过下面的命令查看当前消费组的消费情况:
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--group groupA
\--describe
current-offset 和 log-end-offset还有 lag
,分别为当前偏移量,结束的偏移量,落后的偏移量。
然后进行offset更改
这是一个示例,offset(所有分区)更改为100之后
kafka-consumer-groups.sh \--bootstrap-server master:9092 \--group groupA
\--topic KAFKA_TEST2 \--execute \--reset-offsets \--to-offset 100
–group 代表你的消费者分组
–topic 代表你消费的主题
–execute 代表支持复位偏移
–reset-offsets 代表要进行偏移操作
–to-offset 代表你要偏移到哪个位置,是long类型数值,只能比前面查询出来的小
还一种临时方案,就是更改代码,指定kafka的分区和offset,从指定点开始消费!对应的代码示例也在上述贴出的github链接中。
最终解决办法:将offset的过期时间值(offsets.retention.minutes)设置调大。
Kafka增加节点数据重新分配
背景:为了缓解之前kafka集群服务的压力,需要新增kafka节点,并且对数据进行重新分配。
解决方案:利用kafka自身的分区重新分配原理进行数据重新分配。需要提前将新增的kafka节点添加到zookeeper集群中,可以在zookeeper里面通过ls /brokers/ids 查看节点名称。
1,创建文件
创建一个topics-to-move.json的文件,文件中编辑如下参数,多个topic用逗号隔开。
{\"topics\": \[{\"topic\": \"t1\"},{\"topic\": \"t2\"}\],\"version\":1}
命令示例:
touch topics-to-move.json
vim topics-to-move.json
2,获取建议数据迁移文本
在${kakfa}/bin 目录下输入如下命令,文件和命令可以放在同一级。
命令示例:
./kafka-reassign-partitions.sh \--zookeeper 192.168.124.111:2181
\--topics-to-move-json-file topics-to-move.json \--broker-list
\"111,112,113,114\" \--generate
broker-list
后面的数字就是kafka每个节点的名称,需要填写kafka所有集群的节点名称。
执行完毕之后,复制Proposed partition reassignment configuration
下的文本到一个新的json文件中,命名为reality.json。
3,执行重新分配任务
执行如下命令即可。
./kafka-reassign-partitions.sh \--zookeeper 192.168.124.111:2181
\--reassignment-json-file reality.json \--execute
出现successfully表示执行成功完毕
查看执行的任务进度,输入以下命令即可:
kafka-reassign-partitions.sh \--zookeeper ip:host,ip:host,ip:host
\--reassignment-json-file reality.json \--verify
kafka集群同步
背景:因机房问题,需要将kafka集群进行迁移,并且保证数据同步。
解决方案:使用MirrorMaker进行同步。
1.介绍
MirrorMaker是为解决Kafka跨集群同步、创建镜像集群而存在的。下图展示了其工作原理。该工具消费源集群消息然后将数据又一次推送到目标集群。
2.使用
这里分为两个kafka集群,名称为源kafka集群和目标kafka集群,我们是要把源kafka集群的数据同步到目标kafka集群中,可以指定全部的topic或部分的topic进行同步。
其中同步的topic的名称须一致,需提前创建好,分区数和副本可以不一致!
主要參数说明:
1\. --consumer.config:消费端相关配置文件
2\. --producer.config:生产端相关配置文件
3\. --num.streams: consumer的线程数 默认1
4\. --num.producers: producer的线程数 默认1
5\. --blacklist: 不需要同步topic的黑名单,支持Java正则表达式
6.--whitelist:需要同步topic的白名单,符合java正則表達式形式
7\. -queue.size:consumer和producer之间缓存的queue size,默认10000
在源kafka集群创建consumer.config和producer.config文件,然后配置如下信息:
consumer.config配置
bootstrap.servers=192.169.2.144:9092
group.id=MW-MirrorMaker
auto.commit.enable=true
auto.commit.interval.ms=1000
fetch.min.bytes=6553600
auto.offset.reset = earliest
max.poll.records = 1000
producer.config配置
bootstrap.servers=192.169.2.249:9092
retries = 3
acks = all
batch.size = 16384
producer.type=sync
batch.num.messages=1000
其中 consumer.config的
bootstrap.servers是源kafka集群的地址,producer.config是目标kafka的地址,可以填写多个,用逗号隔开!
同步启动命令示例:
nohup ../bin/kafka-mirror-maker.sh \--consumer.config consumer.config
\--num.streams 10 \--producer.config producer.config ---num.producers 10
\--whitelist \"MT_RVOK_TEST9\" \>/dev/null 2\>&1 &
可以使用jps在进程中查询得到,查看具体同步信息可以查看kafka消费组的offset得到。

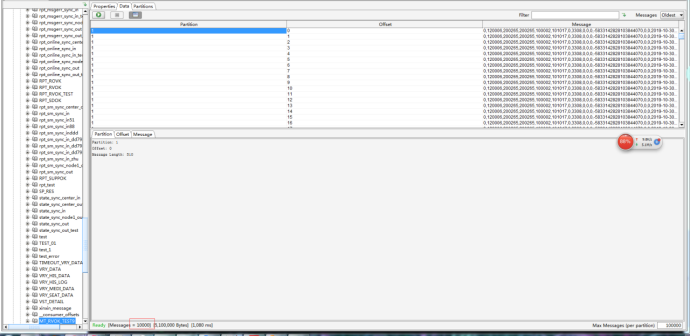
3.测试
用程序往 MT_RVOK_TEST9
先往源kafka(192.169.2.144:9092)发送10000条数��,然后启动同步命令,查看目标kafka集群(192.169.2.249:9092),同步成功!


内外网kafka穿透(网闸)
背景:因为传输原因,需要kafka能够在内外网传输,通过网闸。
解决方案:
1.网闸kafka内外网传输必要条件
1.网闸内外网可用,且网闸开放的端口和kakfa开放的端口必须一致,比如kafka默认是9092,那么网闸开放的端口也是9092;
2.网闸开放端口,必须双向数据同步,不能只单向传输,网闸和外网以及kakfa内网之间互信;
3.kafka配置需要添加额外配置参数,server.properties核心配置如下:
listeners=PLAINTEXT://kafka-cluster:9092
advertised.listeners=PLAINTEXT://kafka-cluster:9092
1.kafka服务、内网访问服务、外网访问服务,均需设置ip和域名映射。linux在/etc/hosts文件中,添加ip和域名映射关系,内网访问,则ip为kafka内网的ip,外网访问则ip为网闸的ip;
内网访问kafka的文件配置示例:
192.168.0.1 kafka-cluster
外网Windows的host文件配置示例:
100.100.100.100 kafka-cluster
2.测试步骤
1.依次启动zookeeper和kafka服务,可以使用jps命令查看是否启动;
1.使用如下命令在kakfa的bin目录下进行生产和消费测试:
生产命令
./kafka-console-producer.sh --broker-list 192.168.0.1:9092 --topic test_3
消费命令:
./kafka-console-consumer.sh --bootstrap-server 192.168.0.1:9092 --topic test_3
示例:
在生产的客户端随意数据数据,查看消费端是否有数据消费


1.在外网使用kafka消费程序进行测试
数据消费成功示例:
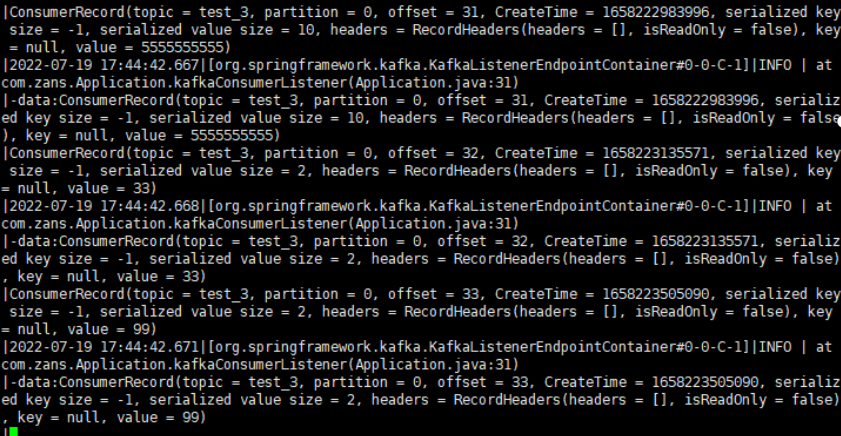
其他问题
kafka数据丢失:
一般来说分为发送消息丢失和消费丢失,区别方式可以用kafka命令进行消费判断,如果是发送消息丢失,那么一般是配置或网络问题;如果是消费消息丢失,多半是自动提交或无事务;找到数据源头解决就行,配置文件更改配置,可参考上面我发出的配置,自动提交改成手动提交,入库失败不提交。
kafka重复消费:
要么是重复发送,要么是消费之后未提交且进行过重启,要么是更换了消费组(group),还有就是offset重置了这种。可根据原因对症下药解决即可,解决办法可参考本文上述示例。
kafka消息积压(堵塞):
生产的消息速度远远大于消费的速度,导致消息积压。
常见情况一、分区设置不合理,分区个数太少,比如默认分区5个,导致消费线程最多只有5个,可选办法有增加分区,然后在增加消费线程;
常见情况二、消费端处理过于耗时,拿到消息之后,迟迟未提交,导致消费速率太慢,可选办法有将耗时处理方法抽出,比如在进行一次异步处理,确保拿到kafka消息到入库这块效率;
常见情况三、IO问题或kafka集群问题,宽带升级或集群扩容。
不常见问题、配置设置问题,一般而言,kafka的配置除了必要的配置,大部分配置是不用更改,若数据量实在太大,需要调优,则可根据官方提供的配置进行调试。
其他
本以为写这种类型文章不太耗时,没想到一看又是凌晨了,整理笔记、文字排版还是真的有点费时,后续在更新一下linux的就结束这个系列吧。至于其他的各种知识有空的就在其他的篇章系列继续更新吧~
手记系列
记载个人从刚开始工作到现在各种杂谈笔记、问题汇总、经验累积的系列。
手记系列
- 手记系列之一 ----- 关于微信公众号和小程序的开发流程
- 手记系列之二 ----- 关于IDEA的一些使用方法经验
- 手记系列之三 ----- 关于使用Nginx的一些使用方法和经验
- 手记系列之四 ----- 关于使用MySql的经验
- 手记系列之五 ----- SQL使用经验分享
一首很带感的动漫钢琴曲~
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:https://xuwujing.github.io/