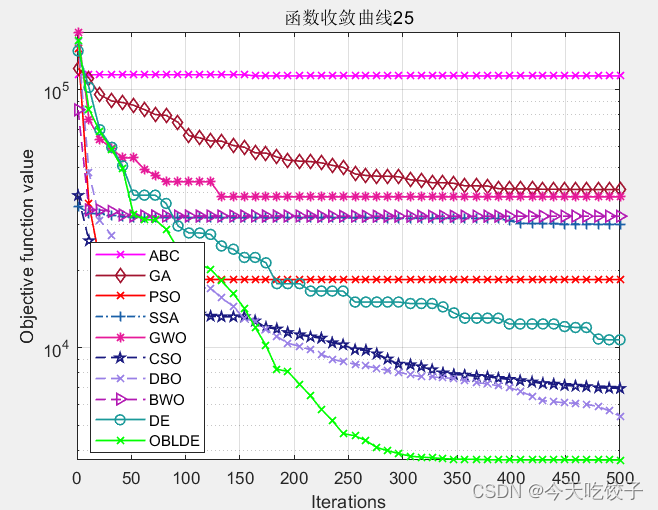
修改公司老代码的时候,发现阿里编码规约插件提示HashMap初始化时尽量指定初始值大小,因为设置合理的初始值可以提升性能:

HashMap继承自AbstractMap类,实现了Map、Cloneable、java.io.Serializable接口,是基于散列表实现的双列集合,它存储的是key-value键值对映射,每个key-value键值对也被称为一条Entry条目。其中的 key与 value,可以是任意的数据类型,其类型可以相同也可以不同。但一般情况下,key都是String类型,有时候也可以使用Integer类型;value可以是任何类型。并且在HashMap中,最多只能有一个记录的key为null,但可以有多个value的值为null。HashMap中这些键值对(Entry)会分散存储在一个数组当中,这个数组就是HashMap的主体。
HashMap的实例有两个影响其性能的参数:初始容量和装载因子。容量是哈希表中的桶数,初始容量就是创建哈希表时的容量。负载因子是一种度量方法,用来衡量在自动增加哈希表的容量之前,哈希表允许达到的满度。当哈希表中的条目数超过负载因子和当前容量的乘积时,哈希表将被重新哈希(即重新构建内部数据结构),这样哈希表的桶数大约是原来的两倍。
那么在使用HashMap时要求尽量指定初始值,该指定多少合适?(可以直接跳到后面看结论)
一般来说,初始值大小的设定应该根据实际需要进行设置。另外,也建议将初始值大小设置为2的幂次方,这样可以更好地利用HashMap的内部机制,提高程序的运行效率。
如果不设置,默认值是16。
如我截图的代码,就存放2个变量,初始值设置2,但是设置2真的合理吗?
我们可以看一下HashMap的源码,看看它里面是怎么实现的。
不设置初始值的构造方法:
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}设置初始值的构造方法:
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}this方法的源码:
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}里面的变量和方法,,我加了一些翻译说明:
/**
* The next size value at which to resize (capacity * load factor).
* 翻译:用于调整大小的下一次大小值(容量*负载因子)
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
//默认大小为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* Returns a power of two size for the given target capacity.(翻译:返回给定目标容量的大小为2的幂)
* 这段代码是一个名为 tableSizeFor 的静态方法,它接受一个整数参数 cap,并返回一个整数值。该方法的作用是计算并返回一个用于散列表(hash table)的合适的大小。
*
* 具体来说,该方法首先将 cap 减去 1,然后使用位运算符将结果向右移动,并按位或运算,以清除最低位的 1。
* 这个过程会重复 5 次,每次向右移动的位数为 1、2、4、8 和 16。最后,如果计算出的值小于 0,则返回 1;
* 如果计算出的值大于等于 MAXIMUM_CAPACITY,则返回 MAXIMUM_CAPACITY;否则返回计算出的值加 1。
*
* 这个方法的设计目的是为了在散列表中获得更好的负载因子(load factor),从而减少哈希冲突(hash collision)的概率。
* 负载因子是指散列表中元素的数量与散列表大小的比率。较小的负载因子意味着每个桶(bucket)中存储的元素较少,从而减少了哈希冲突的概率。
* 但是,较小的负载因子也会导致散列表的空间利用率较低。因此,选择合适的散列表大小非常重要。
* @param cap
* @return
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}上面的源码可以看出threshold是个阈值,它的计算是根据tableSizeFor方法来的(根据设置的初始值计算的),到达这个阈值就会触发扩容,扩容是会影响性能的。
再看一下putMapEntries方法的源码,看注释的意思是实现了Map.putAll和Map构造函数:
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}这里面“ float ft = ((float)s / loadFactor) + 1.0F;”就是我们初始值的大小计算方法。
有兴趣的可以看下HashMap源码研究一下。
结论:默认不设置初始值大小,HashMap使用的是默认大小,值为16,如果要指定大小可以根据“存储数据的个数/0.75+1”计算出的结果作为初始值。
最后说明一下上面我的截图代码的问题,设置2是否合理?答案是不合理,根据计算公式得出,设置3是比较合理的。
原因是设置为2,刚好会触发扩容,造成完全没有必要的性能浪费。
参考以下代码,设置为2:
Map<String, String> map = new HashMap<>(2);
map.put("startTime", "");
getMapLength(map);
map.put("endTime", "");
getMapLength(map);结果为:说明进行了扩容

设置为3:
Map<String, String> map = new HashMap<>(3);
map.put("startTime", "");
getMapLength(map);
map.put("endTime", "");
getMapLength(map);结果为:没有进行扩容
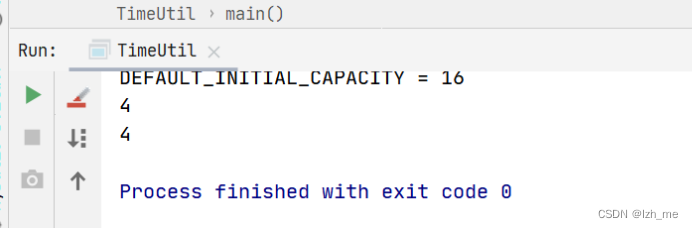
打印Length方法:
/**
* 打印Length
* @param map
* @throws Exception
*/
static void getMapLength(Map<String, String> map) throws Exception {
Field field = HashMap.class.getDeclaredField("table");
field.setAccessible(true);
Object[] elementData = (Object[]) field.get(map);
System.out.println(elementData == null ? 0 : elementData.length);
}PS:关于是否设置初始值影响性能、初始值设置的合理与否影响性能,可以通过测试代码测一下,看看初始化的时间间隔。