一、MyBatis 的使用
1、环境配置
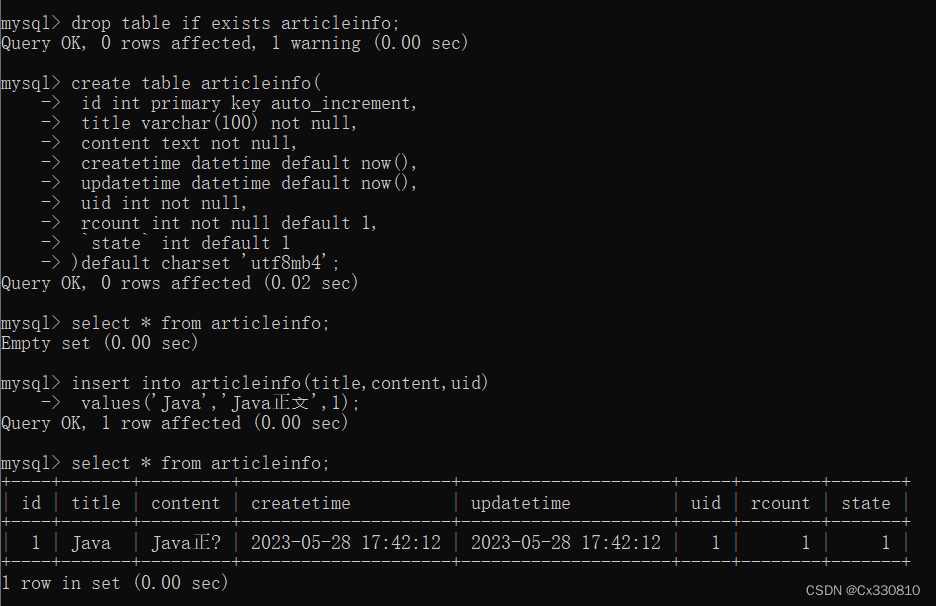
1.1、建库建表
-- 创建数据库
drop database if exists mycnblog;
create database mycnblog DEFAULT CHARACTER SET utf8mb4;
-- 使⽤数据数据
use mycnblog;
-- 创建表[⽤户表]
drop table if exists userinfo;
create table userinfo(
id int primary key auto_increment,
username varchar(100) not null,
password varchar(32) not null,
photo varchar(500) default '',
createtime datetime default now(),
updatetime datetime default now(),
`state` int default 1
) default charset 'utf8mb4';
--添加一个用户信息
INSERT INTO `mycnblog`.`userinfo` (`id`, `username`, `password`, `photo`,
`createtime`, `updatetime`, `state`) VALUES
(1, 'admin', 'admin', '', '2021-12-06 17:10:48', '2021-12-06 17:10:48', 1)
;1.2、安装插件
1.3、插件的使用
1.3.1、已存在的项目中使用
右键点击出现 Generate
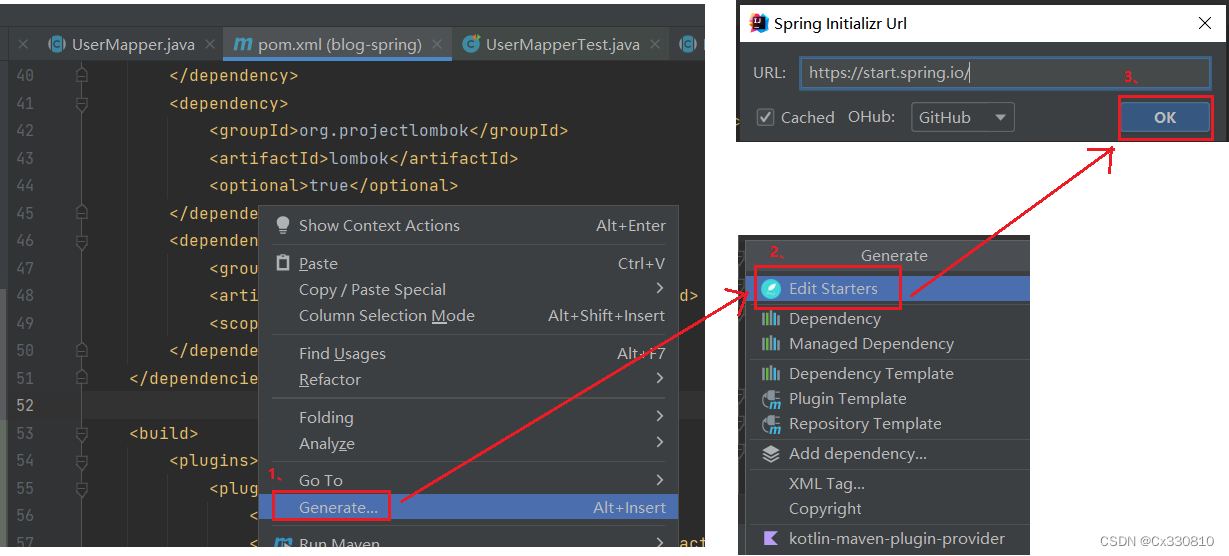
在 SQL中选择相应的依赖:
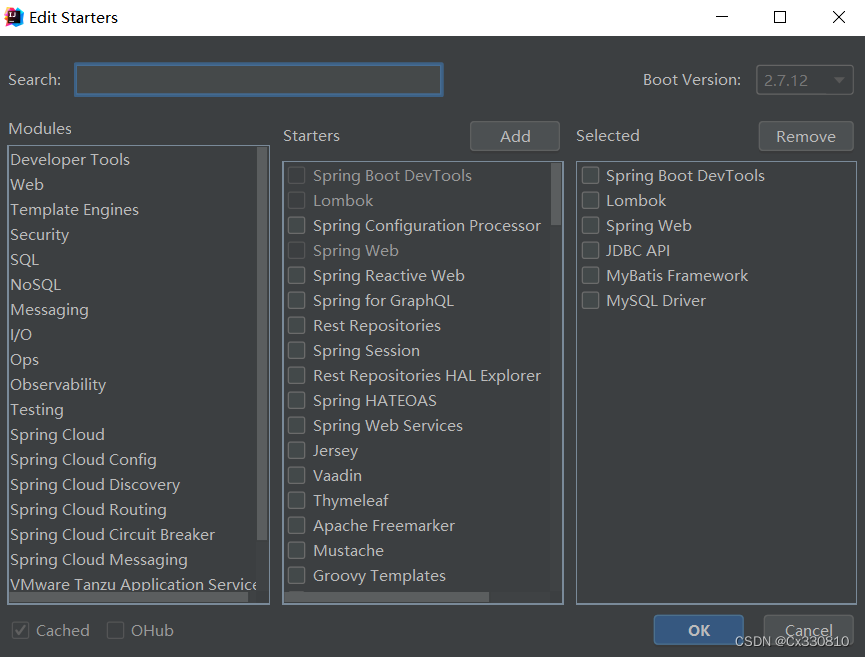 创建好后会显示:
创建好后会显示: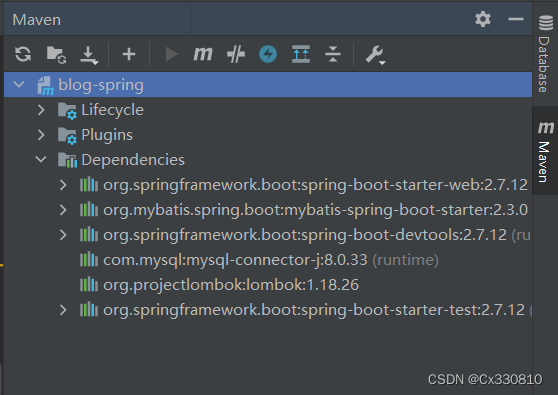
1.3.2、新项目中使用
创建 Spring项目时要注意添加的依赖
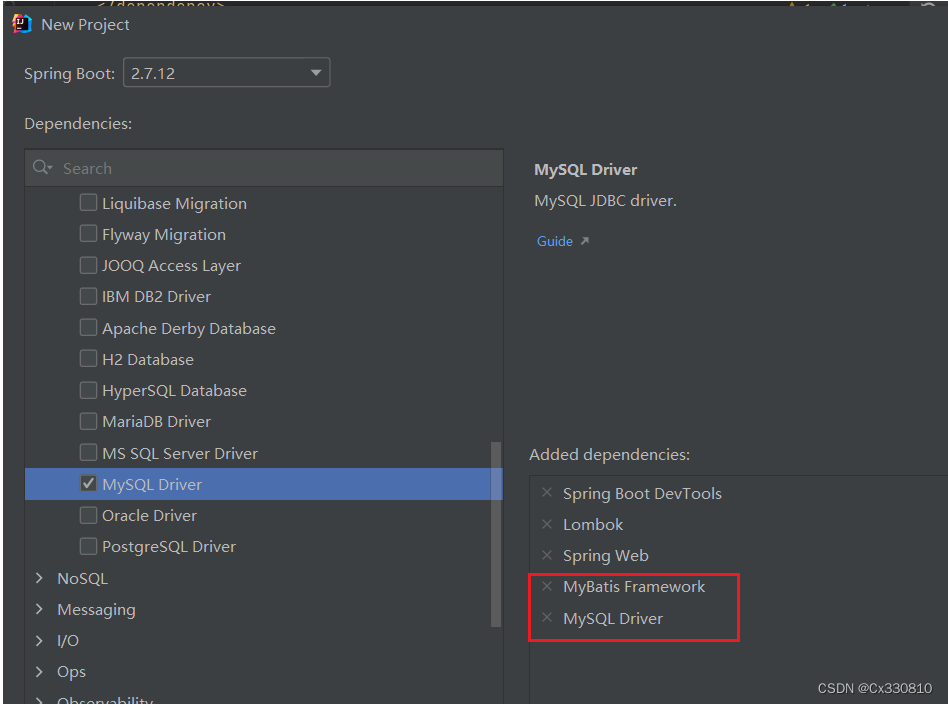
创建好后会显示: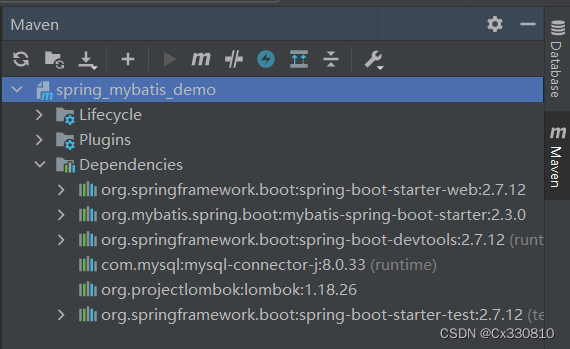
1.4、数据库的配置
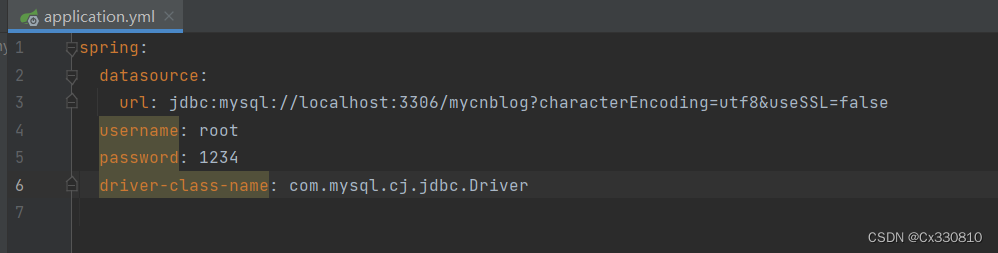
PS:注意:如果使⽤ mysql-connector-java 是 5.x 之前的使⽤的是“ com.mysql.jdbc.Driver ” ,如果是⼤于 5.x 使⽤的是“ com.mysql.cj.jdbc.Driver ” 。
1.5、mybatis xml的配置
# 配置 mybatis xml 的⽂件路径,在 resources/mapper 创建所有表的 xml ⽂件
mybatis:
mapper-locations: classpath:mapper/**Mapper.xml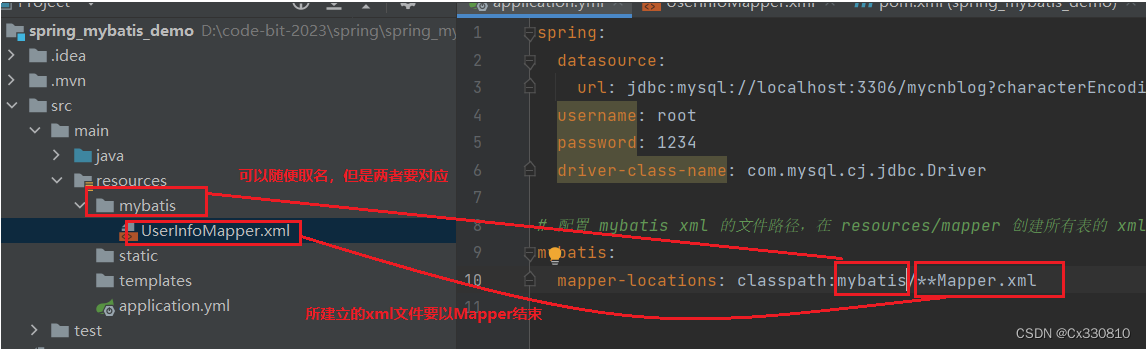
1.6、写 Mapper 文件
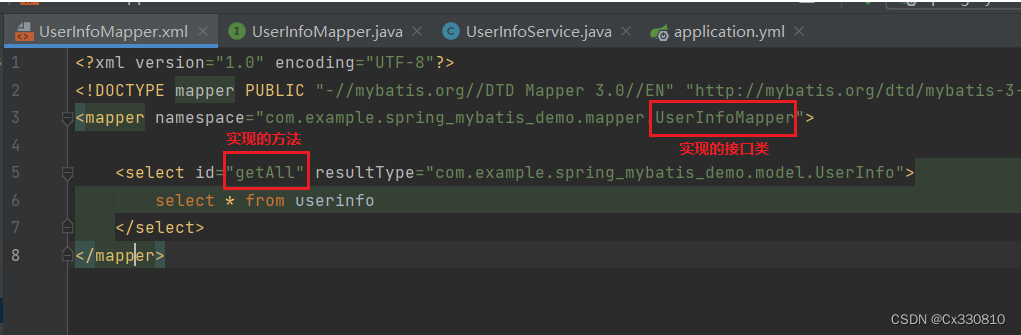
PS: UserInfoMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.spring_mybatis_demo.model.UserInfo">
</mapper>1.6.1、接口
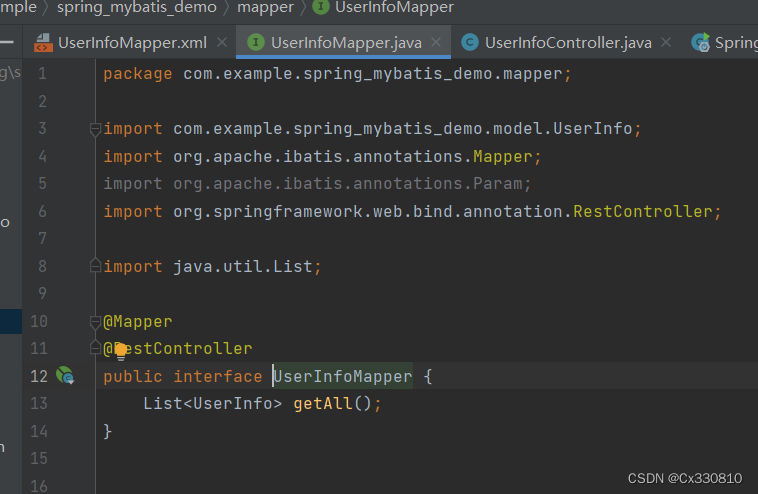
1.6.2、实现
1.7、添加 service
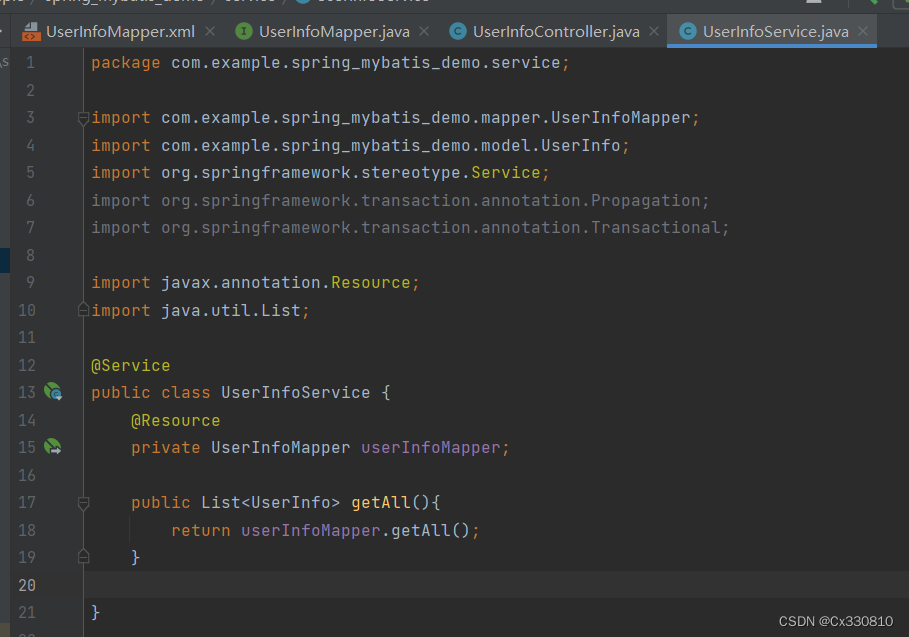
1.8、添加 controller
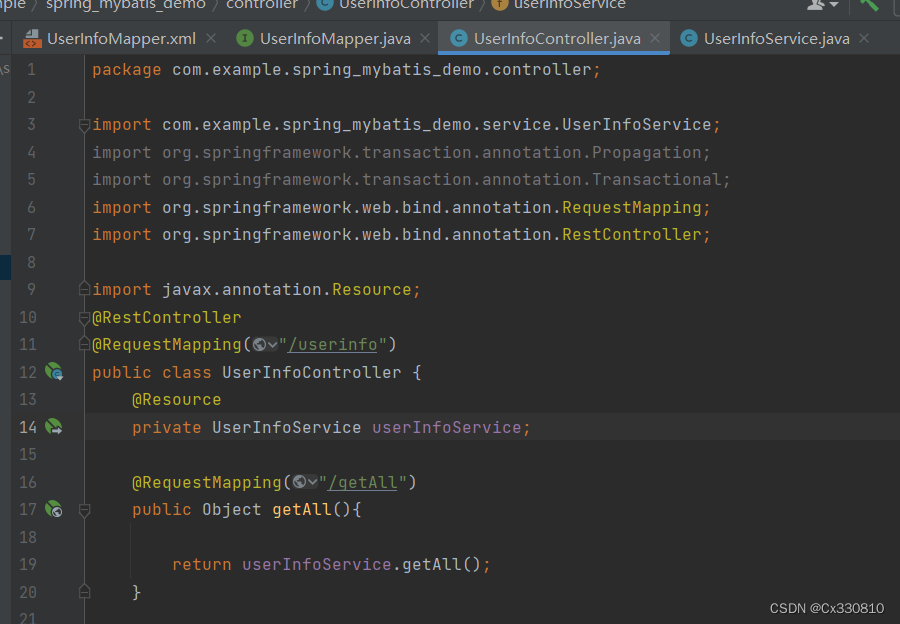
2、使用
2.1、传参
eg 1:
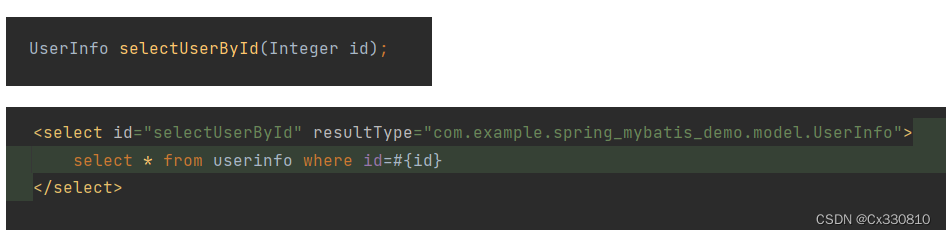
eg 2:
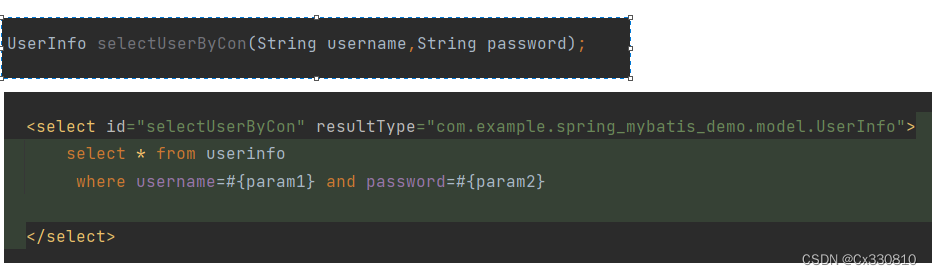
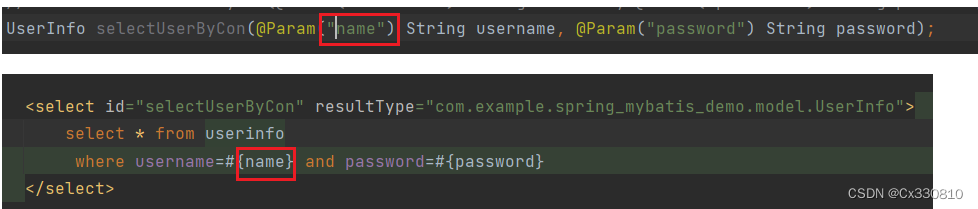
2.2、参数的重命名
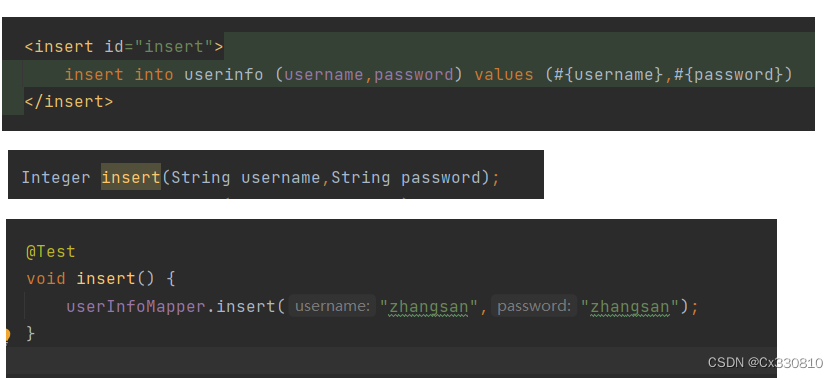
2.3、增
(1)
(2)
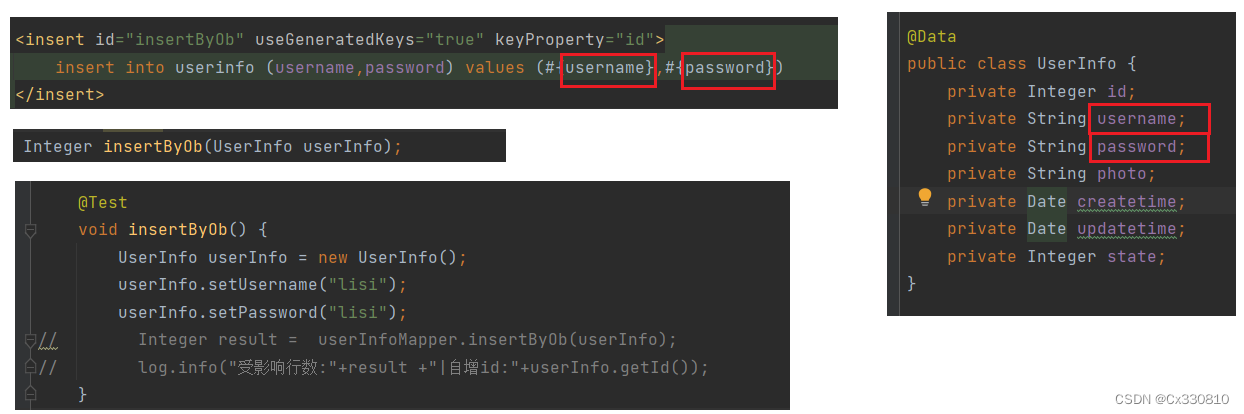
PS:使用对象传参,在 xml 文件中可以注解用属性名字接收参数。
(3)
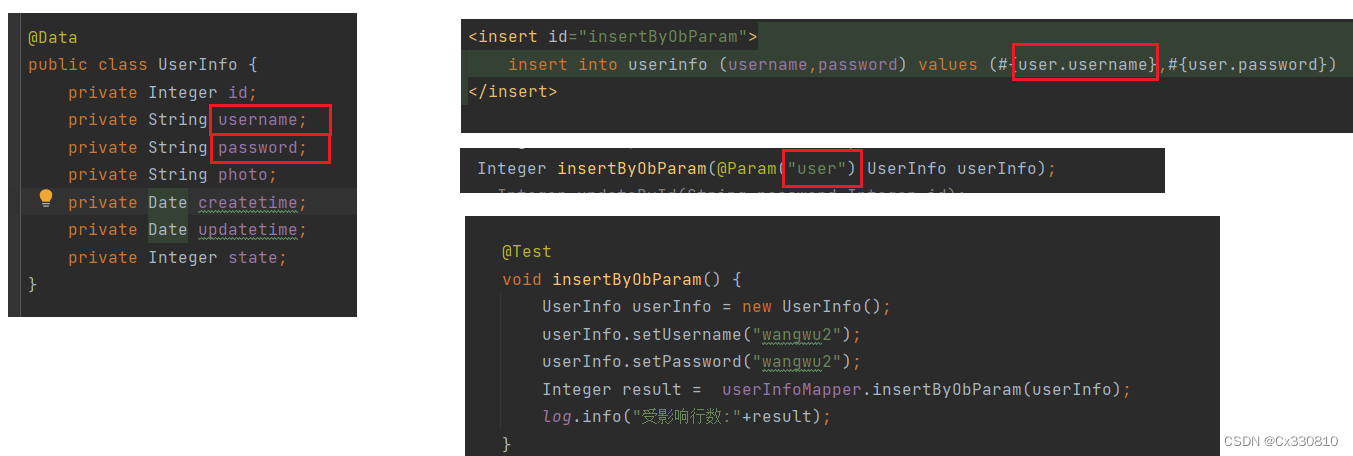
PS:若对参数进行了重命名,在 xml 中接收参数必须要用重命名后的名称,对象使用:参数名(重命名后的).属性名
2.4、改
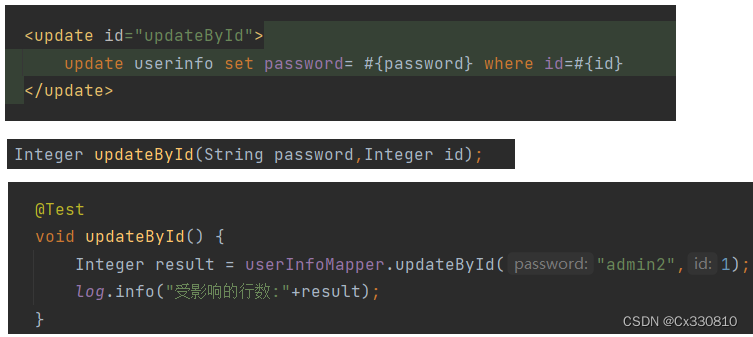
2.5、删
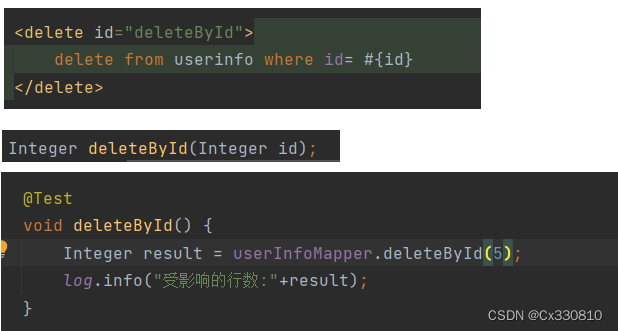
2.6、 参数占位符 # 和 $:
#{ }:预编译处理(MyBatis在处理 #{ }时,会将SQL中的 #{ } 替换为 ?,使⽤ PreparedStatement的 set()来赋值。)。可以解决程序中不安全(越权处理)的问题
${ }:字符直接替换(MyBatis在处理 ${ }时,会将SQL中的 ${ }替换为 变量的值。)。可能会带来越权查询和操作数据等问题。
PS:区别:
(1) #{}
预编译处理,MyBatis在处理 #{ }时,会将SQL中的 #{ } 替换为 ?,是安全的占位符,可以解决程序中的不安全的问题,如越权处理。
(2)${}
字符的直接替换,MyBatis在处理 #{ }时,会将SQL中的 ${ } 替换为变量的值,会带来越权查询和操作数据等问题。使用时,字符串的参数会需加上引号。会存在SQL注入问题。
一般在编写SQL语句时,优先选择#来保证SQL查询的安全性。
在排序是一般会使用$。
在模糊查询时会使用#。
2.6.1、#{ }
表示安全的占位符,可以放置SQL注入攻击。在执行SQL时,MyBatis 会将传入的参数值以安全的方式绑定到编译语句中,自动进行字符串转义等处理。例如:

这里的 #{} 就是使用了 # 占位符,MyBatis 会自动将参数 username 和 password 转换成 PreparedStatement 中的变量,并进行数据类型转换和字符串转义等处理,保证 SQL 查询的安全性。
2.6.2、${ }
$表示简单的字符串替换,不会进行 SQL 注入攻击防范。在执行 SQL 时,MyBatis 会根据传入的值直接进行字符串替换,不做任何处理。例如:

这里的 ${} 就是使用了 $ 占位符,MyBatis 会将传入的参数 username 和 password 直接替换为相应的字符串值,并拼接到 SQL 语句中,这种方式可能会带来安全风险,因此应该尽量避免使用。
2.6.3、SQL注入
(1)概念:
SQL注入是指攻击者通过在Web应用程序中注入恶意的SQL代码,来对数据库进行非法操作的一种安全漏洞。这种攻击方式通常利用了没有经过充分验证和过滤的输入参数,将恶意脚本注入到执行SQL语句的应用程序中,从而导致数据库执行恶意代码而受到攻击。
例如,攻击者可以通过在输入框中注入恶意的SQL代码,并让应用程序把该数据提交给数据库。如果应用程序没有进行严格的校验和过滤,那么数据库就可能执行这些恶意代码,并执行带有恶意目的的SQL语句,比如删除、修改、插入、查询等操作。
(2)$会存在SQL注入问题
使用$时:
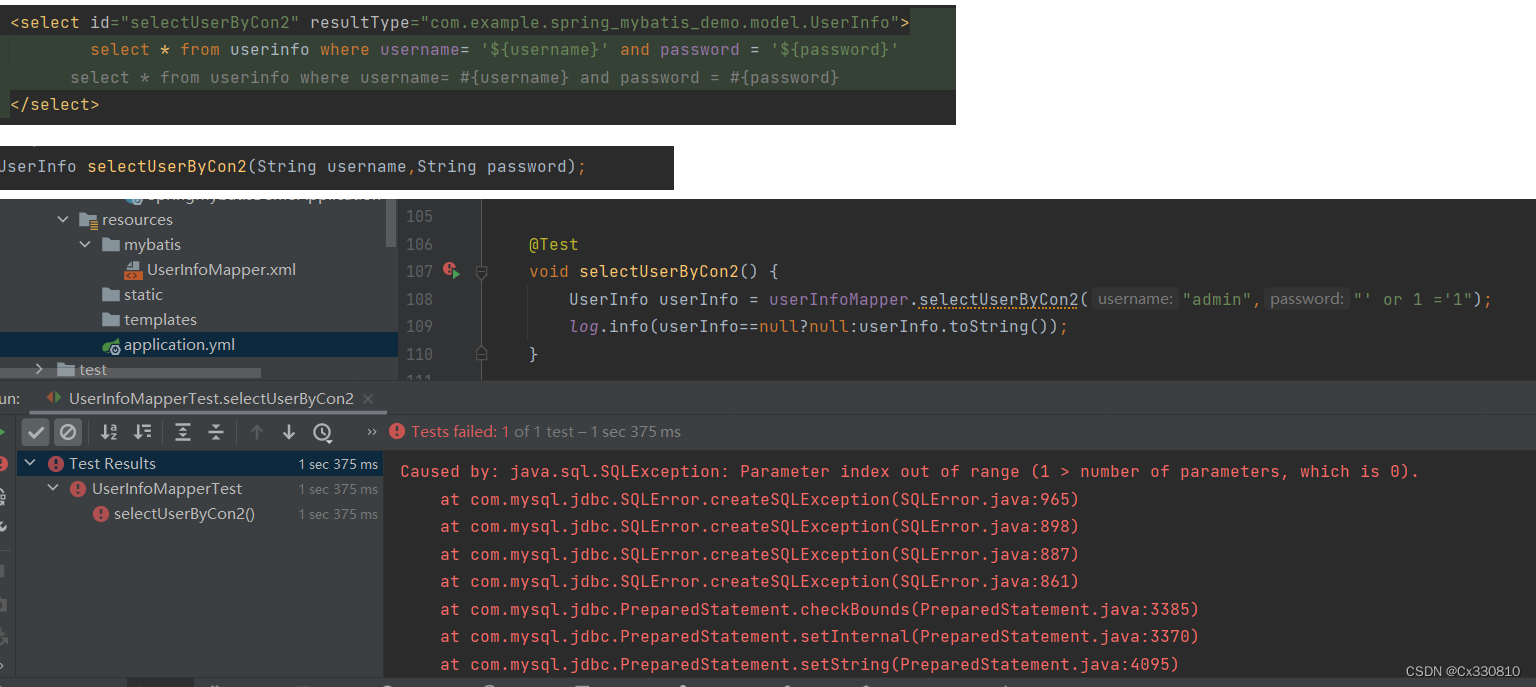
使用#时:
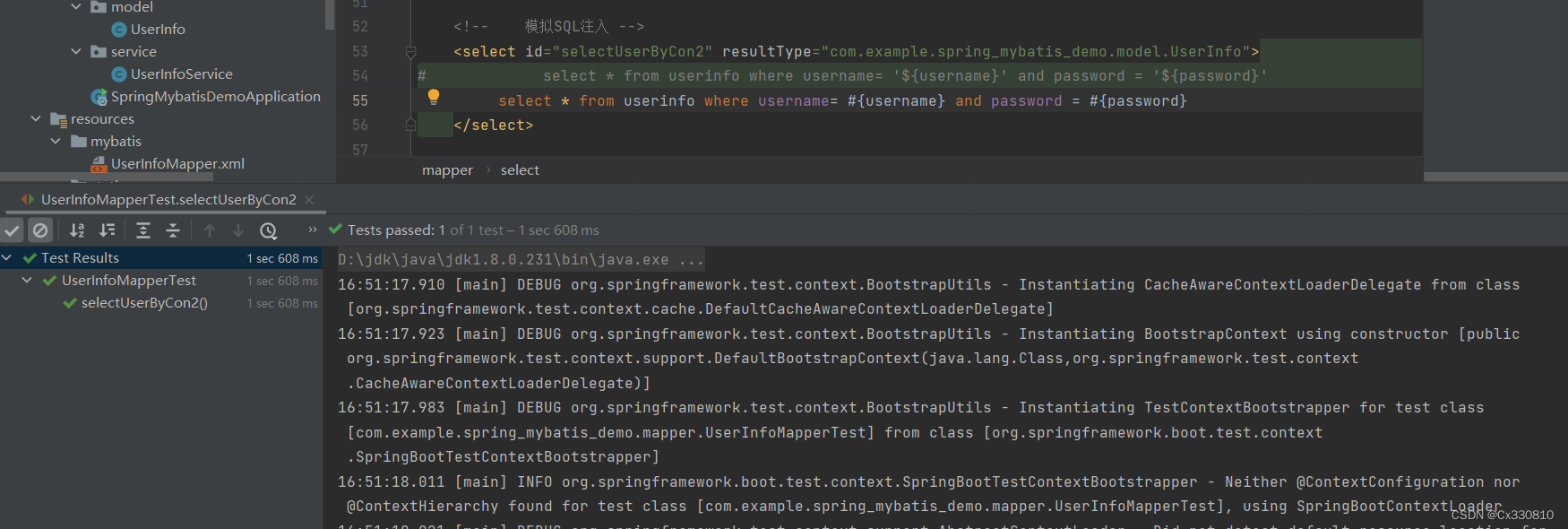
(3)注意:
在编写 MyBatis SQL 语句时,优先使用 # 占位符来保证 SQL 查询的安全性,尽量避免使用 $ 占位符。同时,也需要注意 SQL 注入攻击等安全问题,并采取相应的防范措施。
使⽤ ${sort} 可以实现排序查询,⽽使⽤ #{sort} 就不能实现排序查询了,因为当使⽤ #{sort} 查询时, 如果传递的值为 String 则会加单引号,就会导致 sql 错误。
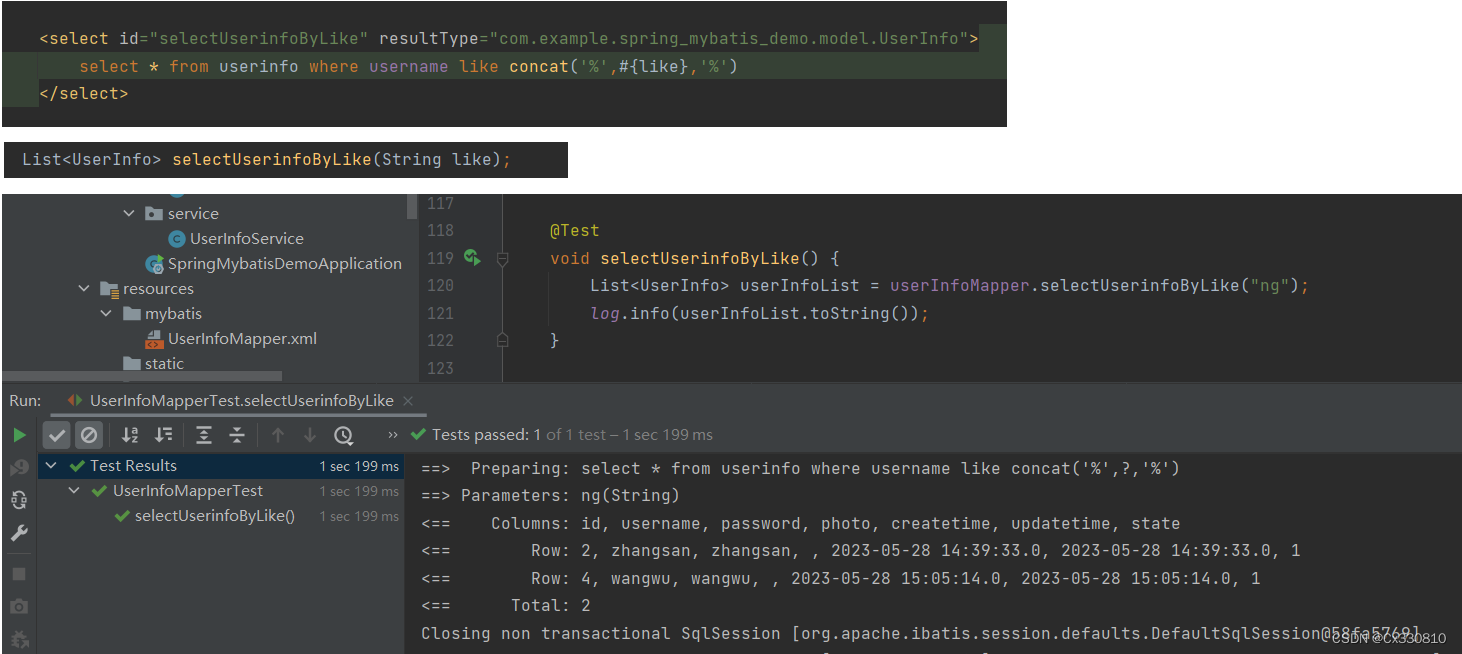
进行模糊查询时,只能使用#,不能使用$。(虽然$也可以查询出结果,但 $ 存在SQL注入问题,所以不能使用)。
PS:模糊查询需要使用内置函数 concat
2.7、多表查询
2.7.1、相关配置
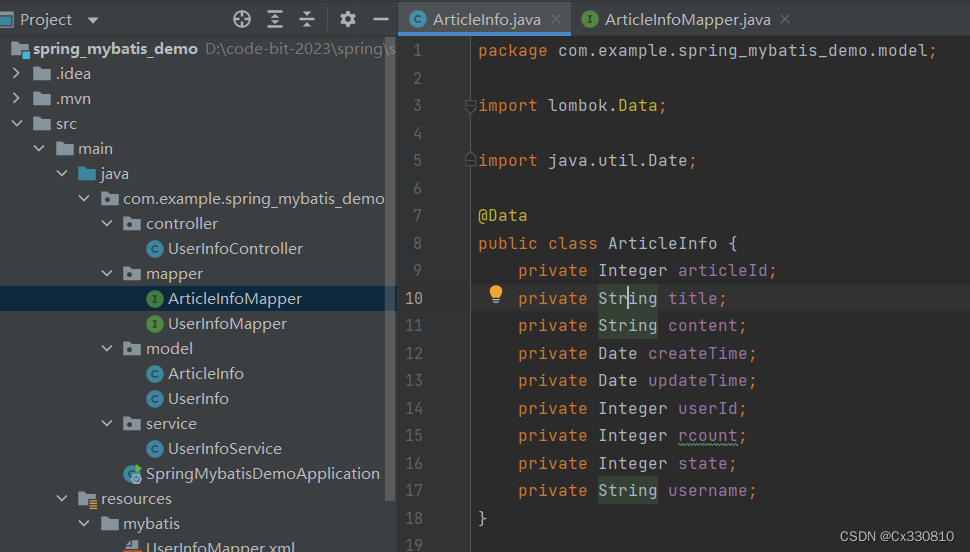
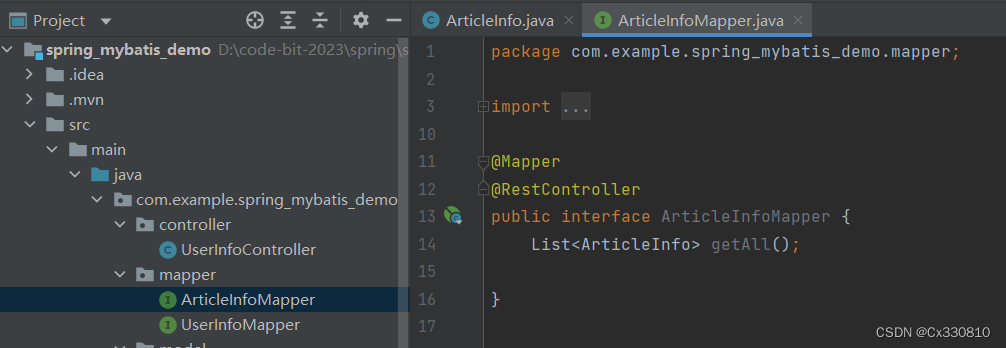
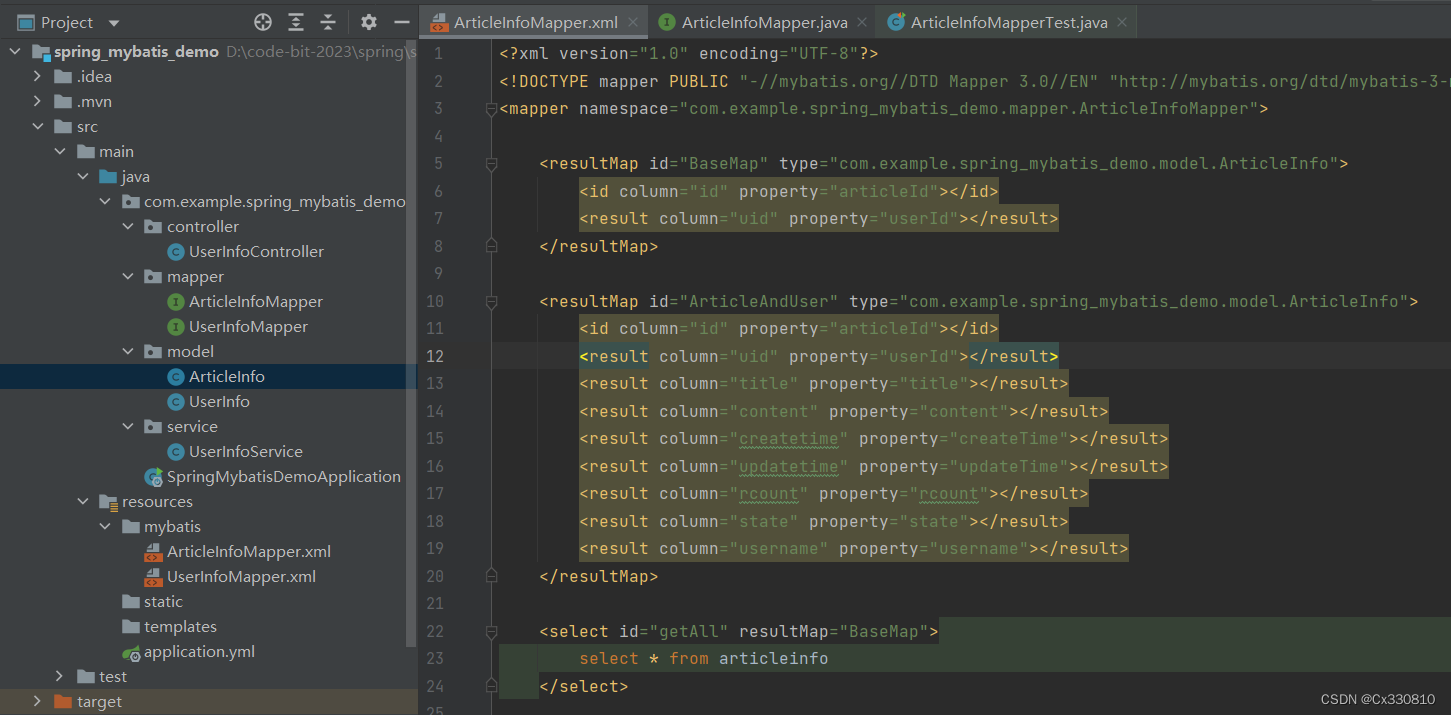
PS:当Java字段名和属性名不同时可以使用 resultMap :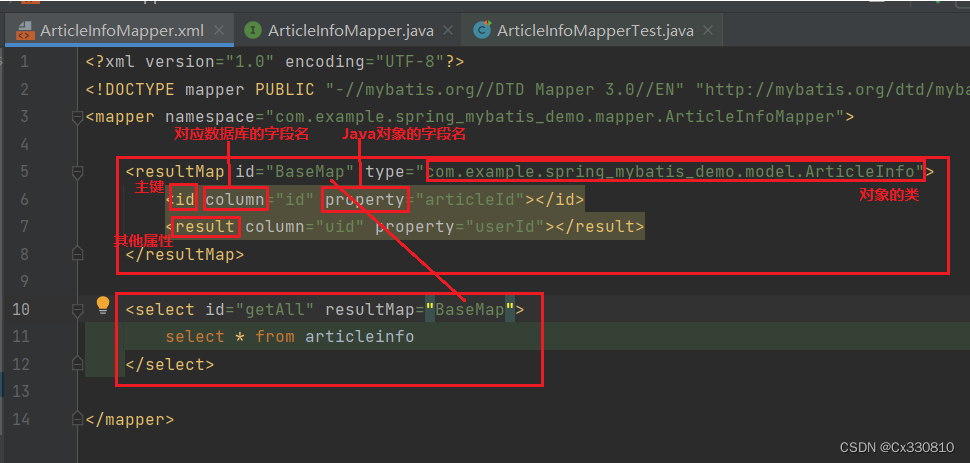
2.7.2、多表查询
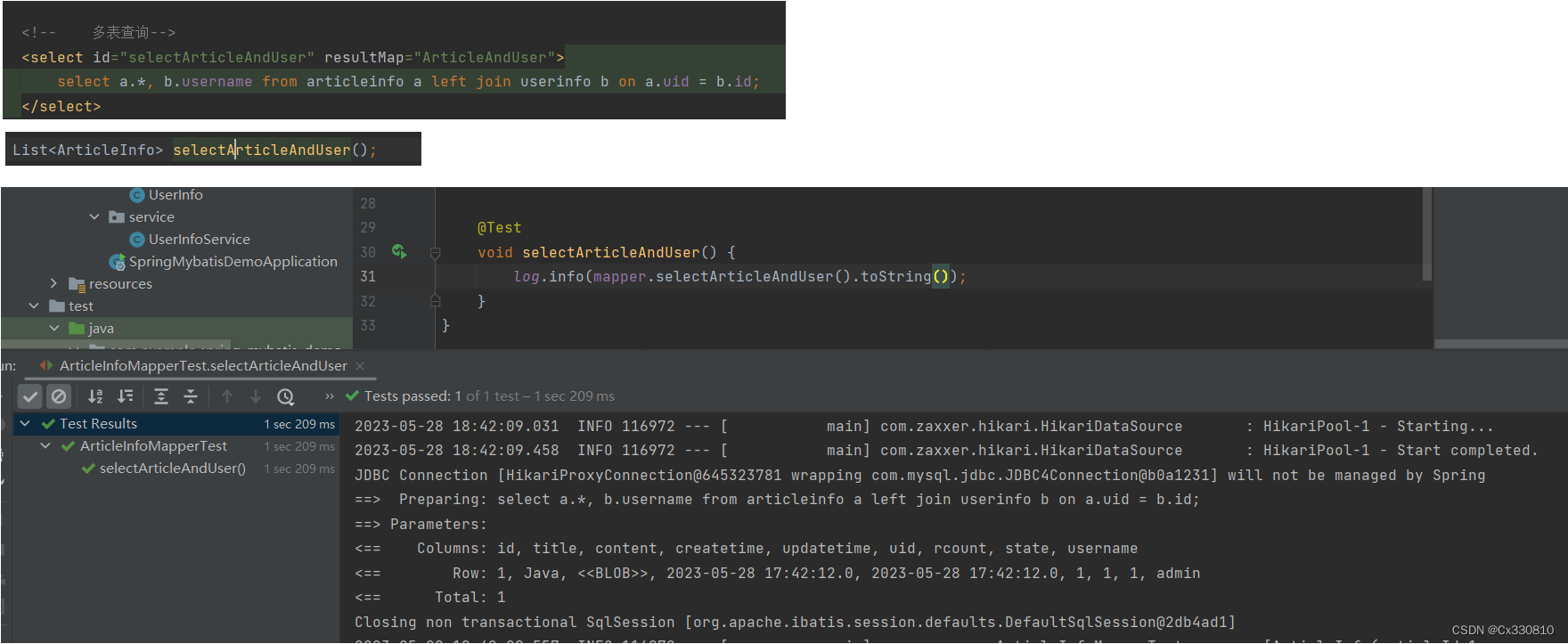
2.8、动态SQL
2.8.1、<if>标签:出现必填字段和非必填字段时
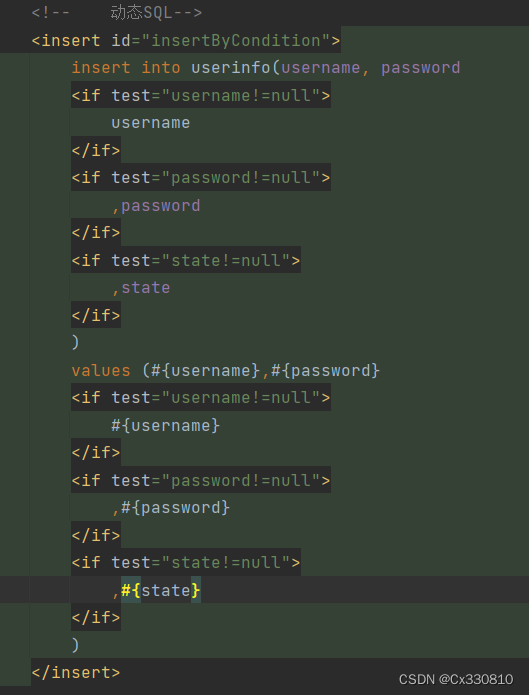
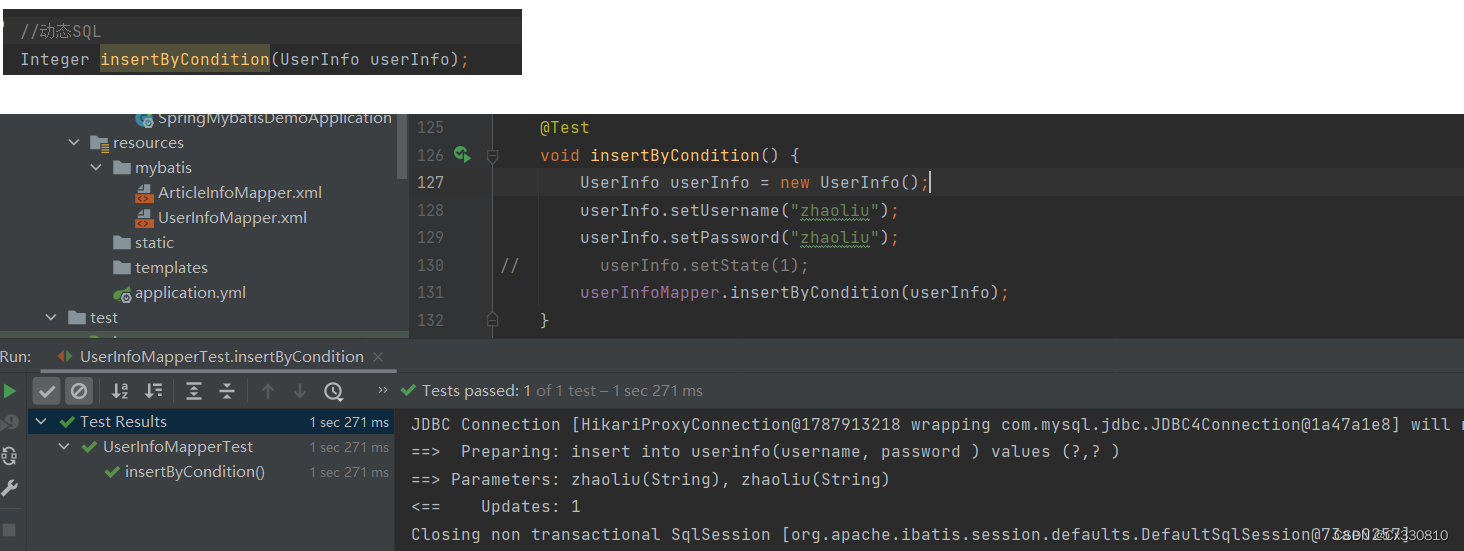
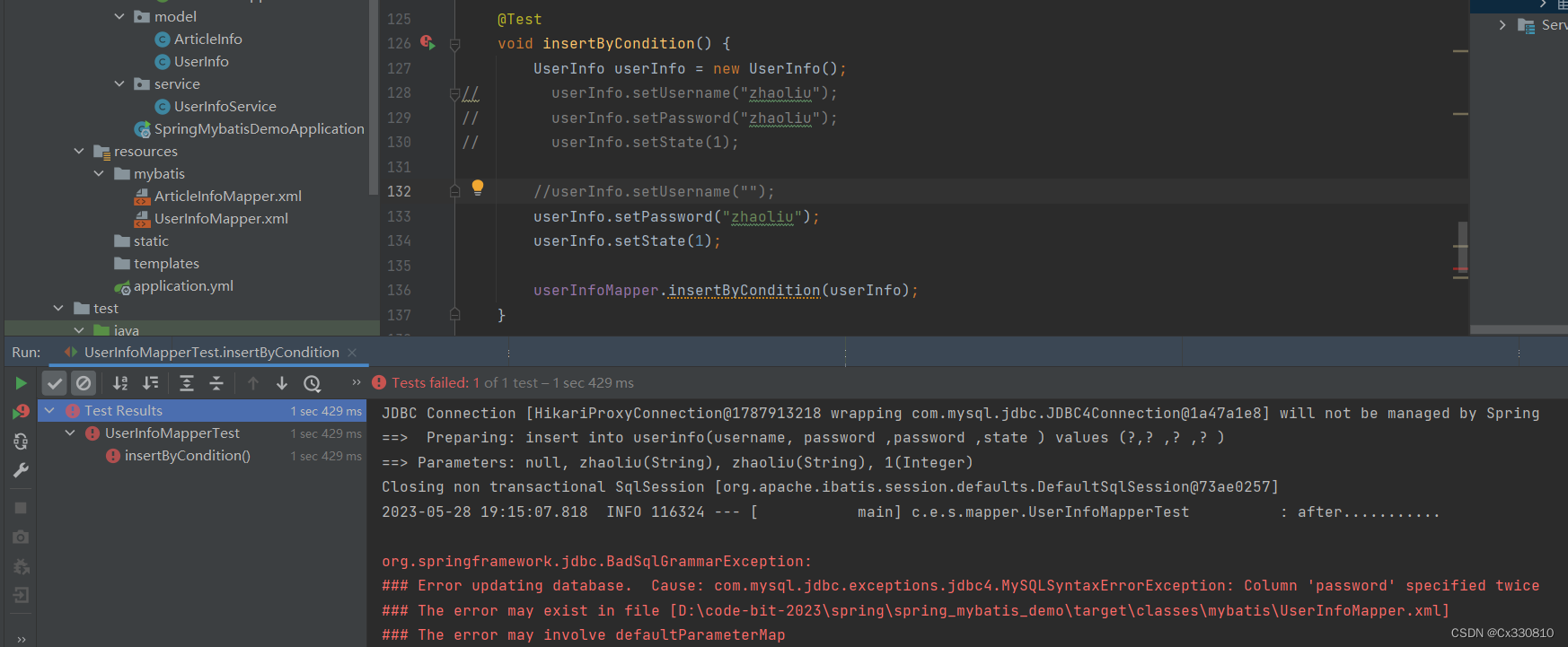
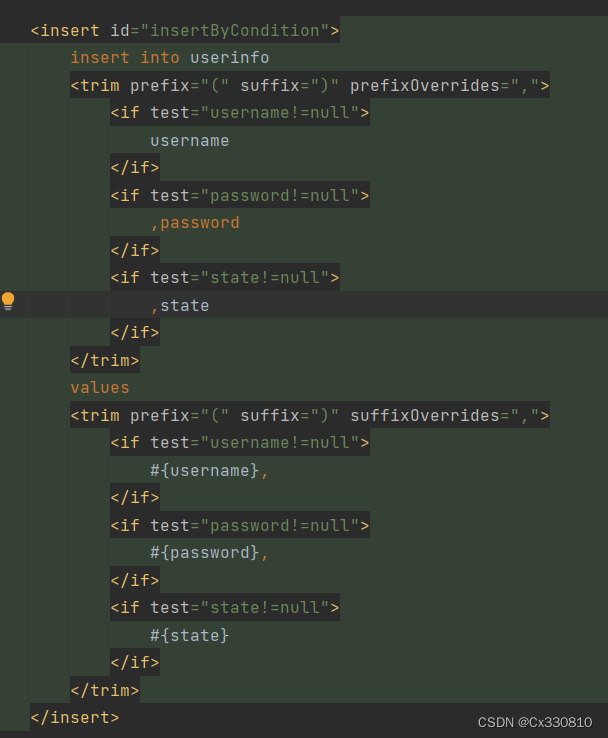
2.8.2、<trim>标签:一般和 if 标签一起使用(对多个字段采取动态生成)

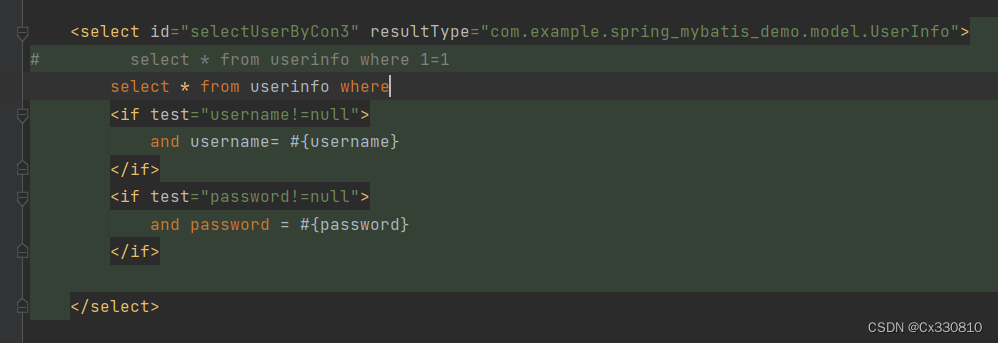
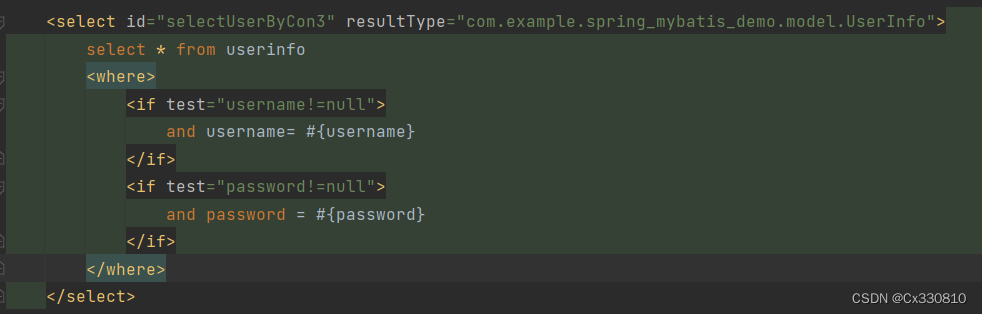
2.8.3、<where>标签:生成where 关键字;去掉多余的 and (传入的对象根据属性做where条件查询,用户对象中属性不为null的都为查询条件)
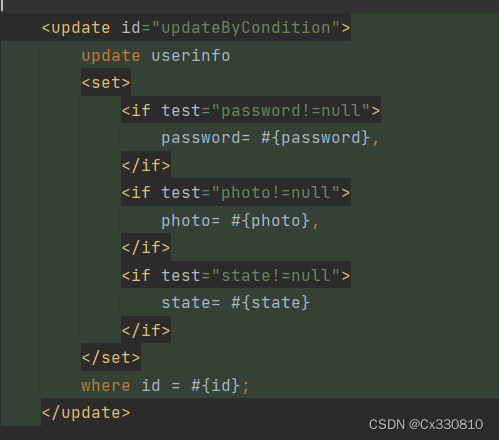
2.8.4、<set>标签:生成set关键字;去除掉多余的逗号 (根据传入的用户对象属性来更新用户数据,可用set标签来指定动态内容)
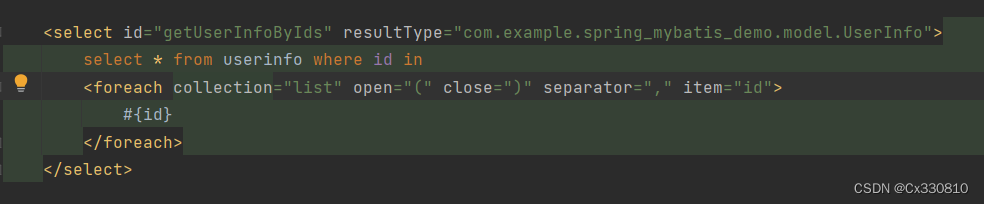
2.8.4、<foreach>标签:循环(对集合进行遍历)
二、Spring AOP
1、基础
1.1、认知
1.1.1、
OOP:面向对象编程
AOP:面向切面编程。是一种思想,是对某一类事情的处理。Spring AOP 是AOP的一个实现。
IOC:控制反转
1.1.2、用处
(1)使用AOP可以扩充多个对象的某种能力(因此AOP可以说是OOP的补充和完善)
(2)对于功能统一且使用地方较多的功能,可以考虑AOP来统一处理。例如:
统一的用户登录判断;统一的日志记录(每个方法都记录操作用户、时间);统一方法执行时间统计(记录每个方法的执行时间);统一的返回格式设置;统一的异常处理(如后端代码的空指针异常、数据越界异常、内存溢出等);事务的开启和提交等。
1.2、AOP的组成
切面:切点+通知。
切点:描述某些方法会有一个规则,这个规则就是切点,根据切点可以获取到连接点。
连接点:对一些具体的方法进行统一事情的处理,这些具体的方法就是规则,根据规则可以指定哪些方法。
通知:具体要做的事。
通知分为前置通知(使用@Before,通知方法会在目标方法调用前执行)、后置通知(使用@After,会在目标方法返回或抛出异常后调用)、返回通知(使用@AfterReturning,会在目标方法返回后调用)、异常通知(使用@AfterThrowing,在目标方法抛出异常后调用)和环绕通知(使用@Around,通知包裹了被通知的方法,在被通知的方法通知之前与调用之后执行自定义)等几种类型。
eg:某班同学要考试,该班有50人:
其中,(某班同学要考试)是切面,(某班同学)是切点,(要考试)是通知,这(50人)是连接点。
eg:多个页面访问用户登录:
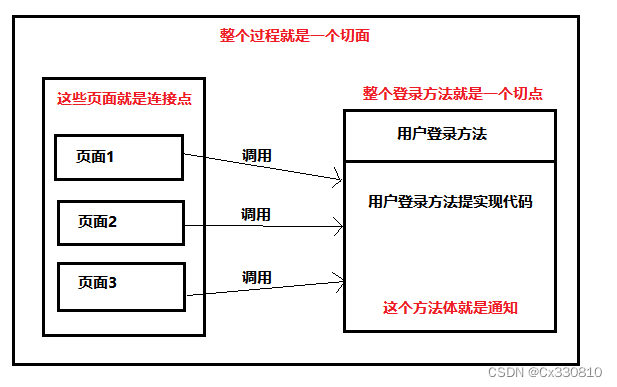
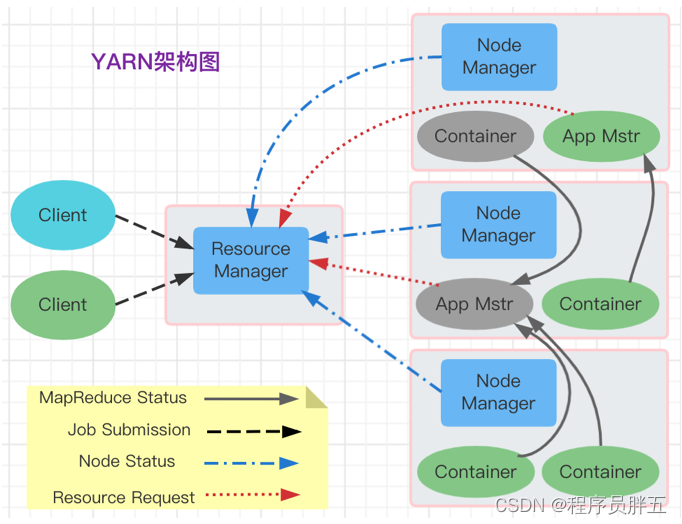
2、 Spring AOP 的实现原理
2.1、
Spring AOP 是构建在动态代理基础上,因此 Spring 对 AOP的支持局限于方法级别的拦截。
Spring AOP支持 JDK Proxy 和CGLIB 方式实现动态代理。默认情况下,实现了接口的类用AOP会基于JDK生成代理类,没有实现接口的类会基于CGLIB 生成代理类。
2.2、JDK 和 CGLIB 实现的区别:
JDK 实现,要求被代理类必须实现接⼝,之后是通过 InvocationHandler 及 Proxy,在运⾏
时动态的在内存中⽣成了代理类对象,该代理对象是通过实现同样的接⼝实现(类似静态代
理接⼝实现的⽅式),只是该代理类是在运⾏期时,动态的织⼊统⼀的业务逻辑字节码来完
成。CGLIB 实现,被代理类可以不实现接⼝,是通过继承被代理类,在运⾏时动态的⽣成代理类
对象。
3、Spring AOP 的代码实现
3.1、添加 Spring AOP框架支持
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
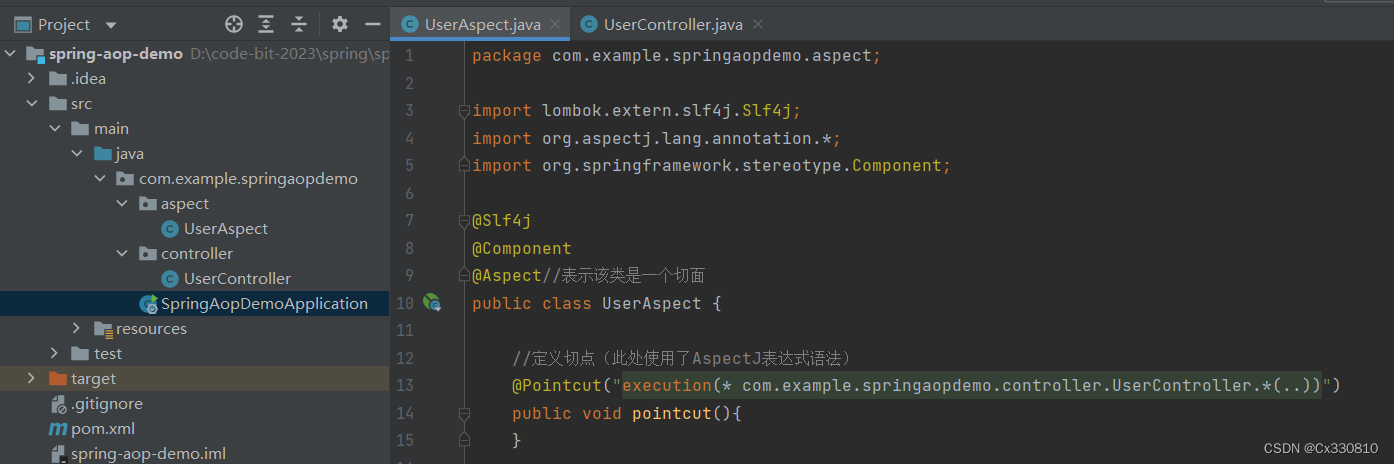
</dependency>3.2、定义切面和切点
3.3、定义通知
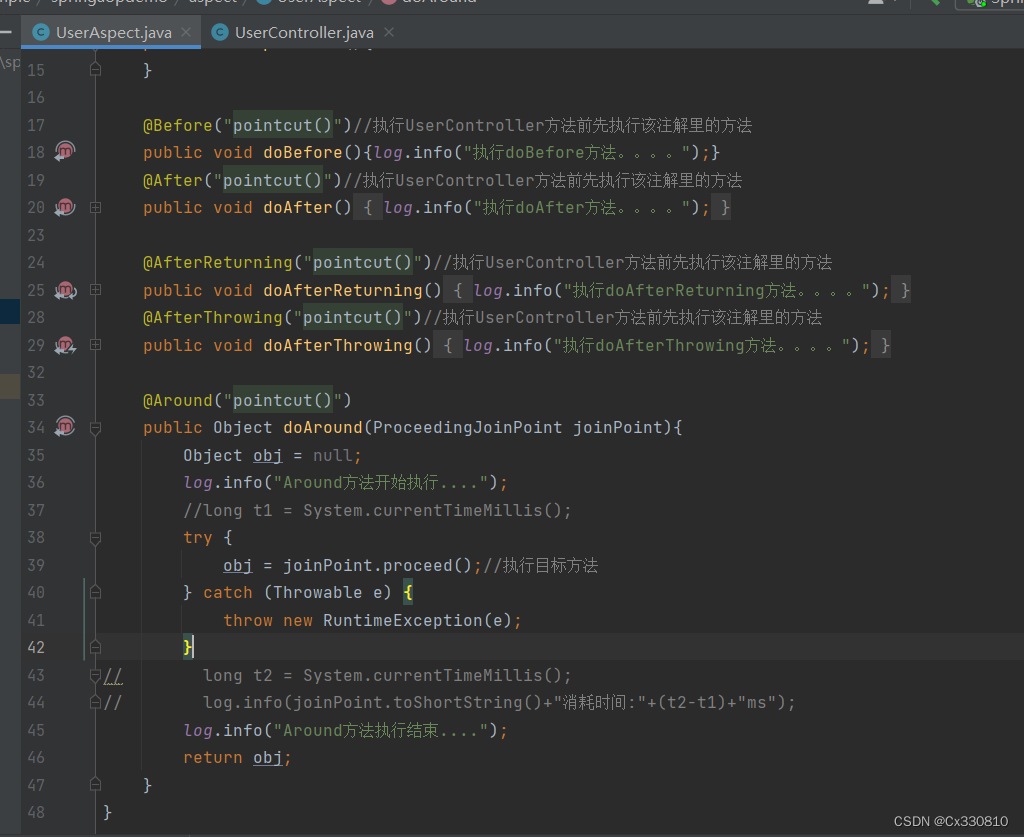
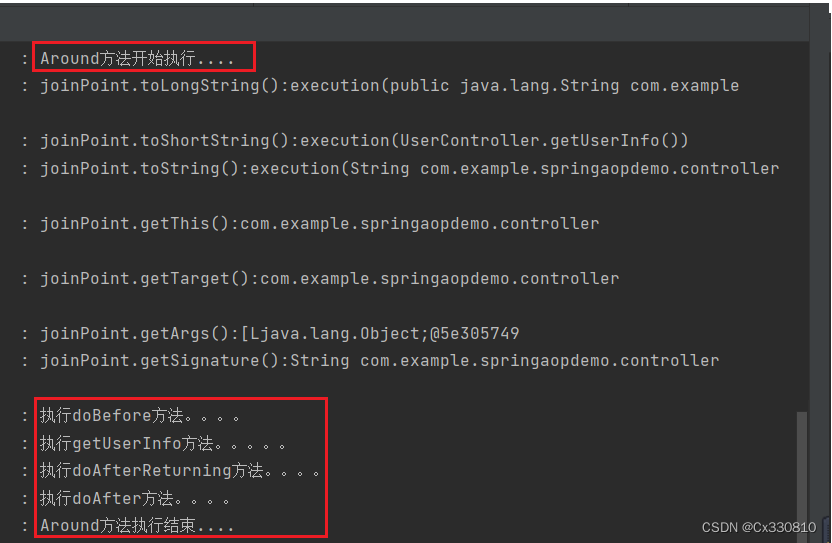
PS:
AfterReturning 与After 同时存在时会先执行AfterReturning。
AfterThrowing 与After 同时存在时会先执行AfterThrowing。
PS: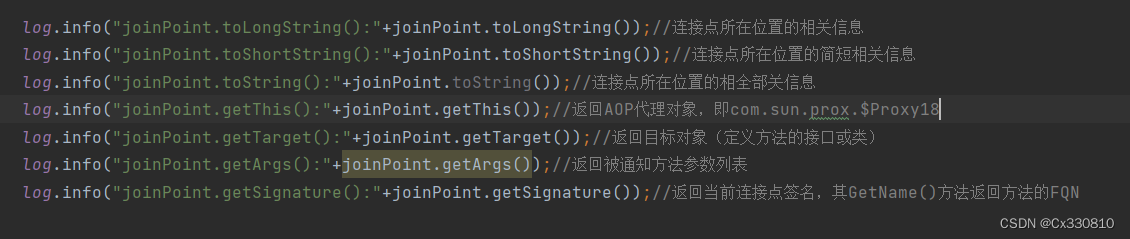
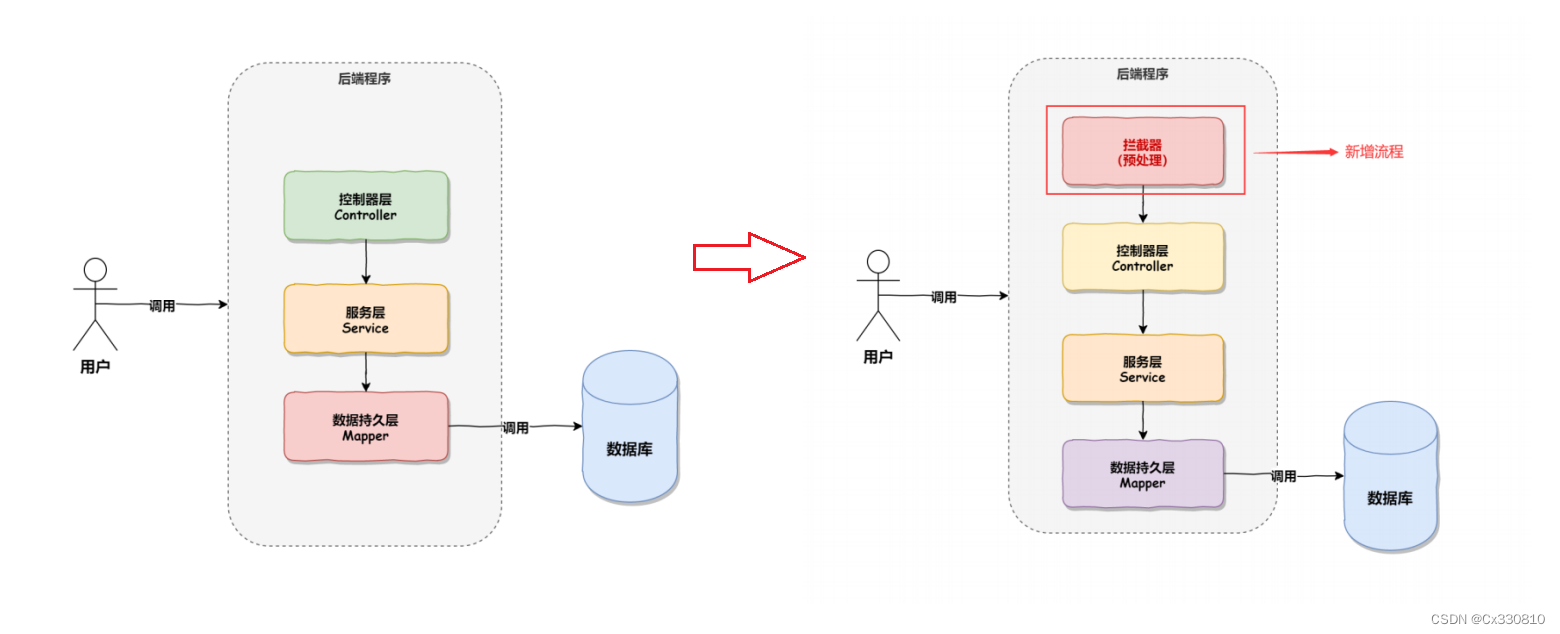
4、拦截器
基于AOP实现的。要对一部分方法进行拦截,另一部分方法不进行拦截。
4.1、实现:
4.1.1、创建自定义拦截器
@Slf4j
@Component
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断用户是否登录
log.info("执行拦截方法...");
HttpSession session = request.getSession();
if (session!=null && session.getAttribute("userinfo")!=null){
return true;
}
response.setStatus(401);
return false;
}
}4.1.2、将自定义拦截器加入到系统配置中
@Configuration
public class AppConfig implements WebMvcConfigurer {
@Autowired
private LoginInterceptor loginInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loginInterceptor)
.addPathPatterns("/**")//拦截哪些路径
.excludePathPatterns("/reg")//排除哪些路径
.excludePathPatterns("/login");
}
}PS:以上拦截规则可以拦截该项目中的所有URL,包括静态文件(图片文件、JS、CSS等)
PS:排除所有静态资源
// 拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
.addPathPatterns("/**") // 拦截所有接⼝
.excludePathPatterns("/**/*.js")
.excludePathPatterns("/**/*.css")
.excludePathPatterns("/**/*.jpg")
.excludePathPatterns("/login.html")
.excludePathPatterns("/**/login"); // 排除接⼝
}4.2、实现原理
5、统一处理功能
5.1、统一异常处理
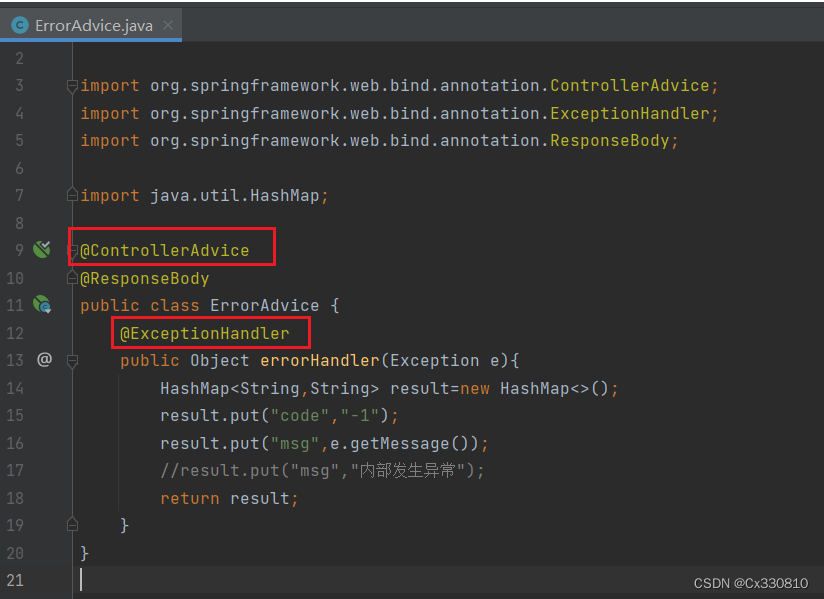

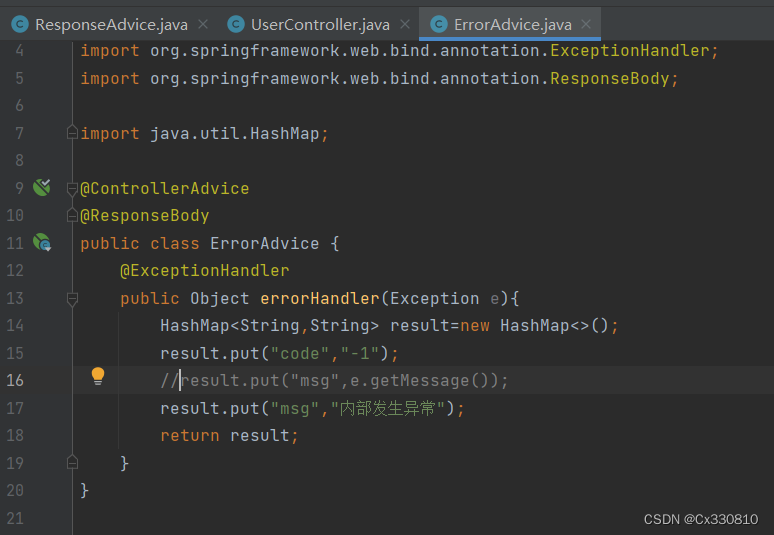
5.2、统一数据返回
5.2.1、统一数据格式返回
接口内容:返回所有的用户
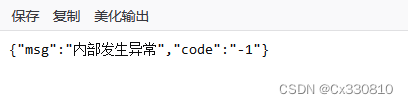
PS:会存在一个情况,返回的结果为 null 。原因可能为:系统发生了异常;没有用户
5.2.2、统一数据返回
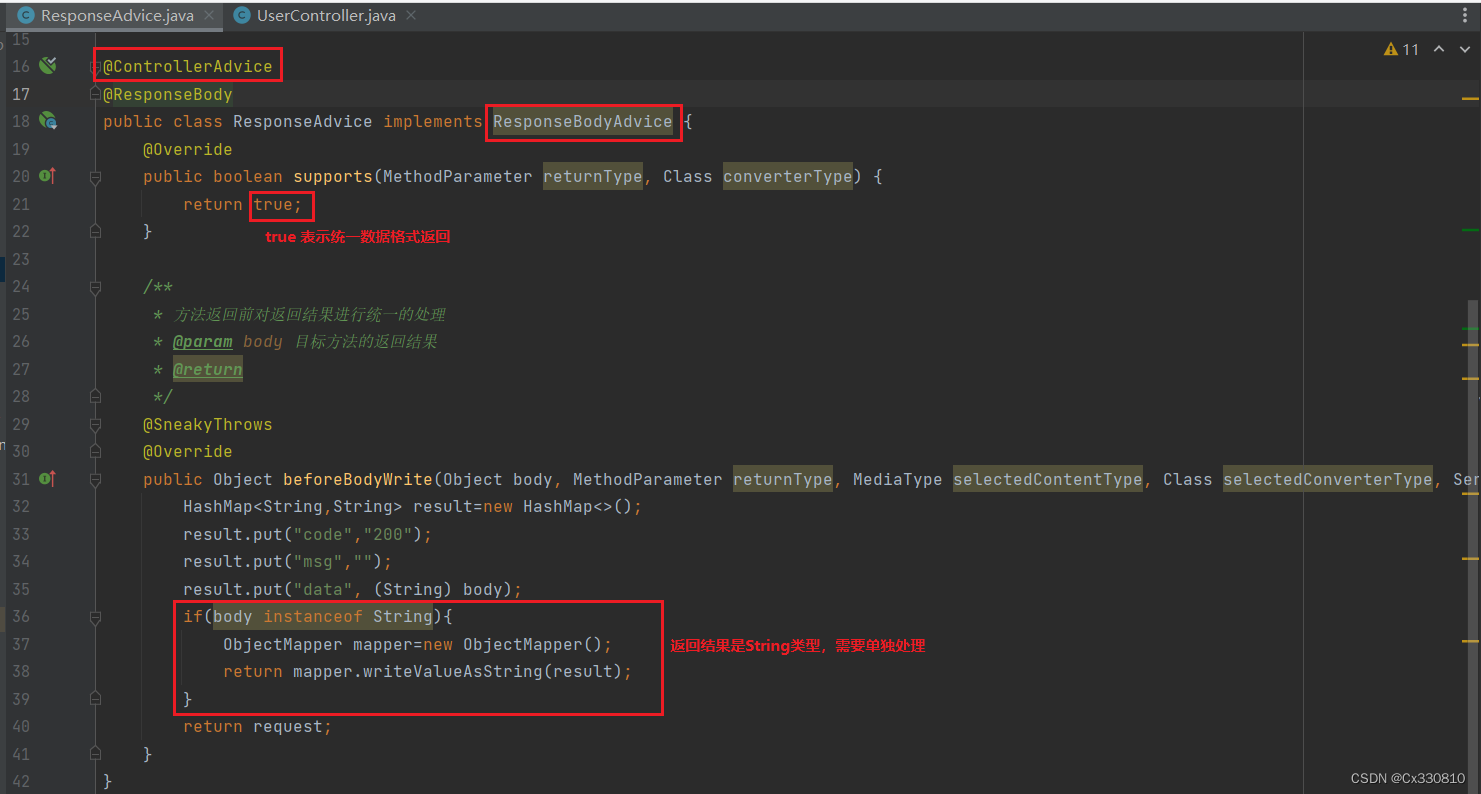
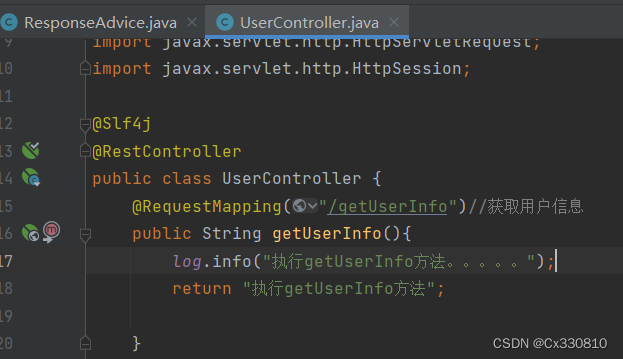
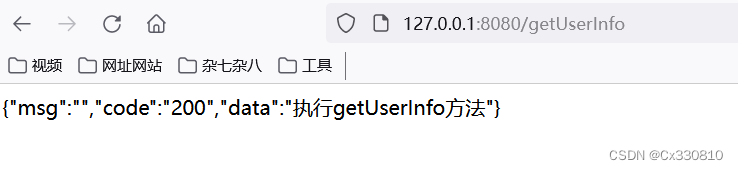
三、Spring事务
1、概念
1.1、定义
把一组操作封装成一个执行单元(即封装到一起),要么全部成功,要么全部失败。
1.2、Spring 事务的实现
(1)编程式:通过写代码的方式。
(2)声明式:通过注释的方式。
2、实现
2.1、编程式
步骤:开启事务;提交事务;回滚事务
@RestController
//@Controller
@ResponseBody
public class TransactionController {
@Resource
private UserInfoService userInfoService;
//JDBC事务管理器
@Resource
private DataSourceTransactionManager transactionManager;//spring内置的对象 数据库事务管理器
//定义事务属性
@Resource
private TransactionDefinition transactionDefinition;
@RequestMapping("/addUser")
public Object add(){
TransactionStatus transactionStatus=transactionManager.getTransaction(transactionDefinition);//开启事务
Integer result=userInfoService.insert("transaction","transaction");//插入数据
System.out.println("添加数据条数:"+result);
transactionManager.commit(transactionStatus);//提交事务
transactionManager.rollback(transactionStatus);//回滚事务
return result;
}
}2.2、声明式
(1) @Transactional
只需要在协议的方法上添加 @Transactional 注解就可以了,无需手动开启和提交事务。进入方法时自动开启事务,方法执行完后会自动提交事务。如果程序没有发生异常,则事务提交;若方式异常,则事务回滚。
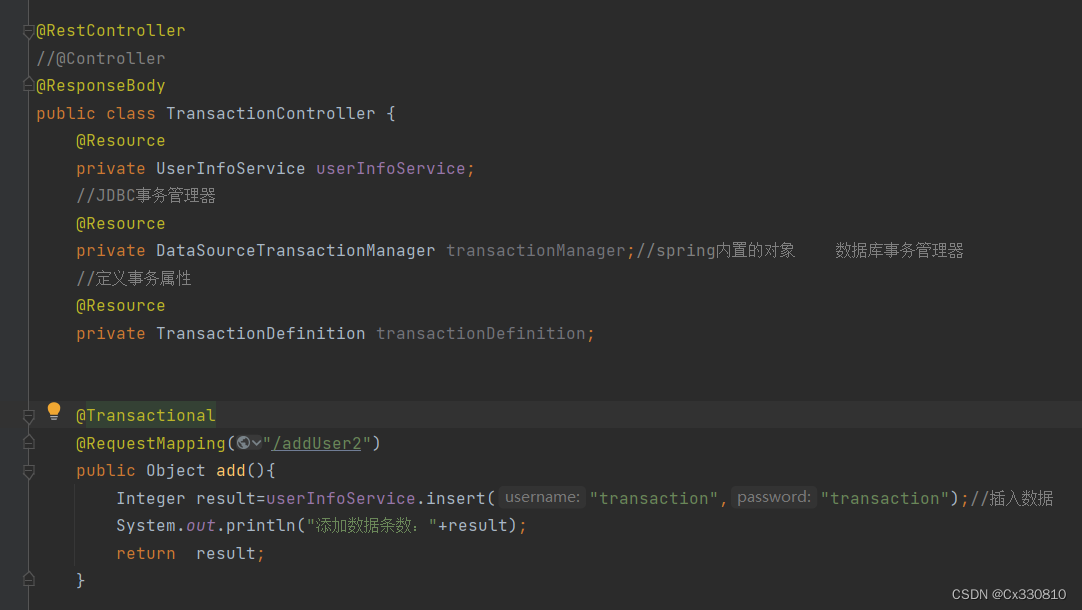
PS:可以捕获所有的异常
@Transactional(rollbackFor = Exception.class)(2)作用范围
@Transactional 可以用来修饰方法和类:
修饰方法时:只能应用到 public 方法上,否则不生效。
修饰类时:表明该注解对该类中所有的 public 方法都生效。
3、事务隔离级别
3.1、事务的四大特性(ACID)
(1)原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成。事务在执行过程中若发生错误,就会被回滚到事务开始前的状态,就像这个事务出来没有执行过一样。
(2)一致性(Consistency):在事务开始前和结束后,数据库的完整性没有被破坏,这表示写入的资料必须完全符合所有的预设规则。
(3)持久性(Isolation):事务处理结束后,对数据的修改是永久性的,及时系统故障也不会丢失。
(4)隔离性(Durability):数据库允许多个并发事务同时对其数据进行读写和修改的能力,可以防止多个事务并发执行时由于交叉执行导致的数据的不一致。事务隔离可以分为读未提交、读提交、可重复读和串行化四个级别。
PS:在这四种特性中,只有隔离性(隔离级别)是可以设置的。
PS:事务隔离级别解决的是多个事务同时调用数据库的问题。
3.2、MySQL中的四种事务隔离级别
(1)读未提交
该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,⽽未提交的数据可能会发⽣回 滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读(也就是一个事务读取到了另一个事务修改后的数据,但后一个事务又进行了回滚,从而导致第一个事务读取到的数据是错的。)。
(2)读已提交
该隔离级别的事务可以读到其他事务中已提交的数据。不会有脏读的问题。但由于在事务的执⾏中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读(一个事务在两次查询得到的结果是不同的,是因为两次查询中有另一个事务把数据修改了)。
(3)可重复读
是 MySQL 中的默认事务隔离级别。它能确保同⼀事务多次查询的结果⼀致。但也会有新的问题,⽐如此级别的事务正在执⾏时,另⼀个事务成功的插⼊了某条数据,但因为它每次查询的结果都是⼀样的,所以会导致查询不到这条数据,⾃⼰重复插⼊时⼜失败 (因为唯⼀约束的原因)。明明在事务中查询不到这条信息,但⾃⼰就是插⼊不进去,这就叫幻读(一个事务两次查询到的结果集是不同的,是因为在两次查询中另一个事务又新增了一部分数据)。
(4)串行化
事务隔离的最高级别。它会强制事务排序,使之不会发⽣冲突,从⽽解决 了脏读、不可重复读和幻读问题,但执行效率较低。
3.3、Spring 中的五种事务隔离级别
(1)Isolation.DEFAULT:以连接的数据库的事务隔离级别为主。
(2)Isolation.READ_UNCOMMITTED:读未提交,可以读取到未提交的事务,存在脏读。
(3)Isolation.READ_COMMITTED:读已提交,只能读取到已经提交的事务,解决了脏读,存在不可重复读。
(4)Isolation.REPEATABLE_READ:可重复读,解决了不可重复读,但存在幻读(MySQL默认级别)。
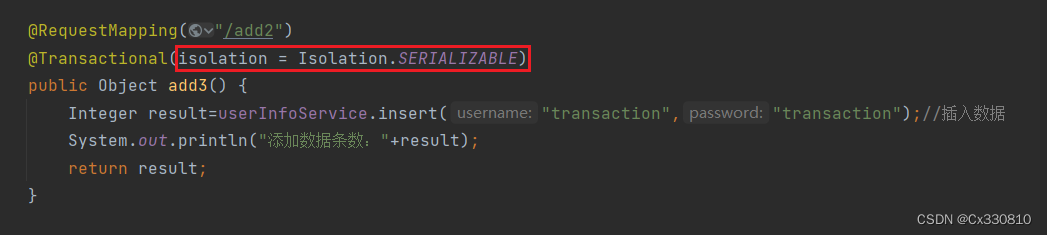
(5)Isolation.SERIALIZABLE:串⾏化,可以解决所有并发问题,但性能太低。
PS:Spring 中事务隔离级别只需要设置 @Transactional ⾥的 isolation 属性即可:如:
4、Spring 事务传播机制
4.1、定义
4.2、Spring 事务传播机制
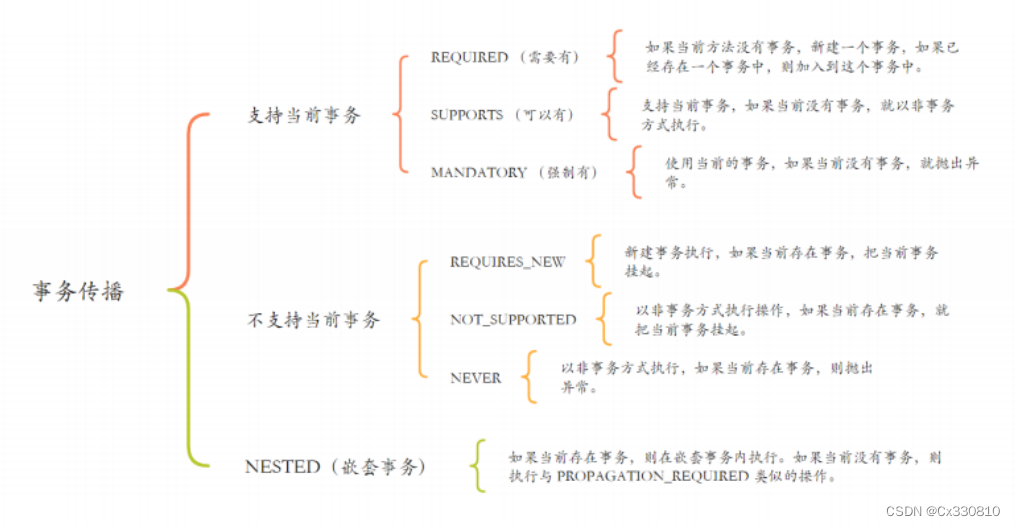
(1)Propagation.REQUIRED:默认,若当前存在事务则加入该事务,若不存在则新建一个。
(2)Propagation.SUPPORTS:若存在则加入,若不存在则以非事务方式继续运行。
(3)Propagation.MANDATORY:若存在则加入,若不存在则抛出异常。
(4)Propagation.REQUIRES_NEW:新建一个新事务,若存在当前事务则挂起它
(5)Propagation.NOT_SUPPORTED:以非事务方式运行,若当前存在事务则把当前事务挂起。
(6)Propagation.NEVER:以非事务方式运行,若当前存在事务则抛出异常。
(7)Propagation.NESTED:若当前存在事务则新建一个事务来作为当前事务的嵌套事务运行,若当前没事务则该取值等价于 PROPAGATION_REQUIRED。