1. OCR
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
2、下载地址
tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
进入下载页面,可以看到有各种.exe文件的下载列表,这里可以选择下载3.0版本。
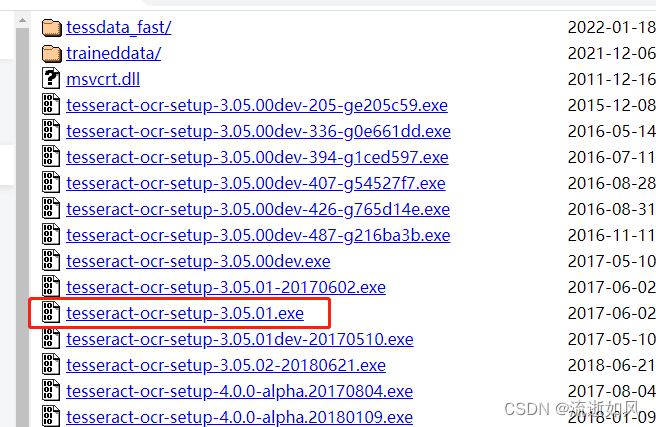
3、安装
默认安装路径是:C:\Program Files (x86)\Tesseract-OCR,可以不用修改。个人习惯不存放在C盘,改为:D:\Tesseract-OCR
直接傻瓜式的下一步,到选择语言时,选择一些需要的,比如可以选择math,英文,中文等。然后一路点击Next按钮即可,不然安装时间特别长。
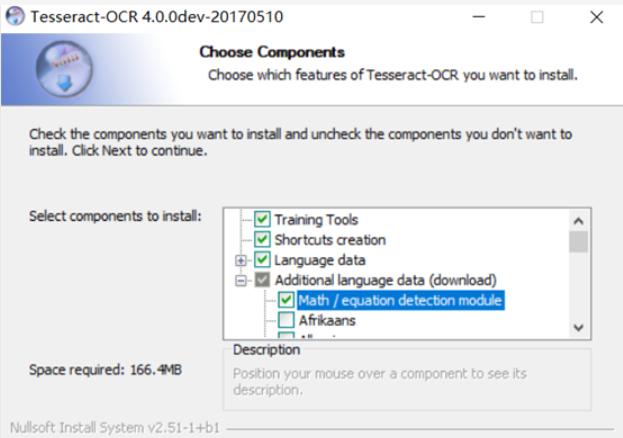
4、配置环境变量
1)配置path
高级系统设置——>环境变量——>系统变量中path路径——>存放刚刚的地址:D:\Tesseract-OCR
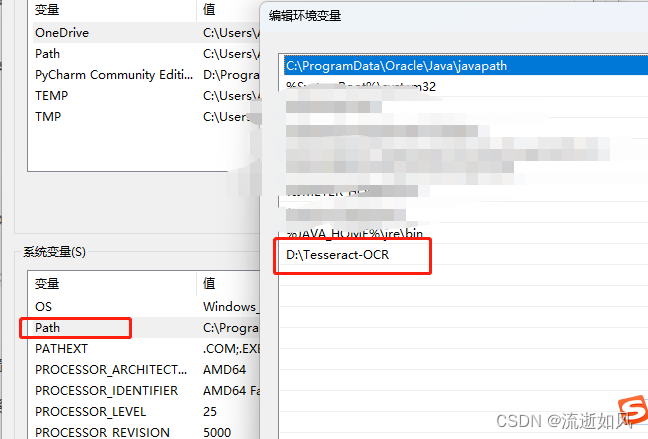
2)配置TESSDATA_PREFIX
变量名:TESSDATA_PREFIX
变量值:D:\Tesseract-OCR\
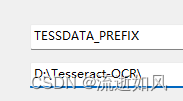
这一步如果没配置,会报错:
Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.
5、验证
1)查看版本号
cmd中输入:tesseract -v

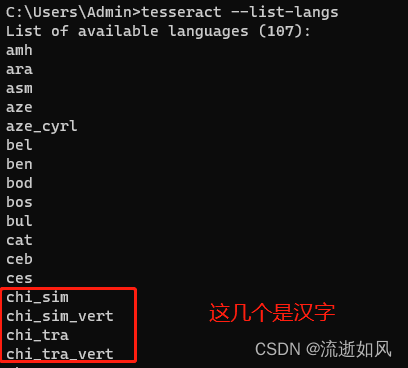
2)查看支持多少种语言
cmd中输入:tesseract --list-langs
3)识别能力
图片是网上随便找的一个,在图片的地址打开cmd,输入指令:
tesseract E:\image.jpg result -l eng
图片所在的路径下,自动新建一个result.txt,里面的内容就是识别出来的内容
可自行下载:https://img-blog.csdnimg.cn/b3f1c541bb124f19b88dcdfd199d9298.jpeg


但是:
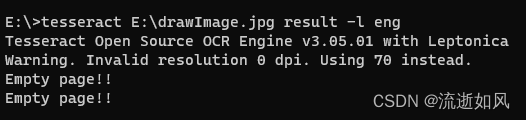
我识别需要降噪的图片就不行
图片:

报错:
目前还没找到解决方法,先记录一下,如果有大神搞定了,麻烦评论里面放一下链接或留言,万分谢谢!