目录
1. 常用函数语法
1.1. open_打开文件
1.2. read_读取文件
1.3. readlines_读取文件
1.4. csv.reader_读取csv文件
1.5. write_写入内容
2. 操作普通文件
2.1. 读取内容
① 按大小读取
② 按行数读取
③ 按列数读取
④ 读取大文件
⑤ 条件过滤
2.2. 写入内容
① 覆盖原有内容
② 追加到原有内容
③ 修改内容
1. 常用函数语法
1.1. open_打开文件
语法
open(
'文件路径', #必选参数
mode='模式', #可选参数,模式包含:r(读)、w(写)、a(追加)、x(创建)、b(二进制)、t(文本),组合'rb'读取二进制文件(任意组合)
buffering=[缓冲大小] #可选参数,单位字节,0表示不适用缓冲。读写二进制文件默认0,读写文本文件默认-1(系统自动决定)
encoding=[编码方式] #可选参数,默认为系统默认编码。常用utf-8、gbk、gb2312
errors=[处理编码错误的方式] #可选参数,默认为'strict',即出现错误时抛出UnicodeError异常。常见的方式有'ignore'忽略错误,'replace' 用?来替换错误,'backslashreplace' 用反斜杠替换错误。
newline=控制文件中换行顺序 #可选参数,None、''、'\n'、'\r'、'\r\n'等
)- open的模式决定了后面函数的读写
1.2. read_读取文件
语法
[文件].read(
size #可选参数,指定读取的字节数
encoding #可选参数,指定文本编码(常见的 UTF-8、GBK)
errors #可选参数,指定解码错误的处理方式(默认:strict),ignore:忽略错误,replace:替换错误,或者其他自定义的错误方法。
newline #可选参数,用于区分并读取带有不同换行符号的文件。Linux:\n,Windows:\r\n
)
1.3. readlines_读取文件
语法
[文件].readlines(
size #可选参数,指定读取的字节数
hint #可选参数,指定读取的最大行数。当文件规模较大时,建议设置该参数,以减轻内存压力。
encoding #可选参数,指定文本编码(常见的 UTF-8、GBK)
errors #可选参数,指定解码错误的处理方式(默认:strict),ignore:忽略错误,replace:替换错误,或者其他自定义的错误方法。
newline #可选参数,用于区分并读取带有不同换行符号的文件。Linux:\n,Windows:\r\n
)
1.4. csv.reader_读取csv文件
语法
csv.reader(
'文件' #必选参数,指定open打开的文件
delimiter='[分隔符]' #可选参数,默认逗号
skipinitialspace=[布尔值] #可选参数,表示是否忽略分隔符后的空白,默认值为 False。
dialect='[CSV文件的方言]' #可选参数,默认值为 excel。例如 csv.excel_tab。可以使用 csv.list_dialects() 获取全部方言信息。
quotechar='[字符串]' #可选参数,当需要引用字段时使用的字符。默认值为 "
escapechar='\' #可选参数,指定在字符串中非字面量字符前面的转义字符,默认值为没有指定。
doublequote=[布尔值] #可选参数,表示是否将引用字符写为两个引用字符。默认值为 True。
strict=[布尔值] #可选参数,默认False,当设置为 True 时,当读取的行中包含与方言不兼容的数据时,抛出 csv.Error 异常。
)
1.5. write_写入内容
语法
[文件].write(
size #可选参数,指定读取的字节数
encoding #可选参数,指定文本编码(常见的 UTF-8、GBK)
errors #可选参数,指定解码错误的处理方式(默认:strict),ignore:忽略错误,replace:替换错误,或者其他自定义的错误方法。
newline #可选参数,用于区分并读取带有不同换行符号的文件。Linux:\n,Windows:\r\n
)
2. 操作普通文件
2.1. 读取内容
手动关闭文件方法
# 打开一个名为file.txt的文件
f = open("file.txt", "r")
# 读取文件
print(f.read())
# 关闭文件
f.close()with 自动关闭文件
# 打开一个名为file.txt的文件
with open("file.txt", "r") as f:
# 读取文件
print(f.read())
① 按大小读取
读取10字节内容
with open('/home/tmp.txt', mode='r', buffering=2048) as f:
# 指定读取10字节
print(f.read(10))
② 按行数读取
读取前10行内容
with open('/home/tmp.txt', 'r') as f:
# 使用readlines切片读取前10行,赋值给某个变量
chunk = f.readlines()[:10]
# 遍历这个遍历
for i in chunk:
# 使用strip处理遍历的内容
print(i.strip())读取文件11-20行内容
with open('/home/tmp.txt', 'r') as f:
# 使用readlines切片读取后10行,赋值给某个变量
chunk = f.readlines()[10:20]
# 遍历这个遍历
for i in chunk:
# 使用strip处理遍历的内容
print(i.strip())读取文件后10行内容
with open('/home/tmp.txt', 'r') as f:
# 使用readlines切片读取前10行,赋值给某个变量
chunk = f.readlines()[-10:]
# 遍历这个遍历
for i in chunk:
# 使用strip处理遍历的内容
print(i.strip())切片会创建一个新列表,因此在处理非常大的文件时可能会导致内存问题。为了避免这种情况,可以使用逆向迭代器,以生成器的方式读取文件行。即使文件太大,也不会读取完整文件
import os,itertools
# 定义一个反向迭代器函数
def reverse_readline(filename, bufsize=8192):
with open(filename) as f:
# 将文件指针移到文件末尾
f.seek(0, os.SEEK_END)
# 获取文件大小
remaining_bytes = f.tell()
# 定位到文件末尾的最后一个完整行
f.seek(-min(bufsize, remaining_bytes), os.SEEK_CUR)
lines = []
# 逆序读取行
while remaining_bytes > 0:
# 读取缓存数据
read_size = min(bufsize, remaining_bytes)
data = f.read(read_size)
# 倒置数据并获取行
lines = data[::-1].splitlines(True) + lines
# 更新剩余字节数
remaining_bytes -= read_size
# 重新定位指针到当前位置的后面
f.seek(-read_size, os.SEEK_CUR)
# 迭代器
for line in lines:
yield line
# 调用逆向迭代器函数,获取文件的最后10行
with open('tmp.txt', 'w') as f:
for i in range(100):
f.write('Line {}\n'.format(i))
for line in itertools.islice(reverse_readline('tmp.txt'), 0, 10):
print(line.strip())
③ 按列数读取
指定分隔符读取某列(索引读取)
import csv
path = '/home/yt/python/file.txt'
# 打开文件
with open(path, newline='') as f:
# 使用csv模块读取文件,指定分隔符为 | (默认逗号)
readr = csv.reader(f, delimiter='|')
# 遍历文件内容
for i in readr:
#按索引取列(第2列)
print(i[1])读取多列(索引读取)
import csv
path = '/home/yt/python/file.txt'
with open(path, newline='') as f:
#默认分隔符为逗号
readr = csv.reader(f)
for i in readr:
# 按索引读取第2列和第3列
print(i[1:3])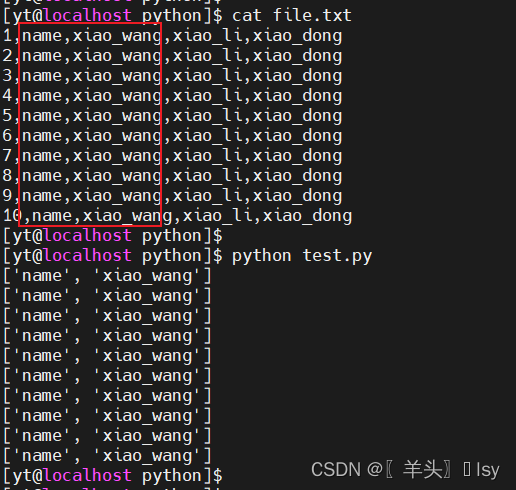
④ 读取大文件
读取大文件(按指定大小循环读取,保证文件过大时不会大量使用内存)
with open('/home/tmp.txt', 'r') as f:
# 循环读取文件中的行
while True:
# 每行读取1024字节,赋值给一个变量(如果单行大小超过1024,那么只会截取1024部分)
chunk = f.read(1024)
# 如果读取为空,那么退出循环(空行不算)
if not chunk:
break
# 持续打印读取的行
print(chunk)
注意:不要用readlines!不要用readlines!不要用readlines!
举个例子
l = []
with open('/home/tmp.txt', 'r') as f:
for i in f.readlines():
l.append(i)- 这种方法去读取一个1GB的文件,会消耗7.4GB内存,且耗时19s。
- 上面的循环方法内存使用仅500MB,耗时1.3s。
⑤ 条件过滤
使用readlines方法(只适用于读取小文件)
过滤条件(仅读取含 "abc" 的行)
with open('/home/tmp.txt', 'r', buffering=8192) as f:
# 按行遍历内容
for i in f.readlines():
# 判断该行包含字符串 'abc'
if 'abc' in i:
print(i.strip())过滤条件(读取不包含 "abc" 的行)
with open('/home/tmp.txt', 'r', buffering=8192) as f:
# 按行遍历内容
for i in f.readlines():
# 判断该行不包含字符串 'abc'
if 'abc' not in i:
print(i.strip())
循环方法(适用于读取大文件)
with open('/home/tmp.txt', 'r') as f:
# 按行遍历内容
while True:
# 每行最大输出1024字节
chunk = f.read(1024)
if not chunk:
break
if 'abc' in chunk:
print(chunk)
2.2. 写入内容
手动关闭文件的方法(覆盖原有文件内容)
# 打开一个名为file.txt的文件,如果该文件不存在,则自动新建一个文件
f = open("file.txt", "w")
# 写入内容到文件
f.write("ha ha ha")
# 关闭文件
f.close()自动关闭文件的方法(覆盖原有文件内容)
# 打开一个名为file.txt的文件,如果该文件不存在,则自动新建一个文件
with open("file.txt", "w") as f:
# 写入内容到文件
f.write("ha ha ha")
① 覆盖原有内容
将手动编写的字符串覆盖到文件
# 打开一个名为file.txt的文件,如果该文件不存在,则自动新建一个文件
with open("file.txt", "w") as f:
# 写入内容到文件
f.write("ha ha ha")
将文件1的内容拷贝到文件2(覆盖)
import shutil
# 使用shutil模块,将文件1拷贝到文件2
shutil.copyfile('file1.txt', 'file2.txt')
将文件1的前10行写入文件2
read_file = '/home/file1.txt'
write_file = '/home/file2.txt'
#读取文件(指定路径,使用r) 写入文件(指定路径,使用w)
with open(read_file, 'r') as f_read, open(write_file, 'w') as f_write:
# 遍历前10行
for i in f_read.readlines()[:10]:
#将每行的内容写入指定的文件
f_write.write(i.strip())
将文件1包含字符串 "abc" 的行写入文件2
read_file = '/home/file1.txt'
write_file = '/home/file2.txt'
#读取文件(指定路径,使用r) 写入文件(指定路径,使用w)
with open(read_file, 'r') as f_read, open(write_file, 'w') as f_write:
#循环读取文件
while True:
#每次读取1024字节,减少内存使用
chunk = f_read.read(1024)
#如果读完内容,则退出循环
if not chunk:
break
#将内容包含 'abc' 的行写入另一个文件
if 'abc' in chunk:
f_write.write(i)
将文件中包含 "abc" 的行读取出来,重新覆盖给文件本身
file_path = '/home/tmp.txt'
# 打开文件,并读取所有行
with open(file_path, 'r') as f:
lines = f.readlines()
# 遍历符合条件的行
filtered_lines = [i for i in lines if 'abc' in i]
# 将过滤后的行覆盖到原始文件
with open(file_path, 'w') as f:
f.writelines(filtered_lines)
② 追加到原有内容
追加自定义内容到文件
# 文件路径
path = '/home/yt/python/file.txt'
# 输入的内容
desc = 'abc\nedf\n123'
# 打开文件,a表示追加
with open(path, 'a') as f:
# 将内容追加到文件
f.write(desc)
将文件1的内容追加到文件2
# 打开需要读取的文件
with open('/home/tmp2.txt', 'r') as f1:
# 打开需要追加的文件
with open('/home/tmp2.txt', 'a') as f2:
# 将f1的内容追加到f2(如果f2不存在,则自动创建并追加)
f2.write(f1.read())
将文件1包含 "abc" 的部分内容追加到文件2
# 打开需要读取的文件
with open('/home/tmp1.txt', 'r') as f1:
# 打开需要追加的文件
with open('/home/tmp2.txt', 'a') as f2:
# 遍历读取的文件内容
for i in f1:
# 将符合条件的行追加到另一个文件
if 'abc' in i:
f2.write(i)
③ 修改内容
将文件内容读取出来再替换字符,最后重新覆盖到文件本身
# 打开文件
with open(path, 'r') as f:
# 将读取的内容赋值给变量
file_content = f.read()
# 使用replace将变量中 AAA 替换为 BBB
file_content = file_content.replace('AAA', 'BBB')
# 再将已替换的变量覆盖给文件
with open(path, 'w') as f:
f.write(file_content)如果让被替换的内容不区分大小写,使用re正则
import re
# 打开文件
with open(path, 'r') as f:
# 将读取的内容赋值给变量
file_content = f.read()
# 使用正则将变量中 AAA(不区分大小写) 替换为 BBB
file_content = re.sub(r'AAA', 'BBB', file_content, flags=re.IGNORECASE)
# 再将已替换的变量覆盖给文件
with open(path, 'w') as f:
f.write(file_content)替换大文件使用逐块读取和写入的方式可以避免使用过多内存
import os, shutil
# 操作的文件
path = '/home/yt/python/file.txt'
# 临时文件(将替换好的行先放入临时文件)
tmp = '/home/yt/python/tmp.txt'
# 创建这个临时文件
os.mknod(tmp)
# 打开需要操作的文件
with open(path, 'rb') as f1:
# 打开临时文件,准备写入已替换的内容
with open(tmp, 'wb') as f2:
# 遍历文件内容
while True:
# 指定每次读取大小(单位:字节)
chunk = f1.read(8192)
# 如果内容已读完,那么退出循环
if not chunk:
break
# 将读取的内容进行替换
chunk = chunk.replace('aaa'.encode('UTF-8'), 'bbb'.encode('UTF-8'))
# 写入临时文件
f2.write(chunk)
# 将临时文件的内容覆盖到操作文件
shutil.copyfile(tmp, path)
# 删除临时文件
os.remove(tmp)