sparksql只能处理结构化数据
基于rdd构建dataframe对象
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
if __name__ == '__main__':
spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate()
sc = spark.sparkContext
#基于rdd建表
rdd = sc.textFile('../data/input/word.txt').map(lambda x:x.split(' ')).\
map(lambda x:(x[0],int(x[1])))
### 使用rdd构建dataframe
df = spark.createDataFrame(rdd,schema=['name','age'])
df.printSchema()
df.show(20,False)
df.createOrReplaceTempView('people')
spark.sql('select * from people where age<20').show()
#使用toDF的方式构建dataframe
df = rdd.toDF(['name','age'])
df.printSchema()
df.show()
# 使用structType的方式构建dataframe
schema = StructType.add('name',StringType(),nullable=True).add('age',IntegerType(),nullable=False)
df2 = rdd.toDF(schema=schema)
df2.printSchema()
df2.show()
sparksql读取本地文件
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
if __name__ == '__main__':
spark = SparkSession.builder.appName('test').master('local[*]').config('spark.sql.shuffle.partitions',2).getOrCreate()
sc = spark.sparkContext
schema = StructType().add('data',StringType(),nullable=True)
# 读取txt文件
df = spark.read.format('text').schema(schema=schema).load('../data/input/word.txt')
# 读取csv文件
df = spark.read.format('csv').option('sep',',').option('header',True).load('../data/input/word.txt')
df.printSchema()
df.show()
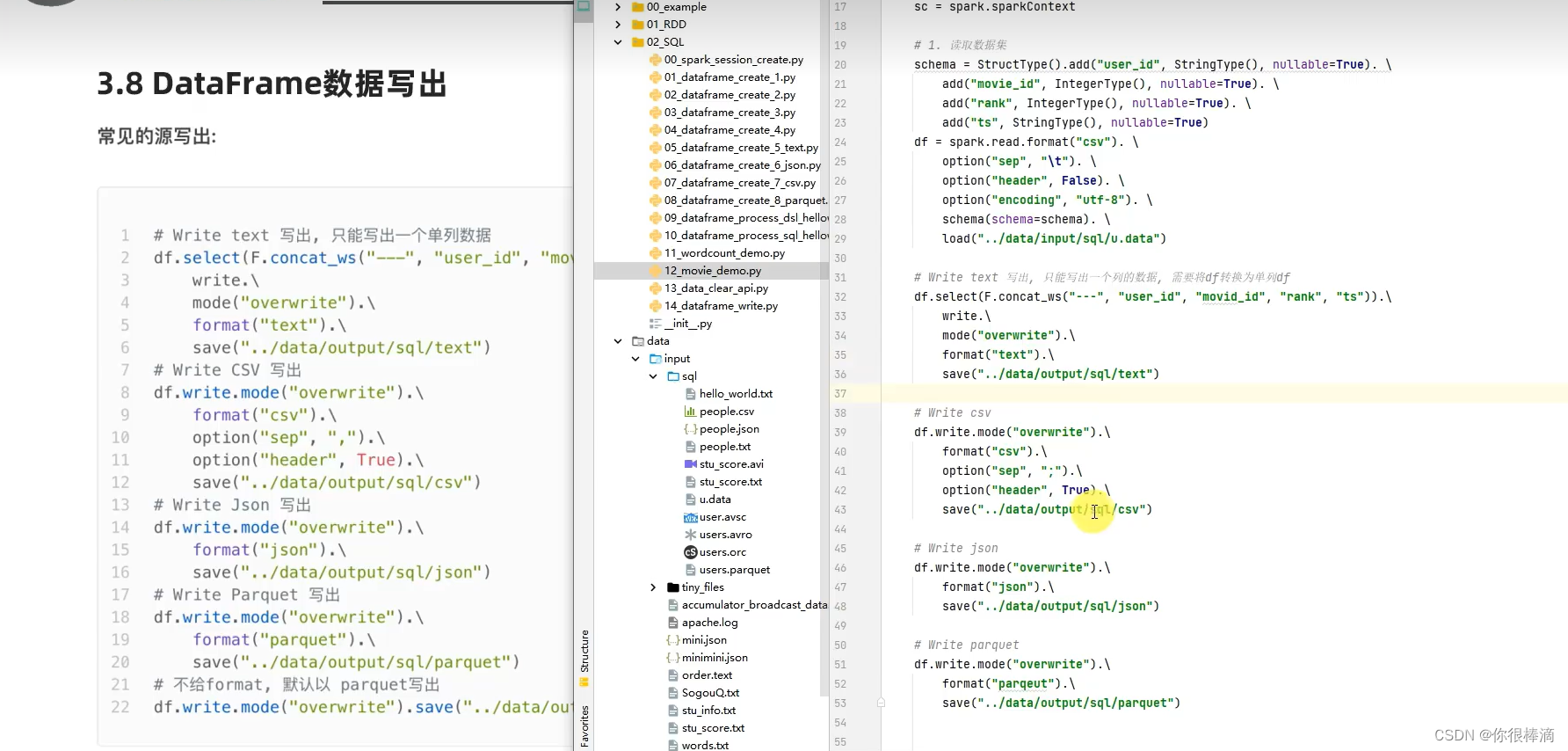
数据的写出(text,csv,json,parqeut)
DSL函数用法汇总
agg,是GroupData对象的api,作用是可以写多个聚合
alias,是column对象的api,可以针对一个列,进行改名
withColumnRenamed,是DataFrame的api,可以对DF的列进行改名,一次改一列,改多列可用链式调用
orderBy,DataFrame的api,进行排序参数1是要排序的字段,参数2是升序降序
first,DataFrame的api,去除DF的第一行数据,返回值是一个Row对象.是一个数组类型,用row[‘列名’]来取出当前值
df.dropDuplicates.show() 去重函数,无参数时是对所有列去重,可以加入参数对指定列去重dropDuplicates([‘age’])
df.dropna().show() 删除空值,dropna(thresh=2,subset=[‘name’,‘age’])这两列如果数据没有两列就会被删除
df.fillna().show() 把空值填充fillna({‘name’:‘未知姓名’,‘age’:1}),把名字那栏空值填为未知姓名,age为1
spark.sql.shuffle.partitions参数的设置
spark = SparkSession.builder.appName('test').master('local[*]').config('spark.sql.shuffle.partitions',2).getOrCreate()
设置参数的意义是提高local模式下的性能,yarn集群下要根据cpu核数的2~4倍进行设置.