广播变量broadcast
使用场景:本地集合变量和分布式变量(rdd)进行关联的时候使用
优点:1.可以节省io操作.2.减少executor的内存占用
#定义
map_list = {(1,'dawang',22),(2,'xiaogou',333).....}
broadcast = sc..broadcast(map_list)
#使用
for i in broadcast.value:
print(i)
累加器accumulator
使用注意事项:当rdd重新生成的时候,accumulator对象会重新累加,所以要在执行action算子之前,对当前rdd进行缓存rdd.cache()
from pyspark import SparkConf, SparkContext, StorageLevel
from operator import add
if __name__ == '__main__':
# 1.通过sparkcof创建conf对象
conf = SparkConf().setAppName('test').setMaster('local[*]')
# 2.生成sc对象
sc = SparkContext(conf=conf)
# spark提供的参数,参数是初始值
aclator = sc.accumulator(0)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7], 2)
def add_num(data):
global aclator
aclator += 1
rdd2 = rdd.map(add_num)
rdd2.cache()
rdd2.collect()
rdd3 = rdd.map(lambda x: x)
rdd3.collect()
DAG-执行流程图
特点:有向无环图
对应关系:1个action=1个job=1个DAG
当代码不在多个分区进行交互的时候,只会产生一个DAG,当执行聚合函数的时候,DAG就会在多个分区内相互交错.产生复杂的DAG
DAG的宽依赖(shuffle)和窄依赖
看rdd在dag中是否有分叉,有分叉就是宽依赖,没有的就是窄依赖,遇到宽依赖就会产生一个stage.stage内部是窄依赖.
spark如何做内存计算,DAG的作用?stage阶段划分的作用?
spark运行会产生DAG,DAG根据宽窄依赖来划分stage,如果都是窄依赖,DAG就会在一个长管道中进行内存计算.一个个管道就是一个个task,一个task对应一个线程,线程之间走的就是内存计算.
DAG的作用就是为了内存计算,stage划分的作用是为了构建内存计算管道.

spark为什么比mapreduce快?
- spark算子丰富,mapreduce只有map和reduce两个算子.
- mapreduce是在磁盘上进行交互,遇到复杂的极端涉及的磁盘交互会更多.运算就会变慢.
- spark可以走内存迭代计算,算子之间形成DAG,DAG根据宽窄依赖划分出阶段,单一阶段内形成内存管道迭代.
spark并行度
先有并行度,然后由并行度扩展成分区.
集群中如何规划并行度,一般是cpu核心的2~10倍.

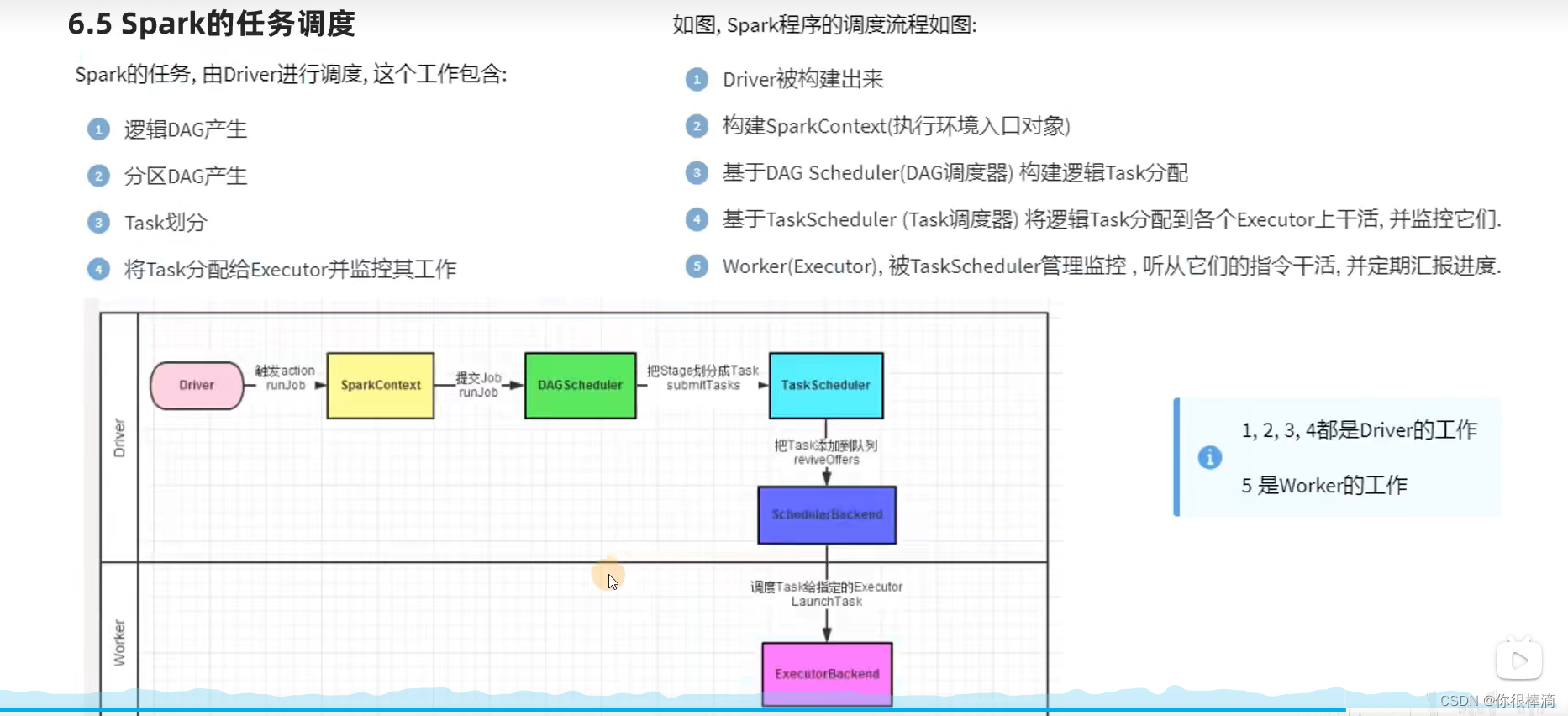
spark的任务调度过程
- 逻辑DAG的产生
- 分区DAG的产生
- task分区任务的产生
- 将task分散给executor并监控其工作(worker的工作,上面三个是driver的工作)
spark层级关系梳理
wordcount程序就相当于一个application.

DAG的知识总结
DAG有什么用?
DAG是有向无环图,用于描述任务执行流程,主要协助DAG调度器构建task,分配用作任务管理
内存迭代的划分
基于款窄依赖进行阶段划分,阶段内部都是窄依赖可以构建内存迭代的管道.
DAG调度器的作用
构建task分配用做任务管理