算法拾遗三十二bfprt算法,蓄水池算法
- 在无序数组中求第k小的数
- 快排解法
- bfprt解法
- 练习题目
- 蓄水池算法
- bfprt 应用
在无序数组中求第k小的数
快排解法
// 改写快排,时间复杂度O(N)
// k >= 1
public static int minKth2(int[] array, int k) {
int[] arr = copyArray(array);
return process2(arr, 0, arr.length - 1, k - 1);
}
public static int[] copyArray(int[] arr) {
int[] ans = new int[arr.length];
for (int i = 0; i != ans.length; i++) {
ans[i] = arr[i];
}
return ans;
}
// arr 第k小的数
// process2(arr, 0, N-1, k-1)
// arr[L..R] 范围上,如果排序的话(不是真的去排序),找位于index的数
// index [L..R]
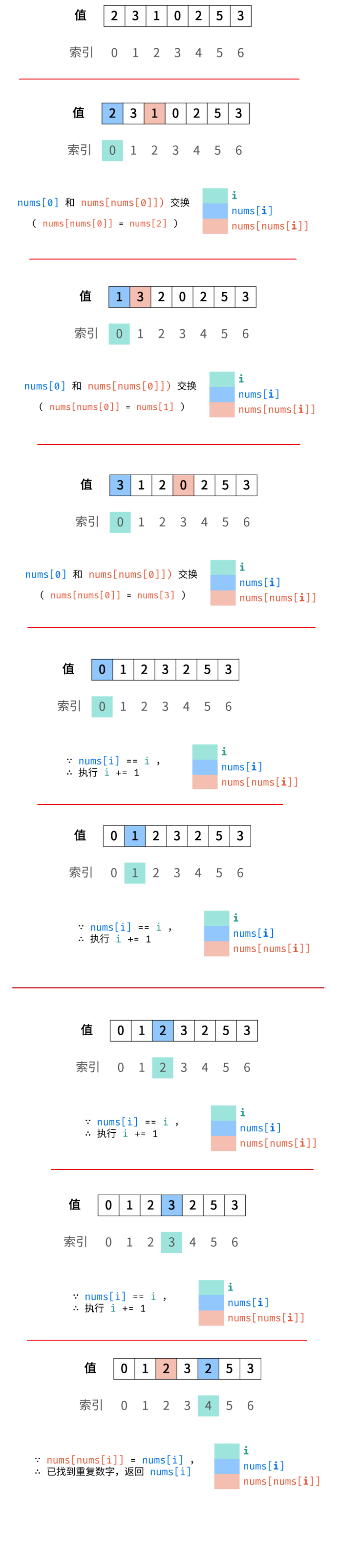
public static int process2(int[] arr, int L, int R, int index) {
if (L == R) { // L = =R ==INDEX
return arr[L];
}
// 不止一个数 L + [0, R -L]
int pivot = arr[L + (int) (Math.random() * (R - L + 1))];
int[] range = partition(arr, L, R, pivot);
if (index >= range[0] && index <= range[1]) {
return arr[index];
} else if (index < range[0]) {
return process2(arr, L, range[0] - 1, index);
} else {
return process2(arr, range[1] + 1, R, index);
}
}
public static int[] partition(int[] arr, int L, int R, int pivot) {
int less = L - 1;
int more = R + 1;
int cur = L;
while (cur < more) {
if (arr[cur] < pivot) {
swap(arr, ++less, cur++);
} else if (arr[cur] > pivot) {
swap(arr, cur, --more);
} else {
cur++;
}
}
return new int[] { less + 1, more - 1 };
}
public static void swap(int[] arr, int i1, int i2) {
int tmp = arr[i1];
arr[i1] = arr[i2];
arr[i2] = tmp;
}
bfprt解法
快排方法,随机划分值打好的情况下时间复杂度就低, 随机差情况下时间复杂度就高。
bfprt算法核心就是在于这个划分值怎么去选。
快排方法整体流程:
1、随机选一个P
2、小于p的放左边等于p的放中间,大于p的放右边(O(N))
3、看一下等于区域是否命中index,如果命中了直接return,如果没命中则左右两侧只走一侧
bfprt方法:
唯一区别就在于第一步怎么讲究的去选一个p
流程:
1、数组按5个数一组划分:
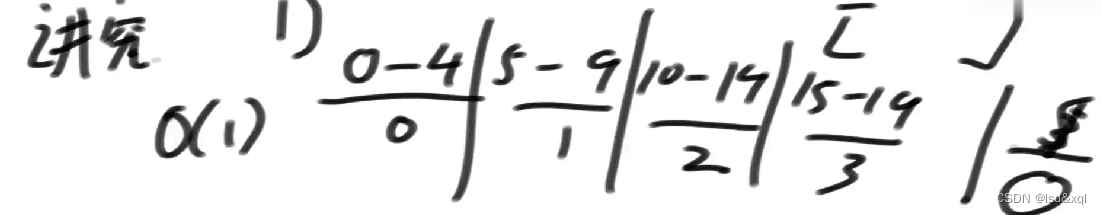
2、让每一个组的数在它所属的小组内部有序(O(N)),每个小组5个数,一个小组的时间复杂度为O(1),所有组里面的元素有序则时间复杂度为O(N)
3、将每个小组里面的中位数拿出来,组成一个新的数组**【如果是剩下四个数为一组:甲乙丙丁,则拿上中位数乙】**
bfprt(arr,k),arr数组里面的第k小的数传入:
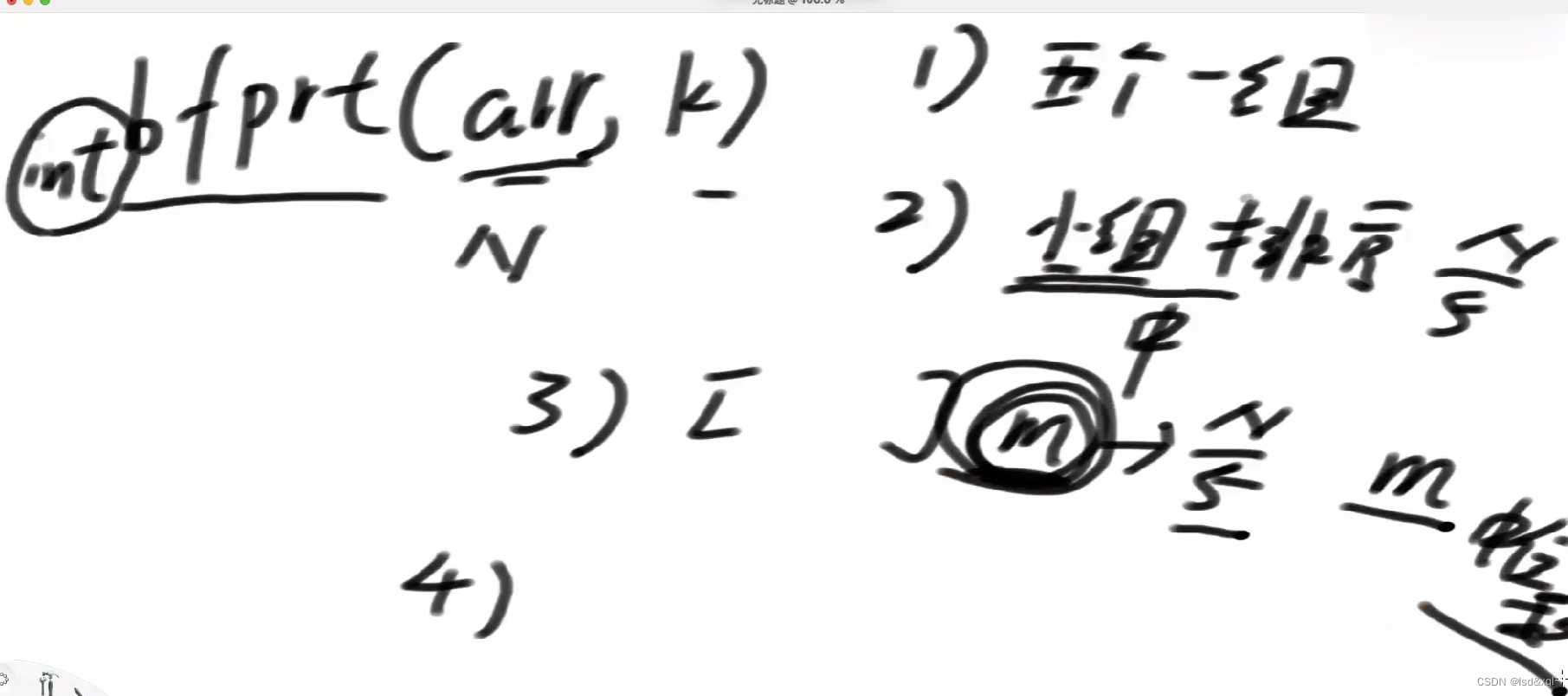
1、五个数为一组
2、小组排序
3、每个组取中位数(N/5)的长度
4、求m这个数组里面的中位数=bfprt(m,N/10)【N/5*1/2=N/10, m数组中元素index从0开始】
这种方式,划分的时候就能划分出一个比较平均的范围,通过中位数可以估算小于p最多有多少个数,则需要估计出大于等于p至少有多少个数

如何根据中位数估计:
有以下几组数都是排好序了的:
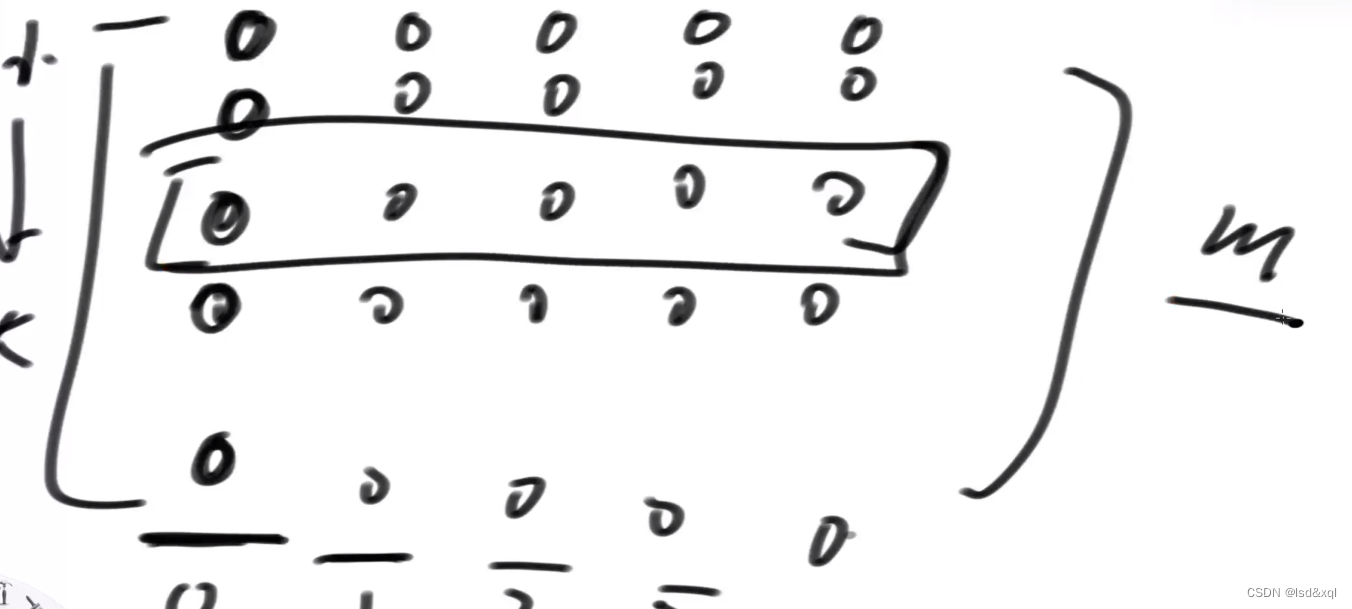
那么m数组就是中间的方框的内容,如果原数组有N个数那么m数组就是N/5的长度,假设是a,b,c,d,e
,然后又求出这5个数的中位数p,那么在这5个数中大于等于p的有至少N/10个。那么在整个数组中有至少3N/10是大于等于p的。
说明:
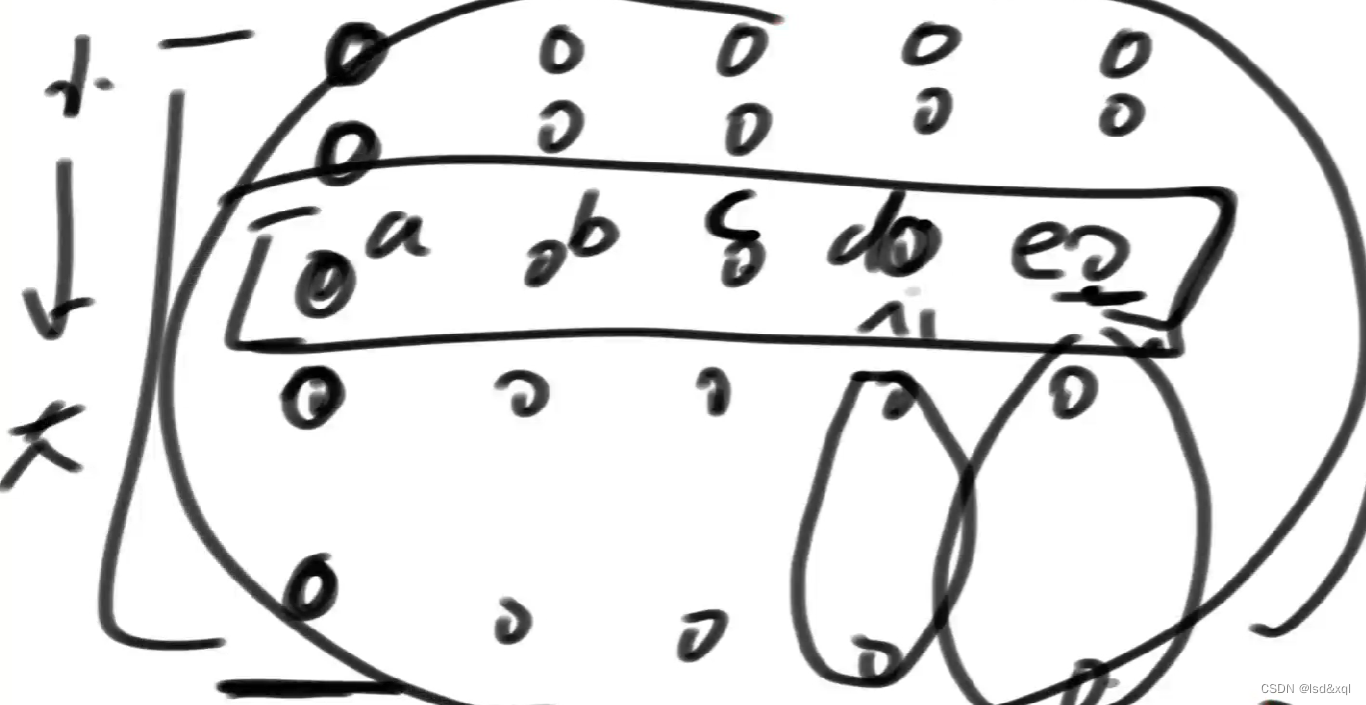
如上图假设c是中位数,d和e都是大于等于c的,d和e对应的下面两个数都是大于等于c的,从而推出整个数组中至少有3N/10个数是大于等于c的。
则得到结论为小于P的情况最多有7N/10,从而确定了固定规模的淘汰,挡掉了随机的最差情况。
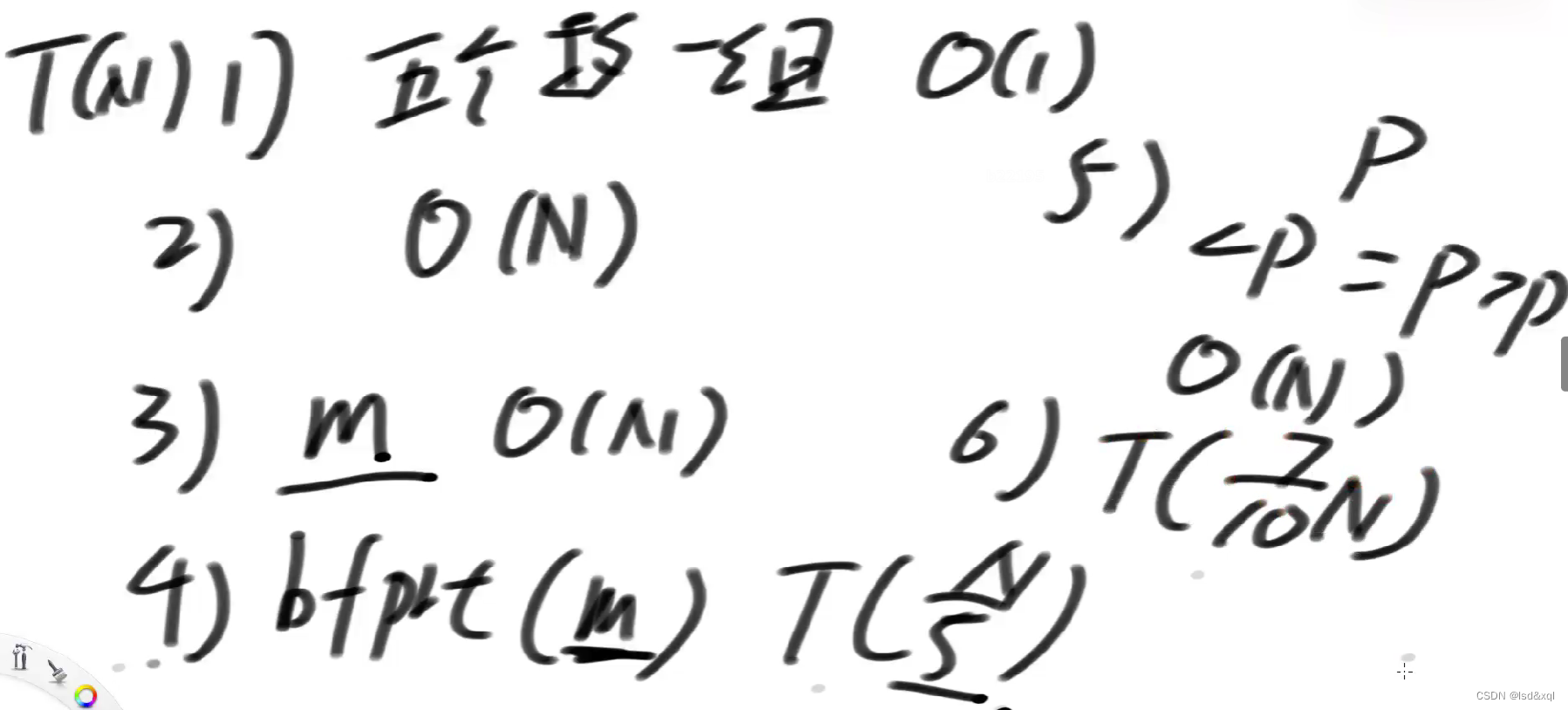
之所以5个数分组是因为这个算法是5个人发明的,3个数7个数都是可以的。
// 利用bfprt算法,时间复杂度O(N)
public static int minKth3(int[] array, int k) {
int[] arr = copyArray(array);
return bfprt(arr, 0, arr.length - 1, k - 1);
}
// arr[L..R] 如果排序的话,位于index位置的数,是什么,返回
public static int bfprt(int[] arr, int L, int R, int index) {
if (L == R) {
return arr[L];
}
// L...R 每五个数一组
// 每一个小组内部排好序
// 小组的中位数组成新数组
// 这个新数组的中位数返回
int pivot = medianOfMedians(arr, L, R);
int[] range = partition(arr, L, R, pivot);
if (index >= range[0] && index <= range[1]) {
return arr[index];
} else if (index < range[0]) {
return bfprt(arr, L, range[0] - 1, index);
} else {
return bfprt(arr, range[1] + 1, R, index);
}
}
// arr[L...R] 五个数一组
// 每个小组内部排序
// 每个小组中位数领出来,组成marr
// marr中的中位数,返回
public static int medianOfMedians(int[] arr, int L, int R) {
int size = R - L + 1;
int offset = size % 5 == 0 ? 0 : 1;
int[] mArr = new int[size / 5 + offset];
for (int team = 0; team < mArr.length; team++) {
int teamFirst = L + team * 5;
// L ... L + 4
// L +5 ... L +9
// L +10....L+14
mArr[team] = getMedian(arr, teamFirst, Math.min(R, teamFirst + 4));
}
// marr中,找到中位数
// marr(0, marr.len - 1, mArr.length / 2 )
return bfprt(mArr, 0, mArr.length - 1, mArr.length / 2);
}
public static int getMedian(int[] arr, int L, int R) {
insertionSort(arr, L, R);
//插入排序返回中位数
return arr[(L + R) / 2];
}
public static void insertionSort(int[] arr, int L, int R) {
for (int i = L + 1; i <= R; i++) {
for (int j = i - 1; j >= L && arr[j] > arr[j + 1]; j--) {
swap(arr, j, j + 1);
}
}
}
练习题目

K一定是小于N的
第一个时间复杂度:就是排完序之后从右往左取出前K个。
第二个时间复杂度:如果整个数组不要求排序,只建立成大根堆的话从下往上建立,是一个O(N)的时间复杂度,然后第二步每次大根堆弹出一个最大值出去直到弹出k个出去时间复杂度为KlogN,所以整个时间复杂度为O(N+KlogN)
第三个时间复杂度为:假设数组中有10000个数,要求最大的前一百个,就可以用前面改写快排的方法,求第k小的数,这个例子中就求第10000减去100(9900)小的数,这个时间复杂度为O(N),然后后面的K*logK的时间复杂度为剩下的k个数排序。
扩展:小根堆写法,N乘以logK ,如果使用小根堆做法,应该是 O(klogk)【因为使用小根堆时,只能看成是一个一个加进来,只能是从上往下建堆】 + O(logk(N-k))【最坏情况数组升序,每次都要调堆】,最终O(N*logk)。
public class MaxTopK {
// 时间复杂度O(N*logN)
// 排序+收集
public static int[] maxTopK1(int[] arr, int k) {
if (arr == null || arr.length == 0) {
return new int[0];
}
int N = arr.length;
k = Math.min(N, k);
Arrays.sort(arr);
int[] ans = new int[k];
for (int i = N - 1, j = 0; j < k; i--, j++) {
ans[j] = arr[i];
}
return ans;
}
// 方法二,时间复杂度O(N + K*logN)
// 解释:堆
public static int[] maxTopK2(int[] arr, int k) {
if (arr == null || arr.length == 0) {
return new int[0];
}
int N = arr.length;
k = Math.min(N, k);
// 从底向上建堆,时间复杂度O(N)
for (int i = N - 1; i >= 0; i--) {
heapify(arr, i, N);
}
// 只把前K个数放在arr末尾,然后收集,O(K*logN)
int heapSize = N;
swap(arr, 0, --heapSize);
int count = 1;
while (heapSize > 0 && count < k) {
heapify(arr, 0, heapSize);
swap(arr, 0, --heapSize);
count++;
}
int[] ans = new int[k];
for (int i = N - 1, j = 0; j < k; i--, j++) {
ans[j] = arr[i];
}
return ans;
}
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1;
while (left < heapSize) {
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
// 方法三,时间复杂度O(n + k * logk)
public static int[] maxTopK3(int[] arr, int k) {
if (arr == null || arr.length == 0) {
return new int[0];
}
int N = arr.length;
k = Math.min(N, k);
// O(N)
int num = minKth(arr, N - k);
int[] ans = new int[k];
int index = 0;
for (int i = 0; i < N; i++) {
if (arr[i] > num) {
ans[index++] = arr[i];
}
}
for (; index < k; index++) {
ans[index] = num;
}
// O(k*logk)
Arrays.sort(ans);
for (int L = 0, R = k - 1; L < R; L++, R--) {
swap(ans, L, R);
}
return ans;
}
// 时间复杂度O(N)
public static int minKth(int[] arr, int index) {
int L = 0;
int R = arr.length - 1;
int pivot = 0;
int[] range = null;
while (L < R) {
pivot = arr[L + (int) (Math.random() * (R - L + 1))];
range = partition(arr, L, R, pivot);
if (index < range[0]) {
R = range[0] - 1;
} else if (index > range[1]) {
L = range[1] + 1;
} else {
return pivot;
}
}
return arr[L];
}
public static int[] partition(int[] arr, int L, int R, int pivot) {
int less = L - 1;
int more = R + 1;
int cur = L;
while (cur < more) {
if (arr[cur] < pivot) {
swap(arr, ++less, cur++);
} else if (arr[cur] > pivot) {
swap(arr, cur, --more);
} else {
cur++;
}
}
return new int[] { less + 1, more - 1 };
}
// for test
public static int[] generateRandomArray(int maxSize, int maxValue) {
int[] arr = new int[(int) ((maxSize + 1) * Math.random())];
for (int i = 0; i < arr.length; i++) {
// [-? , +?]
arr[i] = (int) ((maxValue + 1) * Math.random()) - (int) (maxValue * Math.random());
}
return arr;
}
// for test
public static int[] copyArray(int[] arr) {
if (arr == null) {
return null;
}
int[] res = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
res[i] = arr[i];
}
return res;
}
// for test
public static boolean isEqual(int[] arr1, int[] arr2) {
if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null)) {
return false;
}
if (arr1 == null && arr2 == null) {
return true;
}
if (arr1.length != arr2.length) {
return false;
}
for (int i = 0; i < arr1.length; i++) {
if (arr1[i] != arr2[i]) {
return false;
}
}
return true;
}
// for test
public static void printArray(int[] arr) {
if (arr == null) {
return;
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
System.out.println();
}
// 生成随机数组测试
public static void main(String[] args) {
int testTime = 500000;
int maxSize = 100;
int maxValue = 100;
boolean pass = true;
System.out.println("测试开始,没有打印出错信息说明测试通过");
for (int i = 0; i < testTime; i++) {
int k = (int) (Math.random() * maxSize) + 1;
int[] arr = generateRandomArray(maxSize, maxValue);
int[] arr1 = copyArray(arr);
int[] arr2 = copyArray(arr);
int[] arr3 = copyArray(arr);
int[] ans1 = maxTopK1(arr1, k);
int[] ans2 = maxTopK2(arr2, k);
int[] ans3 = maxTopK3(arr3, k);
if (!isEqual(ans1, ans2) || !isEqual(ans1, ans3)) {
pass = false;
System.out.println("出错了!");
printArray(ans1);
printArray(ans2);
printArray(ans3);
break;
}
}
System.out.println("测试结束了,测试了" + testTime + "组,是否所有测试用例都通过?" + (pass ? "是" : "否"));
}
}
蓄水池算法

动态的过往的每一步球进入袋子的概率相等。
机制:
这个流在吐出1-10号球的时候每一个球都进袋子,
当吐出10号求以后,现在吐出的是i号球(i>10),f(i)=10/i的概率进入袋子里面,如果i号球要进入袋子,那么袋子中的10个球等概率淘汰一个出去。
假设现在吐出到1729个球了,来求一下3号球仍然存活在袋子里面的概率?
10号球之前3号球存活的概率为1
11号球到来的时候3号球被淘汰的概率?
10/11进入袋子的概率,3号球在袋子里淘汰的概率为10/11乘以1/10=1/11。3号球存活的概率为10/11,12号球进入概率为【1-(10/121/10)】=11/12,三号球被淘汰的概率110/11*11/12=10/12依次递推下去可以得到当到了1729个球吐出来的时候,3号球被淘汰的概率为10/1729
证明代码统计词频:
public static void main(String[] args) {
System.out.println("hello");
int test = 10000;
int ballNum = 17;
int[] count = new int[ballNum + 1];
for (int i = 0; i < test; i++) {
int[] bag = new int[10];
int bagi = 0;
for (int num = 1; num <= ballNum; num++) {
if (num <= 10) {
bag[bagi++] = num;
} else { // num > 10
// 看10/num的概率是否命中
if (random(num) <= 10) { // 一定要把num球入袋子
//把老的袋子对应index的球给扔掉
bagi = (int) (Math.random() * 10);
bag[bagi] = num;
}
}
}
//加词频
for (int num : bag) {
count[num]++;
}
}
//100万次实验每个球出现的次数
for (int i = 0; i <= ballNum; i++) {
System.out.println(count[i]);
}
}
整体代码:
public class ReservoirSampling {
public static class RandomBox {
private int[] bag;
private int N;
private int count;
public RandomBox(int capacity) {
bag = new int[capacity];
N = capacity;
count = 0;
}
private int rand(int max) {
return (int) (Math.random() * max) + 1;
}
public void add(int num) {
count++;
if (count <= N) {
bag[count - 1] = num;
} else {
if (rand(count) <= N) {
bag[rand(N) - 1] = num;
}
}
}
public int[] choices() {
int[] ans = new int[N];
for (int i = 0; i < N; i++) {
ans[i] = bag[i];
}
return ans;
}
}
// 请等概率返回1~i中的一个数字
public static int random(int i) {
return (int) (Math.random() * i) + 1;
}
public static void main(String[] args) {
System.out.println("hello");
int all = 100;
int choose = 10;
int testTimes = 50000;
int[] counts = new int[all + 1];
for (int i = 0; i < testTimes; i++) {
RandomBox box = new RandomBox(choose);
for (int num = 1; num <= all; num++) {
box.add(num);
}
int[] ans = box.choices();
for (int j = 0; j < ans.length; j++) {
counts[ans[j]]++;
}
}
for (int i = 0; i < counts.length; i++) {
System.out.println(i + " times : " + counts[i]);
}
}
}
bfprt 应用
假设有一个游戏【国际游戏,不同国家有对应的游戏服务器】,并且打算抽奖,抽奖规则如下:
1、所有在今天登录过的用户抽奖一次
2、开奖时间在第二天的零点
3、任意用户都是等概率中奖
4、中奖名额一百
如果不用蓄水池问题,得把所有服务器的所有用户名单拿到手,风险高且没办法在第二天就能马上得到中奖用户,因为晚上十一点以后还可能有用户登录,这个时候还得再做一系列的汇总
如果有蓄水池算法:
1、全球所有的服务器只跟一台服务器沟通
2、只需要判断某一用户是否是当天第一次登录,如果第一次登录则让他参加登录
3、让用户知道他是第几号登录的(假设是i号登录,则中奖概率为100/i),如果中奖了则在奖池中踢掉一个用户。
如何实现一个大吞吐量的UUID【比如全球要给每个沙子做唯一uuid的编码】:
1、首先不用hash算法(碰撞概率不为0)【SHA1,SHA256,MD5】
2、全球服务器只维护两个变量,1当前给到多少编号了(base)
3、下级为国家服务器,表示各个国家向全国要数据给定一个range【这个range可以根据各个国家服务器要数据的频率来做弹性伸缩】,把压力这件事情划分给range。
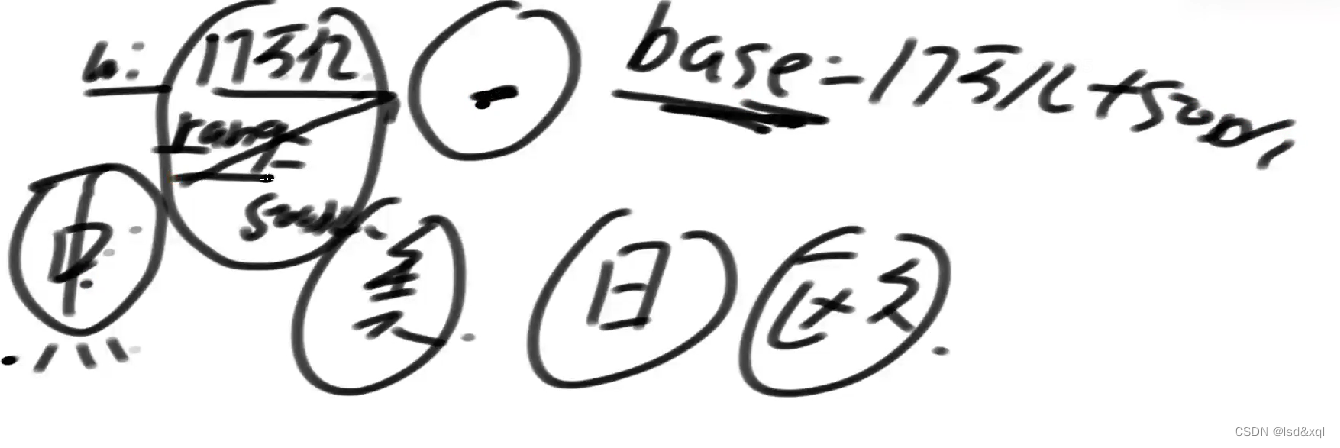
4、国家服务器下面又是各个省级服务器,逐步的往下划分

任何服务器挂掉的时候,不用维持任何数据,只需要向上级要新的UUID,反正给的都是Base加range的结果