什么是大数据
大数据是指数据量巨大、类型繁多、处理速度快的数据集合。它不仅包括传统的结构化数据,还包括非结构化数据、半结构化数据等多种形式的数据。大数据的处理需要使用特殊的技术和工具,如分布式存储、分布式计算、数据挖掘、机器学习等。
大数据的特性
大数据具有以下特性:
- Volume(数据量大):大数据的数据量通常以TB、PB、EB等计量单位来衡量。
- Velocity(数据处理速度快):大数据的处理速度通常要求在实时或准实时的情况下进行。
- Variety(数据类型多样):大数据包括结构化数据、半结构化数据和非结构化数据等多种类型的数据。
- Veracity(数据真实性):大数据的数据源通常来自于多个不同的数据源,因此需要保证数据的真实性和准确性。
- Value(数据价值):大数据的价值在于通过对数据的分析和挖掘,发现其中的价值和意义。
大数据的应用
大数据的应用非常广泛,包括但不限于以下领域:
- 金融行业:风险管理、欺诈检测、信用评估等。
- 医疗行业:疾病诊断、药物研发、医疗资源管理等。
- 零售行业:市场营销、商品推荐、库存管理等。
- 物流行业:路线规划、运输调度、货物跟踪等。
- 政府行业:公共安全、城市管理、社会保障等。
MapReduce
MapReduce是一种分布式计算模型,由Google公司提出。它将大数据分成多个小数据块,分配到多个计算节点上进行并行计算,最后将结果合并起来。MapReduce的核心思想是将计算过程分成两个阶段:Map阶段和Reduce阶段。Map阶段将输入数据映射成键值对,Reduce阶段将相同键的值进行合并和计算。
MapReduce的优点是稳定、可靠、易于扩展,适用于大规模数据处理。但是,MapReduce的缺点是计算速度较慢,因为它需要将数据写入磁盘,再进行读取和计算。
Spark
Spark是一种基于内存的分布式计算框架,由Apache软件基金会开发。它将数据存储在内存中,通过RDD(弹性分布式数据集)进行并行计算。Spark的核心思想是将计算过程分成多个阶段,每个阶段都可以在内存中进行计算,从而提高计算速度。
Spark的优点是计算速度快、易于使用、支持多种编程语言。但是,Spark的缺点是对内存的要求较高,不适用于大规模数据处理。
MapReduce与Spark的区别
MapReduce和Spark都是大数据处理框架,但它们有以下区别:
-
数据处理方式:MapReduce是基于磁盘的批处理模型,而Spark是基于内存的迭代计算模型。因此,Spark比MapReduce更适合处理迭代算法和交互式查询。
-
处理速度:由于Spark是基于内存的,因此它比MapReduce更快。Spark可以在内存中缓存数据,减少磁盘I/O,从而提高处理速度。
-
编程模型:MapReduce使用Java编程语言,而Spark支持多种编程语言,包括Java、Scala和Python。Spark还提供了更简单的API,使得编写和调试代码更容易。
-
数据处理能力:Spark比MapReduce更灵活,可以处理更多类型的数据,包括图形数据和流数据。
-
集成能力:Spark可以与其他大数据技术(如Hadoop、Hive和Pig)集成,而MapReduce只能与Hadoop集成。
总的来说,Spark比MapReduce更快、更灵活、更易于编程和集成。但是,MapReduce仍然是一种可靠的大数据处理框架,特别适合处理大规模的批处理任务。
Spark的产生背景(了解)
在大数据时代,数据量的爆炸式增长给数据处理和分析带来了巨大的挑战。传统的数据处理方式已经无法满足大数据时代的需求,因此需要一种新的数据处理框架来应对这一挑战。
Spark的产生背景就是在这样的背景下。Spark最初是由加州大学伯克利分校AMPLab实验室开发的,旨在解决Hadoop MapReduce的一些缺陷,如低效的数据处理和缺乏实时数据处理能力等。
Spark采用了内存计算技术,将数据存储在内存中,大大提高了数据处理速度。同时,Spark还提供了丰富的API和工具,使得开发人员可以更加方便地进行数据处理和分析。
Spark的产生背景可以总结为以下几点:
- 大数据时代的到来,传统的数据处理方式已经无法满足需求。
- Hadoop MapReduce存在一些缺陷,如低效的数据处理和缺乏实时数据处理能力等。
- Spark采用了内存计算技术,大大提高了数据处理速度。
- Spark提供了丰富的API和工具,使得开发人员可以更加方便地进行数据处理和分析。
Spark的优点
-
高速处理:Spark的内存计算引擎可以在内存中进行数据处理,相比于传统的磁盘计算,速度更快。
-
易于使用:Spark提供了易于使用的API,包括Java、Scala、Python和R等语言,使得开发人员可以轻松地进行数据处理和分析。
-
大数据处理:Spark可以处理大规模数据,支持分布式计算,可以在多个节点上同时进行计算,提高了数据处理的效率。
-
多种数据源支持:Spark支持多种数据源,包括Hadoop、Hive、Cassandra、HBase等,可以方便地进行数据处理和分析。
-
实时处理:Spark支持实时数据处理,可以在数据到达时立即进行处理和分析,适用于需要实时响应的应用场景。
-
机器学习支持:Spark提供了机器学习库MLlib,可以进行机器学习和数据挖掘等任务。
-
可扩展性:Spark可以在集群中添加更多的节点,以支持更大规模的数据处理和分析。
Spark的应用场景
-
批处理(Batch Processing):批处理是一种数据处理方式,将一批数据作为一个整体进行处理,通常是离线处理,数据量较大,处理时间较长,适合于数据分析、数据挖掘等需要全量数据处理的场景。
-
交互式查询(Interactive Query):交互式查询是一种实时查询方式,用户可以通过输入查询语句,实时获取查询结果,通常是在线处理,数据量较小,处理时间较短,适合于需要实时查询的场景。
-
流数据处理(Stream Processing):流数据处理是一种实时数据处理方式,将数据流作为一个整体进行处理,通常是在线处理,数据量较小,处理时间较短,适合于需要实时处理数据流的场景。
Spark生态系统(了解)
Spark生态系统是由Spark核心框架和一系列周边组件构成的,包括:
-
Spark SQL:用于处理结构化数据的模块,支持SQL查询和DataFrame API。
-
Spark Streaming:用于处理实时数据流的模块,支持高吞吐量和低延迟的数据处理。
-
MLlib:用于机器学习的库,提供了常见的机器学习算法和工具。
-
GraphX:用于图计算的库,支持图形算法和分布式图形处理。
-
SparkR:用于R语言的接口,支持R语言的数据分析和机器学习。
-
PySpark:用于Python语言的接口,支持Python语言的数据分析和机器学习。
-
Spark Packages:提供了丰富的第三方库和工具,可以扩展Spark的功能。
Spark生态系统的优点是可以灵活地选择和组合不同的组件,根据不同的需求构建适合自己的数据处理系统。同时,Spark生态系统的组件都是基于Spark核心框架构建的,具有高性能和可扩展性。
Spark运行机制
基本概念
Spark有以下基本概念:
- Resilient Distributed Datasets (RDDs):弹性分布式数据集,是Spark中最基本的数据抽象,是一个不可变的分布式对象集合。
- Transformations:转换操作,指对RDD进行的一系列操作,返回一个新的RDD。
- Actions:动作操作,指对RDD进行的一系列操作,返回一个结果或将数据存储到外部系统中。
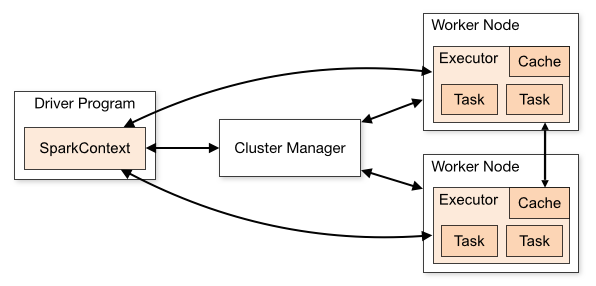
- SparkContext:Spark的主要入口,用于创建RDD、累加器和广播变量等。
- Driver Program:驱动程序,是Spark应用程序的主要入口,负责创建SparkContext、定义RDD、执行转换和动作操作等。
- Cluster Manager:集群管理器,用于管理Spark应用程序在集群中的运行,如Standalone、YARN、Mesos等。
- Executors:执行器,是运行在集群节点上的进程,负责执行Spark应用程序中的任务。
- Task:任务,是Spark应用程序中最小的执行单元,由Driver Program分配给Executors执行。
- Shuffle:洗牌操作,指在RDD之间进行数据重分区的操作,是Spark中性能瓶颈之一。
- DAG:有向无环图,是Spark中用于表示RDD之间依赖关系的数据结构
Spark执行流程
Spark的运行架构包括以下几个组件:
-
Driver:驱动器程序,负责协调Spark应用程序的执行。它包含用户程序的main函数,并创建SparkContext,然后通过SparkContext来创建RDD、累加器和广播变量等。
-
Cluster Manager:集群管理器,负责管理集群资源,如启动和停止Executor进程、监控Executor进程的运行状态等。常见的集群管理器有Standalone、YARN和Mesos。
-
Executor:执行器进程,负责在集群中运行Spark任务。每个Executor进程都会启动一个JVM,并且可以运行多个任务。Executor进程通过SparkContext连接到Driver程序,并接收Driver程序发送的任务,然后执行这些任务。
-
Task:任务,是Spark应用程序的最小执行单元。每个任务都会在一个Executor进程中运行,并处理一个RDD分区中的数据。任务执行完成后,会将结果返回给Driver程序或者其他任务。
-
RDD:弹性分布式数据集,是Spark中最基本的数据抽象。RDD是不可变的、分区的、可并行计算的数据集合,可以从外部数据源创建,也可以通过转换操作从其他RDD派生而来。
-
DAGScheduler:DAG调度器,负责将Spark应用程序中的任务转换成DAG(有向无环图),并根据DAG中任务之间的依赖关系来调度任务的执行。
-
TaskScheduler:任务调度器,负责将DAGScheduler生成的任务调度到Executor进程中执行。常见的任务调度器有FIFO、Fair和Spark自带的动态资源分配调度器。
Spark应用执行流程
Spark应用执行的基本流程如下:
-
创建SparkContext:Spark应用程序首先需要创建一个SparkContext对象,它是Spark应用程序与Spark集群交互的入口点。
-
加载数据:Spark应用程序需要从外部数据源中加载数据,可以从HDFS、本地文件系统、Hive、Cassandra等数据源中加载数据。
-
转换数据:Spark应用程序需要对数据进行转换,可以使用Spark提供的各种转换操作,如map、filter、reduce等。
-
缓存数据:Spark应用程序可以将经常使用的数据缓存到内存中,以提高查询速度。
-
执行操作:Spark应用程序需要执行各种操作,如聚合、排序、分组等。
-
输出结果:Spark应用程序需要将结果输出到外部数据源,可以输出到HDFS、本地文件系统、Hive、Cassandra等数据源中。
-
关闭SparkContext:Spark应用程序执行完毕后需要关闭SparkContext对象,释放资源。
总的来说,Spark应用程序的执行流程可以概括为:加载数据、转换数据、缓存数据、执行操作、输出结果。
Scala基本数据类型
在Scala中,可以使用关键字val和var来声明常量和变量。
val用于声明不可变的常量,一旦赋值后就不能再改变它的值。例如:
val x = 10
var用于声明可变的变量,可以随时改变它的值。例如:
var y = 5
y = 7
在Scala中,推荐使用val来声明常量,因为它可以避免意外的修改。如果需要修改变量的值,可以使用var
Scala有以下基本数据类型:
- 整型:Byte、Short、Int、Long
- 浮点型:Float、Double
- 字符型:Char
- 布尔型:Boolean
- 字符串型:String
以下是使用这些基本数据类型的示例:
- 整型:
val a: Byte = 10
val b: Short = 100
val c: Int = 1000
val d: Long = 10000000000L
- 浮点型:
val e: Float = 3.14f
val f: Double = 3.1415926
- 字符型:
val g: Char = 'A'
- 布尔型:
val h: Boolean = true
val i: Boolean = false
- 字符串型:
val j: String = "Hello, world!"
在Scala中,冒号(:)通常用于类型注解,用于指定变量、函数参数、函数返回值等的类型。例如:
val x: Int = 10 // 定义一个整型变量x,初始值为10
def add(a: Int, b: Int): Int = a + b // 定义一个函数add,参数a和b都是整型,返回值也是整型
此外,在模式匹配中,冒号也可以用于指定类型。例如:
val list = List(1, "hello", true)
list.foreach {
case i: Int => println("整型:" + i)
case s: String => println("字符串:" + s)
case b: Boolean => println("布尔型:" + b)
}
以上代码会遍历列表list中的每个元素,如果是整型则输出"整型:x",如果是字符串则输出"字符串:x",如果是布尔型则输出"布尔型:x"
Scala基本运算符
Scala中的运算符包括算术运算符、比较运算符、逻辑运算符、位运算符、赋值运算符等。
- 算术运算符
算术运算符用于执行基本的数学运算,包括加、减、乘、除、取模等。
示例代码:
val a = 10
val b = 20
val c = a + b
val d = a - b
val e = a * b
val f = b / a
val g = b % a
- 比较运算符
比较运算符用于比较两个值的大小关系,包括等于、不等于、大于、小于、大于等于、小于等于等。
示例代码:
val a = 10
val b = 20
val c = a == b
val d = a != b
val e = a > b
val f = a < b
val g = a >= b
val h = a <= b
- 逻辑运算符
逻辑运算符用于执行逻辑运算,包括与、或、非等。
示例代码:
val a = true
val b = false
val c = a && b
val d = a || b
val e = !a
- 位运算符
位运算符用于执行位运算,包括按位与、按位或、按位异或、按位取反等。
示例代码:
val a = 60
val b = 13
val c = a & b
val d = a | b
val e = a ^ b
val f = ~a
- 赋值运算符
赋值运算符用于将一个值赋给变量或常量。
示例代码:
var a = 10
val b = 20
a += b
a -= b
a *= b
a /= b
a %= b
Scala的控制结构
示例代码:
val x = 10
if (x > 5) {
println("x is greater than 5")
} else {
println("x is less than or equal to 5")
}
运行结果:
x is greater than 5
示例代码:
val nums = List(1, 2, 3, 4, 5)
for (num <- nums) {
println(num)
}
运行结果:
1
2
3
4
5
在Scala中,<-符号通常用于for循环中的生成器表达式中,用于从集合中提取元素并将其绑定到变量上。它也可以用于模式匹配中,用于从一个集合中提取元素并将其与模式进行匹配。例如:
示例代码:
val list = List(1, 2, 3, 4, 5)
// for循环中使用<-符号
for (i <- list) {
println(i)
}
// 模式匹配中使用<-符号
val (a, b) = (1, 2)
val List(x, y) = List(3, 4)
println(a, b, x, y)
运行结果:
1
2
3
4
5
(1,2,3,4)
- while循环
示例代码:
var i = 0
while (i < 5) {
println(i)
i += 1
}
运行结果:
0
1
2
3
4
- match语句
示例代码:
val x = 2
val result = x match {
case 1 => "one"
case 2 => "two"
case _ => "other"
}
println(result)
运行结果:
two
Scala数组
Scala数组是一种可变的数据结构,它可以存储相同类型的元素。Scala数组的长度是固定的,一旦创建就不能改变。Scala数组的下标从0开始。
创建Scala数组的方式有两种:使用Array()方法和使用ArrayBuffer()方法。
使用Array()方法创建Scala数组:
val arr = Array(1, 2, 3, 4, 5)
使用ArrayBuffer()方法创建Scala数组:
import scala.collection.mutable.ArrayBuffer
val arr = ArrayBuffer(1, 2, 3, 4, 5)
Scala数组的常用方法:
- length:返回数组的长度。
val arr = Array(1, 2, 3, 4, 5)
println(arr.length) // 5
- apply(index: Int):返回数组中指定下标的元素。
val arr = Array(1, 2, 3, 4, 5)
println(arr(2)) // 3
- update(index: Int, value: T):将数组中指定下标的元素替换为指定的值。
val arr = Array(1, 2, 3, 4, 5)
arr(2) = 6
println(arr.mkString(",")) // 1,2,6,4,5
- foreach:对数组中的每个元素执行指定的操作。
val arr = Array(1, 2, 3, 4, 5)
arr.foreach(x => println(x * 2)) // 2 4 6 8 10
- map:对数组中的每个元素执行指定的操作,并返回一个新的数组。
val arr = Array(1, 2, 3, 4, 5)
val newArr = arr.map(x => x * 2)
println(newArr.mkString(",")) // 2,4,6,8,10
- filter:返回一个新的数组,其中包含满足指定条件的元素。
val arr = Array(1, 2, 3, 4, 5)
val newArr = arr.filter(x => x % 2 == 0)
println(newArr.mkString(",")) // 2,4
- reduceLeft:对数组中的元素进行累加操作。
val arr = Array(1, 2, 3, 4, 5)
val sum = arr.reduceLeft((x, y) => x + y)
println(sum) // 15
- sort:对数组中的元素进行排序。
val arr = Array(5, 3, 1, 4, 2)
arr.sort
println(arr.mkString(",")) // 1,2,3,4,5
示例代码:
import scala.collection.mutable.ArrayBuffer
object ArrayDemo {
def main(args: Array[String]): Unit = {
// 使用Array()方法创建Scala数组
val arr1 = Array(1, 2, 3, 4, 5)
println(arr1.length) // 5
println(arr1(2)) // 3
arr1(2) = 6
println(arr1.mkString(",")) // 1,2,6,4,5
arr1.foreach(x => println(x * 2)) // 2 4 12 8 10
val newArr1 = arr1.map(x => x * 2)
println(newArr1.mkString(",")) // 2,4,12,8,10
val newArr2 = arr1.filter(x => x % 2 == 0)
println(newArr2.mkString(",")) // 2,6,4
val sum = arr1.reduceLeft((x, y) => x + y)
println(sum) // 18
arr1.sort
println(arr1.mkString(",")) // 1,2,4,6,10
// 使用ArrayBuffer()方法创建Scala数组
val arr2 = ArrayBuffer(1, 2, 3, 4, 5)
println(arr2.length) // 5
println(arr2(2)) // 3
arr2(2) = 6
println(arr2.mkString(",")) // 1,2,6,4,5
arr2.foreach(x => println(x * 2)) // 2 4 12 8 10
val newArr3 = arr2.map(x => x * 2)
println(newArr3.mkString(",")) // 2,4,12,8,10
val newArr4 = arr2.filter(x => x % 2 == 0)
println(newArr4.mkString(",")) // 2,6,4
val sum2 = arr2.reduceLeft((x, y) => x + y)
println(sum2) // 18
arr2.sort
println(arr2.mkString(",")) // 1,2,4,6,10
}
}
Scala元组常用操作
- 创建元组
可以使用圆括号将多个值括起来,从而创建一个元组。
val tuple = (1, "hello", true)
- 访问元组中的元素
可以使用.符号加上元素的索引来访问元组中的元素,索引从1开始。
val tuple = (1, "hello", true)
val first = tuple._1 // 1
val second = tuple._2 // "hello"
val third = tuple._3 // true
- 解构元组
可以使用模式匹配的方式解构元组,将元组中的元素分别赋值给变量。
val tuple = (1, "hello", true)
val (a, b, c) = tuple
println(a) // 1
println(b) // "hello"
println(c) // true
- 拉链操作
可以使用zip方法将两个元组合并成一个新的元组。
val tuple1 = (1, 2, 3)
val tuple2 = ("a", "b", "c")
val zipped = tuple1.zip(tuple2) // ((1, "a"), (2, "b"), (3, "c"))
- 遍历元组
可以使用productIterator方法遍历元组中的所有元素。
val tuple = (1, "hello", true)
tuple.productIterator.foreach(println)
// 1
// "hello"
// true
- 元组转换为列表
可以使用productIterator.toList方法将元组转换为列表。
val tuple = (1, "hello", true)
val list = tuple.productIterator.toList // List(1, "hello", true)
Scala函数
Scala是一门函数式编程语言,因此函数在Scala中扮演着非常重要的角色。Scala中的函数可以像其他变量一样被定义、传递和调用。本文将详细介绍Scala函数的定义、调用、参数、返回值、高阶函数等内容,并给出相应的代码示例。
函数的定义
Scala中的函数定义格式如下:
def functionName ([参数列表]) : [返回类型] = {
// 函数体
return [返回值]
}
其中,def是定义函数的关键字,functionName是函数名,参数列表是函数的参数,返回类型是函数返回值的类型,函数体是函数的具体实现,返回值是函数的返回值。
例如,下面是一个简单的Scala函数,用于计算两个整数的和:
def add(x: Int, y: Int): Int = {
return x + y
}
函数的调用
Scala中的函数调用非常简单,只需要使用函数名和参数列表即可。例如,调用上面定义的add函数可以这样写:
val result = add(1, 2)
println(result) // 输出3
函数的参数
Scala中的函数参数可以分为两种类型:值参数和引用参数。值参数在函数调用时会被复制一份,而引用参数则会直接传递引用。
值参数
值参数的定义格式为参数名: 参数类型。例如,下面是一个使用值参数的函数:
def printName(name: String): Unit = {
println("Hello, " + name)
}
引用参数
引用参数的定义格式为参数名: 参数类型,其中参数类型前加上=>表示该参数是一个函数类型。例如,下面是一个使用引用参数的函数:
def operate(x: Int, y: Int, f: (Int, Int) => Int): Int = {
return f(x, y)
}
val result = operate(1, 2, (x, y) => x + y)
println(result) // 输出3
函数的返回值
Scala中的函数返回值可以是任意类型,包括基本类型、对象类型、函数类型等。如果函数没有返回值,可以使用Unit类型表示。
下面是一个返回字符串的函数:
def getName(): String = {
return "Scala"
}
在Scala中,Unit是一个特殊的类型,表示一个没有返回值的函数或表达式。类似于Java中的void类型,但是在Scala中,Unit是一个真正的类型,而不是一个关键字。
当一个函数没有返回值时,可以将其返回类型声明为Unit。例如:
def printMessage(message: String): Unit = {
println(message)
}
在这个例子中,printMessage函数没有返回值,因此返回类型为Unit。如果函数有返回值,可以将其返回类型声明为其他类型,如Int、String等。
另外,Unit也可以作为一个函数的返回值类型,表示该函数没有返回值。例如:
def doSomething(): Unit = {
// do something
}
在这个例子中,doSomething函数没有返回值,因此返回类型为Unit。
高阶函数
Scala中的函数可以作为参数传递给其他函数,也可以作为返回值返回。这种函数作为参数或返回值的函数称为高阶函数。
例如,下面是一个使用高阶函数的例子,用于对一个整数列表进行过滤:
def filterList(list: List[Int], f: Int => Boolean): List[Int] = {
return list.filter(f)
}
val list = List(1, 2, 3, 4, 5)
val result = filterList(list, x => x % 2 == 0)
println(result) // 输出List(2, 4)
在上面的例子中,filterList函数接受一个整数列表和一个函数作为参数,函数f用于判断一个整数是否符合条件。函数filterList返回一个新的整数列表,其中只包含符合条件的整数。
总结
本文介绍了Scala函数的定义、调用、参数、返回值、高阶函数等内容,并给出了相应的代码示例。Scala函数是Scala编程中非常重要的一部分,掌握好函数的使用可以让我们更加高效地编写Scala程序。
Scala类
Scala是一门面向对象的编程语言,因此类是Scala中最基本的概念之一。类是一种数据类型,它定义了一组属性和方法,用于描述一类对象的行为和状态。在Scala中,类可以包含构造函数、成员变量、方法、嵌套类和嵌套对象等。
下面是一个简单的Scala类的示例:
class Person(name: String, age: Int) {
def getName(): String = name
def getAge(): Int = age
def sayHello(): Unit = println(s"Hello, my name is $name")
}
在上面的示例中,我们定义了一个名为Person的类,它有两个参数:name和age。我们还定义了三个方法:getName、getAge和sayHello。getName和getAge方法用于获取对象的属性值,而sayHello方法用于打印一条问候语。
在Scala中,类可以被实例化为对象。我们可以使用new关键字来创建一个Person对象:
val person = new Person("Tom", 25)
在上面的示例中,我们创建了一个名为person的Person对象,它的name属性为"Tom",age属性为25。我们可以调用对象的方法来获取属性值或执行操作:
println(person.getName()) // 输出 "Tom"
println(person.getAge()) // 输出 25
person.sayHello() // 输出 "Hello, my name is Tom"
除了上面的示例,Scala中的类还支持许多其他特性,例如:
- 继承:Scala中的类可以继承其他类或特质(类似于Java中的接口)。
- 访问修饰符:Scala中的类成员可以使用private、protected和public等访问修饰符来限制访问。
- 伴生对象:Scala中的类可以有一个同名的伴生对象,它可以访问类的私有成员。
- 样例类:Scala中的样例类是一种特殊的类,它自动为类生成一些有用的方法,例如equals、hashCode和toString等。
总之,Scala中的类是一种非常重要的概念,它们提供了一种面向对象的编程方式,可以帮助我们组织代码并实现复杂的功能
单例对象
Scala单例对象是一种特殊的对象,它只能被实例化一次,并且在整个应用程序中只有一个实例。它类似于Java中的静态类,但是它可以扩展类和特质,并且可以作为参数传递给函数。单例对象通常用于存储全局状态和提供共享的工具函数。在Scala中,单例对象可以通过关键字“object”来定义。例如:
object MySingleton {
def doSomething(): Unit = {
// ...
}
}
在上面的例子中,MySingleton是一个单例对象,它定义了一个名为doSomething的方法。该方法可以通过MySingleton.doSomething()调用。由于单例对象只能被实例化一次,因此可以保证在整个应用程序中只有一个doSomething方法的实例。
Scala中的类和单例对象的区别如下:
-
类是可以实例化的,而单例对象只有一个实例,它是Scala中的一种特殊的对象。
-
类可以有构造函数,而单例对象没有构造函数。
-
类可以继承其他类或特质,而单例对象不能继承其他类或特质。
-
类可以被实例化多次,而单例对象只能被实例化一次。
-
类的成员变量和方法必须通过实例来访问,而单例对象的成员变量和方法可以直接访问。
-
类的实例可以被传递给其他方法或函数,而单例对象不能被传递给其他方法或函数。
-
类可以被序列化和反序列化,而单例对象不能被序列化和反序列化。
总之,类和单例对象在Scala中都是非常重要的概念,它们各自有自己的应用场景和特点。类通常用于创建多个实例,而单例对象通常用于创建全局唯一的实例或提供一些全局的工具方法
RDD
RDD(Resilient Distributed Datasets)是Spark中的一个核心概念,它是一个分布式的、不可变的数据集合,可以被并行处理。RDD的原理是将数据集合分割成多个分区(partition),每个分区可以在不同的节点上进行并行处理。RDD的分区可以在不同的节点上进行数据的存储和计算,从而实现了分布式计算。
RDD的特点是不可变性,即RDD一旦创建就不能被修改,只能通过转换操作(如map、filter、reduce等)生成新的RDD。这种不可变性使得RDD具有很好的容错性,因为如果某个节点出现故障,可以重新计算丢失的分区,而不需要重新计算整个数据集合。
另外,RDD还支持缓存(cache)操作,可以将RDD的分区缓存在内存中,以加速后续的计算。RDD的缓存可以在多个节点上进行共享,从而进一步提高了计算效率。
特点
RDD(Resilient Distributed Datasets)是Spark中的一个核心概念,它是一种可靠、可分区、可并行处理的数据集合。以下是RDD的特点:
-
可靠性:RDD具有容错机制,可以在节点故障时自动恢复数据。
-
可分区性:RDD可以将数据分成多个分区,每个分区可以在不同的节点上进行并行处理。
-
可缓存性:RDD可以将数据缓存在内存中,以便在后续的计算中快速访问。
-
不可变性:RDD是不可变的,一旦创建就不能修改,只能通过转换操作生成新的RDD。
-
惰性计算:RDD采用惰性计算的方式,只有在需要计算结果时才会进行计算,可以避免不必要的计算。
-
支持多种数据源:RDD可以从HDFS、本地文件系统、数据库等多种数据源中读取数据。
-
支持多种操作:RDD支持多种转换操作(如map、filter、reduce等)和行动操作(如count、collect、save等),可以完成各种复杂的数据处理任务。
创建
在Spark中,创建RDD有以下几种方式:
- 从内存中创建RDD:可以通过parallelize()方法将一个已有的集合或数组转化为RDD。
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
- 从外部存储系统中创建RDD:可以通过textFile()方法读取外部存储系统中的文件,创建一个包含文件内容的RDD。
rdd = sc.textFile("file:///path/to/file")
- 从其他RDD转化而来:可以通过对已有的RDD进行转化操作,生成新的RDD。
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd1.map(lambda x: x * 2)
- 从其他数据源创建RDD:Spark支持从Hadoop、Cassandra、HBase等数据源中创建RDD。
rdd = sc.newAPIHadoopRDD(...)
执行过程
RDD的执行过程可以分为两个阶段:转换(Transformation)和行动(Action)。
- 转换(Transformation)阶段
在转换阶段,RDD会根据用户定义的转换操作(如map、filter、join等)对数据进行处理,生成一个新的RDD。这个新的RDD并不会立即计算,而是记录下用户定义的转换操作,等到行动操作被触发时才会执行计算。
- 行动(Action)阶段
在行动阶段,RDD会根据用户定义的行动操作(如count、collect、reduce等)对数据进行计算,并返回结果给用户。在行动操作被触发时,Spark会根据用户定义的转换操作,按照依赖关系逐级计算每个RDD,直到计算出最终结果。
需要注意的是,RDD的转换操作是惰性求值的,也就是说,只有在行动操作被触发时才会执行计算。这种惰性求值的特点使得Spark可以对多个转换操作进行优化,从而提高计算效率。
属性
RDD(Resilient Distributed Datasets)是Spark中的一个基本概念,是一个不可变的分布式数据集合。RDD具有以下属性:
-
分区(Partition):RDD将数据分为多个分区,每个分区都可以在不同的节点上进行计算。
-
弹性(Resilient):RDD具有容错性,即当某个节点出现故障时,RDD可以自动恢复。
-
不可变(Immutable):RDD的数据是不可变的,即不能修改已有的数据,只能通过转换生成新的RDD。
-
惰性计算(Lazy Evaluation):RDD的计算是惰性的,即只有在需要结果时才会进行计算。
-
缓存(Caching):RDD可以缓存到内存中,以提高计算效率。
-
数据分区(Data Locality):RDD可以尽可能地将计算任务分配到数据所在的节点上,以减少数据传输的开销。
RDD持久化
RDD持久化是指将RDD(弹性分布式数据集)中的数据缓存到内存或磁盘中,以便在后续的计算中能够更快地访问这些数据。RDD持久化可以提高计算性能,减少计算时间,特别是在迭代计算中。RDD持久化可以通过调用persist()或cache()方法来实现。在持久化RDD时,可以选择将数据缓存到内存、磁盘或两者兼备。持久化RDD需要占用一定的内存或磁盘空间,因此需要根据实际情况进行权衡和选择
需要RDD持久化的原因是,Spark程序通常需要对同一个RDD数据集进行多次计算,而每次计算都需要重新读取数据集并进行计算,这会导致重复计算和磁盘读取,从而降低程序的性能。通过将RDD数据集缓存到内存中,可以避免这种情况,提高程序的性能。同时,RDD持久化还可以在节点故障时提供数据恢复功能,保证程序的可靠性
DataFrame和RDD
都是都是Spark中的数据结构,但是它们之间有一些区别
-
DataFrame是一种结构化数据,类似于关系型数据库中的表格,而RDD是一种分布式数据集合,可以包含任何类型的数据。
-
DataFrame具有自己的模式,即列名和数据类型,而RDD没有模式。
-
DataFrame可以使用SQL查询,而RDD需要使用函数式编程。
-
DataFrame可以使用Spark SQL中的优化器进行优化,而RDD无法进行优化。
常用操作:
DataFrame常用操作包括:
-
创建DataFrame
-
选择列
-
过滤数据
-
分组和聚合
-
排序
-
连接
-
写入和读取数据
RDD常用操作包括:
-
创建RDD
-
转换操作,如map、filter、flatMap等
-
行动操作,如count、reduce、collect等
-
缓存
-
持久化
-
分区
-
广播变量
-
累加器
流数据的定义与特点
流数据是一组顺序、大量、快速、连续到达的数据序列,视为一个随时间延续而无无限增大的动态数据集合。流数据具有一下几个特点
- 数据实时到达
- 数据到达次数独立,不受应用系统控制
- 数据规模宏大且不能预知其最大值
- 数据一经处理,除非特意保存否则不能被再次取出处理,如果再次提取数据则代价昂贵
Spark streaming运行原理
Spark Streaming是基于Spark Core的批处理引擎,它将实时数据流划分为一系列小批量数据,然后使用Spark引擎对这些小批量数据进行处理。其运行原理如下:
-
数据源:Spark Streaming支持多种数据源,如Kafka、Flume、HDFS、Socket等。
-
数据划分:数据源中的数据被划分为一系列小批量数据,每个小批量数据都是一个RDD。
-
处理:Spark Streaming使用Spark引擎对每个小批量数据进行处理,可以使用Spark Core中的各种操作,如map、reduce、join等。
-
输出:处理结果可以输出到文件系统、数据库、消息队列等。
-
容错:Spark Streaming具有容错机制,可以在节点故障时自动恢复。
-
执行:Spark Streaming将处理流程转化为DAG图,然后使用Spark Core的执行引擎进行执行。
-
监控:Spark Streaming提供了丰富的监控和调试工具,可以实时监控流处理的状态和性能。
总的来说,Spark Streaming将实时数据流转化为一系列小批量数据,然后使用Spark引擎进行处理,具有高性能、高可靠性和易于开发的特点。
Scala编写Spark Streaming程序的步骤
- 导入必要的包
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
- 创建StreamingContext
val conf = new SparkConf().setAppName("StreamingExample").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(1))
其中,conf是SparkConf对象,用于设置Spark应用程序的配置信息,ssc是StreamingContext对象,用于设置Spark Streaming应用程序的配置信息。
- 创建DStream
val lines = ssc.socketTextStream("localhost", 9999)
其中,socketTextStream方法用于创建一个DStream,从指定的主机和端口号接收数据流。
- 对DStream进行操作
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
其中,flatMap方法用于将每行文本拆分成单词,map方法用于将每个单词映射为(单词, 1)的键值对,reduceByKey方法用于统计每个单词出现的次数,print方法用于打印结果。
- 启动StreamingContext
ssc.start()
ssc.awaitTermination()
其中,start方法用于启动StreamingContext,awaitTermination方法用于等待StreamingContext停止。
完整的Scala代码示例:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingExample").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
DStream
DStream是Spark Streaming中最基本的抽象概念,代表一个连续的数据流,可以看作是一个RDD序列。DStream可以从各种数据源(如Kafka、Flume、HDFS、Socket等)中实时获取数据,然后对数据进行处理和分析。DStream提供了一系列的转换操作,如map、filter、reduceByKey等,可以对数据进行实时处理和转换。DStream还可以通过window、join、union等操作实现更复杂的数据处理。DStream的最终结果可以输出到文件系统、数据库、Dashboard等目的地
总结如下:
- 导入必要的依赖库,包括Spark Streaming和Spark Core。
- 创建一个SparkConf对象,设置应用程序的名称和运行模式。
- 创建一个StreamingContext对象,指定批处理间隔时间。
- 创建一个DStream对象,可以从数据源(如Kafka、Flume、HDFS等)中读取数据,也可以通过转换操作从其他DStream对象中获取数据。
- 对DStream对象进行转换操作,如map、filter、reduceByKey等,生成新的DStream对象。
- 对DStream对象进行输出操作,如print、saveAsTextFiles等,将结果输出到控制台或存储系统中。
- 调用StreamingContext对象的start方法启动流处理程序。
- 调用StreamingContext对象的awaitTermination方法等待程序运行结束。
- 关闭StreamingContext对象,释放资源。
GraphX图计算
特点
-
基于Spark核心模块Spark Core实现:GraphX是基于Spark分布式计算框架的图计算库,利用Spark Core的分布式计算能力,可以高效地处理大规模图数据。
-
GraphX引入了抽象数据结构弹性分布式属性图:GraphX采用了弹性分布式属性图(Resilient Distributed Property Graph)作为数据结构,可以方便地表示图中的节点和边,并且支持节点和边上的属性。
-
支持pregel编程接口:GraphX支持pregel编程接口,这是一种基于Bulk Synchronous Parallel(BSP)模型的图计算模型,可以方便地实现各种图算法。
-
具有良好的可扩展性:GraphX具有良好的可扩展性,可以在分布式集群上运行,支持水平扩展,可以处理大规模的图数据。同时,GraphX还支持多种分布式存储系统,如HDFS、Cassandra等
属性图
Spark中的属性图是一种基于图形模型的数据结构,用于表示和处理大规模图形数据。属性图由节点和边组成,每个节点和边都可以带有属性。属性图可以用于各种图形分析任务,如社交网络分析、推荐系统、生物信息学等。
机器学习MLlib
机器学习的形式主要有以下三种
-
监督学习(Supervised Learning):监督学习是指在已知输入和输出的情况下,通过学习建立输入和输出之间的映射关系,从而预测新的输入对应的输出。常见的监督学习算法包括线性回归、逻辑回归、决策树、支持向量机等。
-
无监督学习(Unsupervised Learning):无监督学习是指在没有标注数据的情况下,通过学习发现数据中的结构和模式,从而进行聚类、降维等任务。常见的无监督学习算法包括K-Means聚类、主成分分析、自编码器等。
-
半监督学习(Semi-Supervised Learning):半监督学习是指在部分数据有标注的情况下,通过学习利用未标注数据来提高模型的性能。常见的半监督学习算法包括标签传播、半监督SVM等。
-
强化学习(Reinforcement Learning):强化学习是指通过试错的方式,通过与环境的交互来学习最优的行为策略,以最大化累积奖励。常见的强化学习算法包括Q-Learning、Deep Q-Network等。
-
迁移学习(Transfer Learning):迁移学习是指将已学习的知识迁移到新的任务中,从而加速学习和提高性能。常见的迁移学习算法包括领域自适应、多任务学习等。
Spark在机器学习方面有什么优势:
- 因为基于内存计算,速度比hadoop快
- spark有出色而高效的Akka和Netty通信系统,通信效率极高
- MLlib基于RDD,可以与Spark SQL、GraphX、Spark Streaming无缝集成,并以RDD为基础进行联合数据计算
在Spark的MLlib中,基本数据类型包括以下几种:
-
稠密向量(DenseVector):表示一个实数向量,所有元素都是非零的。
-
稀疏向量(SparseVector):表示一个实数向量,只有少数元素是非零的。
-
稠密矩阵(DenseMatrix):表示一个实数矩阵,所有元素都是非零的。
-
稀疏矩阵(SparseMatrix):表示一个实数矩阵,只有少数元素是非零的。
分布式集群上运行,支持水平扩展,可以处理大规模的图数据。同时,GraphX还支持多种分布式存储系统,如HDFS、Cassandra等
属性图
Spark中的属性图是一种基于图形模型的数据结构,用于表示和处理大规模图形数据。属性图由节点和边组成,每个节点和边都可以带有属性。属性图可以用于各种图形分析任务,如社交网络分析、推荐系统、生物信息学等。