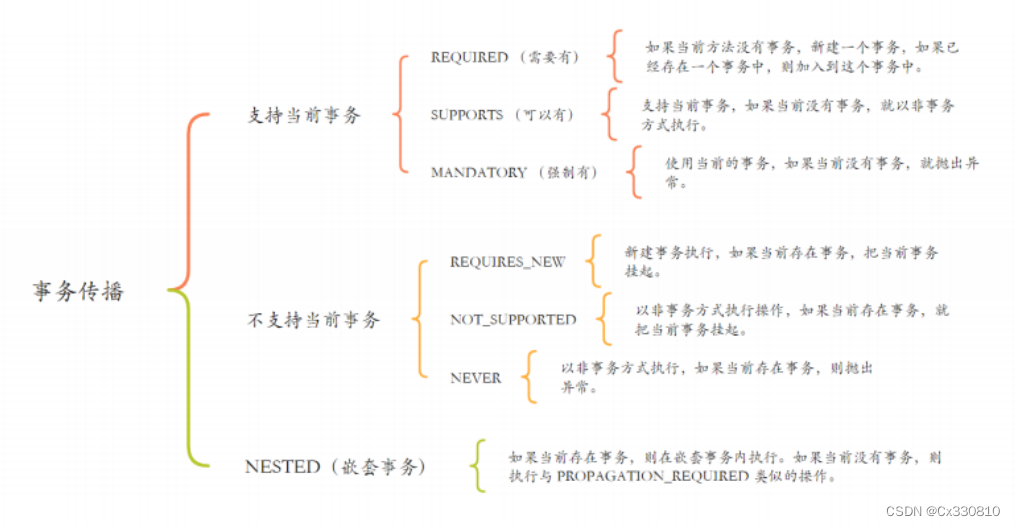
一、standalone基于修改部署
https://blog.csdn.net/weixin_43205308/article/details/131070277?spm=1001.2014.3001.5501
二、安装ZOOKEEPER
zookeeper 安装下载与集群
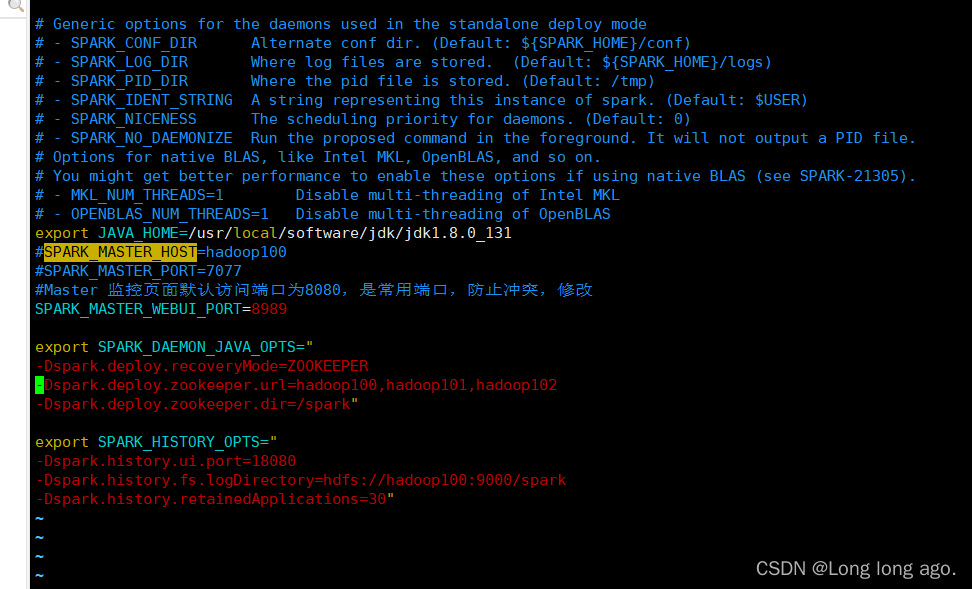
三、修改conf下的spark-env.sh
vim conf/spark-env.sh
注释以下内容(根据自己环境修改)
#SPARK_MASTER_HOST=hadoop100
#SPARK_MASTER_PORT=7077

添加以下配置(根据自己环境修改)
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop100,hadoop101,hadoop102
-Dspark.deploy.zookeeper.dir=/spark
完整配置如图
记得分发配置
四、启动zookeeper
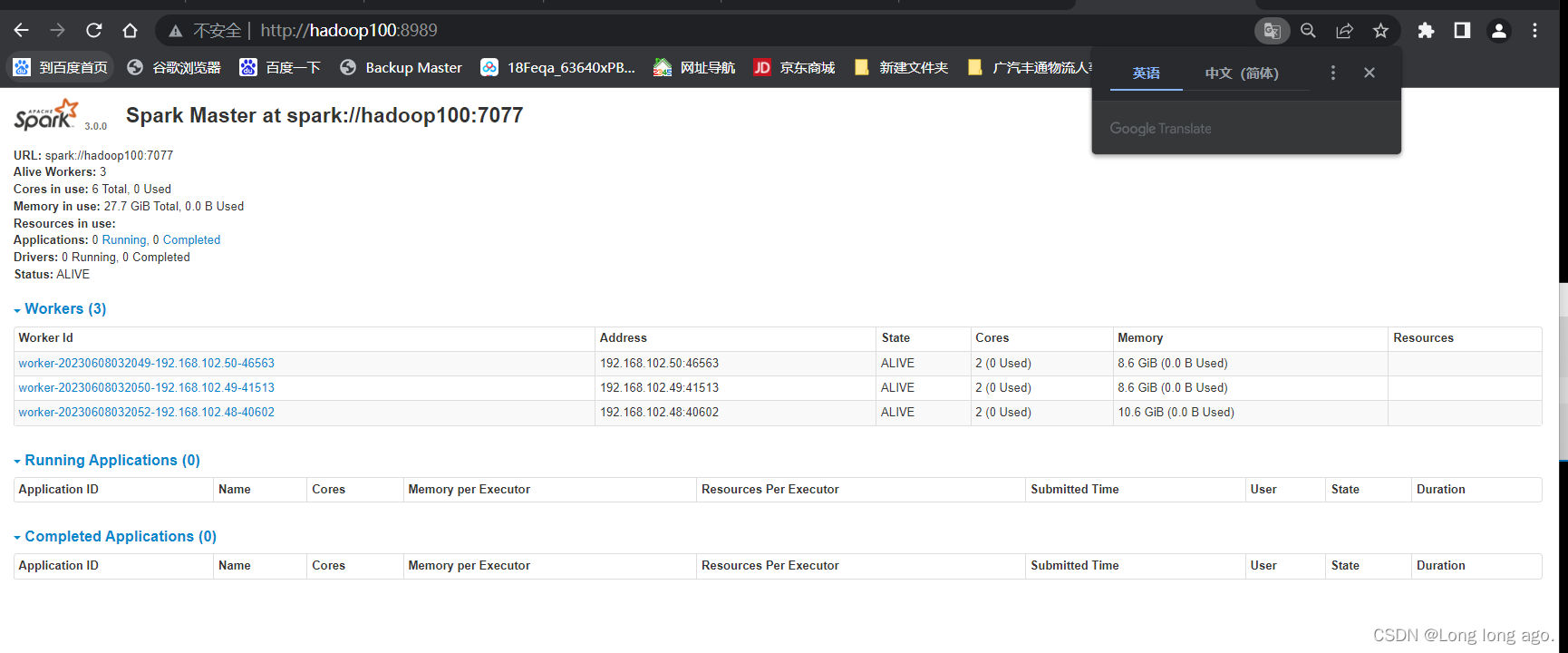
五,重启Spark
在hadoop100操作
sbin/start-all.sh
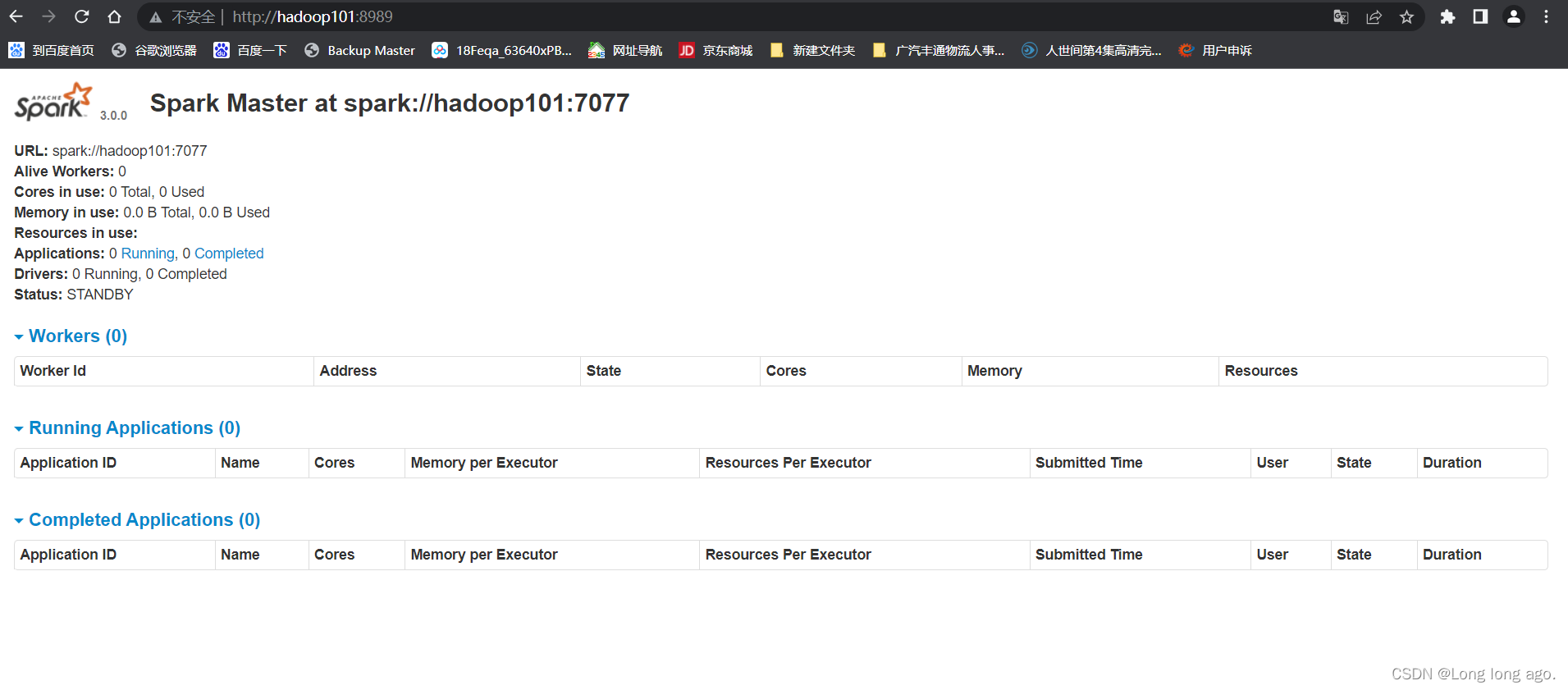
在hadoop101只启动master
sbin/start-master.sh
六、测试
关闭其中一个masetr进程,master节点将会切换